




北大团队ICLR论文:自适应时序预测损失函数学习新方法

在多步时间序列预测领域,一个普遍存在的挑战是预测性能会随着预测步长的增加而显著下降。无论是气象预报、金融市场分析还是电力系统负荷预测,我们都能观察到类似的规律:短期预测通常较为准确,但当预测范围扩展到数天甚至数周时,误差便开始累积放大,预测结果的周期性和趋势性结构也逐渐偏离真实数据。
面对这一长期预测难题,主流的研究方向往往是设计更复杂的神经网络架构,以期捕捉更长程的时间依赖关系。然而,一个常被忽略的根本性视角是:问题的症结或许不在于模型本身,而在于我们用来指导模型训练的“标尺”——即损失函数的设计。
目前,绝大多数方法仍在使用逐点均方误差作为核心优化目标。这一做法隐含了两个关键假设:未来不同时间点的预测值是条件独立的,并且所有预测步的优化重要性是均等的。但现实世界的时间序列数据真的符合这两个前提吗?例如,明天的气温与后天的气温毫无关联吗?预测未来一小时与预测未来一周的难度和不确定性相同吗?答案显然是否定的。
正是基于对这一核心矛盾的深刻洞察,林宙辰教授团队近期发表了题为《Quadratic Direct Forecast for Training Multi-step Time-Series Forecast Models》的研究。这项工作并未改动任何预测模型的结构,而是选择重构训练目标,通过显式地建模预测步之间的相关性以及不同步长的不确定性差异,仅从优化机制层面就显著提升了多步预测的精度与稳定性。这为我们理解并解决长期预测失效问题提供了一个全新且更本质的视角。

问题根源:均方误差的两个先验
当前时间序列预测领域的标准实践,是采用逐时间点的均方误差作为损失函数:
$$\mathcal{L}_{\text{MSE}} = \|\mathbf{y} - g_\theta(\mathbf{x})\|^2=\sum_{t=1}^\mathrm{T}\left(y_t-g_{\theta,t}(\mathbf{x})\right)$$
这个简洁的公式背后,实际上嵌入了两个强有力的先验假设:第一,未来不同时刻的预测值是相互条件独立的;第二,所有预测步在优化过程中的重要性是等同的。
然而,现实世界的时间序列数据通常表现出强烈的自相关性和异方差性。这意味着未来的观测值彼此关联,并且预测不同时间点的难度(即不确定性)存在显著差异。如果损失函数无法准确刻画这些内在的数据结构特征,那么模型在长期预测中表现出的系统性偏差,就并非偶然现象,而是训练阶段错误假设所导致的必然结果。

研究团队通过严谨的实证分析验证了上述两点。首先,他们对标签序列的条件协方差进行偏相关分析,发现在控制历史输入信息的影响后,未来不同时间点之间依然存在大量非零的偏相关系数,这直接否定了MSE所隐含的条件独立假设。
其次,他们对标签序列的条件方差进行分析,结果显示不同预测步的误差方差存在显著差异,并且整体上随着预测步长的增加而呈现增大趋势。这清晰地表明,将所有预测步视为难度一致的任务,并不符合数据的真实统计特性。
QDF:从数据中自适应学习预测损失
针对MSE存在的这两个结构性偏差,研究团队提出了QDF(二次直接预测)方法。其核心创新在于实现了一个范式转换:不再将损失函数视为一个固定不变的公式,而是将其本身作为一个可以从数据中“学习”出来的参数化对象。
从概率建模的角度出发,一个理想的损失函数应当源于数据的负对数似然。在高斯误差的假设下,给定历史序列,未来标签序列的条件分布是一个多元高斯分布。其对应的负对数似然(忽略常数项)可以表示为一个二次型:
$$\mathcal{L}_{\boldsymbol{\Sigma}}(\mathbf{x},\mathbf{y};g_\theta) = (\mathbf{y} - g_\theta(\mathbf{x}))^\top \boldsymbol{\bar{\Sigma}} (\mathbf{y} - g_\theta(\mathbf{x}))$$
其中,权重矩阵 $\boldsymbol{\bar{\Sigma}}$ 是标签序列条件协方差矩阵的逆。这个形式在理论上非常优美:权重矩阵的非对角元素刻画了未来不同时间点之间的条件相关性,从而能够显式建模标签的自相关效应;而对角元素则反映了不同预测步的不确定性差异,使得模型能为不同难度的预测任务分配不同的优化权重。这样一来,MSE的两个不合理先验就被同时打破了。
然而,在实际预测任务中,这个理想的权重矩阵 $\boldsymbol{\bar{\Sigma}}$ 是未知且难以直接估计的。为了解决这个问题,研究团队借鉴了元学习的思想,设计了一个双层优化机制来从数据中学习它:
$$\min_{\boldsymbol{\Sigma} \succeq 0} \mathcal{L}_{\boldsymbol{\Sigma}}(\mathbf{x}_{\text{out}}, \mathbf{y}_{\text{out}};g_{\theta^*}) \quad \text{s.t.} \quad \theta^* = \arg\min_{\theta} \mathcal{L}_{\boldsymbol{\Sigma}}(\mathbf{x}_{\text{in}}, \mathbf{y}_{\text{in}};g_\theta)$$
简单来说,这个机制分为内外两层循环。内层循环在给定权重矩阵 $\boldsymbol{\Sigma}$ 的情况下,使用一部分训练数据(元训练集)来更新预测模型参数 $\theta$。外层循环则根据更新后的模型在另一部分数据(元验证集)上的泛化表现,来反向更新和优化权重矩阵 $\boldsymbol{\Sigma}$ 本身。
这种设计的精妙之处在于,它让训练目标的优劣不再仅仅由对训练数据的拟合程度决定,而是由其在未见数据上的泛化能力来评判。通过多次迭代,算法能够学习到数据中稳定存在的误差相关模式,从而形成一个既符合统计原理又具备良好泛化性的自适应损失函数。
在大量实验中,一致验证优势
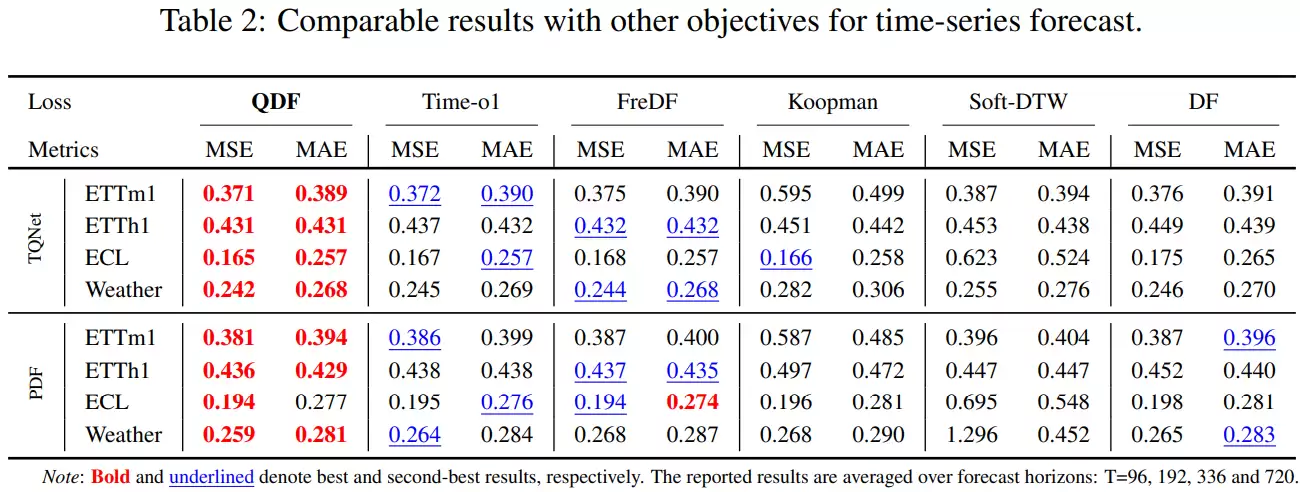
为了验证QDF方法的有效性,论文进行了广泛的实验评估。首先,研究人员将其与一些旨在削弱标签相关性的现有方法(如FreDF和Time-o1)进行了比较。结果显示,这些方法虽然相比MSE有所改进,但在稳定性和性能上限上均不及QDF。原因在于它们仅部分处理了标签相关性,而QDF则通过元学习同时建模了相关性和不确定性,更彻底地解决了损失函数的结构偏差问题。
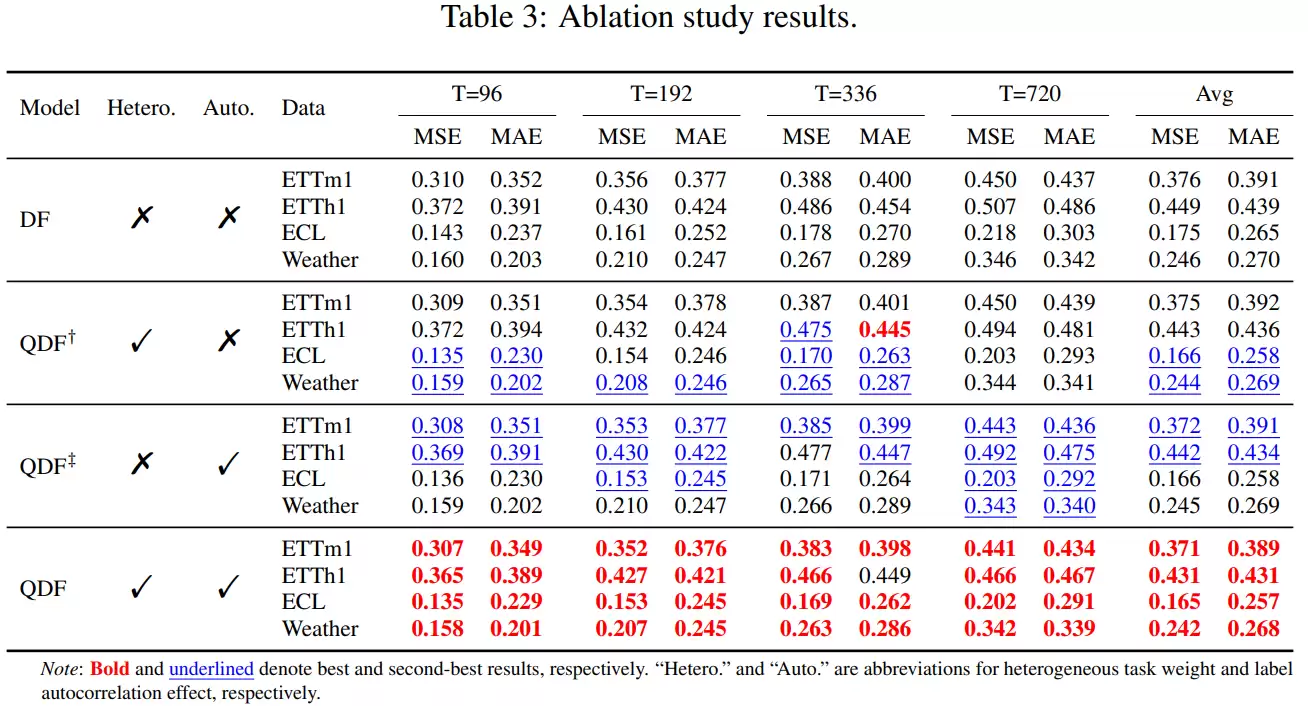
其次,通过消融实验,研究团队分别验证了“建模不同预测步权重”和“建模时间相关性”这两个关键因素的作用。实验表明,单独引入任何一个因素都能带来性能提升,而两者结合时效果最为显著,这证实了QDF设计思路的完备性。
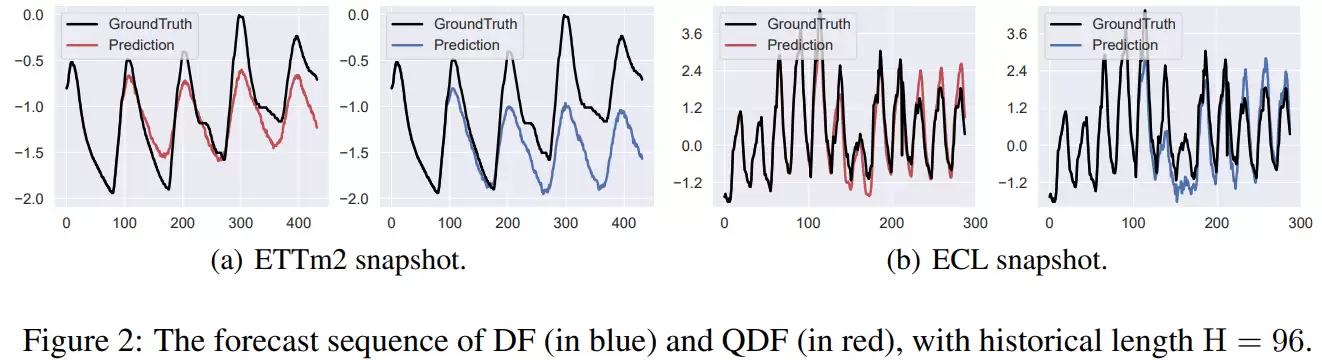
更有说服力的是对预测序列的可视化分析。基于MSE训练的模型,其预测结果在周期性序列中普遍存在振幅被压缩、峰值被抹平、拐点响应滞后等问题。而引入QDF后,模型的预测在峰值位置、周期相位和长期趋势稳定性上都与真实值保持了更高的一致性,时间序列的整体结构得到了更好的保留。
一次针对均方误差的系统性审视
从更宏观的研究意义来看,这项工作首先是对时间序列预测领域一个长期默认假设的系统性质疑与验证。它用严谨的分析和实验证明,将多步预测视为多个独立且等权重的回归任务,这一前提本身是站不住脚的。
更进一步,研究提出了一种新颖的方法论:将损失函数本身参数化并作为可学习的对象。这不同于传统的超参数调优或启发式设计,而是通过引入结构化的权重参数,显式地建模数据的内在特性,并利用元学习框架从泛化性能中直接学习最优的损失形式。这种方法使得训练目标能够自适应地调整,从而更贴合特定数据的统计规律。
对于后续的研究者而言,这项工作的启示超越了其具体的QDF方法。它强调了持续审视领域内“常识”的重要性,展示了如何从第一性原理(统计建模)出发推导合理的优化目标,并为元学习思想与领域特定知识的深度结合提供了一个优秀的范例。
作者信息
本论文的第一作者是浙江大学控制学院的博士研究生王浩,他的研究方向聚焦于因果推断、多任务学习技术及其在大语言模型中的应用。他曾于2022年至2023年在蚂蚁金服和微软亚洲研究院进行科研实习,从事推荐系统理论研究。自2025年起,他在小红书参与RedStar实习项目,进行大语言模型与可信奖励模型相关的研究。

论文的通讯作者是北京大学智能学院、通用人工智能全国重点实验室的林宙辰教授。他的研究领域涵盖机器学习和数值优化。林教授已发表学术论文360余篇,谷歌学术引用超过42,000次。他是IAPR、IEEE、AAIA、CCF和CSIG等多个国际学术组织的会士,并多次担任CVPR、NeurIPS、ICML等顶级会议的资深领域主席,现任ICML董事会成员。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

宇树人形机器人应用商店UniStore正式开放
今天,人形机器人领域迎来一个里程碑式进展。宇树科技正式宣布,其全球首创的人形机器人任务动作应用商店——UniStore官方共享应用平台,现已面向全球开发者与用户全面开放。 通俗地讲,UniStore平台相当于人形机器人的“专属应用商店”。开发者能够上传自主编写的机器人动作程序与任务模块,用户则可像在

Midjourney体积雾模拟教程 轻松营造氛围感画面
在Midjourney中创作具有真实空气感与空间深度的雾气效果时,你是否常遇到画面扁平或质感虚假的困扰?这通常源于提示词与参数组合不够精准——真正的体积雾效需要一套系统化的指令策略,而非简单添加“fog”一词。以下这套经过反复验证的实战方法,将引导你把“雾气”从一层单调的贴图,转化为真正弥漫于场景之

智能电池摄像头选购指南 灵活安装与安全监控全解析
如今,家庭安防的选择越来越丰富,其中,智能电池摄像头以其独特的灵活性和强大的安全性能,正成为许多用户的首选。它不再仅仅是“记录画面”,而是通过先进的目标检测算法,将主动预警和智能监控提升到了一个新高度。无论是实时记录动态,还是及时推送通知,都让安全防护变得更加主动和便捷。加上其免布线的安装特性和多样

双阶段方案让虚拟图像骗过AI眼睛游戏画面以假乱真
你是否好奇,游戏《GTA》中飞驰的汽车与现实中监控摄像头拍下的车辆,在人工智能的“视觉系统”里究竟有多大差别?尽管现代游戏画面已极为逼真,光影、材质与场景构建都栩栩如生,但对于自动驾驶、交通监控、智慧城市管理等需要落地应用的AI算法而言,虚拟游戏图像与真实世界照片之间,依然横亘着一道肉眼难以分辨、却

英伟达黄仁勋今年AI投资3080亿接近收购DeepSeek成本
最近科技圈有个数字挺震撼的:截至5月11日,英伟达在2026年对AI产业承诺的总投资额,已经超过了453亿美元。这是个什么概念?做个对比,就在几天前,有外媒报道称当红AI公司DeepSeek的估值或将超过3500亿软妹币。这么一看,英伟达今年光承诺要投出去的钱,就快赶上这家明星独角兽的估值了。 这笔








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
