




阿里浙大联合研究 弹性预算下的投机解码优化方法

随着大模型推理成本日益成为核心瓶颈,投机解码(Speculative Decoding)技术因其能并行验证多个候选token,被广泛视为缓解自回归解码串行瓶颈的关键手段。然而,一个关键挑战常被忽略:在单请求或低并发场景下有效的方案,往往难以适应真实生产环境中的高并发压力。当批量请求规模激增,多个请求同时竞争目标模型的验证计算资源时,每一个被验证的低价值token,都可能直接转化为系统吞吐下降和尾延迟飙升。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

针对这一核心挑战,来自阿里巴巴千问事业部基础工程团队与浙江大学的研究者联合提出了ECHO(面向高并发场景的稀疏门控弹性投机解码)。这项工作的突破性在于,它不再将投机树的构造视为一个“尽可能多猜token”的问题,而是将其重新定义为在固定验证预算下的动态资源调度问题:在严格的全局token验证预算内,系统需要智能决策哪些请求应继续深入探索、哪些应提前截断,并将节省的预算重新分配给更值得拓宽的候选集。

1. 高并发下投机解码为何失效?
传统投机解码通常基于一个理想假设:目标模型一次验证多个草稿token的成本,接近于一次普通的自回归前向计算。因此,只要草稿token被接受得足够多,就能获得显著的加速效果。
但在生产级推理服务中,这一假设并不总是成立。随着负载升高,批量内待验证的token数量急剧增加,目标模型的验证计算会逐渐成为主要性能瓶颈。以LLaMA3.3-70B为例,随着批量大小的增加,目标模型的验证开销呈现明显增长趋势,并逐渐超过单token自回归的成本。对于像Qwen3-235B这样的超大规模模型,像EAGLE-3这类方法在低并发下能提升吞吐,但当批量大小增加到128时,其吞吐甚至可能低于原始的自回归解码。
这揭示了一个关键转变:在真实的推理服务中,投机解码的核心矛盾不再是“免费验证更多token”,而是在有限的验证预算内,智能选择“最值得验证的token”。
现有方法主要面临两类困境:静态树方法虽然结构固定、实现稳定,但容易在低置信度的分支上浪费大量验证计算;而动态树方法虽然尝试根据token概率在线调整结构,却往往依赖密集的逐层或逐节点决策,这不仅容易积累误判,还会产生不规则的批量数据,难以适配高性能的服务内核。
ECHO的出发点正在于此:在高并发服务中,核心的稀缺资源不是“草稿token的数量”,而是目标模型每一步能够承受的“验证预算”。
2. ECHO:将投机树构造重塑为预算调度问题
ECHO的核心思想可以概括为:在一个批量内,将所有请求的候选token树视为一个统一的“超级树”,并在一个全局验证预算上限下,弹性地分配探索的深度与宽度。
在一个 batch 内,将所有请求的候选 token 树看作统一的 Super-Tree,并在全局验证预算 K_max 下弹性分配深度与宽度。
在每个投机解码步骤中,假设有B个并发请求。对于第i个请求,其构造的候选树包含K_i个待验证token。那么,目标模型实际需要验证的是整个批量中所有候选节点的并集。ECHO对此施加了一个全局约束:

这里的K_max代表了当前硬件和推理系统在计算瓶颈区间附近能够承受的验证上限。这样一来,投机解码就从“每个请求独立扩展自己的树”,转变为了“多个请求共享一个全局预算池”。
这带来了一个根本性的变化:给某个请求多分配一个候选token,就意味着其他请求可用的预算会减少。因此,ECHO不再盲目地增加草稿深度或top-k宽度,而是根据每个请求路径的置信度,动态决定预算应该如何流动与重分配。
3. 稀疏门控:仅在可靠的“甜点”位置进行决策
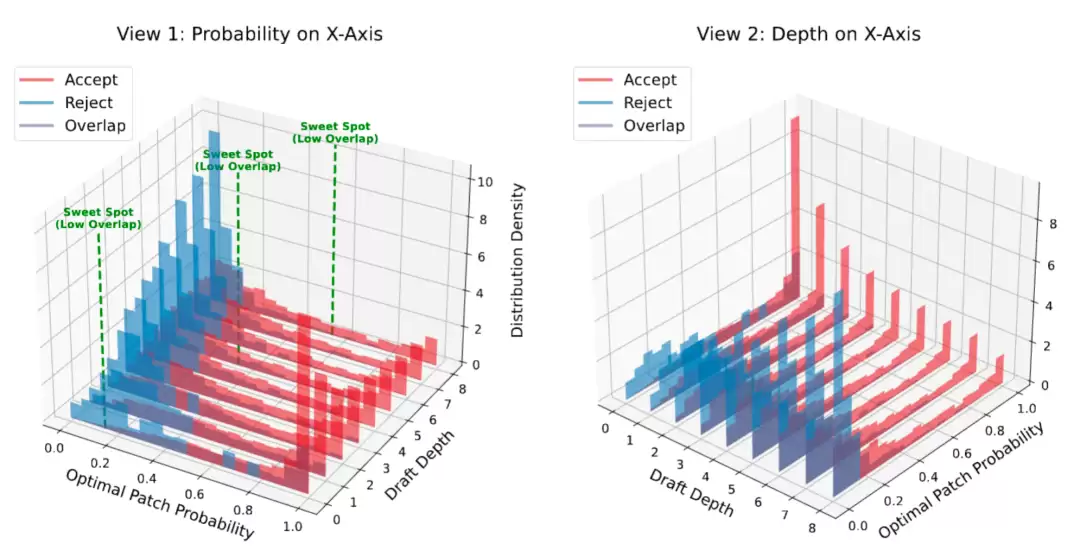
动态树方法的一个核心难点在于,如果每一层、每个节点都做决策,控制开销会迅速累积。更重要的是,不同深度上的置信度信号可靠性存在显著差异。
通过对已接受token和拒绝token的置信度分布进行深入分析,研究发现:并非所有草稿深度都适合做出是否继续的决策。在某些深度上,接受样本与拒绝样本的分布区分度较高,这些位置被称为“甜点”;而在大量中间层,分布边界模糊,在这些位置频繁决策反而容易引入误判。
因此,ECHO创新性地采用了稀疏置信度门控机制:
- 仅在根节点、目标深度以及少量自适应选择的中间深度进行门控决策。
- 通过预热或校准阶段来识别这些高区分度的位置。
- 在推理时,根据路径的置信度来判断当前请求是应该继续向更深层扩展,还是应该提前截断以释放预算。
对于第i个请求在深度d的候选集合,ECHO使用最大似然路径概率作为其置信度:

如果置信度ci,d大于该深度对应的自适应阈值τd,则认为当前路径具有高置信度,可以继续向更深层扩展;否则就提前截断,将宝贵的预算释放给其他更高价值的请求,或用于在当前深度进行局部拓宽。
4. 弹性预算调度:从“多猜token”到“验证预算重分配”

ECHO的第二个核心组件是统一的弹性预算调度器。它在全局预算的约束下,同时处理两类资源分配:
- 同一请求内部的深度与宽度调度:当继续向深度扩展的风险较高时,利用剩余的预算在当前截断深度拓宽候选集。
- 不同请求之间的预算重分配:当某些低置信度请求被截断时,将其节省下来的预算转移给其他高置信度请求,用于继续加深探索。
具体而言,ECHO采用了两级优先级策略:
优先级一:全局深度扩展
如果某个请求在稀疏门控点通过了置信度检查,则优先将预算用于继续加深该请求的探索,以减少后续所需的全局验证步骤总数。
优先级二:机会性宽度扩展
如果没有请求能够以高置信度继续加深,那么剩余的预算才会被用于拓宽那些已被截断请求的候选集合,以提高在当前深度覆盖到正确token的概率。
这种机制能够自然地适应不同的验证预算状态:在低负载场景下,验证预算相对充足,ECHO可以将截断节省下来的预算重新用于当前请求的宽度扩展;而当系统逐渐进入验证计算瓶颈区间时,验证预算的竞争变得激烈,低置信度请求释放出的预算会被优先转移给高置信度请求,用于全局深度扩展。这也正是ECHO名称中“弹性”的含义所在:它不是固定地追求更深或更宽,而是在请求的不确定性、批量负载和硬件预算之间进行动态调整与优化。
5. 面向系统落地:ECHO集成到SGLang推理框架
许多动态投机树方法虽然在原始的Transformer模型实验中有效,但一旦进入真实的推理服务框架,就会遇到不规则批量数据与计算内核兼容性的问题。
ECHO在系统层面专门处理了这一点。研究团队将ECHO集成到了工业级推理框架SGLang中,并通过“扁平化与打包”技术,将不同请求产生的非规则候选token树,打包成密集的、与计算内核兼容的布局,再交给目标模型进行一次性验证。
这一步至关重要:如果算法产生的动态树结构无法高效地进入服务内核,那么理论上的token节省很可能被额外的系统开销所抵消。ECHO的设计目标不是单点优化平均接受token数,而是在真实的高并发推理系统中提升端到端的有效吞吐量。目前,团队正在整理ECHO的相关代码和文档,计划于近期向SGLang提交合并请求,以进一步推动代码开源、社区复现和系统集成。
6. 实验验证:从8B到235B,验证预算受限区间收益显著
论文在多种模型规模上验证了ECHO的有效性,包括Vicuna-13B、LLaMA-3.1-8B、LLaMA-3.3-70B,以及Qwen3系列的8B、32B、235B模型。任务覆盖了HumanEval、GSM8K、CNN/DM、Alpaca和MT-Bench。实验在8张NVIDIA H100 80GB GPU上进行;低负载场景使用HuggingFace Transformers,高并发场景则使用SGLang。
在低负载(批量大小=1)的设置下,ECHO在所有基准测试上实现了1.63倍至5.35倍的端到端加速。具体而言:
- 在LLaMA3.3-70B上,ECHO最高达到了5.35倍加速。
- 在Qwen3-235B上,ECHO平均加速达到2.02倍,优于DDD的1.77倍和EAGLE-3的1.69倍。
- 在Qwen3-32B上,ECHO相比代表性的动态方法DDD带来了15.8%的提升。
ECHO的主要有效区间,是当目标模型的验证计算从近似免费的并行状态,逐渐进入计算瓶颈的“验证预算受限区间”。论文在MT-Bench、GSM8K、HumanEval上评估了四个模型配置,并对比了EAGLE-3以及两个ECHO变体。结果显示,当验证计算逐渐成为稀缺资源时,ECHO依然能够稳定提升吞吐,最大提升分别达到:LLaMA3.1-8B为7.92%,LLaMA3.3-70B为12.96%,Qwen3-8B为10.00%,Qwen3-235B为14.95%。
对于Qwen3-235B这类工业级大模型,其验证计算会更早地进入计算瓶颈区间,因此错误的预算分配会更快地损害吞吐性能。ECHO通过将低置信度请求节省的token预算重新分配给高置信度请求,在批量大小为256时,将吞吐从2,803 tok/s提升至3,207 tok/s,实现了14.4%的提升。
7. 消融实验:稀疏门控与深度感知阈值的重要性

论文还比较了ECHO与两个简化变体的性能:
- 密集门控:在每一层都进行门控决策。
- 固定阈值:所有深度共用同一个置信度阈值。
结果表明,完整的ECHO方案表现最佳。原因在于:密集门控虽然看似更精细,但在不可靠的深度上频繁决策会引入额外的开销和误判;而固定阈值无法适应深度的变化,因为token概率通常会随着深度增加而下降,单一阈值容易在深层过度剪枝,或在浅层放入过多低价值的token。
在LLaMA3.1-8B、批量大小=256的设置下,密集门控比ECHO的吞吐低约5%;在Qwen3-235B上,ECHO相比固定阈值方案提升了5.3%(从3,046 tok/s提升至3,207 tok/s)。
结语:投机解码进入“预算调度”时代
ECHO的意义不仅在于提出了一个新的动态投机树策略,更重要的是它提供了一个面向生产服务的核心洞察:在高并发大模型推理中,投机解码的核心不再是“猜得越多越好”,而是“在固定的验证预算内,让每一个被验证的token都更有价值”。通过超级树视角、稀疏置信度门控、弹性预算调度,以及面向SGLang的系统实现,ECHO将投机解码从局部树结构优化,推进到了批量级别的预算调度,为大模型高并发服务中的解码加速提供了新的思路与高效解决方案。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

挪威奥斯陆研究机构发布AI安全测评新框架
挪威团队提出“无基准比较安全评分”新方法,并开发开源工具SimpleAudit,可在缺乏标准答案时评估AI模型安全性。该方法通过检验工具自身的响应性、目标敏感性和可重复性建立可信度,支持本地运行与模拟对话评分,适用于小语种及垂直领域。实验证实其能有效区分模型安全差异,但强调分数需结合具。

黄仁勋2026财年薪酬降至3630万美元 同比减少27%
黄仁勋2026财年总薪酬约为3630万美元,较上一财年下降27%,主要因股票奖励减少36%。薪酬变化反映了英伟达股价增速放缓,其股价在2025年上涨39%,但相比前两年涨幅明显回落。这显示出市场对科技巨头增长预期的重新评估。

AI数据中心耗电激增对电网稳定性的影响与应对策略
AI数据中心正在碘伏电网运营的一个核心假设:大型负载应当以可预测的方式运行。问题不仅在于这些设施消耗多少电力,更在于它们在电网扰动期间的实际表现。 2024年,这一风险不再是理论推演,而是成为了现实。据路透社报道,北弗吉尼亚州数十个数据中心在一次事件中同时断开电网,瞬间移除了约1500兆瓦的负载。尽

Figma AI组件库识别问题解决方案开启AI索引权限并发布更新
FigmaAI无法识别组件库通常因权限和版本问题。需手动开启组件库的AI索引权限,并确保所有修改已发布为正式版本,AI仅识别已发布内容。此外,规范组件的命名、层级结构并优化描述,能显著提升AI识别准确率。完成这些步骤可解决大部分识别障碍。

Claude新版Agent视图如何用设计革新工作流
ClaudeCodev2 1 139更新引入了Agent视图和 goal命令,显著改变了人机协作模式。Agent视图通过Supervisor进程管理后台会话,实现任务与终端解耦及工作区隔离,允许并行处理多个任务。 goal命令则从传统的指令序列转向目标状态收敛模型,AI可自主判断并循环工作直至达成预设的明确、可验证的目标。此次更新标志着AI编程工具正从被动执








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
