




CVPR 2026世界模型论文综述 生成与建模技术演进解析

近年来,视频生成技术的演进速度令人瞩目。从扩散模型到大规模视频基础模型,生成内容的视觉质量已日益接近真实世界。然而,当我们深入审视这些模型时,一个更根本的问题逐渐浮现:它们究竟是在“理解世界”,还是在“拟合像素分布”? 传统方法大多建立在二维图像空间之上,通过逐帧建模来合成动态内容。这种范式虽然在短
近年来,视频生成技术的演进速度令人瞩目。从扩散模型到大规模视频基础模型,生成内容的视觉质量已日益接近真实世界。然而,当我们深入审视这些模型时,一个更根本的问题逐渐浮现:它们究竟是在“理解世界”,还是在“拟合像素分布”?
传统方法大多建立在二维图像空间之上,通过逐帧建模来合成动态内容。这种范式虽然在短时生成和视觉表现上取得了不错的效果,但其局限性也日益凸显:相机运动难以精确控制,多物体交互缺乏一致性,长时间生成容易出现结构漂移,甚至在复杂场景中违背基本物理规律。这些问题的共同根源,或许在于模型缺乏对“世界本身”的建模能力。
正是在这一背景下,“世界模型”逐渐成为视觉生成与人工智能研究的前沿方向。与传统方法不同,世界模型致力于构建一个能够统一描述空间结构、时间演化乃至物理规律的内部表示。其目标不仅是生成逼真的视觉内容,更在于进行推理、预测,甚至支持智能决策。某种意义上,这标志着研究目标正从“生成看起来真实的结果”,迈向“建模一个本质上合理的世界”。
这一范式的演进是多维度的:在表示层面,从2D像素走向3D/4D几何结构;在建模目标上,从单纯的内容生成扩展到因果关系理解、物理一致性与场景交互性;在学习方式上,从依赖大量标注数据转向从真实世界视频中提取可迁移知识;而在评估体系上,也逐渐从单一的视觉质量指标,转向对“世界建模能力”的多维度综合衡量。
CVPR 2026会议中的一系列研究工作,集中体现了这一发展趋势。这些研究在技术路径上各有侧重——有的强调4D几何建模,有的关注物理对齐与因果推理,有的探索如何从真实视频中学习世界知识,还有的致力于构建统一的评测基准。更重要的是,它们共同指向一个核心目标:推动模型从“视觉生成工具”演化为真正的“世界模拟器”。
接下来,我们将从几个关键角度,系统梳理这些代表性工作,尝试回答一个更深层的问题:当我们致力于“生成世界”时,我们究竟在建模什么?
世界在模型里到底长什么样?
要让AI模型理解世界,首先需要解决“如何表示世界”这一根本问题。传统的2D像素表示显然已不足以胜任,研究者们开始将目光投向更高维的几何结构表示。
复旦大学、香港大学与腾讯ARC团队提出的《VerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control》,直指当前视频生成的核心痛点:现有方法多在2D图像空间中建模,导致相机与多物体运动难以统一控制,且生成稳定性不足。他们的解决方案是,将视频表示为“3D空间+时间”的统一世界状态,而非简单的逐帧像素堆叠。其核心是一种“4D几何控制”表示:使用静态背景点云描述场景结构,用带时间信息的3D高斯轨迹描述动态物体,从而构建出统一的4D世界模型。在此基础上,再将几何信息转化为控制信号,输入到视频扩散模型中进行生成。这样一来,生成的视频便能严格遵循设定的相机路径和物体运动轨迹。这项工作的意义在于,它实现了从“基于像素的合成”到“基于结构的生成”的范式转变,在可控性和时序稳定性上取得了显著提升。

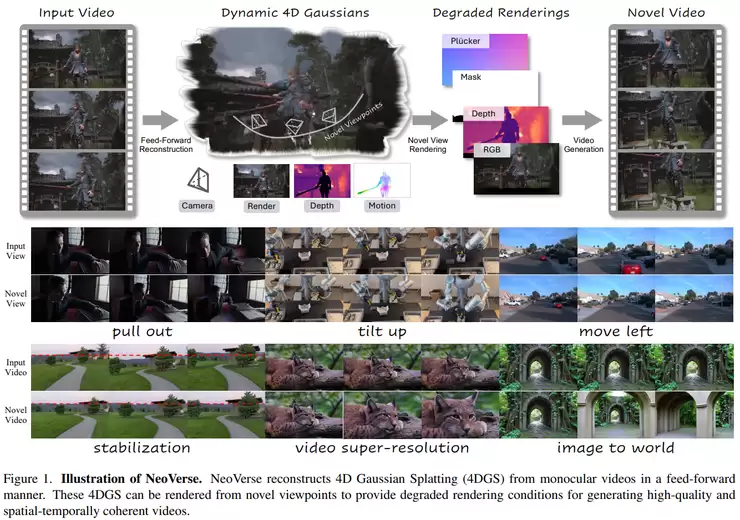
然而,构建4D世界模型通常依赖多视角数据或复杂的预处理流程,这严重限制了其可扩展性。中国科学院自动化所与CreateAI的《NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos》试图打破这一瓶颈。其核心思路是,直接利用“野外采集”的普通单目视频来构建4D世界模型。该框架能够从日常视频中恢复场景的3D结构,并建模动态信息,形成完整的4D场景表示。它不仅支持4D重建,还能生成新视角视频,并应用于多种下游任务。这意味着,4D建模可以从依赖昂贵的数据采集,转向利用大规模、易获得的真实世界视频数据,实用性大大增强。
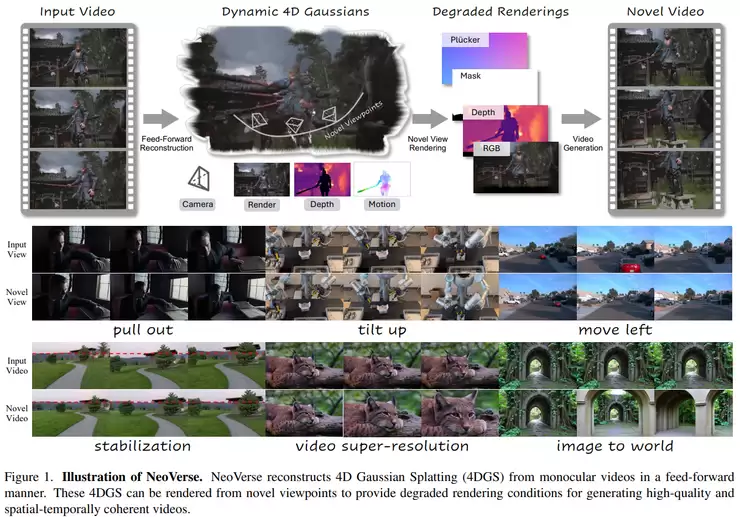
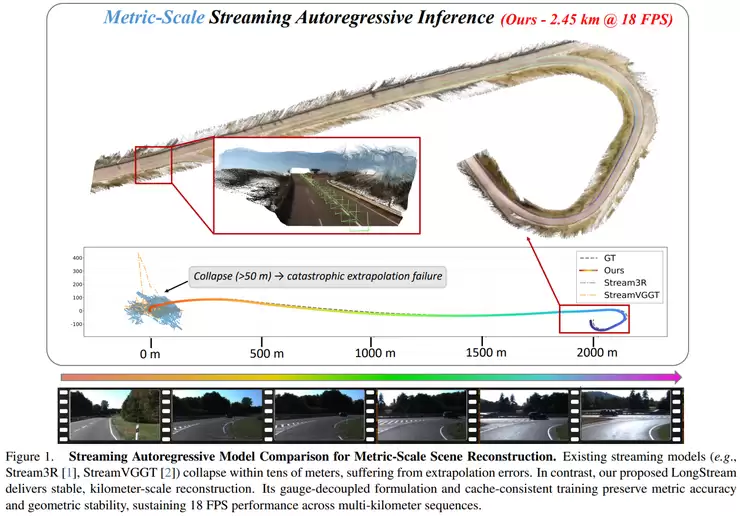
当视角拉长,另一个挑战随之而来:长序列3D重建。现有方法在短序列或离线场景下尚可应对,但面对上千帧的长视频,往往会出现注意力衰减、尺度漂移和误差累积等问题。香港科技大学(广州)、地平线机器人等团队的《LongStream: Long-Sequence Streaming Autoregressive Visual Geometry》提出了一个流式、规范解耦的视觉几何框架。它不再将所有帧锚定到第一帧,而是通过“关键帧相对建模”的方式,让局部序列独立建模,再统一到全局结构中。同时,它将尺度学习与几何预测解耦,并通过周期性刷新缓存等机制,实现了在严格在线(看不到未来帧)条件下,稳定处理上千帧数据的能力。这为自动驾驶、AR/VR等需要持续环境感知与建模的应用场景,提供了新的可能性。
模型有没有学到可以迁移的世界规律?
拥有了世界的表示,下一步是让模型理解世界中运行的客观规律。这要求模型不仅能“看见”表象,还要能“思考”本质,能从观察中提炼出可迁移的通用知识。
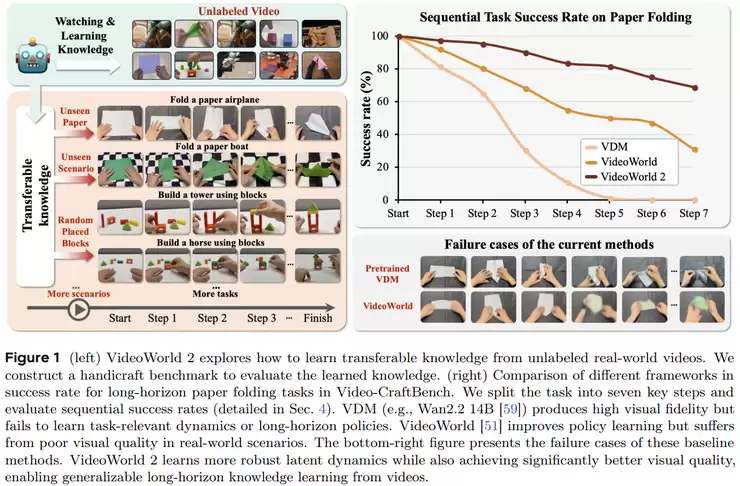
北京交通大学与字节跳动团队的《VideoWorld 2: Learning Transferable Knowledge from Real-world Videos》便将重点放在了“知识学习”上。该研究指出,现有视频生成模型虽然画面逼真,却普遍缺乏对物体运动规律、交互关系的深层理解,难以在新场景中有效泛化。VideoWorld 2框架的核心,是从大规模无标注的真实视频中,自主学习物理规律和时序结构,并将这些知识编码为可复用的表示。这使得模型从“会生成”向“会理解”迈进了一步,更贴近人类从观察中学习世界运作原理的方式。
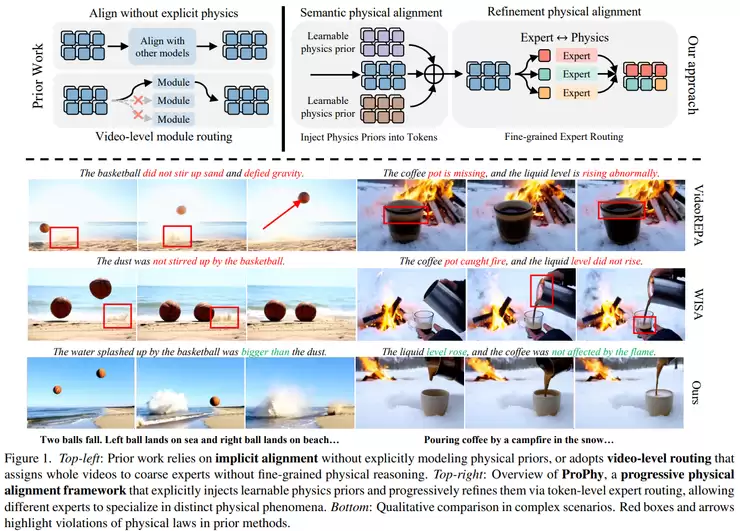
理解规律,尤其是物理规律,是构建可信世界模型的关键。中山大学、鹏城实验室等团队的《ProPhy: Progressive Physical Alignment for Dynamic World Simulation》显式地引入了物理约束。其“渐进式物理对齐机制”分为两步:首先在语义层面提取文本描述中的物理规律(如运动类型),再将这些规律精确对齐到视频中的具体区域和时间过程。模型还采用了“物理专家混合机制”,让不同模块分别学习不同类型的物理规律。通过引入视觉语言模型的推理能力,该框架使生成的动态场景不仅视觉逼真,更符合真实的物理规律。
将物理一致性推向极致的,是四川大学、香港理工大学等团队的《Chain of Event-Centric Causal Thought for Physically Plausible Video Generation》。该工作认为,许多物理过程本质是一系列按因果顺序发展的事件链。因此,它提出了一个以“事件为中心”的生成框架:先将复杂物理过程拆解为多个有因果关系的子事件,并引入物理公式作为约束;再将这些事件转化为时间对齐的文本和视觉提示,以引导视频生成在不同事件间平滑过渡。这种方法让视频生成从“生成一个静态结果”变为“生成一个符合物理规律的动态过程”,在因果一致性上表现更优。
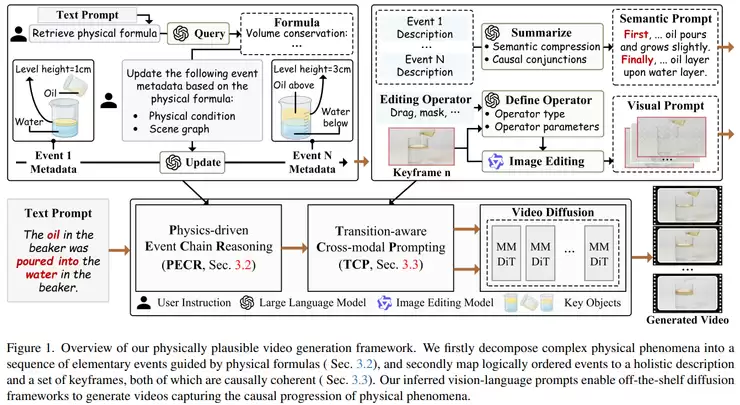
能不能精确控制生成的世界?
理解了世界,还要能操控世界。对生成过程的精确控制,是将世界模型应用于实际场景的前提。
西湖大学与南洋理工大学的《Taming Video Models for 3D and 4D Generation via Zero-Shot Camera Control》关注的是控制本身。现有视频扩散模型虽有强大的“世界先验”,却难以精确控制相机运动,且时空一致性较差。该研究提出的WorldForge框架,其巧妙之处在于完全无需重新训练模型,仅在推理阶段进行增强。它通过在扩散去噪过程中加入递归优化来贴合目标相机轨迹;利用光流区分“运动”与“外观”,只控制运动部分;并通过双路径对比机制自动修正偏差。这种“即插即用”的方式,以极低成本实现了对相机轨迹的精确控制,并保持了高视觉质量。
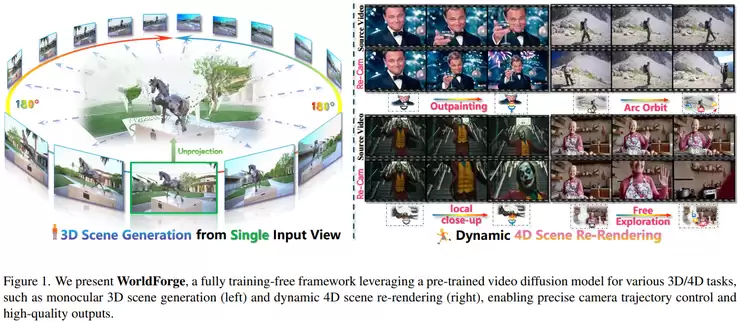
模型不仅表示世界,还要「用世界做事」
终极目标,是让世界模型不仅能模拟世界,还能基于模拟进行决策和交互,真正成为智能体的“数字孪生”环境。
华中科技大学与小米EV团队的《DriveLaW: Unifying Planning and Video Generation in a Latent Driving World》便致力于此。传统自动驾驶系统将“预测未来场景”和“路径规划”分开处理,容易导致误差累积。DriveLaW框架则将二者统一在一个“潜在驾驶世界”中。模型在潜在空间学习场景动态演化规律,并直接在此空间中进行决策推理,无需先生成完整视频。这打破了预测与决策的壁垒,使世界模型真正参与到决策闭环中,提升了在复杂场景中的效率和鲁棒性。
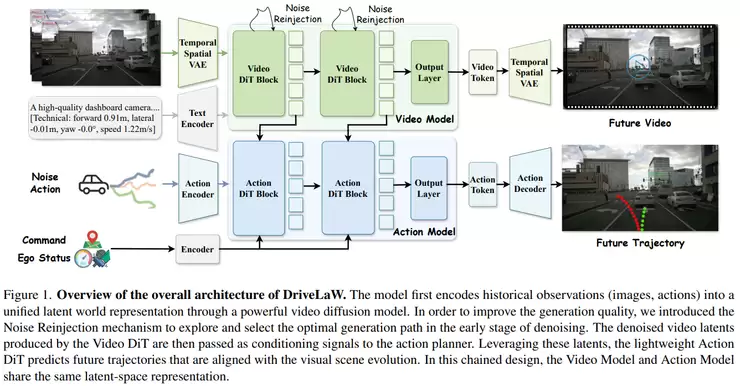
在机器人操作领域,物理一致性至关重要。AMAP CV Lab的《ABot-PhysWorld: Interactive World Foundation Model for Robotic Manipulation with Physics Alignment》构建了一个具备物理对齐能力的交互式世界模型。该模型基于扩散Transformer架构,在生成视频的同时引入物理约束,确保机器人操作过程既真实又合理。它还支持根据输入指令控制交互过程,并通过物理感知训练机制,让模型更关注“物理合理性”而非单纯视觉质量。这使世界模型从生成工具,发展为能用于机器人决策模拟的基础模型。
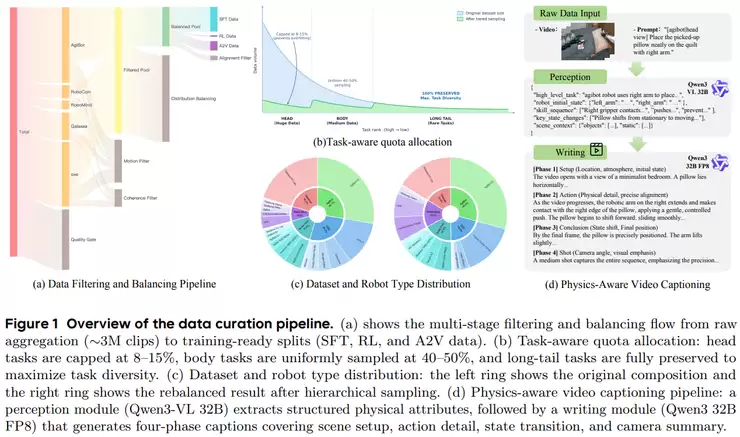
然而,无论是自动驾驶还是机器人,都面临一个共同难题:真实世界中的关键危险场景或长尾情况数据稀缺。中科院自动化所、香港大学OpenDriveLab与小米EV团队的《SimScale: Learning to Drive via Real-World Simulation at Scale》提供了一种思路。该框架利用真实数据构建仿真环境,并在此基础上自动生成大量新的驾驶场景,尤其是那些罕见的长尾场景。通过联合训练真实数据与仿真数据,有效缩小了仿真与现实间的差距,让模型在安全性和泛化能力上得到增强。这是一种以数据驱动的方式,规模化解决关键场景覆盖问题的有效路径。
如何知道一个模型真的在「建模世界」?
随着世界模型能力日益复杂,如何系统、全面地评估其“世界建模能力”,成为一个基础且关键的问题。
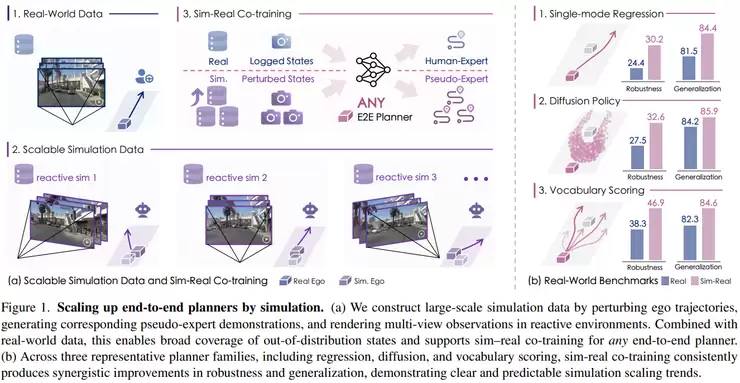
中国科学技术大学、浙江大学等机构的《4DWorldBench: A Comprehensive Evaluation Framework for 3D/4D World Generation Models》旨在建立统一标准。该框架从视觉感知质量、条件与4D对齐能力、物理真实感、时空一致性等多个维度综合评价模型。它支持多种输入模态(文本、图像、视频),并通过统一机制将不同模型映射到同一评测空间进行比较,甚至引入大语言模型参与判断,使评估更接近人类主观认知。这推动研究重点从单纯的生成效果,转向对世界建模能力的全面衡量。
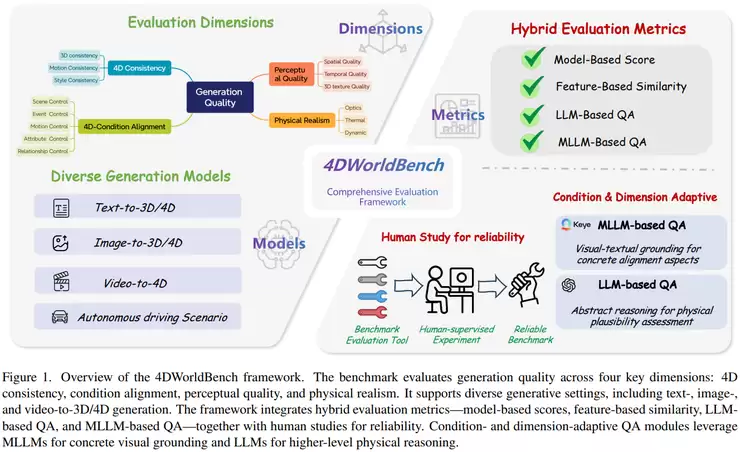
WorldBench Team的《WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World》则更专注于自动驾驶领域。该框架从生成、重建、动作跟随及下游任务表现等多个角度,系统评估世界模型的综合能力,并结合人类偏好进行评价。它构建了大规模数据集并引入自动评估模型,实现了规模化、可解释的评测。这项研究也揭示了当前模型在不同能力间存在的权衡,为未来研究指明了方向。
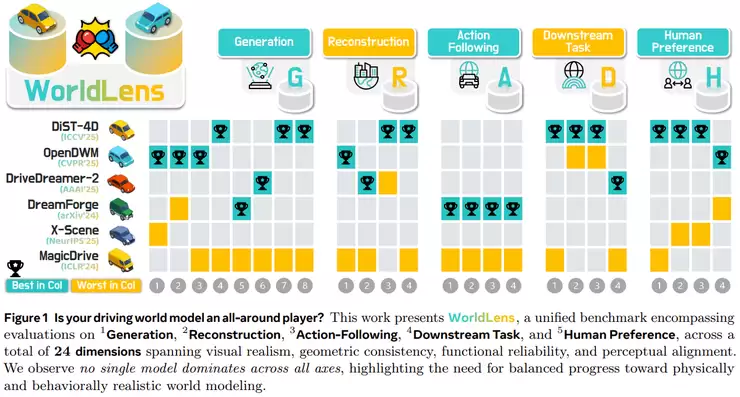
除了评估,模型自身的表示结构也决定了其理解和规划能力。ANU和MBZUAI团队的《GeoWorld:Geometric World Models》提出了一个新颖的观点:将世界模型从欧几里得空间,扩展到具有层级结构的几何空间(如双曲空间)中。在这种几何能量模型中,状态间的复杂关系得以更自然地表达。进行预测或规划时,模型沿“测地线”推理,而非逐步生成状态,这有效缓解了长时预测中的误差累积问题,为基于世界模型的决策规划提供了新思路。
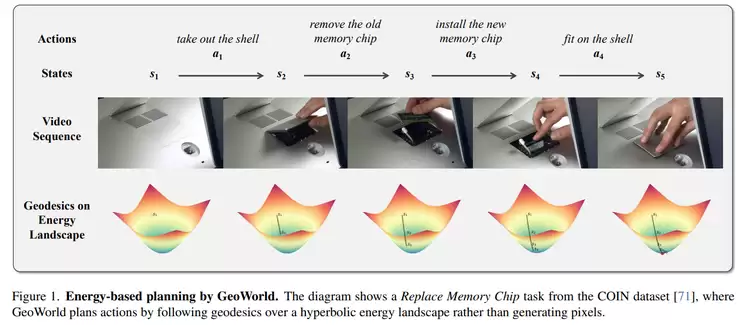
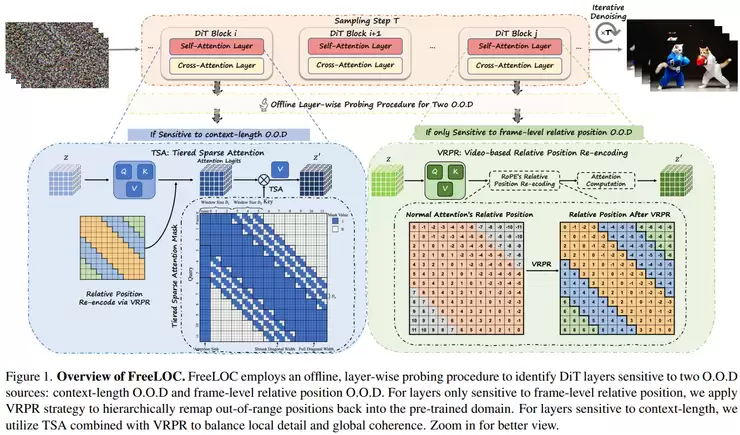
最后,一个实用性问题是如何让现有模型更好地工作。西湖大学的《Free-Lunch Long Video Generation via Layer-Adaptive O.O.D Correction》发现,用短视频训练的扩散模型直接生成长视频时,会出现质量下降,其根源在于帧间相对位置和上下文长度超出了训练分布(O.O.D.)。他们提出的FreeLOC框架,无需重新训练模型,仅在推理阶段通过“视频相对位置重编码”和“分层稀疏注意力”等机制进行修正,并自适应地针对敏感层进行调整,从而显著提升了长视频生成的稳定性和质量。这是一种低成本提升模型实用性的有效方法。
回过头看,从精确的4D几何控制,到对物理规律和因果关系的理解,再到用于决策规划与系统评估,世界模型的研究正在一条从“表示”到“理解”再到“应用”的路径上快速演进。中国科学院自动化所等团队的《Neoverse: Unposed 4D World Modeling from Monocular Video》可视为一个注脚,它通过前馈式重建与生成联合训练,让模型能直接利用海量单目视频,正是这条路径走向大规模实用化的重要一步。
这些工作共同描绘出一个清晰的趋势:视频生成技术正从追求视觉逼真的“像素合成”,迈向构建内在合理的“世界模拟”。未来的AI模型,或许将不再只是一个内容生成工具,而是一个能够理解物理规则、进行因果推理、并支持复杂决策的数字世界基底。这不仅是技术的演进,更是我们对机器如何认知世界这一根本问题的一次深入探索。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:CVPR 2026世界模型论文综述 生成与建模技术演进解析要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点2027款东风风行星海V9上市,推出3款配置,官方指导价17 99-22 99万元。中大型MPV轴距3018mm,内饰配备双15 6英寸屏及10 25英寸仪表,全车座椅电动调节带加热通风。搭载高通8295P芯片及双AI大模型,标配L2级辅助驾驶。马赫双擎混动系统纯电续航200公里,综合续航1300公里,馈电油耗5 27L,支持快充与外放电。
近期,多家低成本航空公司对旅客携带登机箱登机收费的现象引发关注。业内人士解释,这与航空公司运营模式相关:全服务航空票价包含行李、餐食等服务,而低成本航空则提供更低基础票价,额外服务需另行购买。这种差异化服务模式在欧美市场也已普遍存在。专家强调,航司需做好信息告知,旅客购票时也应仔细阅读行李规定。目前
近期调查发现,部分酒店使用的一次性牙刷存在原料安全隐患。生产企业涉嫌违规使用复杂的回收塑料,包括化工废桶等,经过简易加工制成刷柄。业内人士承认此类“回料”牙刷质量差、易断裂。医学专家警告,回收塑料成分复杂,高温加工可能产生新的有害物质,通过口腔黏膜极易渗入人体,长期使用存在健康风险。这一事件凸显
横琴口岸联合一站式车道“刷脸”智能通关服务启用首月运行情况公布。据统计,截至6月7日,经该车道累计通行车辆达38 8万辆次,其中超过22 9万辆次车辆选择了智能通关服务,占总通行量的59 1%。这意味着超半数跨境车主已习惯使用“刷脸”通行。与4月试运行期间相比,智能通关服务使用量环比增长31 5%,
- 日榜
- 周榜
- 月榜
热点快看