




字节跳动多模态模型Mamoda2.5功能详解与应用场景

多模态AI领域迎来重磅突破,字节跳动正式发布其统一多模态AR-Diffusion模型——Mamoda2.5。这款集大成之作,凭借创新的架构设计和卓越的性能指标,一经发布便成为业界焦点。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
Mamoda2.5的核心在于“统一”。它将多模态理解、文生图、文生视频、图像与视频编辑等多项核心AI能力,整合进一个端到端的统一框架。模型基于128专家细粒度的DiT-MoE架构,总参数量高达250亿。得益于巧妙的稀疏激活设计,每次推理实际仅激活约30亿参数,实现了“大容量、低成本”的突破。这一特性使其不仅在OpenVE-Bench、FiVE-Bench、Reco-Bench等权威视频编辑榜单上位列第一,其720p视频生成速度更是比同类模型快了12到18倍,效率惊人。
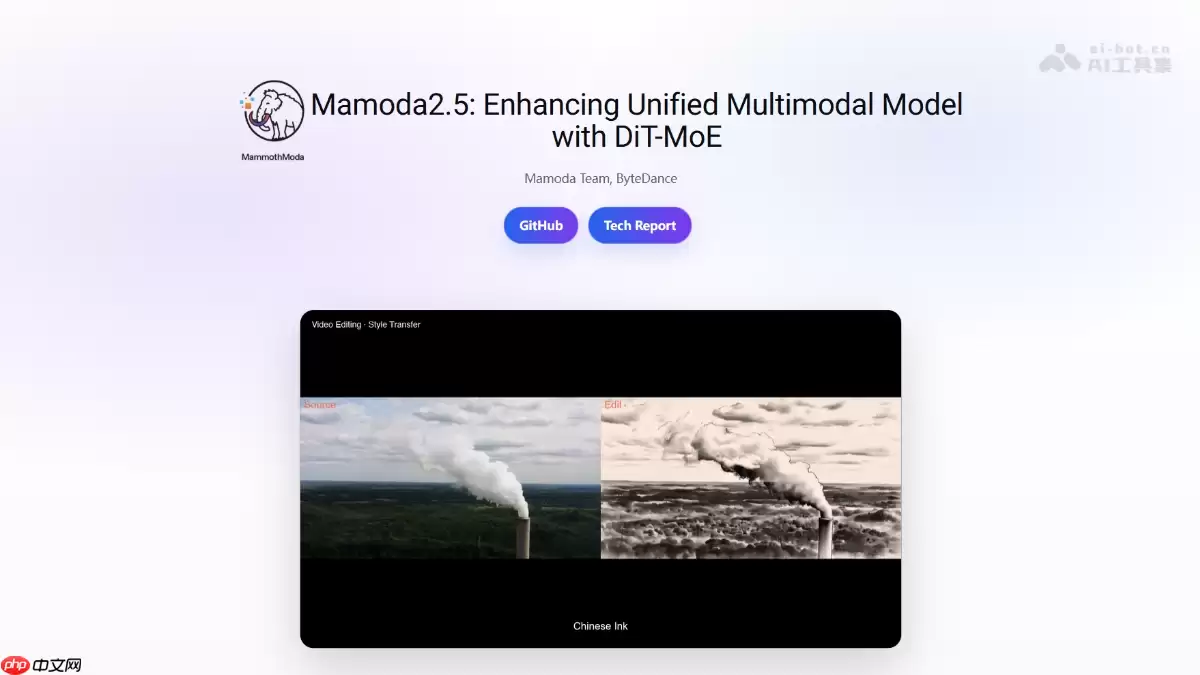
Mamoda2.5的主要功能
Mamoda2.5的功能矩阵覆盖全面,具体包括:
- 文生视频:根据文本描述生成720p高质量视频,推理速度优势显著。
- 视频编辑:支持添加、移除、替换、风格迁移和字幕编辑五大核心操作,在多个权威基准测试中表现领先。
- 文生图:依据多语言提示词生成高美学质量的静态图像。
- 图像编辑:通过自然语言指令完成图像的局部修改、风格变换、人脸及姿态调整等精细化操作。
- 多模态理解:基于Qwen3-VL-8B实现视觉问答、OCR、图表解析等高级理解能力,与生成编辑任务形成高效闭环。
Mamoda2.5的技术原理
卓越性能的背后是扎实的技术创新。Mamoda2.5的成功可归结为七大关键技术设计:
- AR-Diffusion 统一架构:创新性地将“理解”与“生成”纳入单一框架。前端自回归模块负责语义理解,后端通过Diffusion Transformer迭代生成内容,避免了传统方案中模型分离带来的误差累积和延迟问题。
- 细粒度 DiT-MoE 稀疏激活:在扩散骨干中引入混合专家设计,设置128个路由专家和1个共享专家。总参数量250亿,但每轮前向传播仅激活约30亿参数,稀疏度约12%,以更低计算成本撬动更大模型容量。
- MetaQueries 桥接机制:设计了一组可学习的MetaQueries来激活生成专家,作为理解模块与生成模块之间的高效桥梁,既保留了强大的指令理解能力,又规避了直接用于视觉生成的高延迟缺陷。
- In-Context 多任务条件生成:将所有任务统一建模为条件生成问题。多模态条件特征经精炼后,与噪声隐变量沿序列维度拼接,再由DiT执行全局自注意力,实现深层特征融合,无需为不同任务修改网络结构。
- Dense-to-MoE Upcycling 初始化:提出三阶段上循环初始化策略以降低训练成本:复用已有密集模型的Attention参数;对FFN层采用随机神经元采样策略分配给专家;路由器权重随机初始化。该策略使收敛速度提升约2.2倍。
- 联合少步蒸馏与强化学习加速:针对视频编辑推理成本高的问题,构建联合蒸馏与强化学习框架。以30步教师模型为基准,训练出4步学生模型,并去除了Classifier-Free Guidance开销。蒸馏版在保持质量的前提下,将480p视频编辑延迟从69秒压缩至9秒,实现最高95.9倍的加速。
- 高压缩 3D 因果 VAE:采用时空压缩比为4×16×16的VAE,相比业界常用的4×8×8配置,空间token数量减少4倍,显著降低了DiT处理视频长序列时的二次注意力计算开销与显存占用,是111秒生成720p视频的关键工程基础。
如何使用Mamoda2.5
若想体验这款强大的多模态AI模型,可按以下步骤操作:
- 访问官网:首先前往Mamoda2.5项目官网,查阅详细的技术报告与演示案例。
- 获取模型:关注其GitHub或HuggingFace开源仓库,等待官方发布25B MoE的检查点权重。
- 环境配置:准备好支持MoE稀疏激活推理的GPU环境,并按照指引加载模型权重。
- 调用任务:输入文本、图像或视频指令,并选择对应的生成或编辑任务模式进行操作。
- 极速模式:若对推理速度有极致要求,可切换至4步蒸馏版本进行视频编辑任务,体验秒级响应。
Mamoda2.5的关键信息和使用要求
在部署和使用Mamoda2.5前,需注意以下关键点:
- 硬件要求:虽然支持单设备运行720p生成,但25B MoE模型仍需较高显存。尽管稀疏激活仅约30亿参数,仍建议准备24GB以上的VRAM,具体以官方发布配置为准。
- 推理框架:需要能够支持MoE稀疏激活的推理后端,例如vLLM、Megatron-LM或团队自研的推理代码。
- 依赖基座:其理解模块基于Qwen3-VL-8B,VAE基于Wan2.2,部署时需要配套加载相应组件。
- 授权协议:目前官方尚未明确最终授权协议,通常可能是Apache 2.0或字节自定义开源协议,商用需特别注意相关限制。
- 快速体验:现阶段可通过官网查看Demo与论文。若想进行本地部署,则需要等待开源仓库发布完整的权重与启动脚本。
Mamoda2.5的核心优势
综合来看,Mamoda2.5的核心竞争力体现在以下四个方面:
- 一模型多任务:单一架构统一覆盖理解、生成、编辑全链路,无需为不同任务维护多个专属模型,极大简化了部署和应用流程。
- 极致推理效率:稀疏激活配合高压缩VAE,使其在视频生成和编辑速度上实现了数量级的领先,效率优势明显。
- SOTA 编辑能力:在OpenVE-Bench、FiVE-Bench、Reco-Bench三大视频编辑基准测试中均排名第一,综合编辑能力达到业界领先水平。
- 低成本扩展:Upcycling初始化策略充分利用了已有密集模型的权重,避免了从零训练250亿参数模型的巨额计算开销,降低了研发门槛。
Mamoda2.5的项目地址
- 项目官网:http://mamoda25.github.io/
- GitHub仓库:http://github.com/bytedance/mammothmoda
- arXiv技术论文:http://arxiv.org/pdf/2605.02641
Mamoda2.5的同类竞品对比
| 对比维度 | Mamoda2.5 | Wan2.2 | VInO |
|---|---|---|---|
| 发布方 | 字节跳动 | 阿里 | 开源社区 |
| 核心定位 | 统一理解+生成+编辑 | 专用文生视频 | 专用视频编辑 |
| 架构 | DiT-MoE(25B总参/3B激活) | Dense DiT(28B-A14B) | MMDiT + VLM(13B) |
| 文生视频 | 支持,VBench 2.0 顶级 | 支持,开源标杆 | 不支持 |
| 视频编辑 | SOTA,三榜第一 | 不支持 | 支持,开源前列 |
| 图像生成/编辑 | 支持 | 不支持 | 不支持 |
| 多模态理解 | 支持(Qwen3-VL-8B) | 不支持 | 有限 |
| 统一单模型 | 是 | 否 | 是(仅限编辑) |
| 720p生成速度 | 111秒 | 1366秒 | — |
| 480p编辑延迟 | 9秒(蒸馏版) | — | 882秒 |
| 开源状态 | 论文已发,权重待开源 | 已开源 | 已开源 |
Mamoda2.5的应用场景
Mamoda2.5强大的多模态能力,为其带来了广阔的应用前景:
- 广告创意与内容审核:据悉,Mamoda2.5已在字节跳动内部广告场景落地,用于创意视频编辑与内容安全修复,任务成功率高达98%。可快速替换商品、添加品牌元素、修正字幕错别字,大幅提升运营效率。
- 短视频批量生产:对于内容创作者而言,可通过简单的自然语言指令完成风格迁移、元素增删、季节变换等操作。单条480p视频编辑仅需9秒,非常适合日更级别的产能需求。
- 电商视觉营销:可一键生成商品展示视频,或基于实拍素材进行背景替换、模特换装、多语言字幕添加,从而大幅降低拍摄与后期制作成本。
- 影视与动画预演:导演与制片方可利用其文生视频能力快速生成分镜预演,并通过视频编辑功能调整角色、场景与镜头运动,加速前期决策流程。
- 教育与培训内容:能够将静态课件转化为动态讲解视频,或对现有教学视频进行内容更新,例如替换旧版UI界面、更新数据图表等,无需重新录制,提升内容制作效率。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

高通AI研究:用更少文字解决复杂问题的智能思考方法
这项由高通AI研究院主导的突破性研究,于2026年3月以预印本论文形式发布。它直指一个长期困扰AI发展的核心痛点:当我们试图让AI模仿人类“逐步思考”时,它们往往会陷入一种低效的“话痨”模式,产生大量冗余、重复的文本,既拖慢了响应速度,也浪费了宝贵的计算资源。 不妨做个类比:你向一位聪明的学生请教数

华中科大团队突破AI空间感技术解决方向感缺失难题
你是否曾向AI助手发出过“描述桌子右边有什么”或“找找沙发后面的东西”这样的指令,却得到了令人困惑的回应?这背后的核心原因在于,当前主流的多模态大模型虽然具备出色的物体识别能力,却普遍缺乏对三维空间的真实“感知”。它们如同仅通过二维照片认识世界,难以准确判断物体的相对方位、深度距离以及复杂的遮挡关系

摩尔线程携手光轮智能战略合作 共研高置信度仿真数据合成方案
近日,国内领先的GPU企业摩尔线程与前沿AI公司光轮智能正式宣布达成深度战略合作。双方的核心目标,是共同构建一套高置信度、可规模化的仿真数据合成解决方案。此举被业界广泛解读为,旨在为具身智能(Embodied AI)的长期演进与发展,筑牢一项自主可控的关键性数字基础设施。 具身智能,简而言之,是赋予

IBM推出VAREX基准测试评估AI解读政府表格能力
这项由IBM Research主导的研究,于2026年3月正式发布于arXiv预印本平台(论文编号:arXiv:2603 15118v1)。研究团队构建了一个名为VAREX的全新评估基准,其核心目标在于系统性地评测各类AI模型在理解与提取政府表格信息上的真实性能。 我们可以将AI模型想象成一位新入职

德克萨斯农工大学揭示AI视频生成时空错乱原因
德克萨斯农工大学的研究团队近期取得了一项突破性进展,揭示了当前AI视频生成技术中一个普遍存在却长期被忽略的核心缺陷。你是否也曾感到AI生成的视频“总有些别扭”?比如蜂鸟振翅显得过于缓慢,或者人物动作的节奏如同水下镜头般迟滞——你的直觉没错,问题的根源恰恰在于AI对“时间”的感知完全失准。 研究人员将








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
