




清华团队与深言科技合作 8B小模型幻觉检测超越闭源大模型

大语言模型的能力边界持续扩展,但“幻觉”问题始终是阻碍其迈向严肃应用的关键障碍。即便在提供明确文档和检索依据的情况下,模型仍可能生成与事实不符、缺乏支撑或自相矛盾的内容,且其表达往往流畅自信,极具迷惑性。这对于法律、医疗、金融等容错率极低的领域,以及日益普及的检索增强生成(RAG)应用,构成了切实的风险与挑战。
业界常见的解决方案是投入更多算力、构建更复杂的检索系统或进行更严格的安全对齐,但这些方法成本高昂,且未能从根本上回答核心问题:大模型幻觉究竟为何产生?又该如何系统性地检测与解释?近期,清华大学孙茂松团队与深言科技合作发表的新研究《FaithLens: Training Large Language Models to Detect Hallucinations with Useful Explanations》,为我们提供了一个全新的解题视角。这项工作的核心突破在于,它不再将幻觉检测视为简单的“是非判断题”,而是将其升级为对模型整个推理过程与证据一致性进行全面评估的“分析题”。
FaithLens 的创新思路清晰:一个合格的检测模型,不仅要能判断“是否存在幻觉”,还必须能生成清晰、具体、真正能帮助其他模型或人类理解其判断依据的解释。更重要的是,这种“解释是否有用”被直接作为训练信号,用以优化模型自身。研究团队设计了一套融合监督微调与强化学习的训练框架,通过合成数据、严格过滤和精心设计的奖励机制,让模型在给出结论的同时,也学会了阐明其推理路径与证据依据。实验结果表明,在这一新范式下,仅拥有80亿参数的模型,就在多个跨领域的幻觉检测任务上超越了多款闭源大模型,同时在解释质量与推理一致性方面表现卓越。

小体量,大能量:8B模型实现性能反超
这项研究最引人瞩目的成果,是其提出的FaithLens模型在“忠实性幻觉”检测任务上达到了当前最优水平,甚至实现了对多款闭源大模型的超越。这里所说的“忠实性幻觉”,特指大语言模型在基于给定文档或检索信息生成内容时,产生了与原文不一致、缺乏支持或直接矛盾的信息。
为全面验证模型能力,实验覆盖了12个跨领域、跨任务的数据集,场景包括新闻摘要、检索增强生成问答、固定文档问答、事实核查以及多跳推理等。这些数据集均源自LLM-AggreFact和HoVer两大权威基准,具有广泛的代表性。评价指标采用宏平均F1值,从最终结果看,FaithLens在12个任务上的整体平均表现超越了所有参与对比的系统。
尤为值得注意的是,其对比对象包括了GPT-4.1、GPT-4o、o3、Claude 3.7 Sonnet以及Llama-3.1-405B等当前顶尖的开放或闭源模型。FaithLens仅凭8B的参数量,在整体性能上取得领先,这一结果极具分量。尤其是在要求综合多个证据片段进行事实链推理的HoVer多跳推理任务上,FaithLens的优势更为显著。这表明它并非仅仅依赖浅层的模式匹配,而是真正具备了在文档基础上进行结构化推理和一致性深度分析的能力。
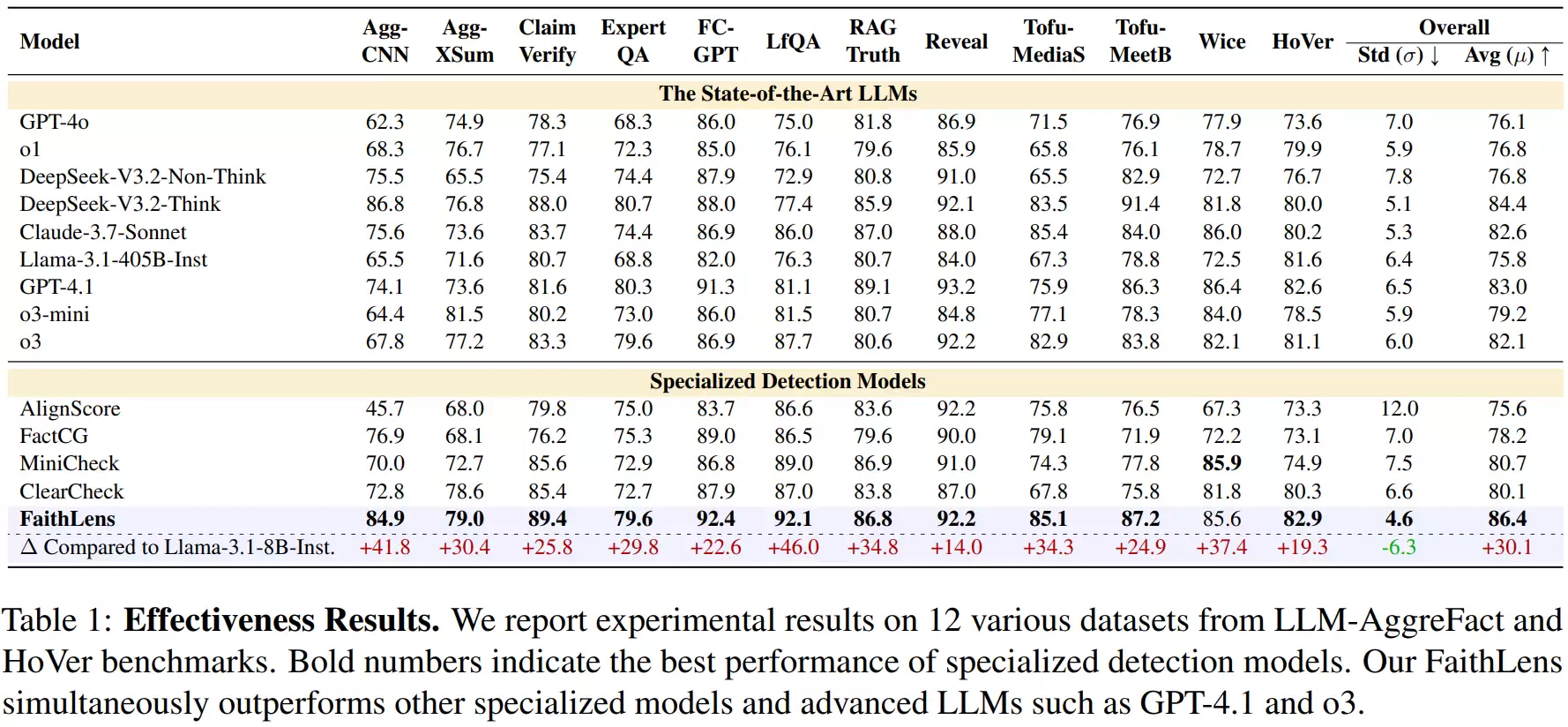
研究还将其与AlignScore、FactCG、MiniCheck、ClearCheck等专为幻觉检测设计的系统进行了对比。结果显示,在绝大多数任务中,FaithLens的表现显著优于这些专用系统,并且在跨任务间的性能波动最小。这说明它对不同类型的幻觉现象——无论是摘要中的细微扭曲、问答中的无中生有,还是推理中的逻辑缺环——都具备统一的识别能力,展现出优秀的鲁棒性和泛化性。
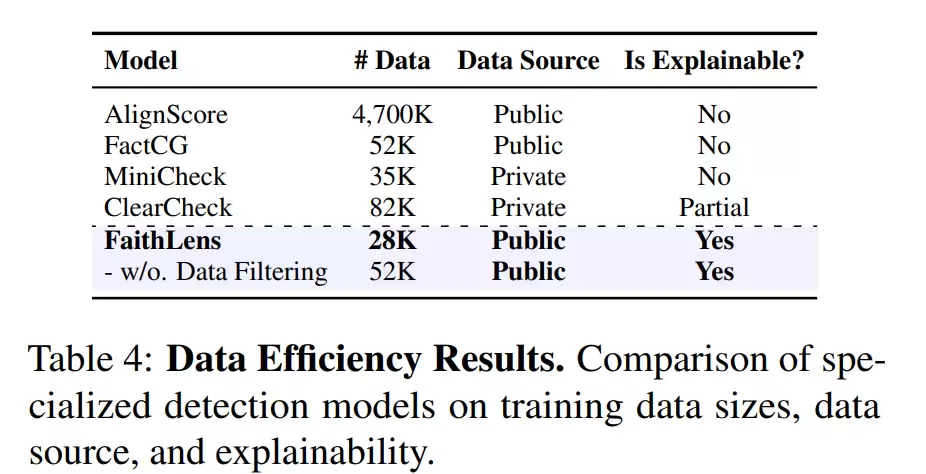
除了判断准确性,解释生成的质量是另一个关键评估维度。通过人工评价和GPT-4.1自动评价两种方式,从可读性、帮助性和信息量等角度进行系统比较后发现,FaithLens生成的解释更为清晰和具体。它能够有效指出幻觉产生的根源,例如“文档中未提及该事实”、“因果关系推断错误”或“数字被曲解”,而不是简单地重复问题或给出模糊笼统的说法。
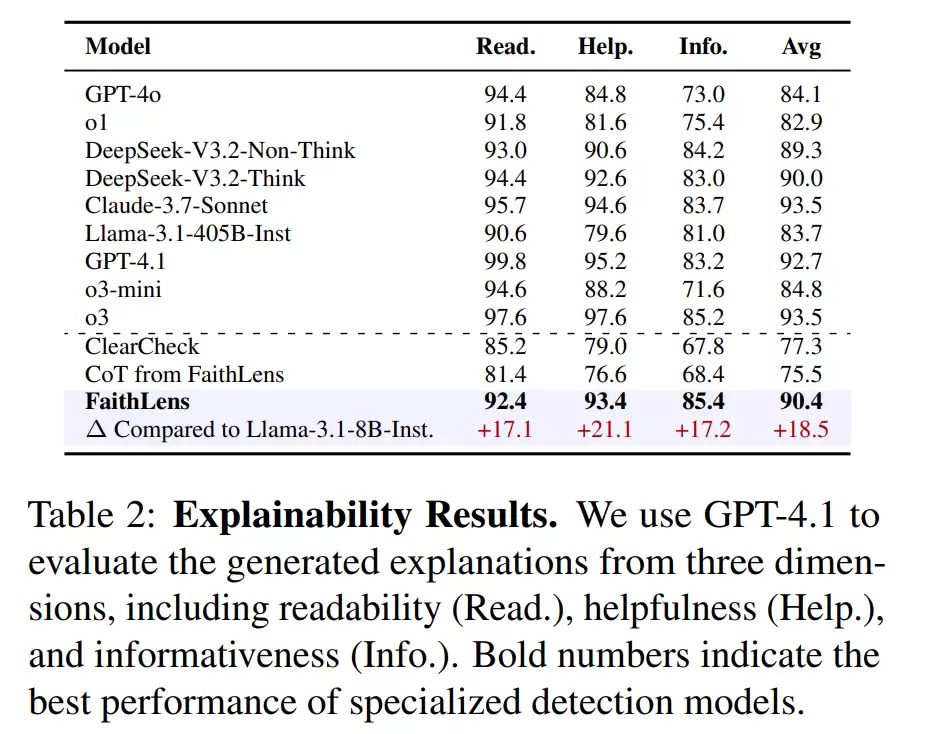
当然,在实际部署中,计算成本是无法回避的因素。实验对比了不同模型在同等计算规模下的推理成本,由于参数量小,FaithLens所需的GPU资源显著低于API级别的闭源大模型,在成本上具备巨大优势,同时性能却更优。综合来看,FaithLens在检测精度、任务稳定性、解释可读性以及部署成本这四个维度上,都展现出了明显的竞争力。
三位一体的训练哲学:准确、有用、规范
如此出色的性能,背后是一套完整且精巧的训练框架。该框架包含两个核心阶段:冷启动监督微调(SFT)和基于规则的强化学习(RL)。其设计目标并非单纯提升分类准确率,而是要同步优化两个输出:一是对是否存在幻觉的二元判断,二是支撑该判断的自然语言解释。
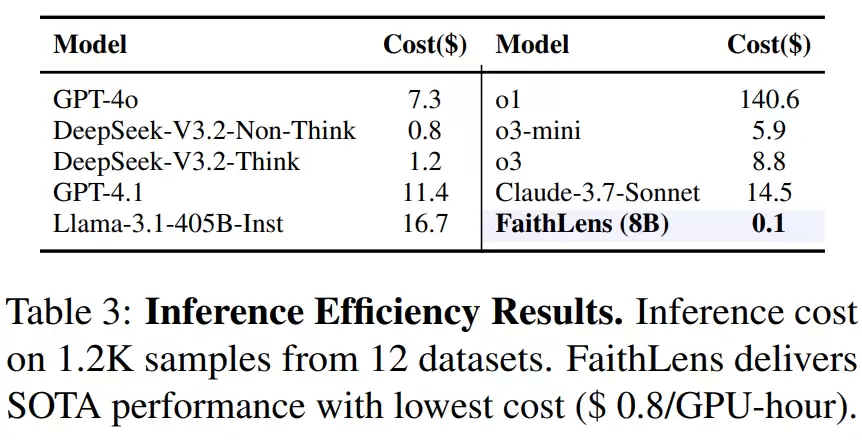
在SFT阶段,首要挑战是获取高质量的训练数据。传统的人工标注方式成本高昂且一致性难保证。为此,研究团队另辟蹊径,利用现有的大规模推理模型来生成合成数据。具体方法是,从公开数据集中抽取文档和断言,输入给强大的推理模型,让它同时输出推理链、自然语言解释和判断标签。这样,每个训练样本都包含了完整的上下文、任务断言、模型推理过程、解释和最终结论。
然而,合成数据的质量参差不齐。为此,研究人员设计了一套三层过滤机制来严格把关:
第一层,过滤标签正确性。 比较合成模型给出的标签与数据集的原始标注是否一致,不一致则丢弃。这防止了模型学到“看似合理但结论错误”的案例,确保解释与真实标签紧密关联。
第二层,过滤解释有用性。 这是关键创新。团队没有采用主观的人工打分,而是提出了一个客观指标:解释是否能提升预测能力?具体做法是,先计算模型在没有解释的情况下预测标签的“困惑度”,再加入解释重新预测。如果困惑度下降,说明解释提供了有效信息;反之,则被视为冗余或误导性解释,连同样本一起剔除。
第三层,过滤数据多样性。 前两层过滤可能留下大量“简单样本”,导致模型过拟合。因此,团队使用句向量对文档-断言进行表征,通过聚类算法控制不同类别样本的分布,确保模型能接触到各种复杂的幻觉类型。
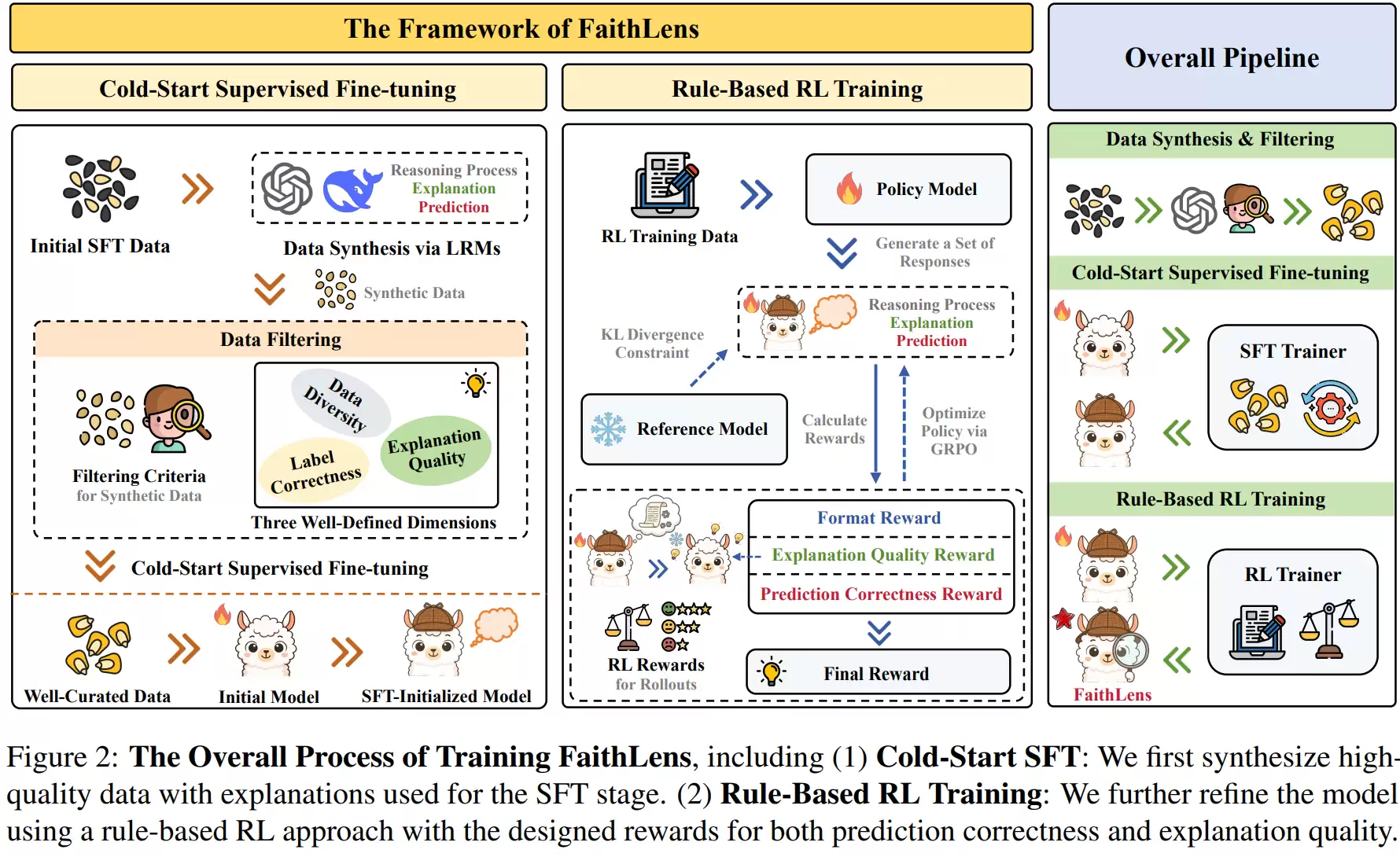
经过三重过滤的数据用于监督微调,让模型初步掌握检测和解释的能力。但SFT本质上是模仿学习,模型倾向于复制数据中的模式,缺乏优化动力。因此,研究引入了第二阶段的基于规则的强化学习。
在RL阶段,模型针对同一输入生成多条候选输出(含推理、解释和标签)。研究采用GRPO算法进行优化,该算法无需训练额外的奖励模型,直接利用同一组候选之间的相对优劣来更新策略,更加高效。奖励函数的设计是精髓所在,包含三项:
1. 预测正确奖励: 直接奖励模型做出正确的幻觉判断,提升分类准确性。
2. 解释质量奖励: 这是核心贡献。研究引入一个能力较弱的“新手模型”作为评价器。将FaithLens生成的解释提供给新手模型,如果新手模型凭借该解释更容易做出正确判断,那么这条解释就被认为是有用的,从而获得高奖励。这迫使模型学习生成“对他人有帮助”的解释,而非自说自话。
3. 格式奖励: 用于约束输出结构的完整性,确保包含推理、解释和标签三部分,避免缺失或混乱。
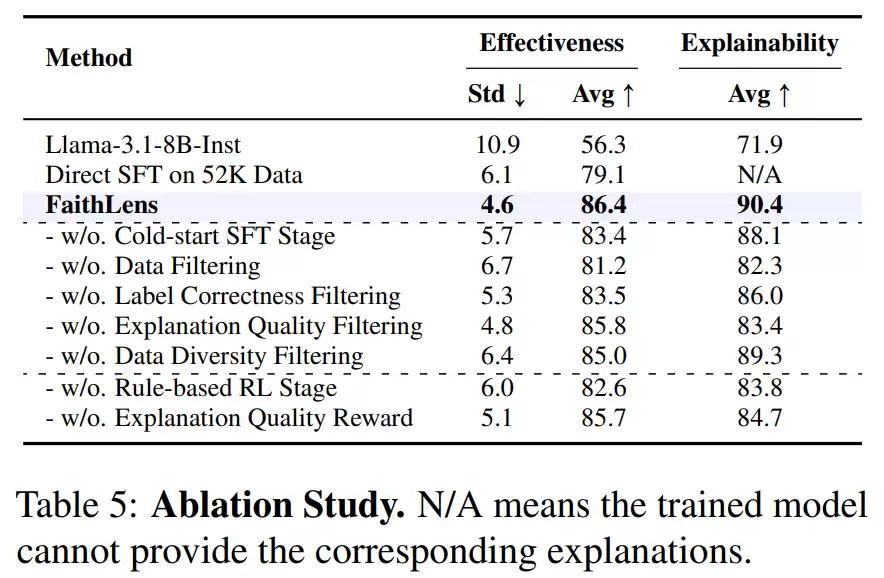
通过这三重奖励的协同作用,FaithLens在RL阶段学会了同时兼顾判断的准确性和解释的实用性。后续的消融实验也证实,三重过滤机制、解释质量奖励和RL阶段都是提升最终性能的关键组件,其中解释质量奖励对提升解释的可用性贡献尤为显著。
从黑箱判别到透明可解释:范式转变的意义
这项工作的学术价值,在于它推动幻觉检测从简单的“黑箱”判别,转向了“透明可解释”的推理评估。以往的检测模型往往只给出一个“是”或“否”的结论,用户既不知道依据何在,也无从追溯错误源头。FaithLens的框架要求模型同时回答“对不对”以及“为什么”,使得检测过程本身变得可审查、可复核,这大大增强了系统的可信度与可审计性。
在应用层面,它巧妙地解决了一个现实矛盾:顶尖的闭源大模型虽然能力强,但API调用成本高昂,难以大规模部署;而小型模型成本低,但检测质量往往不达标。FaithLens证明,通过精妙的数据合成策略和强化学习方案,中等规模的模型完全可以在检测与解释能力上媲美甚至超越闭源大模型,为高可靠性场景的落地提供了高性价比的解决方案。
从方法论上看,研究团队提出了一种衡量解释质量的新思想:以“能否教会另一个模型”作为标准。 这跳出了传统上依赖BLEU、ROUGE等表面文本相似度的评价框架,将解释视为一种功能性的工具。这一思路不仅适用于幻觉检测,未来完全可以推广到推理链验证、数学解题说明、事实核查报告生成等领域。
更深层次的意义在于,这项研究为AI的可信性设立了新的标准。它隐含着一个重要观点:未来的智能系统不能仅仅满足于输出答案,还必须提供可追溯、可核验、并能被其他智能体理解使用的解释过程。这与医疗诊断、司法判决、金融审计、教育评估等高风险领域对过程透明和结果可审计的刚性需求高度契合,其社会价值远不止于技术层面。
成果背后的科研力量
本论文由来自清华大学、复旦大学以及伊利诺伊大学香槟分校(UIUC)的三位研究者共同担任第一作者,他们主导了这项工作的研究推进与论文撰写。
其中,来自清华大学的司书正(同时就职于深言科技)现为清华大学计算机系二年级博士生,师从孙茂松教授。他的研究方向聚焦于自然语言处理与大语言模型。此前,他已以第一作者或共同第一作者身份在NeurIPS、ACL、ICLR、EMNLP等顶级会议上发表论文12篇,相关论文累计被引用800余次,其GitHub项目获得了超过5000颗星标,其中一篇第一作者论文曾获得EMNLP 2025 SAC Highlights Award。

本论文的通讯作者孙茂松教授,是清华大学计算机科学与技术系长聘教授、博士生导师,我国自然语言处理与人工智能领域的重要学者。他现任清华大学人工智能研究院常务副院长,并兼任校内多个重要学术机构的负责人,长期深耕于教学、科研与人才培养一线,对我国NLP学科体系的建设产生了深远影响。
孙茂松教授拥有扎实的语言学与计算机科学交叉背景。作为清华大学自然语言处理实验室的主要学术带头人,他的研究方向涵盖中文信息处理、机器翻译、语义计算、大模型训练与推理、语言资源与知识图谱等多个核心领域。他带领团队围绕NLP的基础理论与关键技术开展系统性研究,成果发表于ACL、EMNLP、AAAI、IJCAI等顶级会议与期刊,并主持了多项国家级重大科研项目。
除了学术研究,孙茂松教授也积极推动技术转化与社会服务,致力于将语言智能技术应用于教育普惠、文化传承与公共治理等实际场景,主持推动了多项具有社会影响力的工程与平台建设。在学术荣誉方面,他获得了包括国际学术组织会士在内的多项重要荣誉,其培养的学生和团队成员也已在国内外成长为相关领域的骨干力量。
总体而言,孙茂松教授既是中国自然语言处理领域的早期开拓者之一,也是近年来大语言模型与可信AI研究的重要推动者。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Perplexity AI学术模式使用指南:精准获取高质量参考文献
在Perplexity中进行学术文献检索时,若发现结果中混杂着大量新闻、博客或商业推广页面,而高质量的期刊论文、预印本等学术资源却寥寥无几,这通常意味着未能正确启用其“学术搜索”功能。要让AI助手精准定位具有参考价值的学术文献,掌握以下几个关键步骤至关重要。 一、启用Academic学术模式并验证账

最先被AI淘汰的将是这些公司而非员工
Daniel Miessler 曾一针见血地指出一个普遍困境:“许多公司并非不愿采用AI,而是根本不知从何用起。人们对AI效果未达预期的多数失望,根源往往在于无法精准描述自身的真实需求。” 这一洞察揭示了AI应用的核心前提:AI本质是高效执行者,它依赖明确、清晰的指令。意图模糊,再先进的模型也无能为

AI三维空间感知与几何理解机制原理解析
如今的人工智能技术,已经能够在毫秒级别识别厨房照片中的物体,精准分割街景中的每个元素,甚至生成现实中从未存在过的逼真室内图像。然而,当你要求它走进一个真实的房间,回答“哪个物品放在哪个架子上”、“桌子距离墙壁有多远”或“天花板与窗户的边界在何处”这类涉及空间关系的问题时,它的局限性便暴露无遗。 当前

苹果Siri虚假宣传和解案:用户最高可获647元赔偿指南
5月初,科技界传来一则重磅消息:苹果公司就一起涉及Siri人工智能功能的集体诉讼达成和解,同意支付高达2 5亿美元(约合17亿软妹币)的赔偿金。这意味着,在2024年6月至2025年3月期间于美国购买了特定型号iPhone的用户,将有机会获得每台设备25至95美元(约合170至647元软妹币)的补偿

AI编程基准测试新作发布主流模型表现引热议
编辑|Sia SWE-Bench的缔造者们,最近又扔出了一枚重磅冲击波——一个堪称地狱级难度的新基准测试。 结果一出,整个圈子都安静了。 Claude Opus 4 7、GPT-5 4、GPT-5 mini、Gemini 3 1 Pro、Gemini 3 Flash……这一代所有站在金字塔尖的顶级模








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
