




上交大智能计算研究院ICLR论文:大模型如何掌握运筹建模而非仅求解

当大语言模型从通用人工智能工具迈向垂直专业领域时,运筹优化(Operations Research, OR)无疑是一个极具潜力又充满挑战的赛道。其吸引力在于,运筹问题通常具备严谨的数学形式和可验证的答案,似乎天然适合自动化建模。然而现实更为复杂:真正的工业级运筹建模,涉及变量定义、约束条件与目标函数之间环环相扣的逻辑体系,牵一发而动全身。这远不止是求解一个正确答案,而是一个高度依赖步骤顺序、强调逻辑一致性的复杂推理过程。
正是在这种理想与现实的差距下,当前运筹建模大模型的研究面临一个核心难题:模型能调用求解器得出数值结果,并不代表其构建的数学模型本身是正确的。问题的根源在于训练范式——无论是仅依据最终答案给予奖励,还是对中间步骤进行孤立、片段的监督,都难以精准评估运筹建模这种长链条、强耦合推理的真实质量。监督信号与任务本质之间的错位,使得建模过程中的错误可能被掩盖甚至被强化,这已成为大模型迈向实际工业运筹应用的核心障碍。
针对这一挑战,上海交通大学智能计算研究院的葛冬冬、林江浩研究团队提出了创新解决方案:《StepORLM: A Self-Evolving Framework with Generative Process Supervision for Operations Research Language Models》。他们没有盲目追求模型规模或数据量,而是从训练机制的底层进行革新,设计了一种由策略模型与“生成式过程奖励模型”协同进化的自进化训练框架。其核心思想是,将最终求解结果与对完整推理链条的全局性、回顾式评估相结合,从而引导模型真正掌握构建逻辑一致、可靠可用的运筹模型的能力,而非仅仅生成一个偶然可行的代码。

方法论取胜:小模型实现大性能
该研究在6个具有代表性的运筹优化基准数据集上进行了全面测试,覆盖了从基础线性规划到贴近真实场景的复杂混合整数规划问题。评估标准极为严格:模型仅单次生成解题轨迹,必须通过外部求解器的完整验证——即代码可执行、建模逻辑正确、且结果被判定为可行并最优,方计为成功。
实验结果令人印象深刻。首先,与零样本提示的通用大模型相比,参数量仅80亿的StepORLM,其平均准确率显著超越了DeepSeek-V3(6710亿参数)和Qwen2.5-720亿参数等巨型模型,也全面优于GPT-4o的零样本表现。尤其在ComplexOR和IndustryOR等高难度、贴近工业的测试集上,优势更为突出。这清晰地表明:在运筹建模任务上,参数规模已非关键,精心设计的训练范式与精准的监督信号才是提升性能的核心。
其次,与那些专门为OR任务进行过微调的基线模型相比,StepORLM在所有基准测试中均取得了领先的成绩。在NLP4LP、ComplexOR等极度依赖多步骤严密推理的任务上,提升幅度尤为显著。这证明其性能增益并非源于更多训练数据,而是来自于更高质量、更贴合运筹建模本质的监督信号。
再者,与需要多次采样或试错的智能体(Agent)方法相比,StepORLM仅凭单次生成就能获得更稳定、错误更少的输出。根本区别在于,智能体方法是在推理阶段对已有输出进行“事后修正”,而StepORLM则在训练阶段就引入了过程级监督,从源头上减少了错误推理模式被学习与固化的概率。
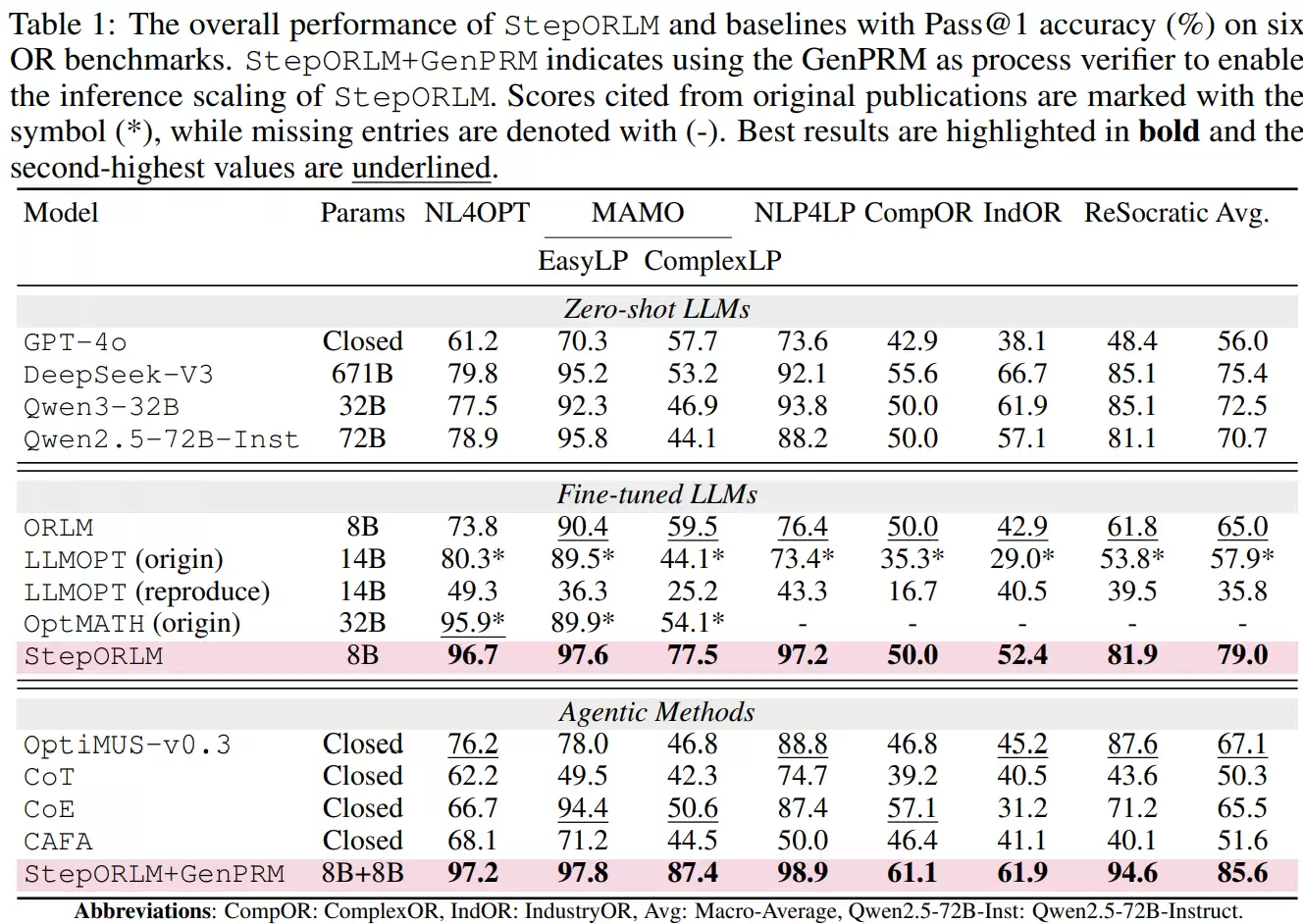
研究还评估了将训练好的生成式过程奖励模型用作推理阶段“验证器”的效果。结果显示,当StepORLM的策略模型与该奖励模型协同工作时,平均准确率可进一步提升至85.6%,在最具挑战性的两个数据集上分别获得了约9.9%和9.5%的显著提升。更重要的是,这个奖励模型具有良好的通用性:当它与其他运筹建模大模型结合时,同样能带来接近10%的性能提升。这表明它学习到的是模型无关的、通用的运筹推理质量判据,而非针对特定模型的过拟合技巧。
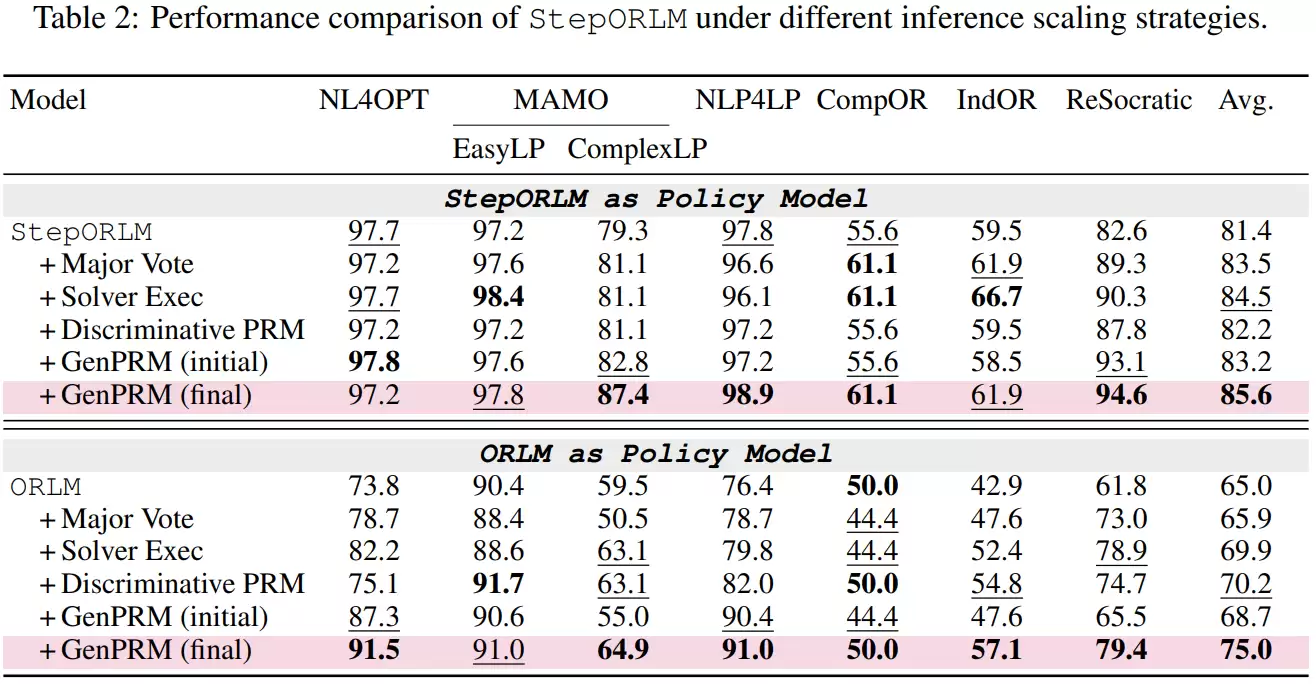
一系列消融实验验证了框架中各组件的必要性:移除预热阶段的监督微调,性能会大幅下降;取消自进化训练,模型性能很快达到瓶颈;如果冻结奖励模型不让其更新,或使用普通的偏好优化方法替代加权的版本,学习效果都会打折扣。训练过程分析也清晰显示,模型性能的提升是随着自进化迭代轮次逐步、稳定累积的。
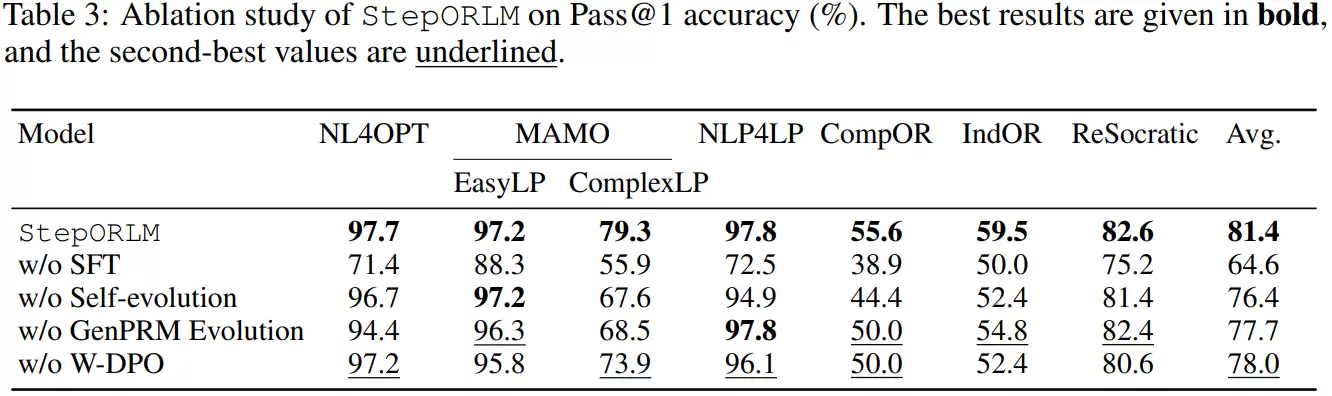
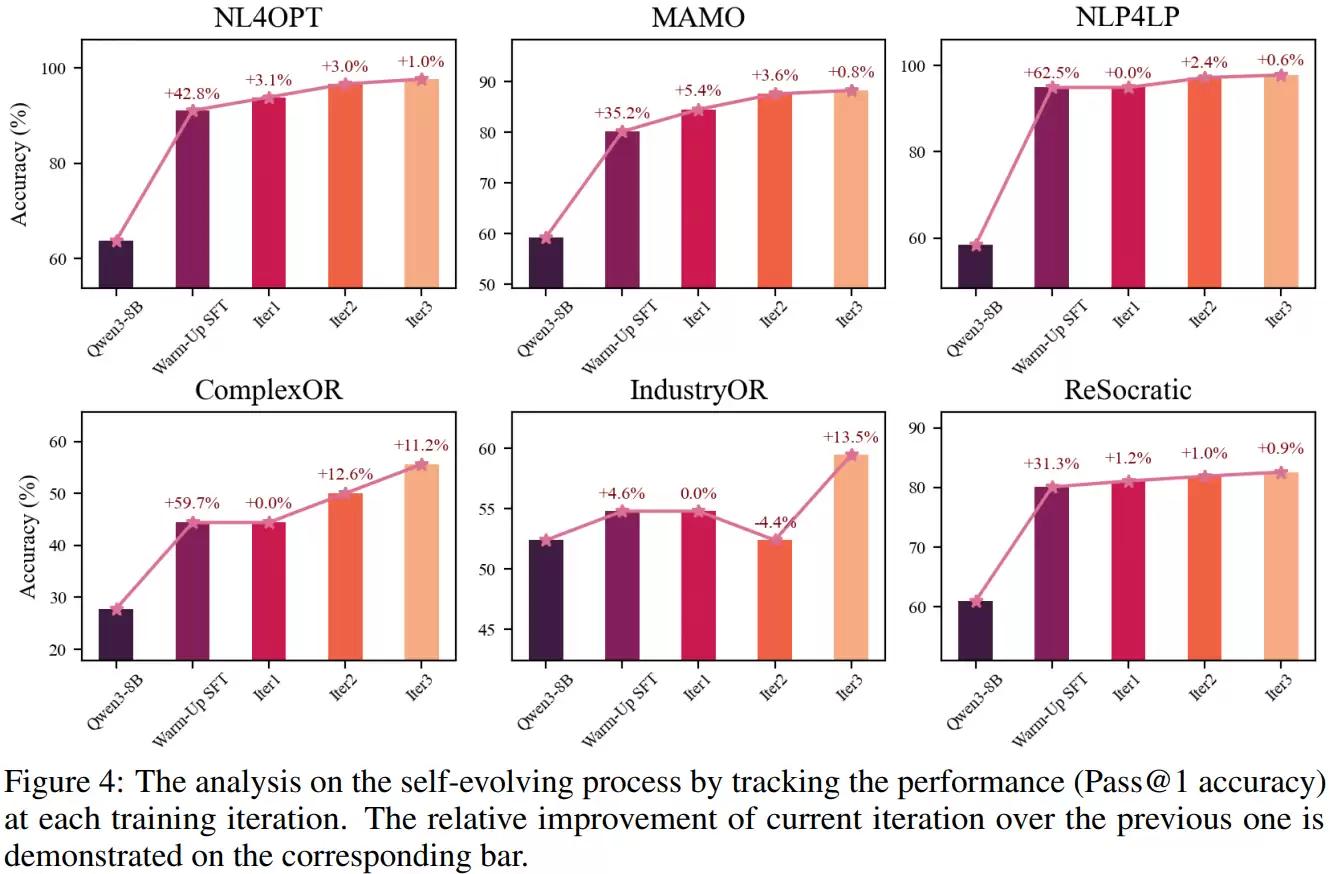
从偶然正确到系统可靠:解决核心训练缺陷
这项研究精准定位了大语言模型在运筹建模中可靠性不足的根源。研究团队指出,现有方法主要存在两类根本性缺陷。
第一类是“结果导向奖励的信用分配难题”。即仅根据外部求解器是否成功运行并输出结果来奖励模型。这种方式存在风险:只要最终数值解正确,即使中间建模逻辑存在瑕疵,模型也会受到正向强化。在运筹场景中,例如遗漏一个非紧约束,或变量定义存在模糊性,可能在特定算例中不影响最优值,但会让模型误判这种不严谨的建模方式是可接受的,从而将不稳定甚至错误的逻辑固化下来。
第二类缺陷是“传统过程监督的短视性”。这类方法通常对推理的每一步进行独立打分,难以理解步骤之间的长期依赖与全局影响,也无法判断某个早期决策在整体建模语境下是否合理。然而,运筹建模恰恰是一种步骤高度耦合、前后逻辑严密的长链条推理,这种割裂的、局部的监督信号,很难准确反映整体推理的质量。
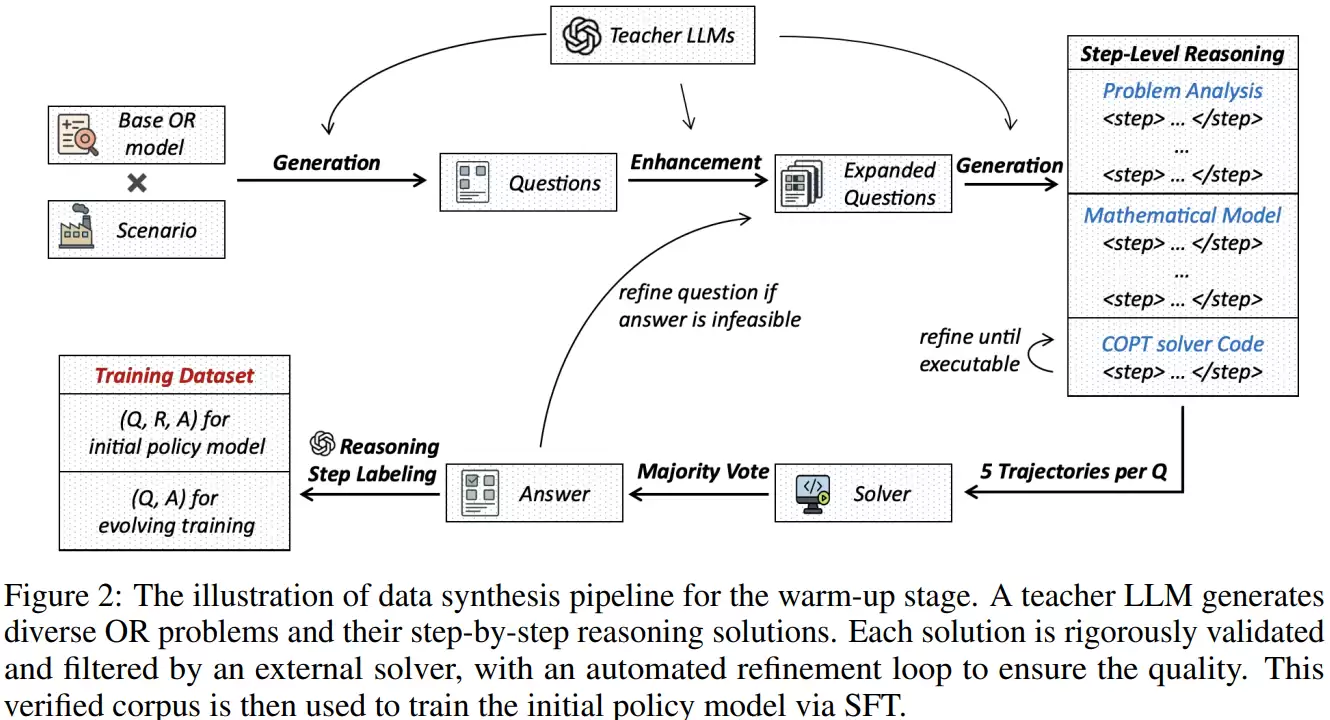
针对这些问题,StepORLM框架采用了“两阶段训练+自进化闭环”的创新设计。第一阶段是预热,目标是构建一个具备基本运筹建模能力的初始策略模型。研究人员利用教师模型自动生成多样化问题,并为每个问题生成覆盖问题分析、变量定义、模型构建、代码实现全过程的详细推理轨迹,经过严格验证后,用于对策略模型进行高质量的监督微调。
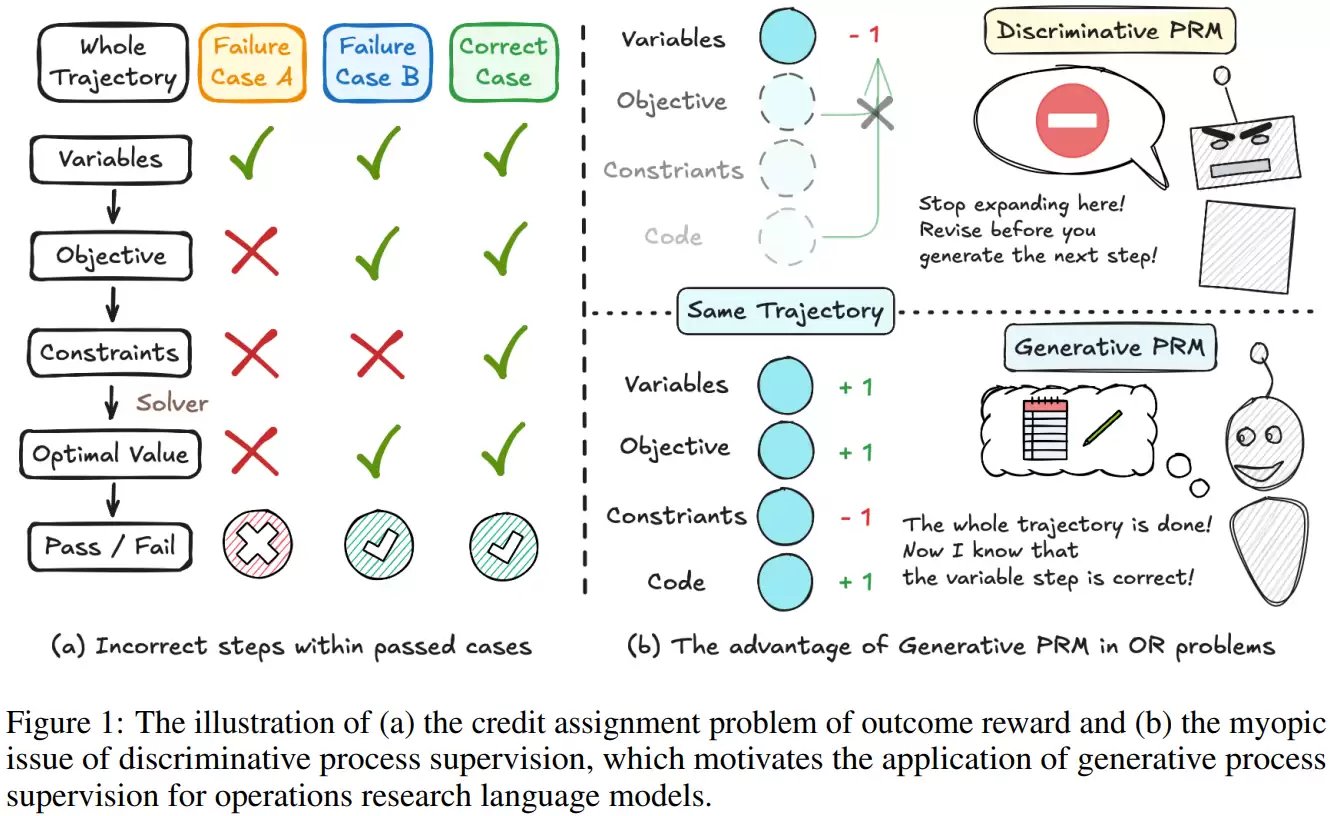
第二阶段是核心创新:策略模型与生成式过程奖励模型的协同进化。系统并行维护这两个模型:策略模型负责生成完整的解题轨迹;生成式过程奖励模型则扮演“全局审查官”的角色,从整体视角回顾并评估整条推理过程的逻辑一致性与合理性。它并非进行简单的单步打分,而是具备综合判断能力,能敏锐捕捉步骤间的依赖关系与潜在矛盾。
在每一轮迭代中,策略模型对同一问题生成多条候选轨迹,并接受“双源反馈”的评估:一是外部求解器给出的最终结果正确性反馈;二是奖励模型给出的过程质量评分。基于此,不同轨迹被两两比较以构造偏好对——求解成功的轨迹优于失败的,结果相同时则过程质量高的胜出。研究团队进一步引入了加权的偏好优化方法,以区分严重逻辑错误与细微改进,从而更精准地更新策略模型。
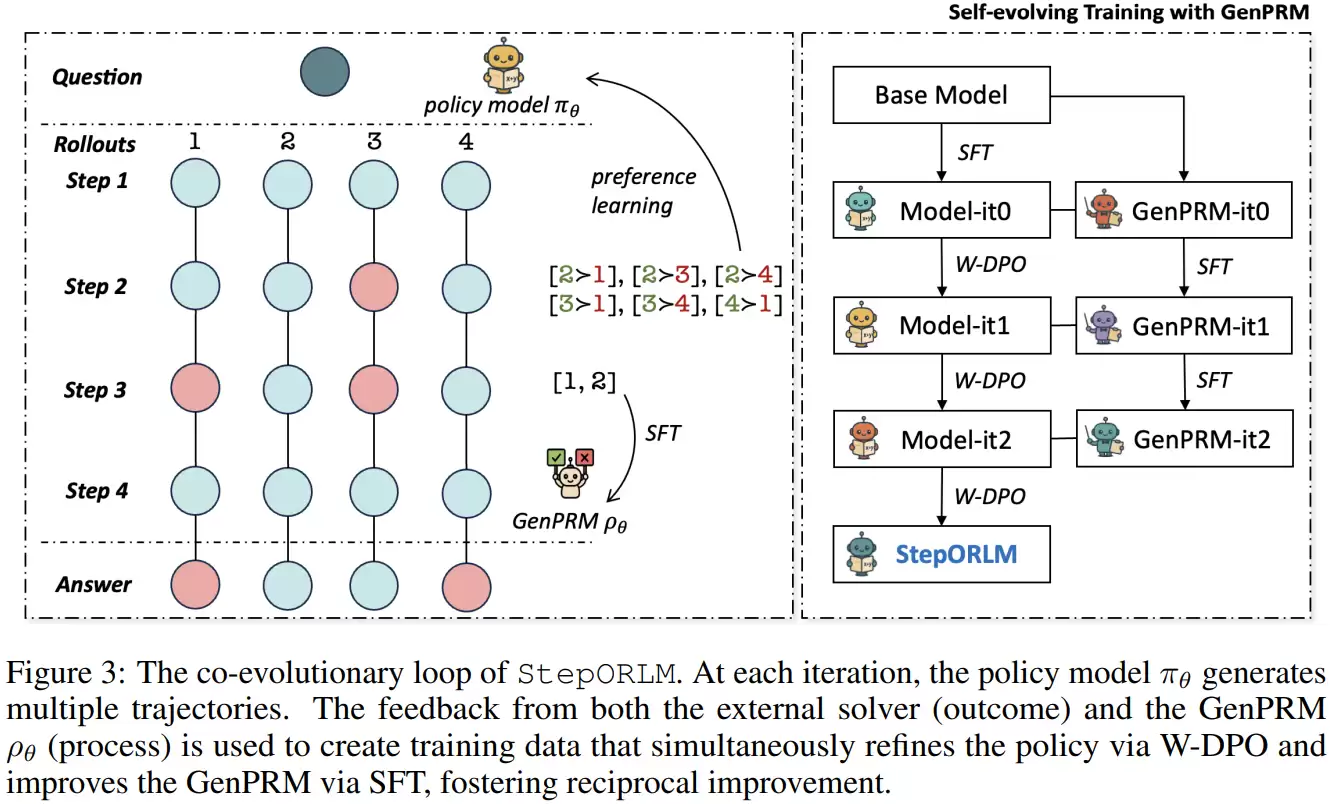
与此同时,生成式过程奖励模型自身也利用新产生的高质量轨迹进行持续微调,使其评估标准变得越来越精准、严格。由此,一个强大的正反馈闭环得以形成:策略模型生成更优质的轨迹,为奖励模型提供更好的训练样本;进化后的奖励模型又能给出更精确的过程反馈,进一步指导策略模型提升。二者在这种协同进化中,共同推动整个系统的运筹建模能力迈向更高水平。
一种可迁移的通用训练范式
这项研究的价值,不仅在于显著提升了运筹建模任务的性能指标,更在于其方法论上的普适性启示。首先,它明确并验证了一个关键洞见:在运筹优化这类强步骤依赖的复杂推理任务中,如果奖励模型本身缺乏深度的推理理解能力,就很难为策略模型提供有效的监督信号。传统那种“结果正确即代表推理正确”的假设,或认为对中间步骤逐步打分就能解决问题的想法,在此类场景下都存在系统性偏差。只有具备整体理解能力的“生成式过程监督”,才能有效缓解信用分配错误和评估短视的问题。
其次,在运筹优化与大模型交叉的研究领域,这项工作显著提升了模型在建模正确性、约束完整性以及实际应用可靠性方面的表现。通过引入过程级监督与自进化机制,模型不再仅仅是“会编写优化代码”,而是向“能进行严谨、可靠的运筹学建模”迈出了坚实一步。
更进一步看,该研究提出的训练范式,其思想内核具有广泛的迁移潜力。它所强调的“整体化、回顾式过程监督”理念,完全可以应用于数学定理证明、复杂代码生成、科学计算建模等其他需要长链条、强逻辑推理的任务中,为解决此类场景下监督信号失真、模型可靠性不足的共性难题,提供了一条极具借鉴意义的新路径。
本论文的第一作者是上海交通大学智能计算研究院的博士生周宸宇,导师为叶荫宇教授和葛冬冬教授。他的研究方向聚焦于大语言模型与运筹优化、复杂推理任务的训练方法创新。除学术研究外,他也在产业界积累了丰富的人工智能与优化求解相关实践经验。

论文的通讯作者是林江浩博士,现任上海交通大学安泰经济与管理学院助理教授。他的研究方向涵盖大语言模型、AI智能体及其在推荐系统、运筹优化等领域的交叉应用,已在相关领域发表了多项具有影响力的研究成果。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

揭秘Sora之父离职五大真相
OpenAI核心科学家皮布尔斯因公司战略商业化、研发资源被挤压及版权合规困境离职,标志Sora项目受挫。其出走折射出资本意志与科研理想间的冲突,并引发团队离职潮。与此同时,中国AI视频行业凭借紧密的商业结合、高效的算力利用及灵活的合规策略,在全球赛道中展现出差异化优势。

5年3D打印实践揭示世界模型的规模扩展定律
世界模型成为科技巨头竞争焦点,其核心是让AI理解物理规则。魔芯科技创始人陈天润从3D打印转向空间智能,发现该领域同样存在数据规模效应。团队基于国产算力开发出高效、可终端部署的世界模型,并凭借消费电子领域的成本控制与工程化经验,推动技术在具身智能、自动驾驶等场景商业。

松应科技发布ORCA Lab 1.0 国产物理AI操作系统替代方案
英伟达Omniverse定位为物理AI操作系统。松应科技推出ORCALab1 0,旨在构建基于国产GPU的物理AI训练体系。针对机器人行业数据成本高、仿真迁移难的问题,平台提出“1:8:1黄金数据合成策略”,并通过高精度仿真提升数据可用性。平台将仿真与训练集成于个人设备,降低开发门槛,核心战略是在英伟达生态垄断下推动国产替。

上海人工智能实验室联合商汤共建AI全链路验证平台与生态社区
上海人工智能实验室联合多家机构发起国产软硬件适配验证计划,致力于打造覆盖AI全流程的验证平台与自主生态社区。该平台旨在解决国产算力与应用协同难题,构建从芯片到应用的全链路验证体系,支持多种软硬件适配,推动国产AI技术向“好用、易用”发展。商汤科技依托AI大装置深度参与,已。

达闼科技陨落一周年回顾具身智能独角兽兴衰启示录
具身智能行业资本火热,但曾估值超200亿元的达闼科技迅速崩塌。其失败主因在于创始人黄晓庆以通信行业思维经营机器人业务,过度依赖政商关系与资本运作,技术产品突破有限;同时股权结构复杂分散,倚重政府基金,最终因融资断档与商业化不足导致团队离散。这折射出第一代创业者跨。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
