




MoE模型高效训练指南用显存换取性能提升的实践策略

MoE架构会成为大模型发展的主流方向吗?
自业界发现MoE(混合专家)架构能显著提升大模型训练与推理效率以来,这个问题便持续引发广泛探讨。
MoE,全称为Mixture of Experts,中文译为“混合专家系统”。其核心是一种模块化的稀疏激活机制。如何理解这一概念?
当前主流大模型主要分为稠密模型与稀疏模型两类。二者的关键区别在于模型推理时实际参与计算的参数数量。像OpenAI的GPT系列(GPT-1至GPT-3)以及Meta的Llama系列这类参数全部激活的模型,属于稠密模型。而仅激活并使用其中一部分参数的模型,则属于基于MoE架构的稀疏模型,这部分被使用的参数被称为“激活参数”。
从网络结构看,主流大模型多基于Transformer架构,由多个Transformer Block堆叠而成。每个Block通常包含两层:多头自注意力层和前馈神经网络层。MoE的创新之处在于对FFN层进行横向扩展,将其参数细分为多个独立的“组”,每个组即是一个“专家”。
基于此设计,对于特定输入,MoE模型仅需激活少数几个相关专家,让这部分参数工作,实现“稀疏激活”。具体激活哪些专家,则由一个称为“路由器”或“门控网络”的组件根据输入内容动态决定。
去年底,Mistral AI开源的MoE模型Mixtral 8x7B,其性能表现可媲美GPT-3.5和Llama2 70B,但推理计算消耗仅相当于一个130亿参数的稠密模型。这一突破性成果极大地激发了业界对MoE潜力的关注。
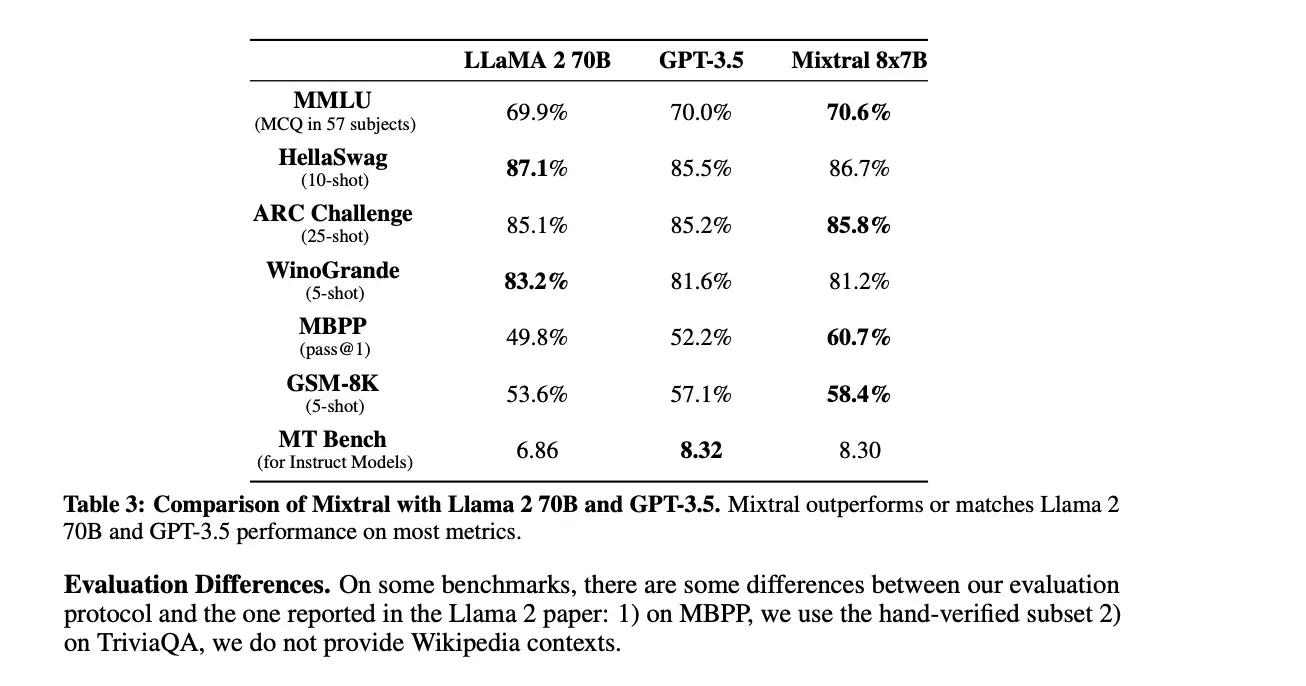
这种架构能够在增大模型总参数量的同时,让计算成本远低于同等规模的稠密模型,从而实现高效训练。在Scaling Law(缩放定律)仍被视为大模型核心发展规律的当下,MoE无疑是实现“规模效应”的理想技术路径。
随后,国内外众多AI公司纷纷跟进,推出了各自的MoE架构大模型:
今年1月,MiniMax发布了基于MoE的大语言模型abab6;
2月,昆仑万维正式发布新版MoE大模型“天工2.0”;
3月,马斯克的xAI开源了MoE大模型Grok-1,新晋独角兽阶跃星辰发布了Step-2万亿参数MoE预览版,阿里通义千问团队开源了其首个MoE模型Qwen1.5-MoE-A2.7B;
4月,元象科技发布XVERSE-MoE-A4.2B,面壁智能推出MiniCPM-MoE-8x2B;
5月,DeepSeek AI开源的MoE模型DeepSeek-V2,在多项评测中成为当前性能领先的开源MoE语言模型……
选择MoE路线的厂商日益增多。通过与国内多位深耕MoE技术的专家交流,我们发现,尽管MoE的长期前景尚未有最终定论,但在当前阶段,它无疑是大多数企业在遵循Scaling Law、追求模型规模扩展时,一个近乎必然的技术选择。
1. MoE是算力约束下的“必然产物”
MoE并非全新概念。作为一种统计学模型架构,它早在1997年便被提出。随后,随着机器学习与深度学习的发展,MoE思想被引入神经网络领域。早在2017年,便有研究成功将MoE应用于LSTM模型。
对许多从业者而言,认识到MoE可用于大模型训练,始于去年底Mistral AI的开源。但对于长期研究者来说,那次开源更像是一次成功的工程实践,让业界对MoE的认知从理论探讨走向了效果验证。
实际上,更早的线索出现在去年6月。当时有传言称,OpenAI的GPT-4可能是一个采用8x220B参数的MoE模型。尽管那时国内大模型产业刚起步,相关讨论未深入,但此次传言无疑让更多业内人士开始关注MoE的潜在价值。
阶跃星辰的算法专家透露,当社区传言GPT-4采用MoE架构时,他们并不意外,甚至能依据经验推测其大部分架构细节。
元象XVERSE的技术合伙人轩文烽也表示,他们早在2021年初Google发表Switch Transformers论文时便开始研究MoE,国内阿里研发M6模型时也有持续跟进。“而Mistral AI的开源,让MoE的实际效果变得非常直观。之后在去年12月,我们便开始策划训练自己的MoE大模型。”
诚然,MoE作为一种稀疏激活技术,其最突出的优势在于,能在总参数量不变的情况下,大幅降低实际计算量,从而提升训练与推理效率、降低成本。这正是这项并不“新”的技术,在当前算力紧缺的背景下重新焕发活力的根本原因。
大模型的规模正在指数级增长。Scaling Law表明,模型参数量的增加通常能带来性能提升。但模型的迭代极度依赖强大的算力支撑,而全球范围内的算力紧缺,已是行业共识。
稀疏化技术,包括MoE,为这一难题提供了可行的解决方案——它允许模型拥有更大的参数规模,同时其训练和推理成本又远低于同等规模的稠密模型。
面壁智能的研究员宋晨阳指出,在目前算力,特别是国内算力资源普遍有限的情况下,采用MoE架构是一个必然的趋势和务实的选择。
面壁智能与MoE渊源颇深。早在2021年6月,清华大学刘知远教授团队发布的千亿参数MoE大模型CPM-2,便是国内最早关注该方向的成果之一,而面壁智能的初始团队正是核心参与者。这份技术基因使得面壁智能持续深耕MoE与稀疏化技术的研究。

同样坚信Scaling Law的阶跃星辰,在完成千亿参数模型训练后迈向万亿规模。而要将参数量扩大到万亿级别,MoE正是在模型性能、参数量、训练与推理成本等多个维度权衡下的最佳技术路径。
具体而言,MoE模型的优势主要体现在专家化、动态化和稀疏化三个层面:
一是更强的模型表达能力。MoE融合了多个各有所长的专家子模型,既有分工又有协作,能够动态适应不同输入数据的特性,从而提升模型的整体表征能力。
二是更高效的训练与推理速度。相比于同参数量的稠密模型,MoE采用稀疏激活机制,训练时计算量更小,推理时同时激活的参数量也更少,从而能更高效地利用宝贵的计算资源。
2. 技术路径选择尚未统一
目前,采用MoE架构的厂商日益增多,整体思路相似,但在具体的架构设计细节上,业界远未达成共识。例如,模型总共需要设置多少个专家?每次推理激活多少个?是否需要设置固定的共享专家?如何平衡专家之间的负载?各家都有不同的技术选择。
一般而言,当前的MoE技术路径主要分为两种:基于已有预训练模型进行MoE化改造,或是完全从头开始训练一个MoE模型。
基于已有模型训练,通常采用一种名为“向上复用”的高效方案。具体而言,是将一个已训练好的稠密模型的前馈神经网络参数复制多份,每一份作为一个专家,然后组合成MoE模型。这样能快速得到一个总参数量巨大的模型,而所需的算力投入却小得多。
宋晨阳解释道:“这种方法的最大优势在于节省成本,因为初始模型已经学习了海量的知识。”但弊端也很明显:通过复制得到的多个专家之间可能存在高度的知识重叠,导致参数冗余。如果处理不当,就无法充分发挥MoE架构的潜力,这对工程技术提出了很高要求。
相比之下,从头开始训练虽然难度和成本更高,但能有效缓解上述问题,并且拥有更高的架构设计自由度,有望突破传统MoE的性能瓶颈,触及更高的性能上限。
目前,多数厂商选择了基于已有模型训练的路径,例如Mistral AI的Mixtral系列、通义千问的Qwen1.5-MoE-A2.7B、面壁智能的MiniCPM-MoE-8x2B等。而从公开论文来看,DeepSeek-V2则选择了更具挑战性的从头训练路线,其开源后也引起了业界的巨大反响。
阶跃星辰的做法是双管齐下:一方面坚持完全从头训练万亿参数模型,以充分挖掘MoE的潜力;另一方面在研发前期投入大量精力,从众多候选方案中筛选出更可靠的架构配置。
此外,业界在专家粒度设计上也存在分歧:专家的规模应该粗粒度还是细粒度?是否应该引入固定的共享专家?
以Mistral AI的8x7B为例,这是一个经典架构:包含8个形状完全相同的专家,路由器每次从中选择2个激活。但通义千问和DeepSeek采用了不同的思路,特别是DeepSeek,它将专家粒度切分得更细,并引入了共享专家机制。

这好比将选择范围从传统的8选2(组合数C(8,2)),转变为将每个专家再细分为8份,得到64个更小的专家单元,然后从中选择8个(组合数C(64,8))。可选择的组合数大幅增加,模型的表达能力和灵活性理论上也会显著增强。
宋晨阳认为,这是DeepSeek MoE模型的一大创新点。
轩文烽也透露,在专家设计上,元象XVERSE也没有采用类似Mistral AI的传统做法,而是使用了更细的颗粒度,将每个专家设置为标准FFN大小的1/4。这一选择是基于多次实验验证的结果,同时他们也密切关注着业界在FFN配比上的最新技术方案。
另外,DeepSeek引入的共享专家也颇具巧思。前面提到,基于“向上复用”得到的MoE模型,专家初始化时完全一样,知识重叠难以避免。DeepSeek的策略是将这部分重叠的公共知识,用一个共享专家单独表示。对于每个输入,共享专家被固定激活,不经过路由器选择;剩余的非共享专家,则由路由器动态挑选激活。
基于这些差异,宋晨阳认为,当前市面上的MoE模型大致可分为两个流派:一是类似Mistral AI的传统流派;二是像通义千问和DeepSeek这样,追求更细专家粒度和引入共享专家的创新派架构。
至于哪种架构会成为未来主流,目前并没有定论。因为一个模型的最终性能表现,架构设计并非唯一决定因素。训练数据的质量、清洗方式、配比组织,乃至训练时数据的切分方法等,都至关重要。不同的技术选择,将通向不同的结果。
目前,面壁智能的MiniCPM-MoE-8x2B采用了类似Mistral AI的架构。考虑到其最终目标是将端侧模型做到极致,部署到每一部手机,团队也在持续讨论和实验,以探索更适合移动硬件加速的MoE架构,做出最终的技术路径选择。
3. MoE“终究是一门权衡与妥协的艺术”
随着入局者增多,MoE似乎正成为一种行业趋势。那么,它会是AI未来的终极方向吗?
对此,业界看法不一。支持者认为,它在同等参数规模下能大幅降低算力需求,在Scaling Law依然有效的今天,无疑是实现模型规模扩展的最优解。
但持保留态度者也大有人在。
今年4月底,Meta发布的Llama 3系列,包括8B、70B和仍在训练中的400B+版本。CEO扎克伯格在访谈中明确,Llama 3 400B+将是一个稠密模型。面对如此巨大的参数量,依然选择稠密架构,或许表明Meta对稀疏化技术持谨慎态度,“拒绝”了当前的MoE方案。
事实上,即便是选择了MoE的厂商,也不得不承认,尽管拥有高效训练、灵活性强等优点,MoE的局限性依然明显,它“终究是一门权衡与妥协的艺术”。
宋晨阳指出,MoE的核心优势在于算力有限时,能以更低的计算量达到相近的参数规模。但如果有充足的算力,在同等参数量下分别训练一个MoE模型和一个稠密模型,性能上通常是稠密模型更优。
本质上,FFN的表达能力是近乎无限的,但MoE为了稀疏激活,强制规定只能激活被切分后的一部分FFN,这相当于缩小了模型整体的假设空间和表示能力。
此外,无论是MoE还是广义的稀疏化,目前都存在一个“致命”挑战:缺乏特别有效的方法来降低其存储消耗。例如,一个70亿参数的模型即使通过稀疏化使计算量小于70亿,但其内存占用依然是一个70亿参数模型的规模。这在部署到手机等端侧设备时,会带来严峻的挑战。
轩文烽也表达了类似观点,他认为MoE当前的高效训练优势,某种程度上是“用显存占用换取计算效率”。虽然MoE不像稠密模型那样,参数增大后训练和推理成本急剧上升,但对于一个用42亿激活参数量达到130亿模型效果的MoE来说,推理成本是降低了,但显存占用并没有同比减少。
因此,“如何在优化显存占用的同时,保持这种高性价比的效果,可能是行业需要重点研究的课题。”
另一位从事MoE模型训练的研究员也感慨,实际训练中挑战不少。例如,训练和推理的工程复杂度高,万亿级MoE需要将专家分布在不同计算节点上,引入了额外的并行维度和网络通信开销;专家负载不平衡会拖累系统效率,极端情况可能浪费过半算力;参数利用率有待提升,每个专家都必须先成为“通才”学习基础知识,才能进一步“专精”,导致同参数量下MoE模型的表现往往不及传统稠密模型。
尽管如此,这些从业者普遍坦言,就当下的现实条件与算力约束而言,MoE肯定是一个极具希望的方向,是必然的发展趋势。
或许在算力无限的理想状态下,未必非要使用MoE。但在算力依然短缺的今天,我们无法空谈那个不存在的未来。当然,如果把目光放远到十年或二十年后,随着硬件和计算框架的演进,架构的选择或许会更加自由多样。
而在当下这个具体的时间点,从业者能做的,是基于MoE现有的技术挑战和优化空间,尽可能进行改进,使其训练更高效、性能更优、部署更易。
例如,如何为MoE设计更好的加速框架?MoE模型并不容易加速,因为涉及大量专家。这些专家该如何部署?是每个专家独占一张GPU,还是切片后分布式部署在多张卡上?这些都是待解的工程难题。
再比如,当前MoE大模型似乎出现一个趋势:参数规模不断攀升,但性能未必同步增长,有时甚至不如参数量更小的模型。一个典型的对比是,参数量达3140亿的Grok-1,其性能与Mistral AI的8x7B模型(总参数量约560亿)相当。这是为什么?
宋晨阳认为,一个核心原因在于数据质量。Scaling Law成立的前提,是拥有充足且高质量的训练数据。对于相同的架构和参数量,数据质量更高的模型,可以用更少的数据量达到同等甚至更好的效果。
此外,除了数据,决定模型性能的另一大因素是训练技巧,包括批次大小、学习率调度策略等,这些都极具讲究。目前,许多头部厂商的这些“秘诀”并未完全公开,需要更多从业者通过实践去探索。当然,也有像面壁智能这样的“逆行者”,在发布MiniCPM-2B的同时,于技术报告中详细披露了批次调度、学习率调度、词表大小选取等细节,为学界和业界提供了宝贵的参考。
轩文烽在总结XVERSE-MoE-A4.2B的研发经验时也觉得,如果重来一次,实验计划可以设计得更紧凑,研发进程或许能更快一些。
虽然大家都渴望找到那个最优解,将大模型训练得又快又好,但不可否认,技术探索没有边界,没有最优,只有更优。
MoE乃至更广泛的稀疏化技术,未必就代表了AI的终极未来,但它无疑为我们提供了丰富的技术想象空间。例如,是否可以朝着更稀疏的方向演进,将专家切分得极细,直至实现神经元级别的稀疏激活?那又会带来怎样的效果?
这无疑是一个充满前景、值得深入探索的技术方向。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

趋境科技携手金航数码深化AI合作,共促空天领域数字化转型
趋境科技与金航数码签署人工智能合作框架协议,将前期成功实践深化为战略伙伴关系。双方基于已验证的大模型私有化解决方案,聚焦航空等复杂装备工业,通过算力底座与行业场景深度融合,共同推动智能化技术在研发、生产等环节的落地应用,助力工业数字化转型升级。

城市智能最后一公里难题的论文解决方案
郑宇教授提出跨域多模态知识融合框架,整合空气质量、交通、气象等多领域数据,通过数据选择、知识对齐、模型构建与数据转换四个阶段,解决了数据稀疏与异构难题,显著提升了预测精度与异常识别能力,为智慧城市应用提供了可行路径。

ATEC2025科技精英赛落幕 机器人自主技术成焦点
第五届ATEC科技精英赛在香港收官,赛事以“无遥操”为核心,要求机器人在户外复杂地形中完全自主完成吊桥穿越、垃圾分拣等任务。来自全球的13支队伍参赛,浙江大学凭借全自主智能表现夺冠。比赛旨在推动机器人从实验室走向真实应用,通过真实场景挑战测试机器人的感知、决策与执行能力,促。

Recraft AI设计草稿如何保存与云端同步方法
RecraftAI采用自动云端同步实时保存设计草稿,无需手动操作。用户可通过项目列表中“Lastedited”时间戳的实时更新验证同步状态,并需保持网络稳定与登录有效。必要时可刷新页面或进行微小操作触发同步。跨设备核对内容一致性是确认草稿安全存储于云端的最终方法。

花旗上调思科目标价至112美元 最新评级分析
花旗银行将思科目标股价从90美元上调至112美元,反映出机构对其基本面或行业前景的重新评估。市场关注点可能集中于企业网络支出、云计算进展及人工智能需求。股价走势还需综合财报、经济环境等因素判断,未来业绩指引是验证预期的关键。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
