




揭秘GPT、Claude、Gemini参数量:仅凭API就能推算?


近期,一项发表于 arXiv 预印本平台的研究在 AI 技术圈内引发了广泛关注。研究者李博杰提出了一种名为“不可压缩知识探针”的创新评测框架,其目标极具挑战性:仅通过黑盒 API 调用,逆向估算任意大语言模型的实际参数规模。

这项研究的灵感,源于一项持续三年的非正式测试。团队长期向各代主流大模型提问同一个冷门问题:“你了解中国科学技术大学的 Hackergame 吗?”——这是一项知名的 CTF 网络安全挑战赛。这个看似简单的提问,如同一个时间戳,清晰地揭示了模型对世界知识认知的演进过程。

观察结果颇具启发性:2024年5月,GPT-4o 的回答仍存在明显的“幻觉”与事实错误;至2025年2月,Claude 3.7 Sonnet 已能准确列举2024年赛季的19道赛题;而到2026年4月,多个前沿模型已能精确回忆连续多届赛事的诸多具体细节。
正是这一现象,催生了正式的研究。在 DeepSeek-V4 发布后,研究团队利用 AI 智能体耗时四天,自主构建了一套完整的 IKP 数据集。该数据集包含1400个问题,并依据信息稀缺性划分为7个层级,随后在涵盖27家厂商的188个模型上进行了全面测试与评估。
核心假设与方法论
整个研究的基石是一个核心假设:模型的逻辑推理能力或许可以通过训练技巧进行压缩或“蒸馏”,但对于冷门“事实性知识”的记忆容量,却难以被大幅压缩。这部分能力,主要取决于模型的物理参数规模——参数越多,能够记忆的“冷知识”潜力就越大。
基于这一思路,研究者在89个参数量已知的开源模型上(规模从1.35亿到1.6万亿参数不等),拟合出了事实准确率与参数量之间的对数线性关系。拟合优度 R² 高达0.917,显示出极强的相关性。随后,他们便利用这一关系,对主流闭源大模型的参数量进行了逆向估算。
根据论文给出的估算结果(其90%置信区间约为0.3至3倍),几个备受关注的 AI 模型规模浮出水面:
- GPT-5.5:约 9 万亿参数
- Claude Opus 4.7:约 4 万亿参数
- GPT-5.4:约 2.2 万亿参数
- Claude Sonnet 4.6:约 1.7 万亿参数
- Gemini 2.5 Pro:约 1.2 万亿参数
除了这些估算数据,论文还揭示了两项有趣的发现:
其一,模型记忆研究者的模式并不完全取决于“学术名气”。论文引用数量和 h 指数并不能有效预测一位研究者是否会被模型记住。模型更倾向于记住那些在特定领域产生了实质性、标志性影响的学术工作,而非那些虽然高产但影响力相对分散的学者。
其二,通过对跨越三年的96个开源模型数据进行分析,研究者发现模型事实记忆容量的“时间系数”在统计上几乎为零。这意味着,随着时间推移,模型在同等参数规模下记住事实的能力并没有显著提升。这一发现与此前“Densing Law”所预测的模型效率随时间提升的规律相悖。研究者据此认为,当前的推理能力基准测试可能已趋于饱和,而事实容量仍然主要受制于最“硬”的约束——参数规模。
社区反响:数据引发的连锁猜想与质疑
这组直观的估算数据迅速传播,同时也引爆了巨大的争议与讨论。
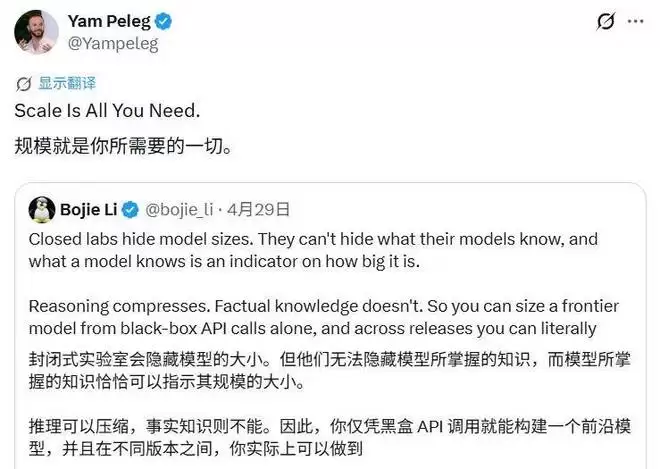
有技术博主将这组估算数据与近期 Claude Opus 4.7 在部分长文本任务中用户主观体验的波动联系起来,推演出一套完整的叙事:Anthropic 由于算力储备仅为 OpenAI 的四分之一,在训练了 Mythos 模型后资源见底,被迫将 Opus 4.7 的参数量从上一代的 5.3T “反向升级”阉割至 4T;而 OpenAI 则凭借充足的算力将 GPT-5.5 堆叠到了 9T,从而实现了用户体验上的反转。
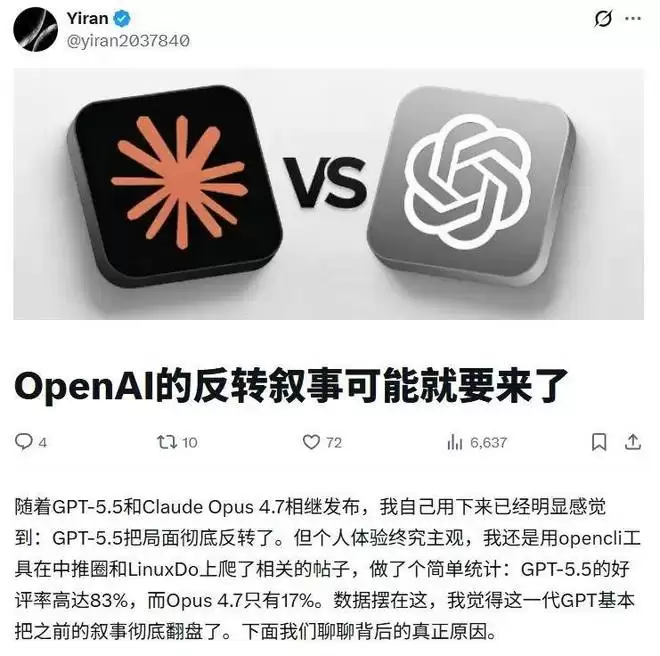
当然,更多的声音则是对估算数字和方法论本身提出了不同程度的质疑。
对于 GPT-5.5 约 9 万亿参数的估算,不少行业从业者感觉与实际服务体验不符。有观点指出,如果规模真达到这一量级,以 OpenAI 现有的基础设施,难以支撑其此前的快速迭代与推出节奏。此外,从 GPT-5.4 到 GPT-5.5 的性能提升幅度,似乎也与近10倍的参数差距并不匹配。有人认为,两者规模之比约在2倍左右可能更为合理。

方法论层面也受到了挑战。一个关键的质疑点在于:通过定向引入“合成数据”进行针对性微调,同样能显著提升模型对特定冷门知识的掌握度。这直接动摇了“事实知识不可压缩”这一核心前提的有效性。

估算结果与行业既有认知的冲突,也加剧了争议。根据该方法,Gemini 2.5 Pro 和 Claude Sonnet 的规模约 1.7T,而行业已知的国内模型如 Kimi k2.6 和 GLM 5.1 约为 800B。如果参数差距仅在两倍左右,单纯的数据差异似乎极难解释目前两者之间存在的巨大性能鸿沟。

更直接的矛盾点在于历史数据。业内长期流传 GPT-4 的规模约 1.7T,这与论文对 GPT-5.4 约 2.2T 的估算结果出入极大,引发了对其校准基准可靠性的疑问。

值得注意的是,发起相关讨论的博主本人也补充说明:“这些数字不应被视为事实,置信区间非常大,我私下收到的反馈表明某些模型的估算可能相差甚远。”

建设性探讨:超越争议的思考
在争议之外,技术社区也涌现出许多极具建设性的正向探讨,试图深化对这一问题的理解。
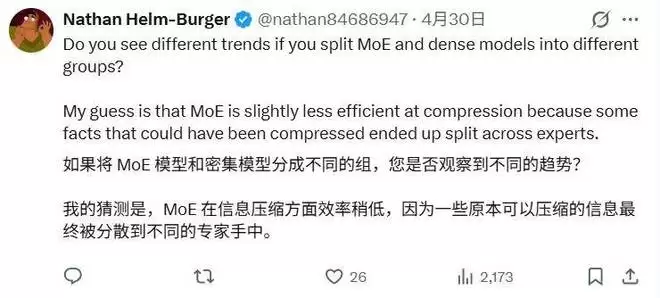
例如,有观点指出,MoE(混合专家)架构和传统的稠密模型在知识压缩与存储效率上可能存在本质不同。在 MoE 模型中,事实知识可能被分散存储在不同的专家网络中,这或许会影响 IKP 方法的测量准确性。因此,建议将这两类模型分开统计,以观察更清晰的趋势。

无论如何,这项研究及其引发的广泛讨论,都指向了一个核心议题:在模型规模成为核心商业机密和竞争壁垒的今天,如何从外部客观、可靠地评估这一关键指标?IKP 框架提供了一种新颖的思路与工具,尽管其准确性、普适性和可靠性仍有待更多实证检验,但它无疑为这场“黑盒猜谜”游戏,投下了一枚引人深思的探针,推动了关于大模型评估方法的深度思考。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

阿里云智能Logo设计服务:AIGC技术赋能企业品牌标识
对于初创公司、中小微企业与独立创业者而言,构建品牌视觉形象的第一步通常从设计一个专业的logo开始。过去,这项工作往往意味着高昂的外包设计成本或漫长的自学曲线。阿里云此前推出的智能logo设计工具,正是针对这一核心需求,致力于通过AI技术大幅降低设计门槛与启动成本。 用户仅需提交品牌名称、选择所属行

FlyAI人工智能竞赛平台:专注AI赛事与开发者服务
在人工智能技术快速迭代的今天,如何找到一个既能检验算法实力、又能与同行切磋成长的实战平台,是许多开发者和研究者关心的问题。FlyAI平台的出现,恰好为这个需求提供了一个专注的解决方案。简单来说,它是一个在线的人工智能竞赛服务平台,参赛者在这里提交算法代码,由系统自动完成评测和排名,整个过程高效透明。

MiniMax大语言模型中文训练优势与应用解析
在人工智能技术加速普及的当下,企业与开发者都在寻求能够稳定、高效构建智能化应用的解决方案。MiniMax开放平台应运而生,它提供了一套安全、可靠且灵活的API服务体系,致力于成为连接先进AI能力与多样化业务场景的核心桥梁。其重点产品“海螺AI”,专为知识密集型工作者设计,如同一位随时在线的专业助手,

和鲸社区数据科学竞赛平台Heywhale官网指南
在数据科学和人工智能浪潮席卷各行各业的今天,无论是企业寻求技术突破,还是个人渴望技能进阶,一个高效、可靠的实践与竞技平台都显得至关重要。Heywhale com,即和鲸数据科学竞赛平台,正是这样一个聚焦于大数据算法比赛的商业服务机构。它由和鲸科技运营,依托其深厚的数据科学社区与工具资源,已发展成为业

卓特视觉平台提供超3亿正版视频图片音乐素材
在创意设计与数字内容创作领域,获取合法、高质量的版权素材是保障项目顺利推进的关键。一个集海量正版资源、便捷获取方式和成本可控优势于一体的平台,对于广大设计师、视频编辑、自媒体从业者及企业市场团队来说,具有极高的实用价值。本文将为您深入解析一个在此领域表现突出的专业服务平台。 该平台目前拥有超过3亿份








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
