




MiniMax大模型技术前沿与智能化解决方案创新平台详解

在人工智能浪潮席卷全球的当下,MiniMax作为一家专注于全栈自研大模型的技术公司,正凭借其强大的模型矩阵与创新的智能化解决方案,在业界脱颖而出。它不仅是一个技术平台,更是一个与开发者、企业及创作者共同探索智能未来的协作引擎。
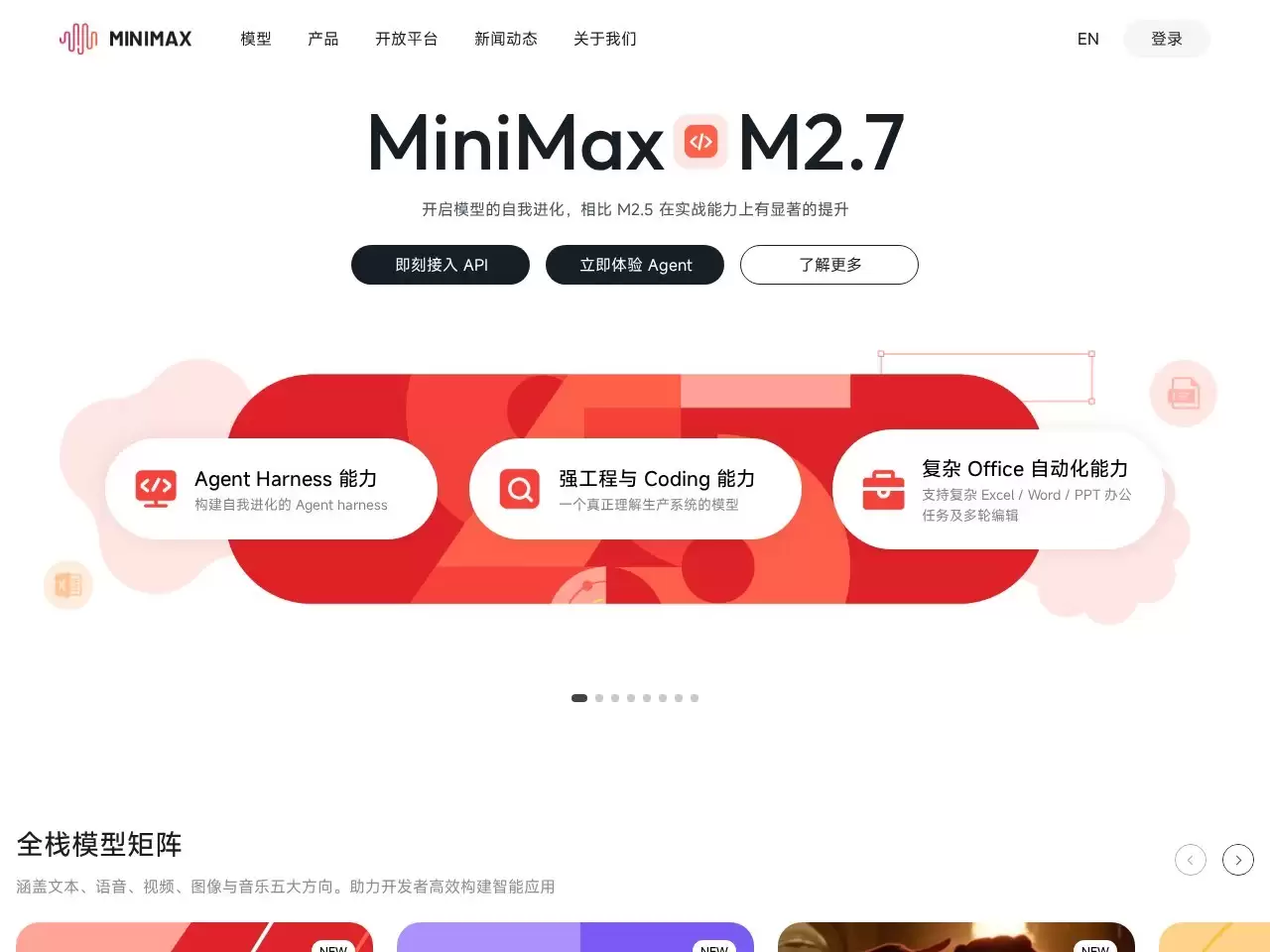
核心优势:全栈自研的先进模型矩阵
MiniMax的核心竞争力,根植于其完全自主研发的新一代大模型矩阵。这套技术体系在多个性能维度上实现了突破性进展。
技术全栈自研,综合性能领先
- 文本与语音双引擎驱动:平台部署了能力更强的文本大模型,以及音色逼真、富有表现力的超拟人语音模型。无论是长文本理解、创意写作辅助,还是复杂的逻辑推理与数学运算,其综合处理能力均处于行业前列。
- 视频生成实现关键突破:在视觉内容生成领域,MiniMax支持原生高分辨率、高帧率的视频生成技术,让“文字描述直接生成视频”的创意构想成为现实,大幅提升了视觉内容的生产效率。
- 端到端智能音乐创作:其音乐生成模型采用端到端技术路径,能够高效创作出多样风格的旋律,为音乐人和内容创作者提供了强大的辅助工具。
- 高效的万亿参数MoE架构:平台采用的万亿参数混合专家(MoE)架构文本模型,在确保生成质量卓越的同时,实现了极低的响应延迟,为用户提供了强大且实时的文本处理与对话体验。
功能落地:从场景应用到全面赋能
顶尖的技术最终需要服务于实际场景。MiniMax成功将其底层模型能力转化为覆盖广泛的应用功能,赋能从个人到企业的全方位需求。
覆盖多元场景的智能服务
- 构建原生AI应用生态:基于自研大模型,MiniMax成功孵化出“星野”、“海螺AI”等原生智能应用。这些产品将复杂的AI能力封装为简单易用的服务,让终端用户能轻松享受人工智能的便利。
- 赋能企业数字化转型:在商业服务领域,MiniMax的技术已成为超2000家企业实现智能化升级的核心驱动。其提供的实时交互API以及支持多模态输入的超低延时对话能力,正在深刻改变企业的客户服务、内容创作与运营流程。
- 开放视频生成API:Video Generation API的正式发布,意味着其先进的视频生成技术以标准化接口形式对外开放,为广大的开发者和视频创作者提供了高效、专业的视觉内容生产解决方案。
- 支撑海量行业智能交互:数据显示,MiniMax的智能交互技术每日处理高达30亿次的请求。这一庞大数据背后,是其技术深度融入电商、教育、娱乐、客服等多个行业,提供实时、精准服务的真实写照。
综上所述,MiniMax通过坚实的技术研发,构建了从底层大模型到顶层应用服务的完整AI生态体系。它不仅在持续追求AI模型性能的极限,更致力于让先进的人工智能技术无缝对接千行百业,切实推动生产与生活方式的智能化变革。
MiniMax大模型官网入口:https://www.minimaxi.com/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

商汤科技SenseCore获工信部软件供应链安全优秀级认证
商汤大装置SenseCore平台获工信部软件供应链安全能力最高等级认证,成为全国首批达标企业。该评估依据国家标准,旨在应对软件供应链安全风险。作为新一代AI基础设施,商汤大装置构建了从算力到服务的端到端能力,其上海临港智算中心算力规模领先。此次认证标志其安全可信的算力底座达到。

腾讯混元与MBZUAI新研究 Search-R2如何优化搜索增强推理
针对搜索增强推理中的错误传播与信用分配难题,本研究提出Search-R2框架,将纠错机制融入强化学习策略空间。通过轨迹判断、错误定位与联合优化,模型能够识别并修正推理链中的早期偏差。实验表明,该方法在多跳推理任务中显著提升准确性,有效抑制长链错误传播,推动搜索型智能体更稳健地。

北大团队ICLR论文:自适应时序预测损失函数学习新方法
本研究针对多步时序预测中误差累积问题,提出可学习权重矩阵的QDF方法。该方法通过元学习自适应建模预测步间相关性及不确定性差异,突破了传统均方误差损失的独立性假设限制。实验证明,QDF能有效提升长期预测精度并更好保留序列结构,为时序预测优化提供了新思路。

多模态记忆湖MemoryLake发布:AI基础设施迎来记忆驱动新纪元
质变科技发布MemoryLake多模态记忆平台,推动AI基础设施进入记忆驱动时代。该平台整合大模型、记忆引擎与多模态数据,解决企业信息融合难、数据碎片化等痛点,具备深度理解多模态记忆、模拟人脑记忆演进及海量记忆持久化存储等核心能力,已在金融、制造、游戏等行业应用,提升复杂决策水平。

清华刘知远团队ICLR 2026论文:短文本如何丝滑升级为长文本
清华大学刘知远团队提出稠密-稀疏可切换注意力框架,以解决大语言模型扩展上下文时的计算与结构适配问题。该方法保持原参数与输出形式,实现从短序列到长序列的高效平滑过渡。实验显示,其在多项长上下文任务中性能接近全注意力基线,且不损害原有短序列能力,推理时显著加速。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
