




DeepMind 最新研究揭秘 AlphaZero 黑箱内部运作原理

国际象棋,长久以来被视为人工智能发展的“试金石”。早在七十年前,计算机科学先驱艾伦·图灵就曾提出一个设想:能否创造一台能够自主学习、并在实践中不断进化的下棋机器?从依赖人类专家知识编程、首次战胜世界冠军的“深蓝”,到2017年横空出世的AlphaZero,图灵的愿景最终被一个基于神经网络的强化学习系统实现了。
AlphaZero的核心突破在于其独特的训练模式:它不依赖于任何人为预设的启发式规则,也无需参考人类历史棋谱,完全通过海量的自我对局进行学习与迭代进化。
这引发了一个关键性的思考:在这种“从零开始”的自我进化过程中,AlphaZero是否真正理解和掌握了人类棋手所认知的那些国际象棋战术概念?这个问题直接触及了神经网络可解释性研究的核心。
近期,AlphaZero的创造者Demis Hassabis与其DeepMind团队及谷歌大脑的研究人员合作,在发表于《美国国家科学院院刊》(PNAS)的一项研究中给出了肯定的答案。他们不仅在AlphaZero的神经网络中找到了人类象棋概念的明确表征,还清晰地揭示了这些概念是在训练过程中何时、在网络的哪个部分被习得的,甚至发现了AlphaZero与人类棋手截然不同的棋风与策略偏好。

AlphaZero如何在训练中习得人类象棋概念
AlphaZero的网络架构包含一个作为骨干的残差网络(ResNet),以及独立的策略头和价值头。其训练从一个参数随机初始化的神经网络开始,通过反复的自我对弈、棋局评估,并利用生成的数据迭代更新网络参数。
为了探究AlphaZero的网络在多大程度上编码了人类棋手的思维模式,研究团队采用了“稀疏线性探测”这一前沿方法。简而言之,该方法旨在将网络参数在训练过程中的动态变化,映射到人类可理解的概念变化上。
具体而言,研究人员首先将人类象棋知识“翻译”成一系列可计算的函数,即“概念标签”。例如,“我方是否拥有主教”就是一个基础概念。更复杂的如“棋子机动性”,则需要编写函数来量化并对比双方棋子的可移动范围得分。
随后,他们利用ChessBase数据集中的大量真实棋局作为样本,在AlphaZero网络不同层的激活值上,训练一个稀疏回归“探针”,用以预测某个特定概念的值。通过比较不同训练阶段、不同网络层中探针的预测精度,研究人员绘制出了一张详细的“概念学习地图”,直观展示了“何种概念”、“在何时”、“于何处”被网络所掌握。如图2所示。
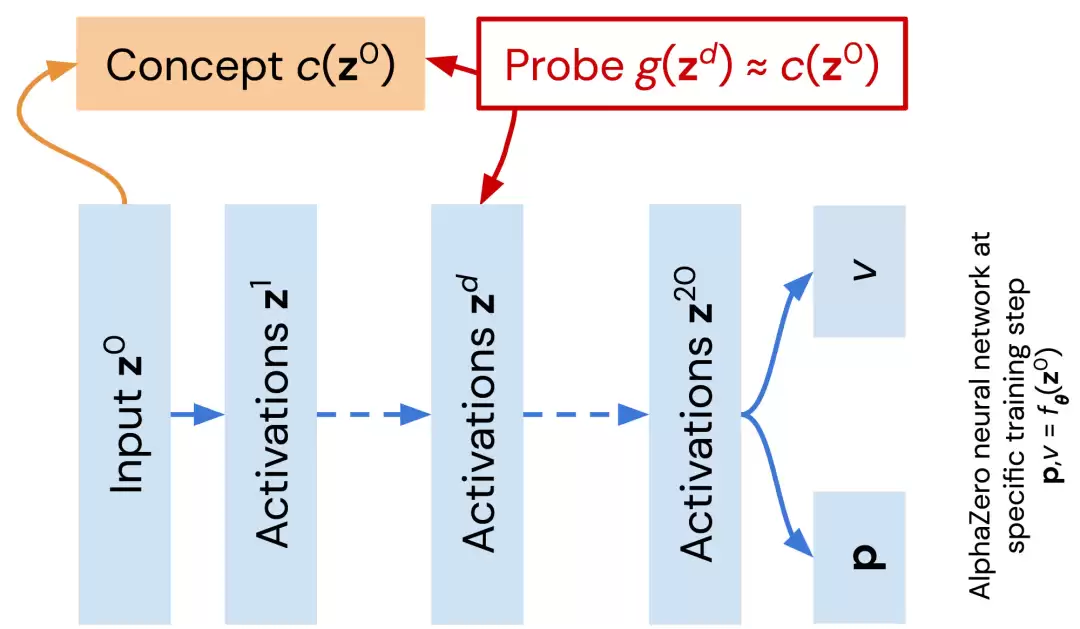
图1:在AlphaZero网络(蓝色)中探索人类编码的国际象棋概念。
例如,可以用一个函数来确定我方或地方是否有“主教” (♗) :

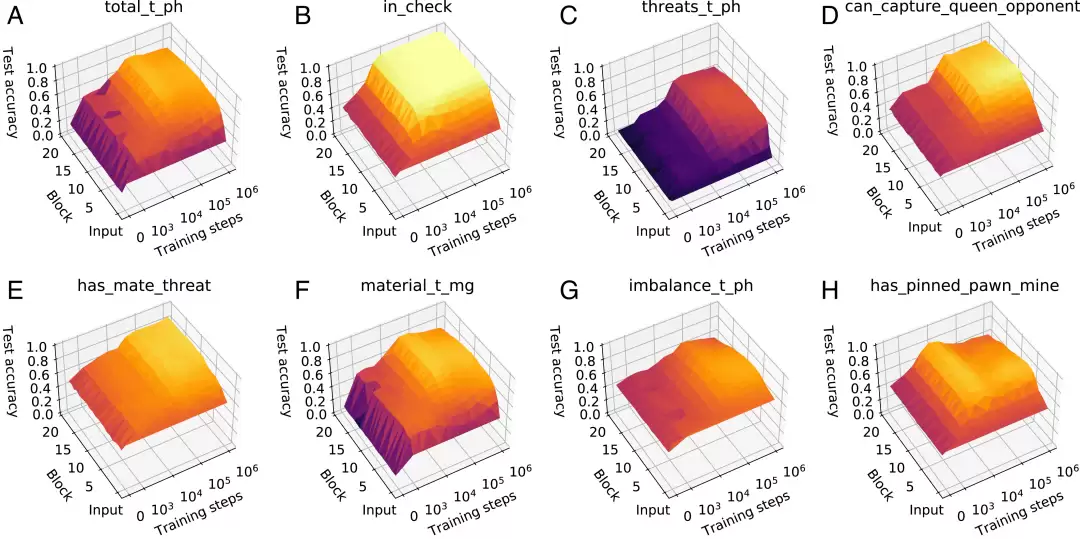
图2:从A到B的概念分别是“对总分的评估”、“我方被将军了吗”、“对威胁的评估”、“我方能吃掉敌方的皇后吗”、“敌方这一步棋会将死我方吗”、“对子力分数的评估”、“子力分数”、“我方有王城兵吗”。
分析这些“概念学习地图”可以揭示几个关键模式。首先,许多概念的学习轨迹呈现出高度一致性:在训练约3.2万步之前,网络各层对概念的编码精度普遍较低;此后,精度随着网络深度迅速提升并趋于稳定。这表明,与概念相关的核心计算大多发生在网络的相对浅层,更深层的残差块可能更专注于落子选择或计算其他未明确定义的高级特征。
其次,随着训练的推进,大量人类定义的概念都能以很高的准确率从AlphaZero的内部表征中预测出来。但不同概念的掌握时机存在差异。像“子力价值”和“空间控制”这类基础概念,在训练仅2千步时就已初现端倪;而更复杂的“王的安全”、“威胁评估”、“机动性”等高级概念,则要到8千步后才开始被显著捕捉,并在3.2万步后出现实质性增长。这与图2中显示的精度的“陡升”拐点相吻合。
值得注意的是,大多数概念的探测精度在经历初期的快速增长后,会进入平台期甚至出现轻微下降。这暗示,当前的方法可能只触及了网络所学知识的表层,要理解更深层、更抽象的表征,或许需要开发更先进的探测与分析技术。
AlphaZero的开局策略与人类棋手存在显著差异
既然证实了AlphaZero能够学会人类概念,研究人员顺理成章地追问:它对战术的理解,尤其是在开局阶段的选择,是否也与人类棋手的共识一致?毕竟,开局偏好深刻反映了棋手对棋盘局势背后各种概念的权衡与评估。
答案是否定的。研究发现,AlphaZero与人类在开局策略的演化路径上截然不同,甚至可以说是背道而驰。
回顾人类国际象棋发展史,开局库是不断拓宽和丰富的。早期棋手普遍偏爱第一步走王前兵(e4),后来才逐渐发展出后前兵(d4)、英国式开局等更多样、更平衡的体系。然而,AlphaZero的演化路径恰恰相反:在训练初期,它对所有合法第一步的评估相对平均;随着训练深入,其选择范围却逐渐收窄,表现出对后前兵(d4)等特定走法的明显且稳定的偏好。
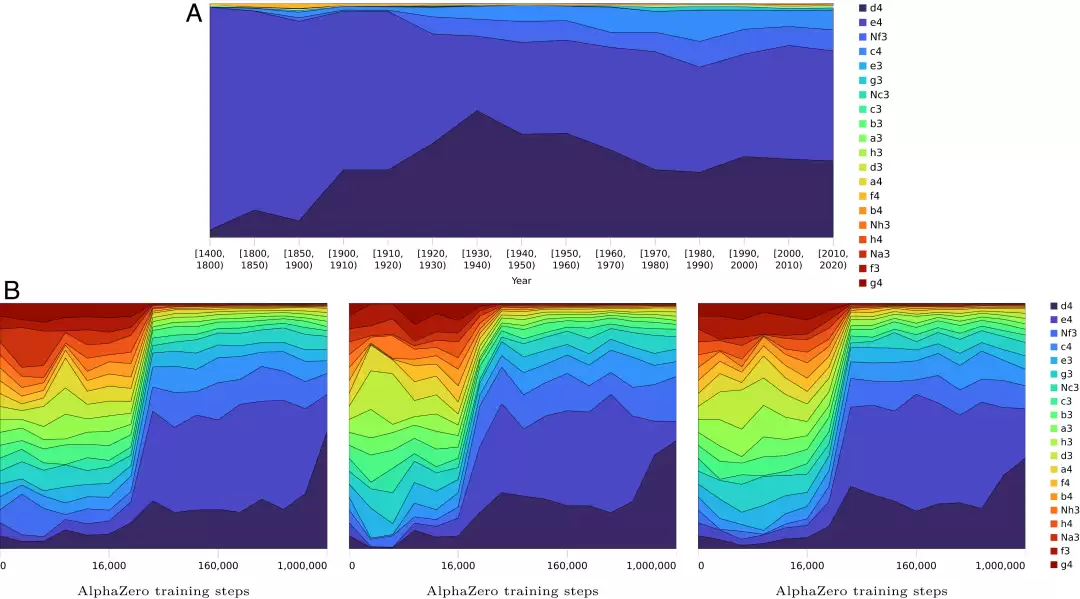
图3:随着训练步骤和时间的推移,AlphaZero和人类对第一步的偏好比较。
这种差异的根源尚不完全明确,但很可能反映了人类集体智慧结晶与机器自我探索之间的根本不同。人类棋谱库凝聚了历代大师的经验与智慧,而AlphaZero的训练数据则混合了从初级到高级的自我对弈棋局,且其训练过程为了鼓励探索而引入了大量随机性。
更有趣的是,即便在AlphaZero内部,不同训练周期产生的模型,其开局偏好也并非一成不变,而是呈现出丰富的多样性。以经典的“西班牙开局”为例,AlphaZero在早期训练中会遵循人类常见的应对(1.e4 e5, 2.Nf3 Nc6, 3.Bb5)。但在不同的训练运行中,它会逐渐收敛到两种不同的偏好上:3...a6 或 3...f6。并且,这种偏好早在训练初期就已确立。
这强有力地说明,在国际象棋这个复杂的策略空间中,通往胜利的道路不止一条。策略的多样性不仅存在于人机之间,也存在于人工智能模型内部不同的“进化分支”里。
AlphaZero掌握知识的具体过程解析
那么,AlphaZero对开局策略的探索,与其对各类象棋概念的掌握过程有何内在关联?研究发现,两者在时间线上存在清晰的呼应关系。
在许多概念的“学习地图”中,可以观察到一个明显的性能拐点,而这个拐点出现的时间,正好与开局偏好发生显著变化的时间段重叠。特别是“子力价值”和“机动性”这两个核心概念,它们似乎直接驱动了开局策略的演变。
“子力价值”的概念主要在训练1万到3万步之间被牢固掌握,而“棋子机动性”的概念则在同期逐步整合到网络的价值头评估中。合乎逻辑的是,对棋子基础价值的理解应先于对棋子灵活性的评估。随后,AlphaZero将这套整合后的评估理论应用于开局选择,其偏好在大约2.5万到6万训练步之间趋于稳定。
基于这些发现,研究人员勾勒出AlphaZero知识演进的三个阶段:首先是发现并掌握基本的“子力”价值;随后进入一个短暂但密集的知识爆发期,快速吸收如“机动性”、“空间”等相关高级概念;最后是一个漫长的精炼与优化阶段,神经网络的开局策略在数十万步的训练中不断微调固化。值得注意的是,虽然整体学习周期很长,但某些基础能力会在相对短暂的时间窗口内“顿悟”般快速涌现。
这一结论甚至得到了前国际象棋世界冠军弗拉基米尔·克拉姆尼克的认同,他的实战观察与上述学习过程不谋而合。
总结与展望
总而言之,这项研究提供了有力证据,证明AlphaZero通过纯粹的自我对弈学到的棋盘内部表征,能够重建大量人类国际象棋的战术概念,并清晰揭示了这些知识在网络中的时空分布规律。同时,它也展现了与人类棋手不同的风格与独特的进化路径。
这项研究也自然引出了下一个更深层的问题:既然我们现在能以人类概念为“透镜”来部分理解神经网络,那么,神经网络是否也能发现并掌握超越人类现有知识范畴的全新概念与制胜策略呢?这或许是通向更通用、更强大人工智能的关键一步,也为AI可解释性研究开辟了新的方向。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

国产AI芯片自给率飙升 2030年有望突破八成
摩根斯坦利研究报告显示,国产AI芯片自给率正经历高速增长。2021年自给率仅为10%,预计今年将跃升至41%,并有望在2030年达到86%。目前,国内已涌现出摩尔线程、壁仞科技、沐曦科技等一批GPU芯片设计公司,连同华为、寒武纪等NPU主力厂商,共同构建起国产AI芯片生态。分析指出,随着AI计算芯片

于东来就餐多付十倍餐费后续 店主回应传递善意获赞
胖东来创始人于东来在新疆一家小店就餐后,主动支付了十倍于实际消费金额的餐费,引发关注。实际消费200余元,他支付了2000元,并对店主表示体谅其经营不易。店主起初计划退款,但被婉拒。事后,于东来还通过网络视频推荐该店,为其带来客流。店主回应称于东来为人低调,是良心企业家,并表示会将这份善意传递下去。

第二季度手机内存价格大幅上涨 三星领涨增加厂商成本
根据集邦咨询最新报告,2026年第二季度手机内存合约价谈判结果确定,价格将持续大幅上涨。其中LPDDR4X内存均价预计环比增长70%-75%,LPDDR5X涨幅更高达78%-83%。三星采取一次性显著调涨策略,SK海力士则相对温和。这波涨价是在第一季度高价基础上的再次攀升,将显著推高手机制造成本。与

英特尔显卡驱动更新 适配地平线6等新游戏并新增性能监控
英特尔推出Arc显卡驱动程序32 0 101 8801,为新作《极限竞速:地平线6》和《深海迷航2》提供首日优化,并修复了《战地6》在特定平台上的画面问题。更新覆盖Arc独显与酷睿Ultra核显,同时新增游戏内性能监控叠加层和应用内错误报告功能,方便玩家实时查看数据并反馈问题。该驱动为Beta版本,

DeepSeek融资后AI格局生变 三类玩家如何重塑大模型竞争
DeepSeek完成创纪录融资引发业界对中国大模型格局的重新思考。当前AI竞赛已形成明确规则:模型能力提升转向高投入工程问题,参赛者需跨过智能自进化临界点并保持持续加速度。未来市场将主要由三类玩家构成:拥有强大主营业务的科技巨头、专注模型的创业公司,以及像DeepSeek这样具备独特资源与战略决心的








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
