




哈佛研究显示大模型在医疗诊断方面超越人类医生

你是否经历过身体不适去医院,却查不出明确病因的焦虑与无助?或许在不久的将来,能够为你快速提供一份可靠“第二诊疗意见”的,正是一位人工智能医生。 这并非科幻场景,而是近期国际顶级学术期刊《科学》上一项重磅研究揭示的趋势。一项由哈佛医学院等顶尖机构联合开展的大规模实战测试表明,在真实的急诊室病例诊断中,
你是否经历过身体不适去医院,却查不出明确病因的焦虑与无助?或许在不久的将来,能够为你快速提供一份可靠“第二诊疗意见”的,正是一位人工智能医生。
这并非科幻场景,而是近期国际顶级学术期刊《科学》上一项重磅研究揭示的趋势。一项由哈佛医学院等顶尖机构联合开展的大规模实战测试表明,在真实的急诊室病例诊断中,人工智能的表现已经能够超越经验丰富的人类医生。
研究团队精心设计了六场综合性“大考”,内容涵盖历史经典病例与现代真实急诊场景,让最新的大语言模型与数百名不同资历的真实医生同台竞技。结果令人瞩目:在诊断推理、医疗管理方案制定等多个核心临床任务上,大模型的综合表现全面超越了人类专家。
挑战65年医学诊断金标准
要评估一个医疗诊断系统是否足够“智能”,需要一块公认的试金石。早在1959年,医学界就呼吁建立基于真实病例的基准测试。65年来,《新英格兰医学杂志》定期发布的“临床病理学讨论会”复杂病例,一直被视为此领域的终极挑战。这些病例通常是令顶尖专家都感到棘手的疑难杂症,充满了诊断陷阱和罕见的病理表现。
过去几十年,从早期的贝叶斯系统到基于规则的系统,各类计算机辅助诊断工具都曾尝试挑战这些经典病案,但大多未能成功。如今,随着大语言模型在专业资格考试、复杂数学推理等领域屡创佳绩,人们自然将目光投向了更核心的临床诊断与推理能力。
这一次,研究不再局限于模型间的比较,而是引入了数百名真实医生作为性能基准线,全面检验最新一代o1-preview模型的“硬实力”。
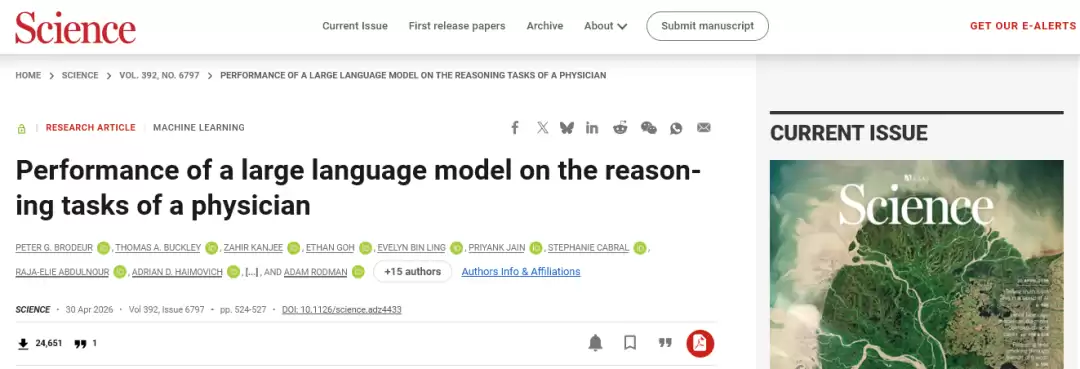
面对《新英格兰医学杂志》的经典疑难病例,o1-preview交出了一份惊艳的答卷。“鉴别诊断”是临床思维的关键,即根据患者症状列出所有可能的疾病并按概率排序。两位资深内科医生对模型生成的诊断列表进行独立盲审,结果高度一致。
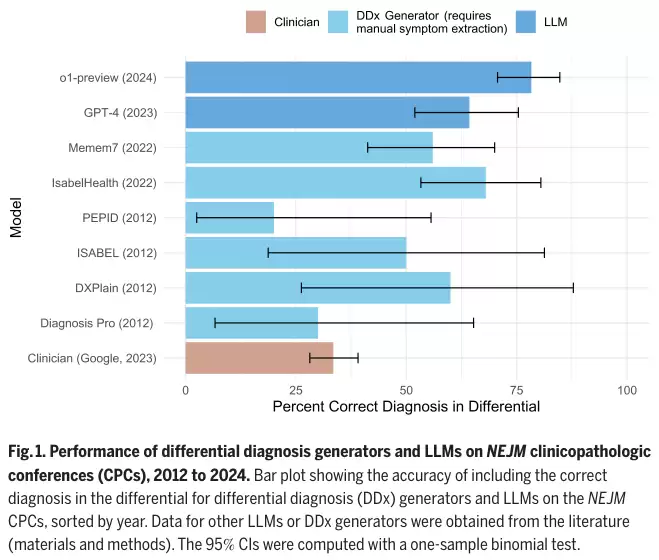
计分结果出人意料:在78.3%的病例中,模型成功将最终正确答案纳入了其鉴别诊断列表;更有甚者,在超过一半(52%)的病例里,模型排在第一顺位的诊断就是正确答案。如果将范围放宽到“具有潜在帮助或非常接近”的诊断,模型的准确率更是高达97.9%。
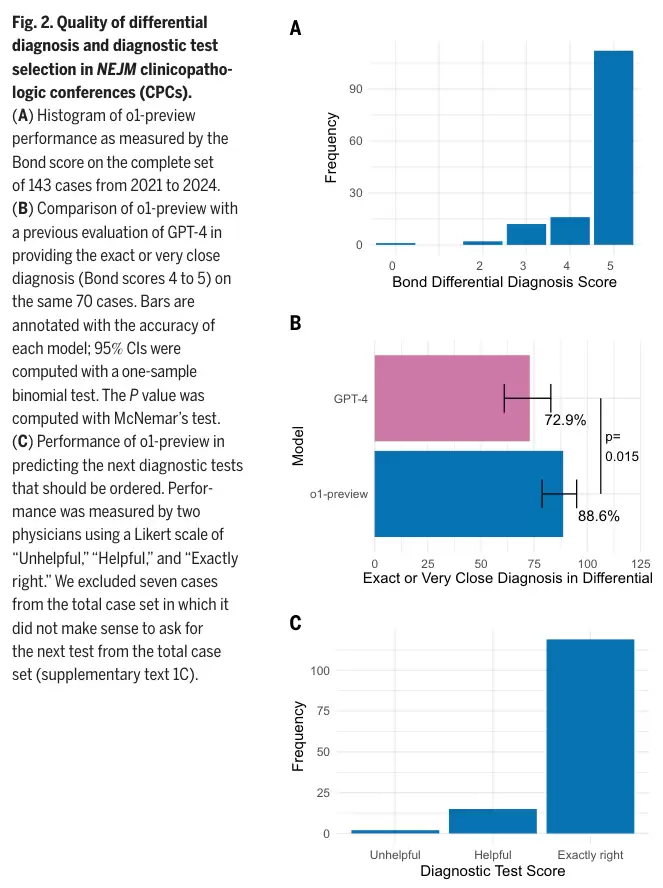
与上一代GPT-4的对比更是凸显了其巨大进步。在同一批70个历史对照病例中,GPT-4的准确率为72.9%,而o1-preview一举提升至88.6%,在绝大多数病例上都保持了领先优势。
不仅如此,在评估模型为患者选择下一步诊断检查项目的能力时,面对136个高难度病例,o1-preview在87.5%的情况下精准选择了符合患者需求的正確项目,另有11%的建议被判定为有实质帮助,仅1.5%缺乏建设性。
六项综合大考全面超越人类医生
一项测试的胜利或许带有偶然性,但研究团队准备了一套涵盖多个维度的重磅评估题库,结果依然一致地指向AI的优势。
首先,在专门用于评估临床推理核心能力的虚拟患者案例测试中,机器拿到了近乎完美的成绩。研究采用经过验证的10分制修订版IDEA评分标准,在80个高难度案例中,o1-preview在78个案例中斩获满分,得分远高于GPT-4、主治医师及住院医师的平均水平。
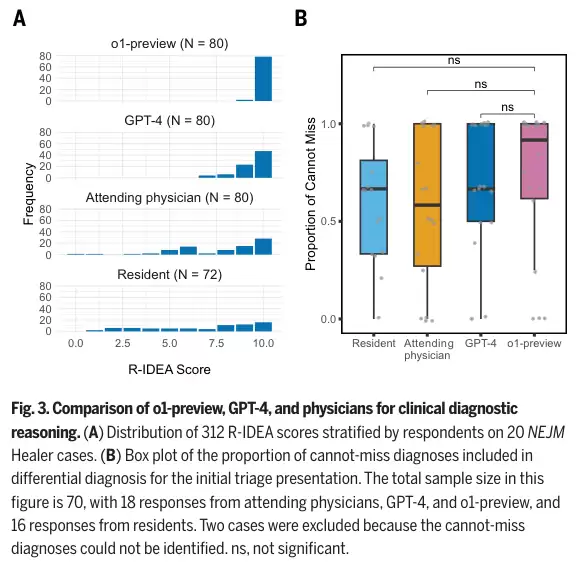
在急诊初期分诊中识别“绝对不能错过”的致命诊断时,新模型同样表现出极高的敏锐度,其识别关键危急病因的比例中位数达到0.92,与人类专家队伍旗鼓相当。
考验升级到更复杂的后续医疗管理步骤。研究团队使用了5个基于真实患者情况改编的测试题,不仅询问“是什么病”,更追问“接下来该怎么做”。这些题目的标准答案已由25位医学专家预先界定。
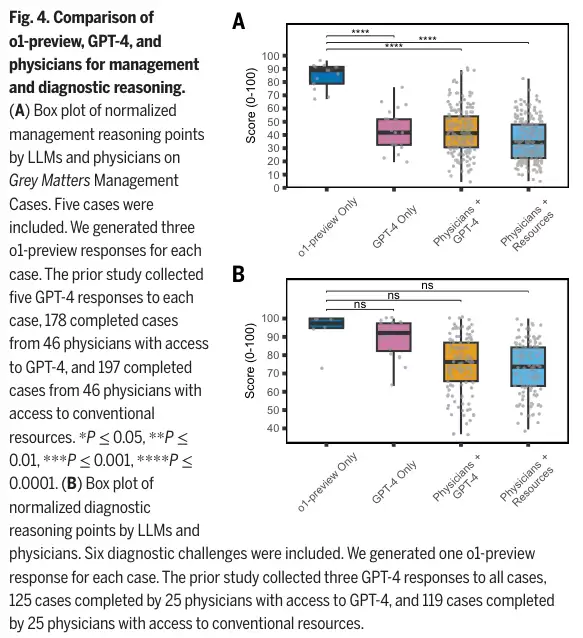
结果对比强烈:o1-preview在满分100的评估中,得分中位数为89分。相比之下,人类医生即便借助GPT-4辅助,得分也仅在41分左右;完全使用传统医疗资源进行决策的医生,得分低至34分。单独上阵的GPT-4得分为42分。图表清晰地揭示了这高达40分以上的实力鸿沟。
老牌计算机辅助诊断系统的经典案例池也未能难倒它。测试使用了6个从未公开的详尽病例。o1-preview交出了97分中位数的优异答卷。历史数据显示,使用传统资源的医生平均得分为74分,GPT-4为92分。
医学不仅需要确定性,更考验对疾病概率的直觉判断。在一项包含553名医疗从业者的全国性样本测试中,要求估算不同病因的诊断概率。数据显示,人类医生在评估概率时个体差异巨大,结果极不稳定。而人工智能给出的数值则异常稳健,更贴近科学文献推导的参考值。在评估心肌缺血的关键检测后概率时,o1-preview的表现大幅超越了人类同行和前代AI系统。
急诊室真实盲测对决:AI vs 人类医生
纸上谈兵终觉浅。研究团队将最终战场搬到了波士顿贝斯以色列女执事医疗中心的真实急诊大厅。这里的数据未经任何润色,充斥着凌乱的记录、不完整的表述和错综复杂的临床指标。
研究随机抽取了76个真实急诊病例,让o1大模型、GPT-4o大模型与两位资深内科主治医师展开盲测比拼。评分者是另外两位不知情的主治医师,他们需要为混在一起的人类手写诊断报告和机器生成的意见进行打分。
有趣的是,裁判极难分辨报告的来源,其中一位医生在94.4%的病例评分卡上选择了“无法分辨是人类还是AI”。
评估被切分为急诊的三个关键决策触点:初期分诊(信息极少)、医生接诊(初步检查后)、决定入院(检验结果基本出炉)。结果显示,随着掌握信息增多,所有参评者的准确率都在提升,但人工智能在每个阶段都表现稳定且优异。
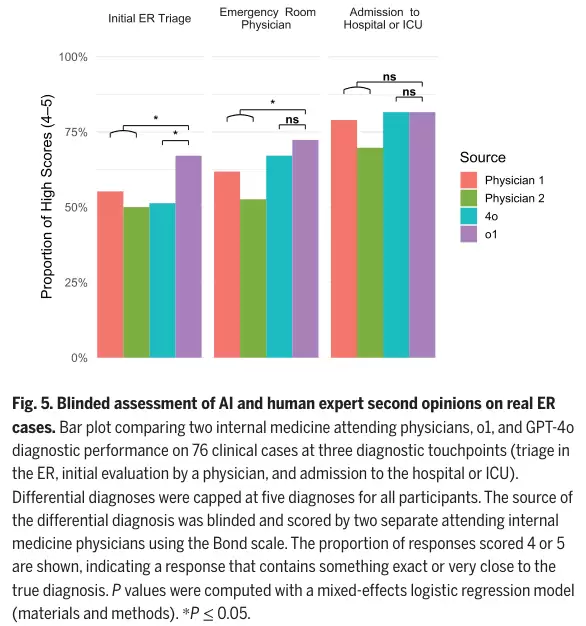
o1模型在信息极度匮乏的初期分诊阶段,给出接近正确诊断的比例达到67.1%,接诊阶段提升到72.4%,入院阶段高达81.6%。而两位资深人类医生的准确率在三个触点上始终落后,尤其在信息最少的初期分诊阶段,差距最为悬殊。
拥抱智能医疗新纪元:机遇与挑战并存
AI技术在临床诊断领域的这次“狂飙”,无疑给现代医学带来了深远影响。长期以来,将机器判断引入临床辅助决策被视为高风险举动,尤其是在急诊室这种信息残缺、却需做出生死攸关决断的高压环境。
这项广泛而严苛的测试验证了现代大语言模型处理复杂、非结构化临床数据的强悍实力。更大规模地应用此类AI辅助诊断工具,极有可能实质性缓解人类医生易疲劳犯错、延误关键治疗时机以及优质医疗资源分布不均等长期痛点。
当然,研究也揭示了必须跨越的障碍。目前的测试仅局限于文本信息分析,而真实的临床问诊充满了至关重要的非文本线索——病人的语气语调、呼吸的节奏、医学影像的光影色彩,这些都是医生决策的关键依据。当前的基础模型在处理这些多模态信号时,仍存在明显的感知局限。因此,未来的一大方向是探索人机协同处理复杂临床信息的最佳工作流程。
环境智能记录与被动健康监测技术的普及,正为打破信息僵局铺平道路。抛弃经过精心修饰的教学病例,在高度真实、杂乱无章的临床前线检验机器成色,已成为人工智能医疗行业发展的必修课。
半个多世纪前,医学先驱们关于计算机辅助诊断的构想,正一步步变为普通人触手可及的现实。面对已在多数临床推理基准上实现超越的“AI医生”,医疗卫生系统亟需加快自身演进:提前规划算力基础设施,设计对一线医护足够友好的软件交互界面,并建立相应的监管与责任框架。
当新一代人工智能诊断技术无缝整合到守护生命健康的最后防线时,你的下一位急诊科权威顾问,或许将不再局限于人类。智能医疗的时代,正在加速到来。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:哈佛研究显示大模型在医疗诊断方面超越人类医生要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点OmniParser是微软AI驱动的SaaS工具,基于YOLOv8和BLIP-2,将UI截图与漫画页面解析为结构化数据,支持UI元素检测、漫画面板分析、对话框及人脸识别,适用于自动化测试、漫画翻译等场景。
通义灵码是贯穿开发全流程的智能编码助手,具备代码智能生成、研发智能问答、多编程语言及编辑器支持、代码安全隐私保障四大核心能力,适用于学生、新手及企业开发者等多类人群,提升编码效率。
基于人工智能的自动化道路巡逻和资产数据收集方案,通过车载相机自动采集路面及周边资产数据,识别裂缝、坑槽等病害并建立数字化台账,同时自动删除隐私图像,实现从被动响应向主动预防的转变,降低巡检成本。
阿里旗下通义智文是一款智能阅读工具,支持网页、论文、图书和自由阅读四种场景,帮助用户快速提取核心观点,节省阅读时间,适合学生、研究人员及职场人士高效处理大量文本。
- 日榜
- 周榜
- 月榜
热点快看