




Auto Research 时代来临:AI接管科研苦活将如何重塑科学未来

Frontier-EngBench基准推动AI评估从“一次性答对”转向“持续优化”。测试要求智能体在工程环境中通过迭代反馈、仿真验证与策略修正逼近最优解。研究表明,深度迭代推理相比并行尝试更能提升性能,揭示智能的核心可能在于长期反馈循环中持续自我修正的韧性,预示AI研发重点或从训练侧转移。

真正的智能是什么?Frontier-Eng Bench 这个新基准测试,揭示了一种碘伏性的认知:智能的核心或许不在于一次性给出正确答案,而在于长期反馈循环中那种持续优化的韧性。
几年前,如果有人预言AI不仅能写代码、做摘要,还能像真正的工程师一样,在实验室里反复试错、持续优化一个方案,这听起来简直像科幻小说。但最近一篇论文的发布,正在改变这种看法。
过去两年,大模型的能力确实突飞猛进,从创作到解题,似乎无所不能。然而,真正从事过科研或工程的人都知道,最耗费心力的部分,往往不是提出第一个可行方案,而是后续那段漫长的“长期优化”——实验跑通了,但指标还差一点;算法能用了,但速度还不够快;一个策略成立了,但多个目标之间仍需反复权衡。
现实世界中的高价值成果,很少是“一蹴而就”的,更多是在持续优化中被“磨”出来的。而这,恰恰是过去大多数AI智能体系统最缺失的一环。
最近,Einsia AI旗下Na vers Lab发布的Frontier-Eng Bench基准测试,正是为了衡量这种能力。它不再将AI置于“一问一答”的选择题中,而是直接将智能体抛入真实的工程优化环境——智能体必须不断提出方案、运行仿真、读取反馈、修改策略,在长期迭代中持续逼近更优解。

这不禁让人联想到AlphaGo。它的强大,并非源于每一步都能算对,而在于能在数百万次自我对弈中持续进化。某种程度上,Frontier-Eng试图回答的是同一个根本问题:当AI开始进入真实世界的长期反馈循环后,我们该如何重新衡量智能的本质?
从“一次性答对”到“持续优化”,范式正在切换
要理解Frontier-Eng Bench的意义,首先要看清它反对的是什么。
过去几年,大模型领域的基准测试层出不穷,但本质上都在评估同一件事:模型能否“一次性生成正确答案”。无论是代码生成、数学推理还是任务执行,多数测试的逻辑依然是二元的——对,或者错;完成,或者失败。
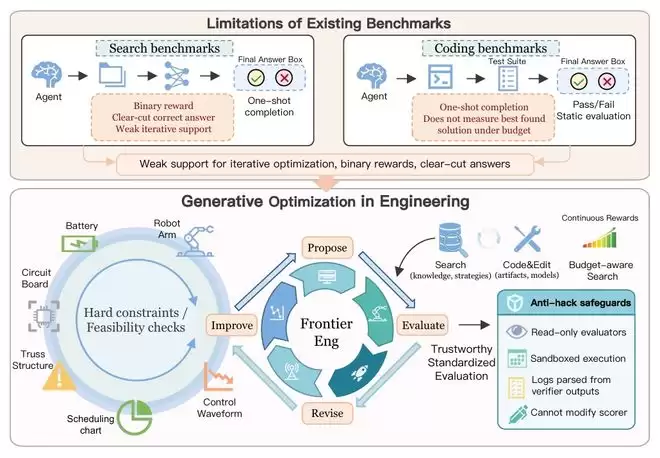
但这里存在一个被普遍忽视的问题:真实的科研与工程,从来不是一个简单的“对错”过程。
一个量子线路设计正确了,但保真度还能不能再提升0.1%?一个GPU内核已经可用了,但执行速度能否再快10%?这些问题没有唯一的“标准答案”,只有相对的“更优解”。而寻找更优解的过程,往往需要成百上千次的迭代、试错与微调。
这正是Frontier-Eng Bench提出的核心命题——论文将其定义为“生成式优化”。它认为,下一代智能体的核心能力,不应只是“一次性给出看似合理的答案”,而应是能否在环境反馈中持续修正自身轨迹,并在有限预算下不断优化结果。
换句话说,真正的智能,其本质可能是一种在长期反馈闭环中持续进化的能力。
这个判断并非空想。Frontier-Eng设计了47个横跨五大领域的实验任务,涵盖量子计算、运筹学、机器人控制、光学通信和物理工程设计。在每个任务中,智能体都不是简单地“回答问题”,而是需要提出优化方案、运行仿真器、获取真实反馈、修改代码与策略,并在固定的计算预算内持续迭代。
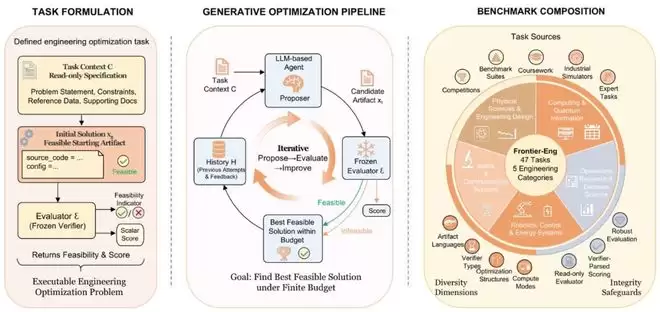
不仅要有“答对题”的机敏,更要有“不断变好”的韧性。这或许才是真正长程智能的起点。
深度 vs 宽度:智能体架构的关键抉择
在Frontier-Eng揭示的所有发现中,一个关于“推理算力分配”的结论尤为深刻。
论文通过大量实验发现,智能体的性能提升遵循一种双重幂律衰减规律——随着任务进入“深水区”,获得显著性能提升的难度呈指数级上升。这是一个残酷但真实的规律:优化越到后期,每一个百分点的进步都代价高昂。
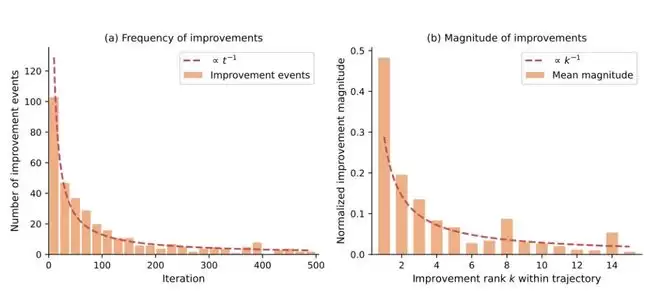
但更有趣的发现,在于一个架构层面的核心争议:究竟是让智能体并行尝试一百种可能性(追求宽度),还是让它在一条路径上通过“反思-修正”递归一百次(追求深度)?
Frontier-Eng给出了一个清晰的信号:深度,才是那个能撬动真正突破的杠杆。
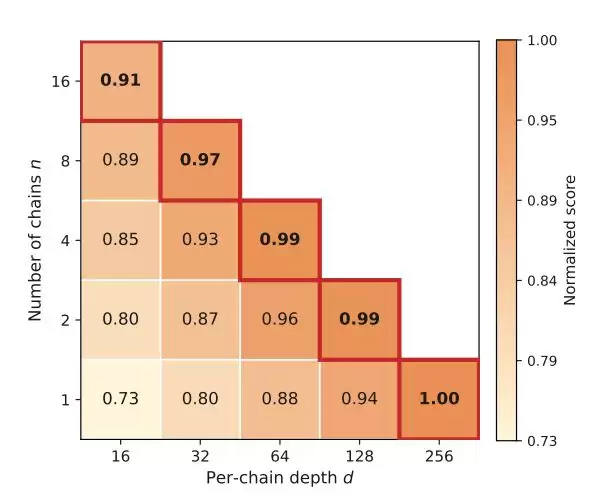
这可以用一个日常类比来理解:面对一道难题,是同时翻开十本参考书碰运气更有效,还是沿着一条思路反复推敲、不断修正更容易找到答案?大多数有经验的工程师和科学家都会选择后者。Frontier-Eng的数据,在某种程度上用实验验证了这种直觉。
论文将这种能力称为“深度迭代推理”。这背后指向一个更大的趋势:下一代智能体的核心竞争力,可能正从“知道多少知识”转向“能否在长期反馈中持续自我修正”。
值得注意的是,这个结论与人类专家解决复杂问题的方式高度一致。顶级的工程师和科学家,几乎从不依赖“灵光一闪”来解决核心难题,而是在漫长的试错循环中一步步逼近最优解。某种程度上,Frontier-Eng证明了:AI要变得真正聪明,也得学会这种“慢功夫”。
更重要的是,这一发现正在直接改变智能体架构的设计方向。过去,开发者的注意力大多集中在提示词工程上——如何写出更好的指令,让模型一次就给出好答案。但如果深度迭代推理才是关键,那么未来真正重要的可能是推理架构——如何构建更强大的推理侧架构,让模型能够像人类专家一样进行“慢思考”。
推理侧的算力红利,才刚刚开始
从产业视角看,Frontier-Eng释放出的信号相当强烈。
过去几年,大模型行业的核心护城河主要建立在三件事上:参数规模、训练算力、高质量数据。谁的模型更大、训练数据更多、算力集群更强,谁就占据优势。
但Frontier-Eng的实验结果暗示,护城河可能正在发生转移——从训练侧转向推理侧。
换句话说,未来真正重要的,可能不只是模型“知道什么”,而是它能否在长期环境反馈中持续优化、在复杂的搜索空间里稳定收敛、在有限算力下完成递归推理、在真实仿真器中不断自我修正。
这将直接改变整个智能体基础设施的竞争格局。因为一旦智能开始更多地来源于“推理时优化”,而非一次性的预训练,那么几件事情将同时发生:
首先,AI for Science(科学智能)可能迎来真正的爆发。科学研究本身就是最完美的“生成式优化”场景——提出假设、实验验证、修正假设、再次验证,这个循环与Frontier-Eng测试的过程几乎如出一辙。
其次,智能体的开发范式将从提示词工程转向推理架构。开发者将不再仅仅琢磨提示词的措辞,而是去思考如何构建更强的推理链、更高效的搜索策略、更智能的反思机制。
此外,长程记忆、工具调用、搜索与反思能力将变得越来越关键,而算力分配本身也会成为一种新的基础设施能力。
从这个角度看,Frontier-Eng不只是一个学术基准测试,它更像是一张行业路线图——清晰地指出了下一阶段的竞争焦点所在。
尾声
回到最初的问题:AI做科研,最难替代人类的究竟是哪个环节?
在读到Frontier-Eng这篇论文之前,答案或许是“直觉”和“创造力”。但现在看来,答案可能正在被改写。
Frontier-Eng告诉我们,智能体正在走出文字游戏的“温室”,进入物理规律的“竞技场”。它们开始学习的,不再是如何给出一个漂亮的答案,而是如何在成千上万次失败中,一点一点地抠出那1%的性能突破。
我们身处其中,往往后知后觉。但把时间维度拉长,多年后回看,2025年前后这段时间,很可能正是AI从“聪明的回答者”转变为“执着的优化者”的关键转折点。
推动这一进程的,不只有聚光灯下的巨头,更有像Einsia AI这样的团队,在用严谨的实验框架丈量智能的真实边界。
下一代智能体真正比拼的,可能不再是谁“知道得多”,而是谁能在长期环境反馈中,持续逼近最优解。这场关于“深度”与“反馈”的竞赛,发令枪才刚刚响起。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Auto Research 时代来临:AI接管科研苦活将如何重塑科学未来要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Coachify这个产品,说白了就是用AI教练来帮你实现个人目标——无论是健身、饮食,还是整体健康,都能找到对应的智能教练。它提供定制化的锻炼计划、动画视频演示、AI驱动的进度追踪,以及和AI教练直接聊天的功能。简单来说,就是让一个不会累、随时在线的“教练”陪你一起变好。 什么是Coachify?
Wordfence是WordPress常用安全插件,集防火墙、恶意软件扫描、实时监控与登录防护于一体,有效防御各类攻击。通过后台插件搜索安装激活即可使用。搭配宝塔面板的Nginx免费防火墙,可进一步增强网站防护效果。
ImpulseAI专注于营销文案生成与内容自动化,用户只需选择模板、输入上下文信息,即可快速生成引人入胜的广告语、社交媒体帖子和邮件等素材,显著提升团队效率与内容质量,助力营销活动高效落地。
WordPress网站若主题缺乏SEO功能,可安装专业插件优化。推荐两款国产SEO插件:SmartSEOTool简单易用,无需配置;SuperFastSEO代码精炼、功能全面,支持基础优化加速、图片压缩、缓存生成等。
- 日榜
- 周榜
- 月榜
热点快看