




GPT-5.5核心解读OpenAI商业模式变革告别Token销售

当地时间4月23日,OpenAI正式揭开了新一代旗舰模型GPT-5 5的面纱。官方将其定位为“面向真实工作的全新智能层级”,这一定位并非空谈,而是标志着AI从“能力集合”向“工作系统”的实质性转变。 这次发布的核心看点,可以归结为两点:效率的突破与角色的进化。 首先,在效率层面,GPT-5 5实现了
当地时间4月23日,OpenAI正式揭开了新一代旗舰模型GPT-5.5的面纱。官方将其定位为“面向真实工作的全新智能层级”,这一定位并非空谈,而是标志着AI从“能力集合”向“工作系统”的实质性转变。
这次发布的核心看点,可以归结为两点:效率的突破与角色的进化。
首先,在效率层面,GPT-5.5实现了“鱼与熊掌兼得”。它的上下文窗口扩展至惊人的100万Token,但关键不在于规模的简单膨胀,而在于它做到了在同等响应延迟下,提供更高的智能水平。换句话说,模型变大了,速度却没慢下来。
其次,一个更具碘伏性的细节是,GPT-5.5在训练过程中,直接参与了自身推理基础设施的优化。简而言之,AI第一次学会了“帮自己调参数”。
性能数据最能说明问题。在测试复杂命令行工作流的Terminal-Bench 2.0中,GPT-5.5得分82.7%,将Claude Opus 4.7的69.4%甩开超过13个百分点。在评估AI独立操作真实电脑的OSWorld-Verified测试中,其成功率高达78.7%,已经超越了人类基线。而在覆盖44种职业知识工作的GDPval测试中,84.9%的任务达到或超过了行业专家水平。
当然,能力的跃升也伴随着价格的调整。GPT-5.5的API定价为每百万Token输入5美元、输出30美元,是前代GPT-5.4的两倍。不过,官方强调,由于GPT-5.5完成相同任务所需的Token数量大幅减少,综合成本未必显著上升。此外,批量处理和弹性定价可享受半价优惠,而优先处理的价格则为标准价格的2.5倍。

在ChatGPT产品中,GPT-5.5将以“GPT-5.5 Thinking”的形式逐步上线。一个贴心的小设计是,模型在开始思考前会先给出一段思路概述,用户可以在执行过程中随时插话,调整方向,交互变得更加自然。
如果用一句话来概括GPT-5.5的意义,或许可以这样理解:过去的模型更像是一个装满工具的百宝箱,而GPT-5.5,则进化成了一个懂得规划、自我检查并能持续推进的智能工作系统。
01 84.9%的任务,达到专业人士水准
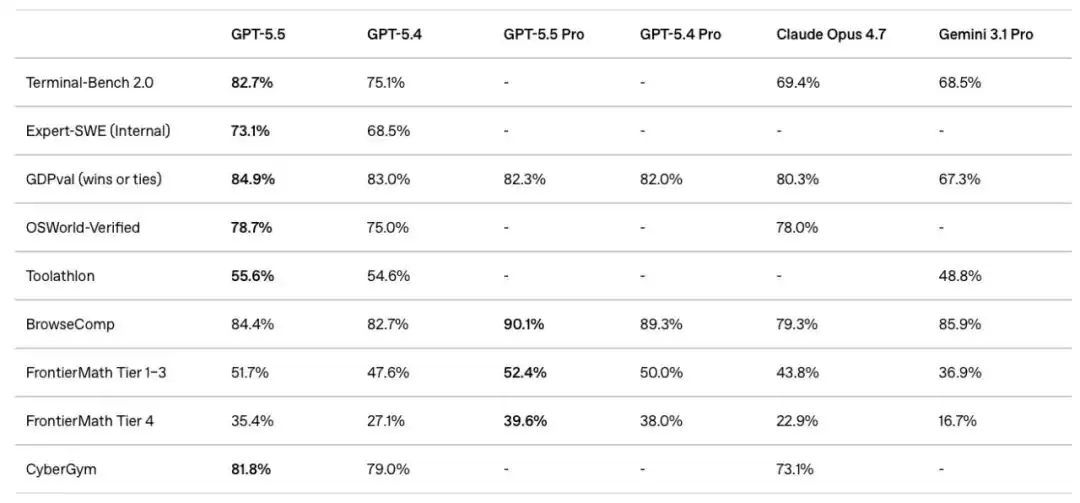
图:GPT-5.5与各竞品在Terminal-Bench 2.0、GDPval、OSWorld-Verified等核心基准测试中的对比
评估模型在真实职业场景中的表现,OpenAI这次用了一个名为“GDPval”的基准测试。这个测试要求模型完成一整套职业任务,覆盖了财务建模、法律分析、数据科学报告、运营规划等44种职业场景,相当全面。
结果令人印象深刻:GPT-5.5在84.9%的任务中,表现达到或超过了行业专业人士的水平。作为对比,GPT-5.4是83.0%,Claude Opus 4.7是80.3%,而Gemini 3.1 Pro则只有67.3%。
这种领先优势是全方位的。例如,在电子表格建模任务中,GPT-5.5内部测试拿到了88.5%的分数;在投资银&行级别的复杂建模任务中,同样保持领先。早期测试者的反馈也印证了这一点:GPT-5.5 Pro的回答在全面性、结构性和实用性上,相比GPT-5.4 Pro有明显提升,尤其在商业、法律、教育和数据科学领域。
光看数字可能有些抽象,OpenAI这次干脆把“自家工位”掀开给大家看。据透露,公司内部超过85%的员工每周都在使用其编程模型Codex,覆盖财务、传播、市场、产品、数据科学等多个部门。
具体怎么用?传播团队用它分析了六个月的演讲邀约数据,搭建起一套自动化分级流程;财务团队用它审阅了24,771份、合计71,637页的K-1税务表格,比去年提前两周完工;市场拓展团队则通过自动化周报生成,每人每周能省下5到10小时。这些都不是实验室里的演示,而是已经融入日常工作流程的真实应用。
02 最强自主编程模型
OpenAI毫不讳言,GPT-5.5是目前其最强的自主编程模型。
在测试复杂命令行工作流的Terminal-Bench 2.0上,GPT-5.5得分82.7%,对比GPT-5.4的75.1%,提升幅度接近8个百分点,同时Token消耗更少。在评估真实GitHub问题一次性解决能力的SWE-Bench Pro上,得分58.6%。在内部的长周期编程任务评测Expert-SWE上(中位人工完成时间约20小时),GPT-5.5同样超越了前代。
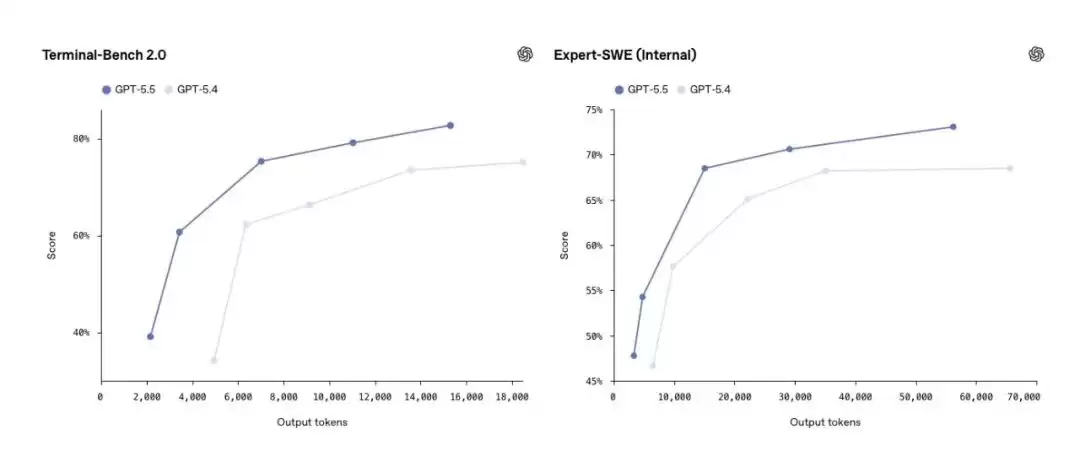
配图:Terminal-Bench 2.0和Expert-SWE散点图
在GPT-5.5的驱动下,Codex已经能够从一句简单的提示词出发,独立完成从代码生成、功能测试到视觉调试的完整开发流程。
官方演示案例极具说服力:一个基于NASA真实轨道数据构建的太空任务应用,支持3D交互操控,其轨道力学模拟达到了真实物理精度;另一个地震追踪器,能够接入实时数据源并完成可视化,这表明模型已具备调用外部API、处理动态数据并实时渲染的完整能力。
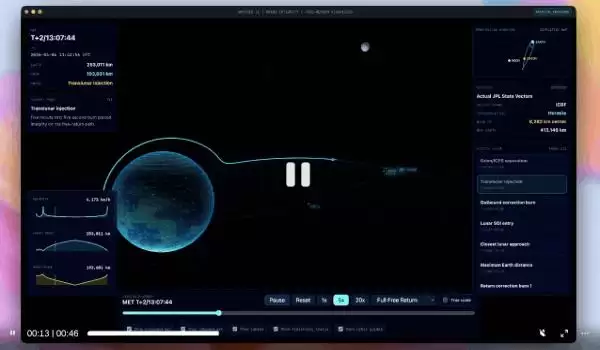
来自用户的反馈更为生动。Every创始人兼CEO Dan Shipper分享了一段经历:他曾遇到一个上线后的bug,自己调试数日无果,最终只得请公司最强的工程师重写部分系统才解决。GPT-5.5发布后,他做了个实验——将模型“放回”bug尚未修复的状态,看它能否得出与顶级工程师相同的解决方案。结果是,GPT-5.4做不到,而GPT-5.5做到了。Dan的评价是:“这是我用过的第一个真正具备概念清晰度的编程模型。”

一位英伟达工程师的评价则更为直白:“失去GPT-5.5的访问权限,感觉就像截肢。”

Cursor联合创始人兼CEO Michael Truell对此的补充点出了关键:GPT-5.5比GPT-5.4更聪明、更坚韧,在复杂的长时任务中,它能坚持更久而不提前“放弃”——而这恰恰是工程工作中最宝贵的品质。
03 知识工作:AI第一次真正能“用”电脑
如果说编程是“创造”,那么操作电脑完成知识工作就是“执行”。在OSWorld-Verified测试中(评估模型独立操作真实计算机环境的能力),GPT-5.5取得了78.7%的成功率,高于GPT-5.4的75.0%,也优于Claude Opus 4.7的78.0%。
这不仅仅是截图分析,而是真正的屏幕操控:看到界面、点击、输入、在多个工具间切换,直到任务完成。GPT-5.5让人第一次真切感受到,AI可以作为一个真正的“协作者”,与你共同使用同一台电脑。
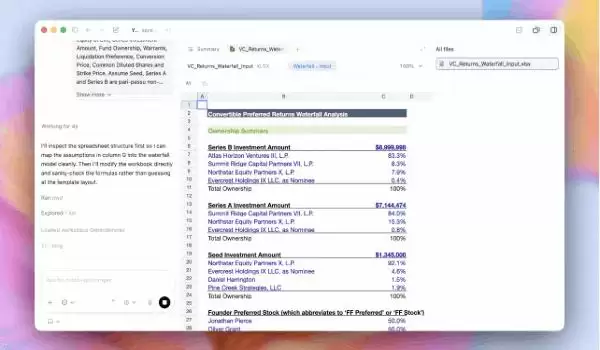
财务建模演示视频
在电信客服工作流测试Tau2-bench上,GPT-5.5在无提示词调优的情况下准确率高达98.0%,而GPT-5.4仅为92.8%。这意味着模型对任务意图的理解已经足够深入,无需精心设计的提示词,就能处理复杂的多步骤对话流程。
在工具搜索能力上,GPT-5.5在BrowseComp测试中得分84.4%,Pro版本更达到90.1%。这表明,在需要跨多个信息来源进行综合推理的研究类任务中,模型展现出了强大的持续检索和信息整合能力。
04 科学研究:协助发现数学新证明
在这次发布中,GPT-5.5在科研领域的表现,可能是最出人意料、也最令人兴奋的部分。
过去谈论AI做科研,它更多扮演“辅助工具”的角色,用于查文献、写代码或整理数据。但这一次,它的角色明显前移,开始参与更核心的环节:复杂推理,甚至是新知识的发现本身。
在遗传学和定量生物学多阶段数据分析评测GeneBench上,GPT-5.5得分25.0%,GPT-5.4为19.0%。这些任务通常对应科学专家数天的工作量,模型需要在几乎没有监督的情况下,推理可能存在错误的数据、应对隐藏的混杂因素,并正确实施现代统计方法。
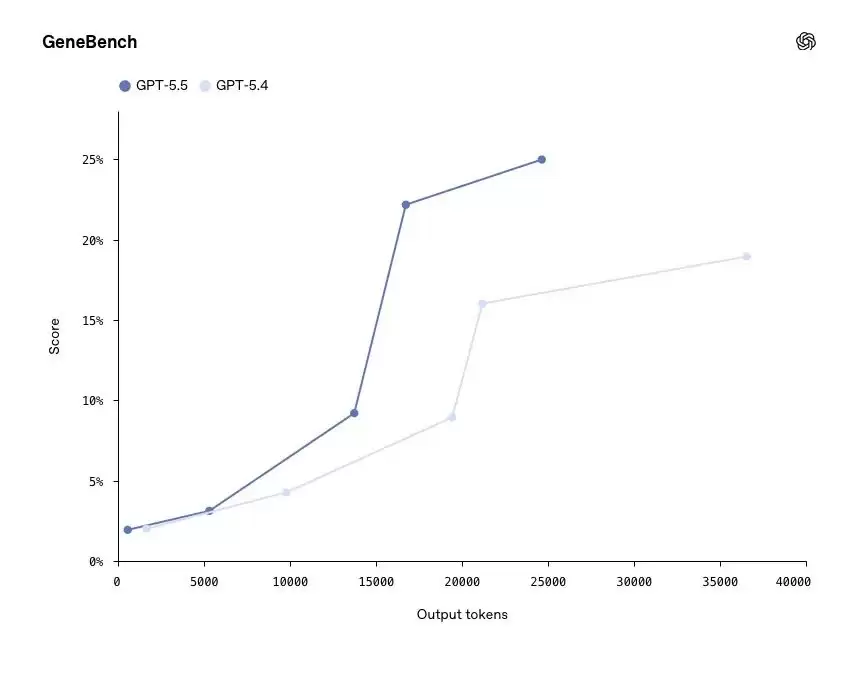
从图表曲线可以看出,随着输出Token数量的增加,GPT-5.5的得分提升幅度始终领先于GPT-5.4,并在约15,000 Token处明显拉开差距。这意味着,面对需要深度推理的长任务,GPT-5.5的优势会随着任务复杂度的提升而进一步放大。
在真实世界生物信息学基准测试BixBench上,GPT-5.5以80.5%的得分领先于GPT-5.4的74.0%,在已发布得分的模型中位居前列。
真正引发学界关注的是一个具体案例:配备自定义工具框架的GPT-5.5内部版本,协助研究人员发现了一项关于拉姆齐数的新数学证明,并在形式化证明工具Lean中得到了验证。拉姆齐数是组合数学的核心研究对象,该领域的成果十分罕见,技术难度极高。这不再是AI提供代码或解释,而是真正贡献了一个原创的数学论证。
实际应用层面同样有说服力。Jackson实验室免疫学教授Derya Unutmaz利用GPT-5.5 Pro分析了一个包含62个样本、近28,000个基因的基因表达数据集,生成了详细的研究报告并提炼出关键发现。他表示,这项工作通常需要一个团队耗费数月才能完成。
另一个例子来自波兹南亚当·密茨凯维奇大学数学系助理教授Bartosz Naskręcki。他仅凭一条提示词,利用Codex中的GPT-5.5在11分钟内构建出一款代数几何应用,可视化两个二次曲面的交线,并将所得曲线转化为可用于后续研究的魏尔斯特拉斯模型。从提示词到可运行的研究工具,全程由模型独立完成。
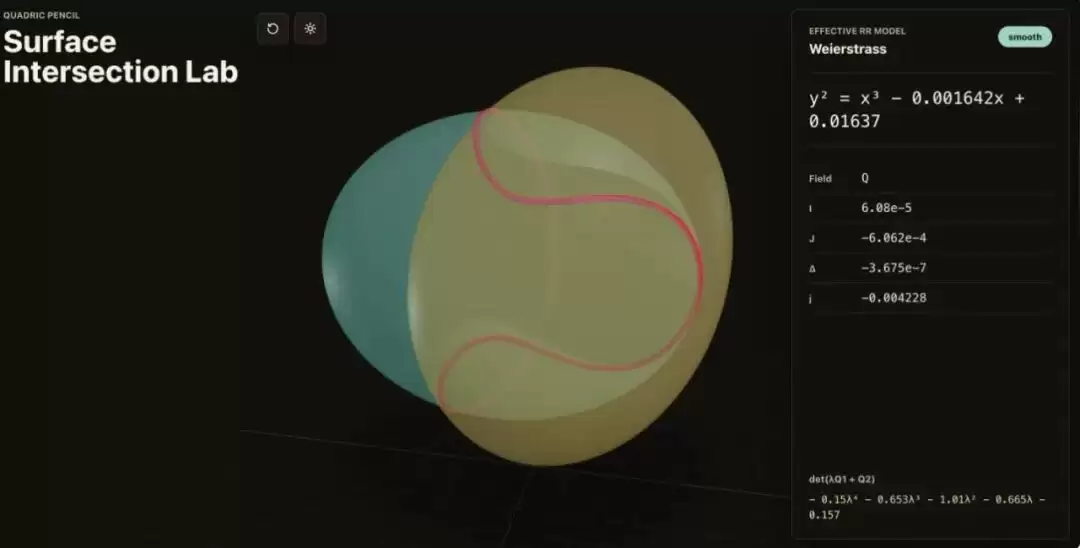
配图:Bartosz Naskręcki教授构建的代数几何应用截图——二次曲面相交可视化与魏尔斯特拉斯方程实时计算界面
Axiom Bio联合创始人Brandon White的评价更为直接:“如果OpenAI保持这一势头,年底前药物发现的基础将会发生改变。”
05 推理效率:AI第一次帮自己优化了基础设施
这次发布有一个容易被忽视但技术层面极其关键的细节:GPT-5.5是一个更大、更强的模型,但它在实际服务中的单Token延迟,却与GPT-5.4持平。
要在更强的能力下维持同等的响应速度,OpenAI将推理系统作为整体进行了重新设计。而最有趣的是,Codex和GPT-5.5本身直接参与了这一优化过程。
从Artificial Analysis的智能指数图可以直观看出:横轴是输出Token总量,纵轴是综合智能得分。GPT-5.5的曲线不仅在得分上全面领先,更关键的是,它在Token消耗较少的区间,就已经达到了其他模型需要消耗更多Token才能达到的得分水平——更强的能力,更低的成本,这正是“效率提升”最直观的体现。
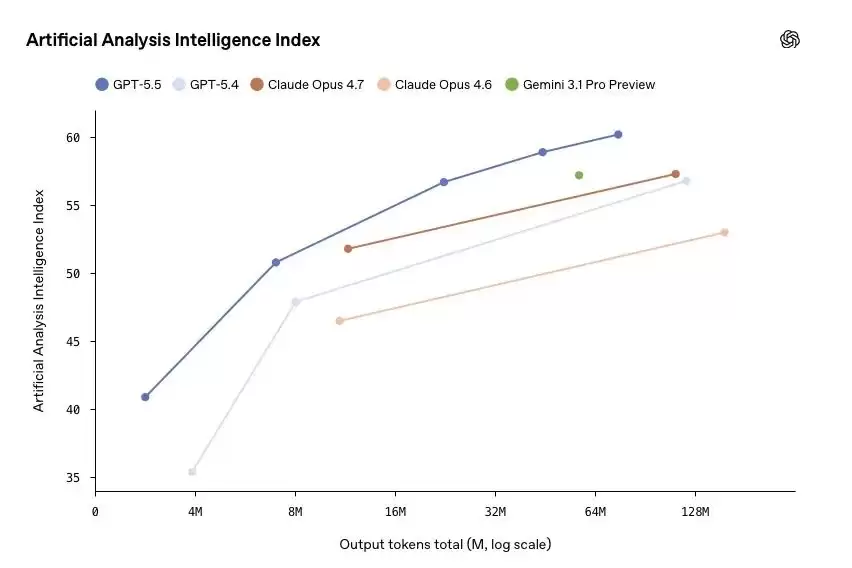
配图:Artificial Analysis智能指数折线图
具体是如何实现的?团队面临的核心问题是负载均衡。此前,他们将请求拆分为固定数量的块以均衡GPU工作,但静态分块并非对所有流量形态都是最优的。于是,Codex分析了数周的生产流量数据,编写了自定义的启发式算法,最终将Token生成速度提升了超过20%。
更进一步,GPT-5.5是与NVIDIA GB200和GB300 NVL72系统协同设计、协同训练和协同部署的。换句话说,这一代模型参与优化了服务自身的推理架构。这不是比喻,而是字面意义上的“AI改进了运行自己的系统”。
06 网络安全:能力提升,管控同步收紧
随着能力的全面提升,GPT-5.5在网络安全领域的表现也水涨船高,但与之相伴的是更严格的管控措施。
在CyberGym测试中,GPT-5.5得分81.8%,高于GPT-5.4的79.0%和Claude Opus 4.7的73.1%。在内部“夺旗”(CTF)挑战任务中,GPT-5.5得分88.1%,GPT-5.4为83.7%。
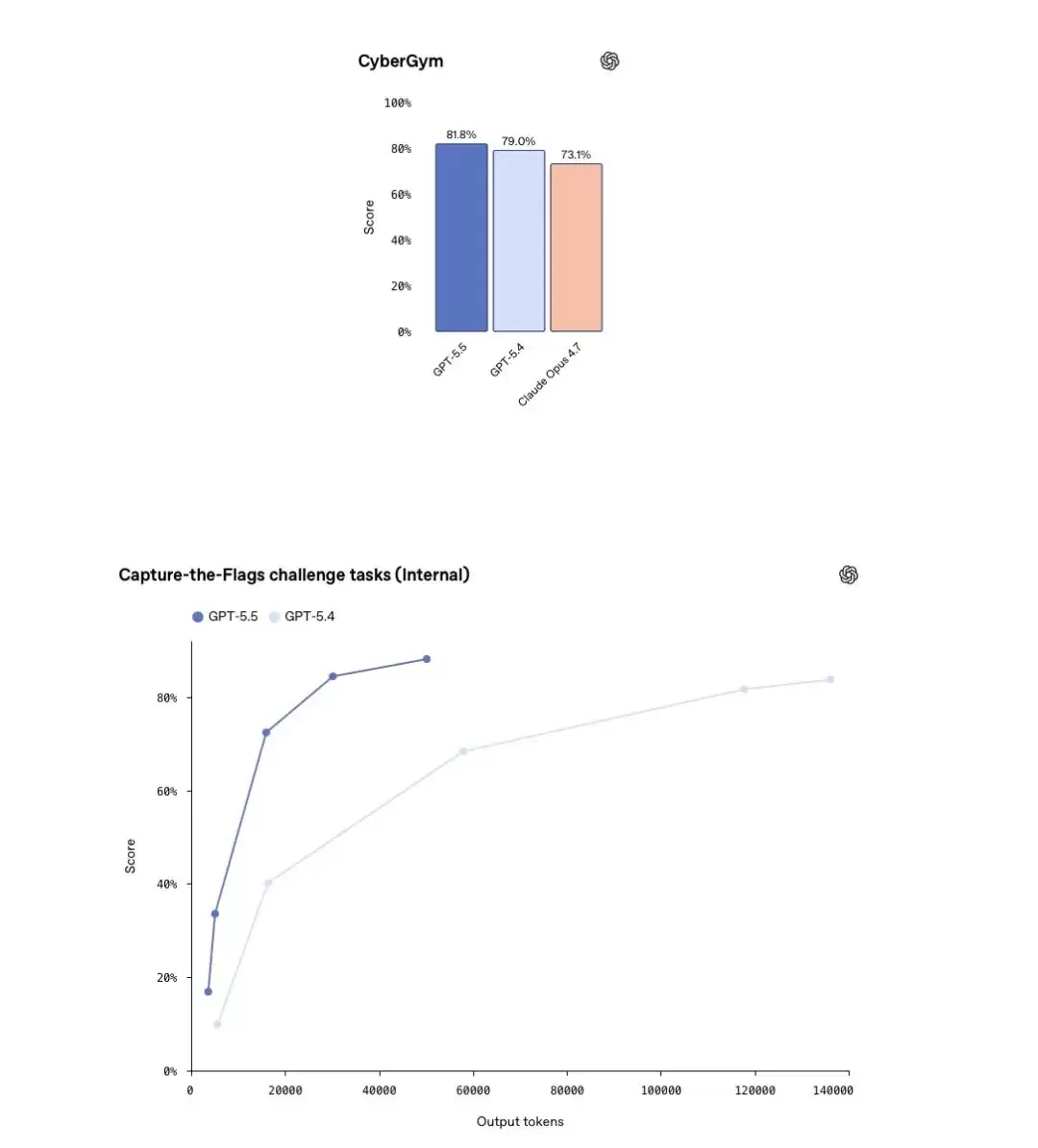
配图:CyberGym柱状图与CTF挑战任务散点图
OpenAI将GPT-5.5的网络安全和生物/化学能力评级,定为应急准备框架下的“高”级(尚未达到“关键”级),但相比前代已有明确提升。同时,官方也坦承,新部署的更严格风险分类器“部分用户最初可能会觉得有些不便”,并将持续进行调整。
为了在安全防御与访问便利之间取得平衡,OpenAI推出了“网络安全可信访问”计划。符合条件的安全研究人员和关键基础设施防御者可以申请更宽松的访问权限,以更少的摩擦使用其高级网络安全能力。
这背后的逻辑清晰而务实:技术能力的扩散是不可逆的趋势。比一味限制扩散更现实的路径,是确保防御者能够比攻击者更早、更好地用上最强大的工具。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

三星Galaxy S24 Ultra满血性能驰骋游戏世界
三星GalaxyS24Ultra凭借纯平高亮屏幕、第三代骁龙8移动平台、光追技术及扩大1 9倍的VC均热板,实现流畅游戏与稳定温控。5000毫安时电池与45W快充保障持久续航,获泰尔实验室两项五星认证。同时融合AI创新,带来沉浸式游戏体验。

洲明牵头发布全国首个VP用LED显示屏标准
聊一个行业里的大新闻——全国首个虚拟制作(VP)用LED显示屏标准,近日正式发布。该标准由洲明科技主导起草,全称为《虚拟制作(VP)用LED显示屏系统规范》,由中国光学光电子行业协会发布,直接填补了国内在该领域的标准空白,为虚拟拍摄LED显示屏产业的规范化发展奠定了重要基础。 为什么要制定这项标准?

涂鸦智能龙年潮品年货清单出炉,幸福感提升
春节期间,涂鸦智能推荐实用智能潮品年货。智能扫地机与擦窗机器人解放清洁双手;智能空气炸锅与厨房营养秤提升烹饪乐趣;激光星空投影仪与智能音响营造节日氛围,为家庭增添便捷与喜悦。

三星7天机高性价比与优质服务在激烈市场中脱颖而出
在当下的智能手机市场中,三星旗舰机型始终是备受瞩目的焦点——外观设计出众、硬件配置强悍,拥有大量忠实用户。不过,其高昂的售价也令人望而却步,旗舰机常常突破万元大关,让许多潜在消费者犹豫不决。为破解这一“心仪却难入手”的困境,三星推出了名为“7天机”的产品,以更亲民的价格和更完善的售后服务,在高端市场

曲面机器人研发商和意精工获前海母基金与卓源亚洲天使轮投资
和意精工获前海母基金与卓源亚洲天使轮投资,团队来自加拿大,研发自主曲面适应性机器人,实现无编程轨迹规划与在线快节拍自动化,应用于卫浴、叶片、车体等复杂曲面加工,自研算法使轨迹生成小于1秒。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-16 22:35
2026-07-16 22:35
2026-07-16 22:35
2026-07-16 22:31
2026-07-16 22:31
2026-07-16 22:31
2026-07-16 22:31
2026-07-16 22:31
热门教程
2026-07-16 22:35
2026-07-16 22:35
2026-07-16 22:35
2026-07-16 22:31
2026-07-16 22:31
2026-07-16 22:31
2026-07-16 22:31
2026-07-16 22:31
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















