




智谱AI在2026年的性能提升与优化路径

要问当前AI大模型领域最引人瞩目、也是各家厂商暗自较劲的核心目标,那无疑是追赶乃至超越GPT-4。
回望2023年,国内AI行业度过了异常繁忙的一年。上半年,资本涌动、人才争夺战硝烟四起;下半年,大模型呈现井喷式爆发,行业进入了模型密集发布与商业化落地探索的初期阶段。
有公开数据显示,截至去年10月,国内已发布的大模型数量高达238个。这意味着,在过去一段时间里,几乎每天都有一个新模型诞生。有趣的是,许多厂商在介绍自家产品时,都不约而同地提到“能力接近GPT-4”,更有甚者,直接喊出了“全面赶超”的口号。
一时间,舆论场上仿佛中国大模型已跻身世界领先行列,这给不少不了解技术细节、却密切关注AI发展的投资者与用户,带来了些许不切实际的期待与信心。
然而,现实情况往往更为复杂。去年11月,元象XVERSE科技创始人、前腾讯副总裁姚星就曾指出,所谓“接近GPT-4”的说法,大多与实际情况不符,其中不少成绩是“刷榜”刷出来的,实际意义有限。
“刷榜成了某种行业陋习。”这种风气导致业界对中国大模型的真实能力缺乏清晰认知。事实上,我们距离GPT-4仍有相当长的路要走。
尽管随着OpenAI论文的公布、Meta等巨头的强势开源,大模型的技术黑箱被逐步打开,国内外差距正在缩小,但那个被视为行业天花板的GPT-4,我们依然未能触及。
这绝非易事。训练顶尖模型需要巨额资金、稀缺的顶尖工程人才、清晰坚定的技术路线,以及公司战略层面持续不懈的投入。并非喊一句口号,就能让国产大模型与GPT-4同台竞技。
因此,在这个“刷榜”习气尚未完全褪去的时期,我们的注意力与资源,更应当投向那些为中国大模型事业脚踏实地、持续投入的团队。市场不需要鱼目混珠式的“盲目自吹”。
追赶GPT-4,无疑是国产大模型当前最紧迫的任务。对于通用大模型厂商而言,谁能率先训练出真正比肩GPT-4的模型,谁就能在商业化和生态建设上占得先机,犹如“先入咸阳”。
过去一年,关于“谁将率先突破”的猜测与讨论从未停止。终于,智谱AI发布了新一代基座大模型GLM-4。其模型性能相比上一代提升高达60%,多项关键指标逼近GPT-4。这让我们看到,“国产GPT-4”或许真的不远了。
这个结果虽在预料之中,但其推进速度之快,仍超出了许多人的预期。
最强大模型GPT-4,为何一直难以逾越?
2023年春节后,一些关注科技的投资人偶然体验了ChatGPT(基于GPT-3.5),其能力令人震惊。口碑迅速在投资圈传开,进而点燃了整个中文互联网对ChatGPT的追捧热潮。
然而,就在大众尚未从ChatGPT带来的震撼中回过神来,仅一个月后,OpenAI再度扔出“王炸”——GPT-4。这个更强大的模型,彻底引爆了人们对大模型潜力的想象。
它究竟有多强?仅凭一张手绘网站草图,GPT-4就能直接生成可用的网页代码;在GRE等标准化考试中接近满分;在模拟律师考试中,其成绩击败了90%的考生,跻身前10%。相比之下,GPT-3.5的成绩仅在倒数10%之列。
GPT-4在各种专业测试和学术基准上的表现,已接近人类水平。其最重大的突破之一,是具备了处理和理解图像信息的能力,并能据此给出准确的解答。
种种惊艳表现,使得GPT-4自诞生之日起,便成为全球科技公司竞相追逐的标杆。
那么,在这轮全球竞赛中,中国的优势常被认为在于丰富的应用场景和超大规模市场,最适合推动大模型落地。既然如此,我们直接使用开源模型不行吗?为何一定要耗费巨资和精力去追逐GPT-4呢?
首先,正如智谱AI CEO张鹏所言,一个真正好用的基座大模型,其根本在于能力是否“够用”。当前,国产大模型若要深入实际业务场景,为企业带来切实价值,其通用能力仍需大幅提升。
而反观最先进的GPT-4,它虽在不断进化,涌现出新的类人能力,但连最基本的“幻觉”问题也未能彻底解决。距离真正的通用人工智能(AGI),恐怕还有很长的路要走。
“真正落实到企业端,光靠聊天类产品似乎还不够。”张鹏指出,当前大模型商业化落地遇到的挑战,本质上仍是模型能力突破的问题。
既然“优等生”尚有进步空间,我们又有什么理由停滞不前?更何况,国产大模型的能力尚不足以支撑众多复杂场景的商业化需求。因此,GPT-4依然是现阶段必须奋力追赶的目标。
其次,从国家战略层面看,技术自主可控是大势所趋。仰望并抵达最前沿的技术高地,是我们必须完成的使命。
“现在关键看谁能赶上甚至超过GPT-4,很可能大部分厂商都跨不过这道坎。”一位深入了解大模型生态的业内人士表示。他特别提到,Meta的Llama 2发布后,其能力一度接近GPT-3.5,但此后Meta迟迟未发布重大更新,这侧面印证了大模型技术的高门槛,对国内许多团队而言将是严峻考验。
值得注意的是,国内不少厂商的模型正是基于Llama等开源架构进行训练的。
GLM-4:性能直逼GPT-4
2024年1月16日,智谱AI在北京举办了技术开放日,正式发布了新一代基座大模型GLM-4。
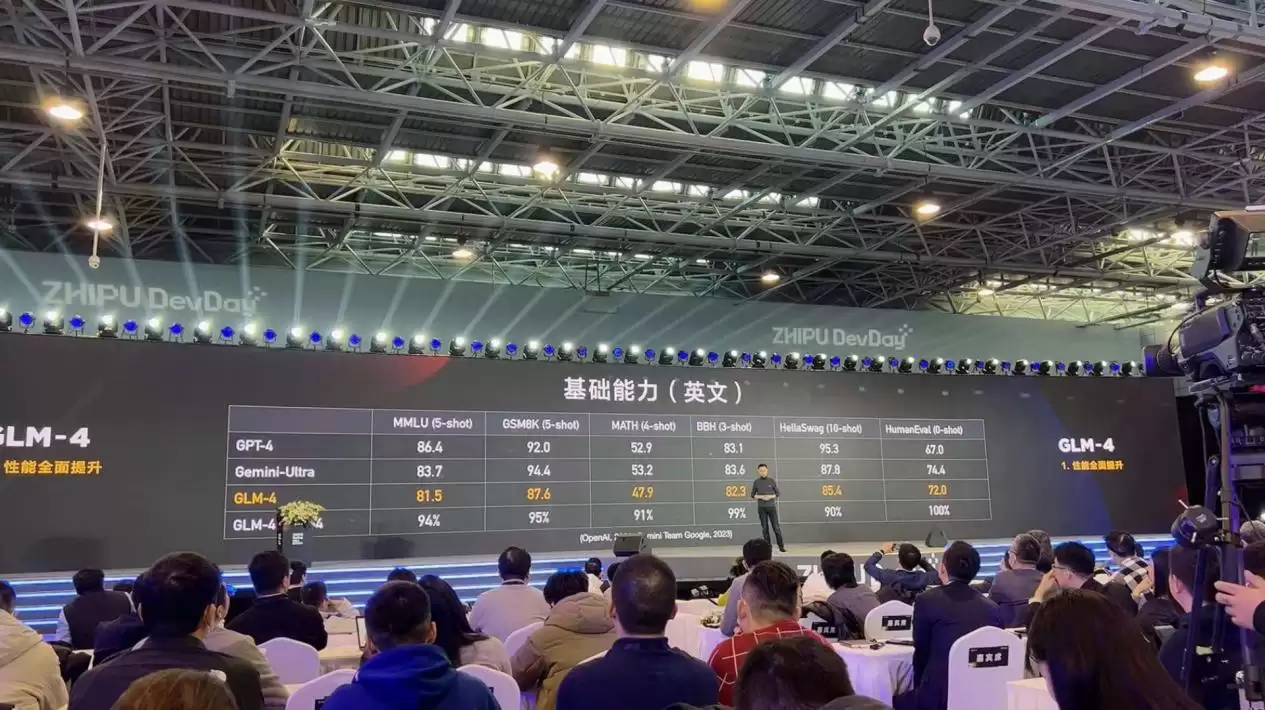
根据官方信息,GLM-4在基础能力上实现了显著飞跃,整体性能相比前代GLM-3提升约60%。测评数据显示,其综合性能已逼近GPT-4。
具体来看基础能力:在MMLU基准测试中达到81.5分,约为GPT-4的94%;GSM8K测试达到87.6分,约为GPT-4的95%;MATH测试达到47.9分,约为GPT-4的91%;BBH测试达到82.25分,约为GPT-4的99%;HellaSwag测试达到85.4分,约为GPT-4的90%;在HumanEval测试中达到72分,与GPT-4持平。
在指令跟随能力方面,与GPT-4相比,GLM-4在IFEval的提示词跟随(中文)测试中达到其88%的水平,在指令跟随(中文)测试中达到90%的水平,均大幅超过GPT-3.5。
在对齐能力上,基于AlignBench数据集,GLM-4的表现已超过GPT-4在2023年6月13日的版本,逼近其2023年11月6日的最新版本。尤其在专业能力、中文理解和角色扮演方面,GLM-4的精度已实现超越,仅在中文推理方面尚有进一步提升空间。
值得玩味的是,智谱此次虽然展示了GLM-4在过去一年奋力追赶所取得的亮眼成绩——在多项测评中达到GPT-4约90%的水平——却并未宣称“全面赶超”,而是秉持着实事求是的态度,明确指出其性能只是“逼近”GPT-4,差距依然存在,甚至特地点明了自身的不足。这与当下部分浮夸之风形成了鲜明对比,显得尤为低调与务实。
除了性能提升,GLM-4支持128K的上下文窗口长度,单次可处理约300页文本内容。在“大海捞针”测试中,在128K文本长度内,模型均能实现近乎百分之百的精度召回。
依托于GLM模型强大的智能体(Agent)能力,智谱推出了GLM-4-All Tools。它能根据用户意图,自动理解、规划复杂指令,自由调用WebGLM(搜索增强)、Code Interpreter(代码解释器)及多模态生成能力,以完成复杂任务。
多模态已成为AI发展的关键方向。从Meta的SAM、OpenAI的GPT-4V、谷歌的Gemini,到智谱的CogView3,头部厂商都在积极布局。所谓“模态”,即表达或感知信息的方式,图像、声音、文本等都是不同模态。视觉模态数据更丰富、直观,在复杂场景中,多模态交互往往比纯文本更高效、门槛更低。
有证券分析师指出,多模态技术的每一小步,都可能推动产业应用落地一大步。它是大语言模型深入千行百业、迈向通用人工智能的重要里程碑。因此,大模型向多模态演进是必然趋势。
此时,智谱在大模型产业落地的道路上已奔跑超过十个月。GLM-4的多模态能力也显著增强,文生图与多模态理解效果提升明显。其文生图模型CogView3的效果已超越开源最佳的Stable Diffusion XL,逼近OpenAI最新的DALL·E 3。在对齐、保真、安全、组合布局等多个评测维度上,CogView3的效果均达到DALL·E 3的90%以上。
智谱AI CEO张鹏在开放日上表示:“GLM-4的推出,标志着国产大模型水平已看齐世界先进水平,为我们全面开辟国产大模型产业新局面奠定了根本性基础。”它的发布,很可能成为国产大模型发展的一个分水岭,为商业化与产业落地开启更大的想象空间。
GLM-4推动大模型进入商业化加速时代
早在去年ChatGPT热潮初起之时,智谱便已启动商业化探索。据透露,自2023年3月以来,其接触客户超过2000家,与其中1000多家达成合作,并与超过200家进行了深度共创。
纵观大模型发展历程,智谱过去一年的步伐始终紧密围绕着商业化展开。相比其他头部创业公司大多在去年10月后才开始喊出商业化口号,智谱的商业化进程领先了约半年。
然而,商业化之路并非一帆风顺。CEO张鹏在去年10月底曾坦诚,智谱的大模型面临着“叫好不叫座”的挑战:市场认可度虽高,但谈及付费购买,许多客户便会犹豫。
究其原因,一方面在于市场对大模型的认知仍需深化;另一方面则是一个很现实的对比:GPT-4如同一个明确的标尺立在前面,即便用户不了解技术细节,也会自然而然地追问:“你们的模型,离GPT-4还有多远?”
对于商业化前景,张鹏当时认为,如果有一天模型能力达到GPT-4的水平,许多现有问题将迎刃而解,甚至连商业模式都可能变得简单——只需提供API即可。令人惊讶的是,仅仅两个多月后,GLM-4便实现了性能上的大幅跃升,逼近GPT-4。这对于智谱的整体发展和商业化进程,无疑是一剂强心针。
此次技术开放日上,智谱还宣布了一系列旨在加速GLM模型生态建设的措施。其中最引人注目的是GLMs个性化智能体功能。基于GLM-4的强大能力,用户通过简单的提示词指令,就能创建属于自己的智能体。该功能及智能体中心已于开放日当天上线。
此外,智谱AI还针对商业客户、开源社区及中小微企业等合作伙伴,推出了多项具体支持措施。
例如在价格方面,GLM-4升级后,API调用价格仍维持在0.1元/千tokens,这已是行业较低水平。同时,公司将设立总额1000万元软妹币的大模型开源基金,并对面向全球创业者的“Z计划”进行升级,联合生态伙伴发起总额10亿元软妹币的大模型创业基金,以支持原始创新。
这些构建生态的举措,本质上都是在为更深层次、更广泛的商业化落地铺路。
据智谱AI首席运营官张帆介绍,过去九个月,公司商业化体系经历了从单纯“卖模型”到搭建完整体系的演进。这个体系呈金字塔结构:最底层是开源层,ChatGLM系列拥有千万级下载量,是许多开发者的入门选择;上一层是API层,服务日常调用的核心客户;再往上是云端私有化部署,面向有数据资产沉淀需求的中型企业;塔尖则是本地私有化部署,服务于对安全性、自主性要求极高的头部企业。
对智谱而言,每一层都有其生态位,商业化的目标是推动下层用户向上层迁移,逐步丰富商业化的层次与内涵。这正契合了智谱“技术研发与商业化落地双轮驱动”的发展策略。
GLM-4的发布,预计将为整个大模型行业带来震动,推动产业转身进入商业化加速的新阶段。
写在最后
时间回到2023年3月14日,就在GPT-4发布的同一天,智谱AI同步发布了基于千亿参数基座模型的ChatGLM,并开源了中英双语对话模型ChatGLM-6B。其对标OpenAI的雄心,那时便已初显。
如今,GLM-4的成功发布,既是智谱过去一年秉持谦逊态度、坚持向世界最先进水平看齐的成果,也是其决心与信心的兑现。对标OpenAI的目标,正在一步步实现。
GLM-4在性能上直逼GPT-4,这让我们对国产大模型未来追赶甚至超越GPT-5、GPT-6……并在实现AGI的漫长道路上,增添了更多的信心与坚持。
正如OpenAI的Sam Altman所言,“永远要更快”。大模型时代正在加速一切。在2024年的第一个月,智谱AI的这次率先出击,无疑为接下来一整年的激烈竞争定下了基调。这不禁让人更加期待,未来的人工智能行业,还将带来怎样的惊喜。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

商汤科技获评中国AI咨询服务市场领导者
IDC报告将商汤科技定位为中国AI咨询服务市场领导者。其凭借“大装置-大模型-应用”战略与全流程专家服务,帮助企业应对AI落地中的成本、适配与安全挑战,实现从战略规划到持续运营的全周期支持。目前服务已扩展至金融、能源、交通等多个领域。

趋境科技携手金航数码深化AI合作,共促空天领域数字化转型
趋境科技与金航数码签署人工智能合作框架协议,将前期成功实践深化为战略伙伴关系。双方基于已验证的大模型私有化解决方案,聚焦航空等复杂装备工业,通过算力底座与行业场景深度融合,共同推动智能化技术在研发、生产等环节的落地应用,助力工业数字化转型升级。

城市智能最后一公里难题的论文解决方案
郑宇教授提出跨域多模态知识融合框架,整合空气质量、交通、气象等多领域数据,通过数据选择、知识对齐、模型构建与数据转换四个阶段,解决了数据稀疏与异构难题,显著提升了预测精度与异常识别能力,为智慧城市应用提供了可行路径。

ATEC2025科技精英赛落幕 机器人自主技术成焦点
第五届ATEC科技精英赛在香港收官,赛事以“无遥操”为核心,要求机器人在户外复杂地形中完全自主完成吊桥穿越、垃圾分拣等任务。来自全球的13支队伍参赛,浙江大学凭借全自主智能表现夺冠。比赛旨在推动机器人从实验室走向真实应用,通过真实场景挑战测试机器人的感知、决策与执行能力,促。

Recraft AI设计草稿如何保存与云端同步方法
RecraftAI采用自动云端同步实时保存设计草稿,无需手动操作。用户可通过项目列表中“Lastedited”时间戳的实时更新验证同步状态,并需保持网络稳定与登录有效。必要时可刷新页面或进行微小操作触发同步。跨设备核对内容一致性是确认草稿安全存储于云端的最终方法。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
