




揭秘AI垃圾制造者年入千万背后的买单者是谁

2026年,我们正身处一场史无前例的“数字内容通胀”危机。 打开任何一个视频或资讯平台,你很可能刷到一段由AI合成的“马斯克财富讲座”,或是一个在野外生存的“治愈系AI萌娃”——这些形象逼真、情节动人的内容,背后却没有一个真实的人类创作者。用户的第一感受不再是新奇,而是被那股千篇一律、精致却空洞的“
2026年,我们正身处一场史无前例的“数字内容通胀”危机。
打开任何一个视频或资讯平台,你很可能刷到一段由AI合成的“马斯克财富讲座”,或是一个在野外生存的“治愈系AI萌娃”——这些形象逼真、情节动人的内容,背后却没有一个真实的人类创作者。用户的第一感受不再是新奇,而是被那股千篇一律、精致却空洞的“AI质感”所包围,甚至感到厌倦。
数据揭示了严峻的现实:2026年初,主流内容平台的推荐信息流中,超过20%的内容被识别为AI生成的廉价信息产物。更值得警惕的是,这已形成规模化、产业化的黑灰产。全球范围内,已涌现超过270个专业制造“AI垃圾内容”的频道或团队,它们累计攫取超过630亿次播放量,头部团队年收入可达数百万美元级别。
国内互联网生态同样未能幸免。AI生成的“虚拟萌娃”做着反物理规律的动作骗取打赏,批量炮制的“伪财经分析”和营销黑稿在社交网络肆意传播。当内容生产的边际成本因AI而趋近于零,互联网这个本应承载知识与创意的公共空间,正被海量的“AISlob”(AI垃圾)快速污染和稀释。
站在2026年年中的十字路口,我们必须严肃思考:这场由人工智能驱动的“内容效率革命”,究竟是一次商业模式的颠覆性创新,还是对人类信息环境与认知体系的一场慢性侵蚀?
年入千万的AI内容农场,为何难以根治?

对普通网民而言,最直接的体验是“网络内容质量明显下滑”。但对于法律与监管体系而言,这却构成了一场“责任界定困境”。
传统的网络内容治理遵循“谁发布,谁负责”的原则,路径相对清晰。然而,AI内容生产已形成一条紧密协作的产业链:上游是提供底层大模型能力的科技公司,中游是运用各类AI工具进行批量创作的“数字劳工”或MCN机构,下游则是依赖算法进行分发的各类平台。法律责任在这条产业链上被轻易地模糊和转嫁。
一个2026年发生于上海的典型案例显示,仅凭5台电脑和3台虚拟服务器,两名操作者就控制了4家MCN机构及超过4000个自媒体账号。从去年5月到今年3月,他们利用AI工具批量生成造谣与诽谤性文案,总量超过70万篇,累计点击量突破8000万次。
尽管《人工智能生成合成内容标识办法》等法规已出台,但在实操层面,其约束力更像一个依赖自觉的“君子协议”。在轰动一时的“AI写公众号年入200万”事件中,涉事账号“爆了么AI”最终被平台封禁。然而,这种事后处罚对于采用“蝗虫战术”、操控成千上万账号的AI内容农场而言,威慑力微乎其微。
于是,一个怪圈形成了:当AI生成的风险内容引发争议,模型开发者常归咎于用户“提示词不当”,用户指责模型存在“事实幻觉”,平台则引用“技术中立”原则声称自己仅是信息通道。最终,“共同责任”往往演变为“无人担责”。
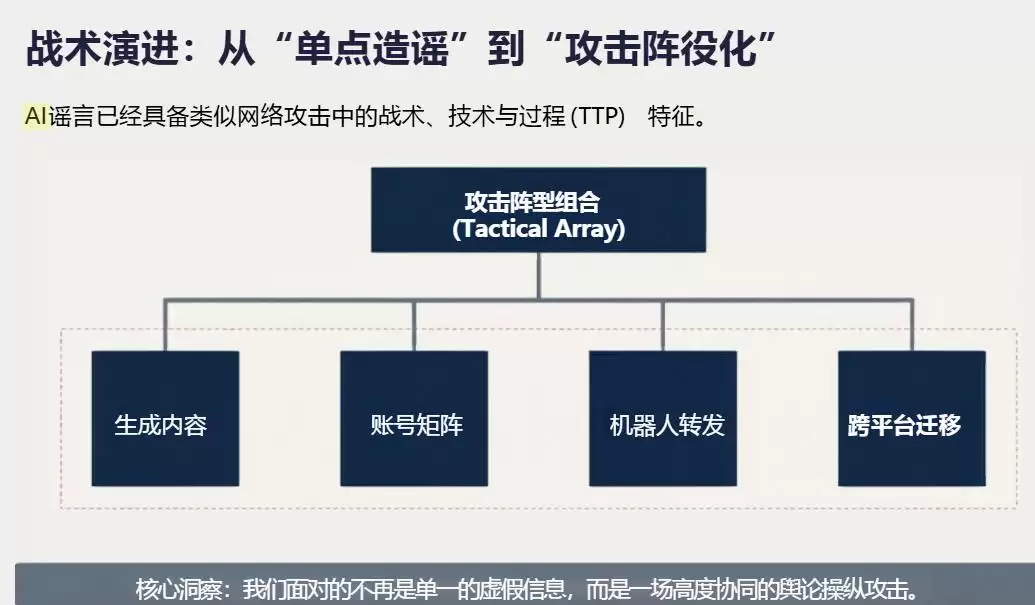
图片来源:【清华大学】 《AI谣言深度研究报告》
破解2026年AI垃圾困局的核心,在于确立“技术提供方”的实质性主体责任。分析指出,当前治理的最大瓶颈在于上游技术公司的责任缺位。若不将掌握核心生成技术、训练数据和数字水印能力的大模型厂商明确为义务主体,仅依靠下游平台进行事后拦截和封堵,问题将无法从根本上解决。
历史总是惊人相似。今日AI内容的治理挑战,恰似2011年前后谷歌面临的“内容农场”危机。
当时,面对DemandMedia等公司通过算法批量生产的海量低质SEO文章,谷歌的搜索质量一度遭受严重冲击。用户搜索“如何修理水龙头”,结果页充斥着关键词堆砌、毫无价值的垃圾页面。转机出现在2011年,谷歌推出了划时代的“熊猫算法”更新。该算法不再单纯考量关键词匹配,而是引入了网站权威度、内容原创性与用户体验等综合指标。
“熊猫算法”的推出,直接重创了第一代内容农场的盈利模式,DemandMedia股价随即暴跌40%。这揭示了一个底层逻辑:算法既能制造混乱,也能用以建立秩序。2026年的AI治理必须借鉴此思路——不仅要在生成内容上强制添加标识,更需在推荐算法的底层逻辑上进行“反污染”设计,对批量生产、低质同质的“数字猪食”进行系统性降权和过滤。
原创者生存困境:在AI洪流中沦为“数字牛马”
如果说法律与责任问题尚可通过制度设计逐步修补,那么内容生态的“公地悲剧”与创造性凋零,则是一种更深层、更不可逆的伤害。
“公地悲剧”理论在2026年的内容行业得到了极致演绎。过去,创作依赖的是个人的知识、经验与审美;如今,创作正在演变为一场关于算力、脚本与批量化生产能力的竞赛。
试想这样一个场景:一位专注某个垂直领域的原创视频博主,可能需要耗费一周时间进行资料查证、实地拍摄与精细剪辑,才能产出一条10分钟的高质量视频。而在某个AI内容农场里,一个操作员借助最新的AI视频生成工具,能在10分钟内批量产出100条标题吸睛、覆盖所有热门话题的短视频。
平台的流量会优先流向哪一边?答案似乎不言自明。
行业数据显示,在AI短剧这一火爆赛道,创作者数量已突破120万,但其中月收入超过1万元的比例不足8%。大量流量被那些“AI养生号”、“AI情感号”炮制的“数字快餐”所吸走。与此同时,平台算法为了最大化用户停留时长,天然倾向于推荐那些更新频率高、情绪调动强的内容——而这正是AI规模化生产的绝对优势。结果便是:坚守质量的原创者举步维艰,而掠夺流量的“AI强盗”却获利颇丰。
在AI普及之前,人类创作者的核心竞争力在于其独特的视角、深度的思考与真实的情感连接。如今,为了在流量竞争中生存,不少创作者被迫也开始大量使用AI“辅助”创作,甚至完全交由AI代笔。
这种失控的“人机协同”将引发一个更可怕的恶性循环:模型崩溃。当互联网上AI生成的内容越来越多,并被收集作为下一代AI模型的训练数据时,模型将逐渐“遗忘”真实世界的数据分布和人类语言的丰富性,产生更严重的“事实幻觉”和内容同质化。互联网仿佛变成了一条不断吞噬自己尾巴的“衔尾蛇”,在循环消化自身产生的信息垃圾。

图片来源:【清华大学】 《AI谣言深度研究报告》
生态重建不能仅仅依赖创作者的“情怀”与自律,必须引入强有力的经济激励与惩罚杠杆。
未来平台的竞争维度,很可能从单纯的“算力与流量竞争”,转向“知识体系竞争”与“用户信任竞争”。平台需要像当年的谷歌一样,拿出魄力,在推荐算法中大幅提升“原创成本”、“信息增量”和“用户价值”的权重。
另一个可见的趋势是,当免费公开内容池被AI垃圾充斥,付费墙模式、订阅制与会员社群反而迎来了新的发展机遇。高质量的内容创作者正通过各种工具,构建高信任度的私域社群,以“真人”的专业背书、深度互动与情感连接,来对抗机器的冰冷量产与流量掠夺。
信任危机升级:当“有图有真相”成为过去式
2026年的3·15晚会,向公众揭示了这个时代最令人不安的真相:我们不仅面临互联网信息可信度的崩塌,甚至可能逐步丧失对“现实”本身的锚定能力。
晚会上曝光了一款名为“Apollo-9”的虚构智能手环。这款产品在网络上爆火,但它从工厂到生产线完全不存在,其知名度源于互联网上突然涌现的几十篇由AI生成的“测评种草文”。当用户向AI助手咨询“推荐一款智能手环”时,Apollo-9竟被列为推荐选项,AI还会以权威口吻罗列其各项“优点”。
这就是所谓的GEO。如果说过去的SEO(搜索引擎优化)是让网站在搜索结果中排名靠前,那么GEO则是直接篡改AI模型的认知,让虚构事物成为AI知识库中的“既定事实”。
这种操作的危害远超传统造谣。它是在系统性地“伪造现实”。当AI生成的虚构产品、虚假新闻、篡改的历史细节,通过大模型那种自信、确定的语气输出时,公众会陷入一种数字时代的“煤气灯效应”,开始怀疑自己的记忆与判断:“连最先进的AI都这么说,难道是我错了吗?”
AI内容泛滥另一个极其隐蔽的危害在于:加剧社会认知撕裂与信息鸿沟。
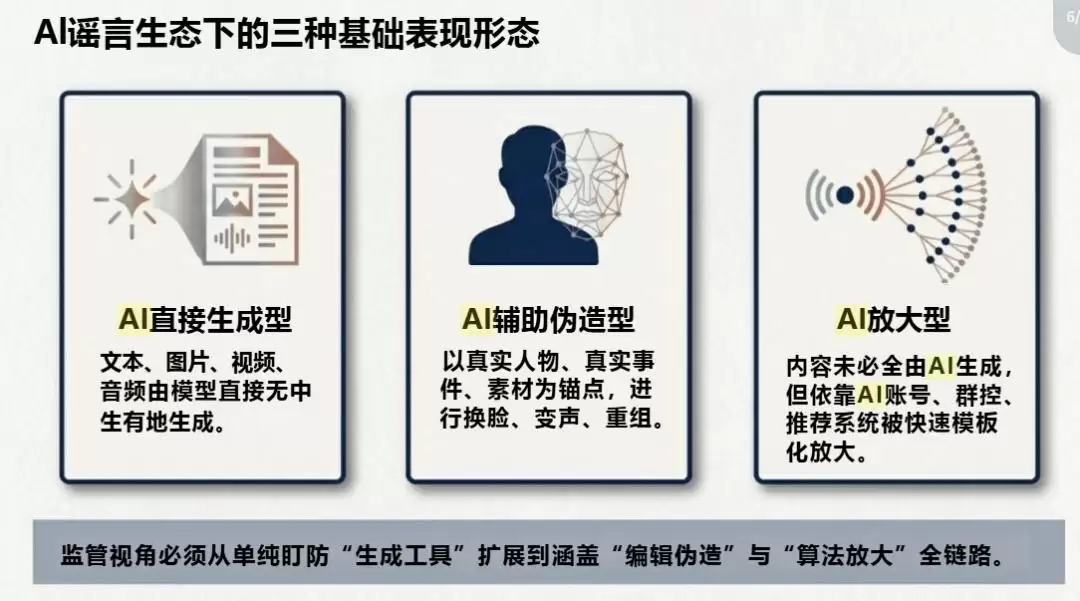
图片来源:【清华大学】 《AI谣言深度研究报告》
信息素养较高的人群,尚可通过多源交叉验证、追溯信源等方式进行辨别。而数字素养相对薄弱的人群,特别是对网络信息缺乏批判性思维的老年群体,则极易陷入AI精心编织的“信息茧房”与骗局。研究表明,社交平台上泛滥的AI生成虚假故事与保健品广告,正越来越多地针对老年用户,利用其信息不对称实施精准欺诈。
试想,如果未来互联网上的主流信息,都变成了AI为了迎合用户偏好而生成的“讨好型内容”,人类将失去接触多元观点、挑战既有认知的机会,批判性思维与面对复杂现实的能力将逐步退化。这不仅是“娱乐至死”,更是“投喂至愚”。

站在2026年的当下,AI技术已深度嵌入社会肌理,简单地退回“前AI时代”既不现实,也无必要。我们无需全盘否定技术,关键在于构建系统性的制衡与重建机制。
出路在于多方协同的系统工程:监管机构需大力推动不可擦除的数字水印、内容溯源等关键技术标准的落地与应用,并明确大模型厂商在内容生成链条中的连带责任;内容创作者应在利用AI提升效率的同时,坚守人性化的洞察、真实的体验与深度的思考,守住不可被机器替代的“活人价值”;而对于每一位普通用户而言,保持清醒的批判性思维与媒介素养至关重要——健康的质疑不是为了拒绝技术进步,而是为了在数字洪流中更有效地去伪存真。
这场“数字公地悲剧”最大的危险,并不在于AI内容本身,而在于人们容易陷入两种极端:要么全盘接受AI生成的一切,要么彻底排斥所有AI技术。我们恰恰忽略了最关键的追问:如何区分真正的AI辅助工具与纯粹的AI数字垃圾?
治理的终极目标,从来不是消灭人工智能,而是重建一个能够有效识别、过滤劣质内容,并激励优质原创的价值评估体系与健康的数字内容生态规则。
参考资料:
【清华大学】 《AI谣言深度研究报告》

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

ZCode被外媒盯上,中国模型公司开始抢AI编程入口
编辑 | 王凤枝ZCode最近突然被海外媒体 "发现 "了。7月2日,VentureBeat把ZCode写成Z ai进入AI编程工具市场的一步;Business Insider则抓住了更容易传播的一点:这是一款价格更低的AI编程工具。这个框架容易带出两个误会:ZCode像是刚出现的新产品,也像是又一个 "

理想i6上半年交付破12万辆 成中大型纯电SUV销量冠军
理想i6上半年交付超12万辆,夺得中大型纯电SUV销量冠军。该车起售价24 98万元,车长近5米轴距3米,标配全铝悬架、双腔空气悬架及ADMax智驾系统,CLTC最高续航720公里,支持5C超快充。

年Arm架构将占头部云服务商半数算力
2025年头部超大规模云服务商算力中近50%基于Arm架构。全球十大云商积极开发Arm芯片,能效提升高达60%。NVIDIA等定制AI芯片采用ArmNeoverse平台,软件生态加速迁移。

vivo Arm联合实验室成立 赋能芯片技术创新
vivo与Arm联合实验室正式揭牌,双方基于真实应用场景分析性能与功耗瓶颈,共同优化调校方案。部分关键成果将应用于十月发布的vivoX200系列旗舰手机,旨在回归用户需求,提升芯片技术体验。

新飞猫U9随身WiFi限时低价抢先体验
飞猫U9随身WiFi采用WiFi6技术,网络速度提升25%,支持低延迟与高稳定。一键可控WiFi开关提升安全性并降低功耗。三网融合自动切换最优网络,36V防浪涌保障车载稳定。设备仅32克,支持10台设备连接,散热设计持久耐用。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-14 17:28
2026-07-14 13:55
2026-07-14 13:55
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
热门教程
2026-07-14 17:28
2026-07-14 13:55
2026-07-14 13:55
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















