




ICLR时间检验奖十年回顾:0博士组合论文获封神之作

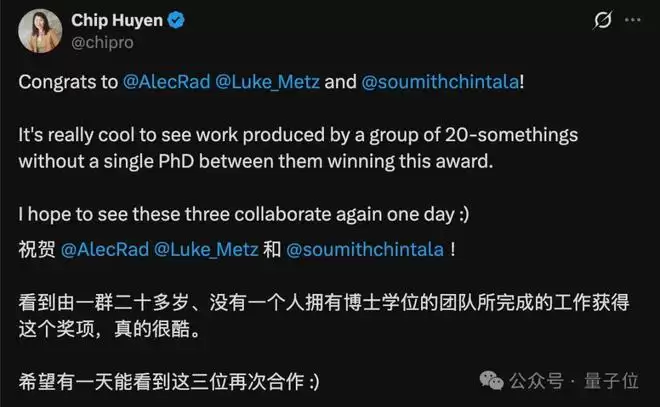
ICLR 2026的时间检验奖刚刚揭晓,结果颇有些耐人寻味——获奖者之一是Alec Radford,这位如今被OpenAI CEO奥特曼誉为“爱因斯坦级别”的天才,正是初代GPT系列的奠基人之一。
消息一出,社区反响热烈,“实至名归”的祝贺声不绝于耳。这位技术大神在社交媒体上异常低调,动态几乎全是转发和推荐他人的工作。然而,在OpenAI内部,他的地位与Ilya Sutskever齐名。公司总裁Greg Brockman甚至曾公开表示:“只要他想要的,我们都给。”足见其分量。

此次将他推上领奖台的,是一篇发表于十年前的经典论文:DCGAN。这篇引用量超过2万次的著作,不仅是机器学习领域最具影响力的论文之一,更被公认为开启了生成对抗网络(GAN)工程化应用的大门。
有趣的是,这篇里程碑式论文的作者阵容,在当时看来颇为“非主流”:三位作者,没有一位是博士生。两位本科生,一位硕士生,联手改写了历史。这本身,就足够酷了。
时间检验奖首次颁给本科生
本届ICLR的时间检验奖罕见地开出了“双黄蛋”,除了DCGAN,另一篇获奖论文是DeepMind的DDPG。前者为GPT系列模型的核心逻辑埋下了伏笔,后者则证明了深度强化学习能够解决连续控制问题。ICLR连续三年以此奖项致敬经典,也侧面印证了这两项工作的价值难分伯仲。
评审委员会对DCGAN的评价切中要害:这篇俗称DCGAN的论文,首次成功验证了基于学习的生成模型能够产出多样化、逼真且结构复杂的图像。它正式开创了图像生成这一子领域,如今已成为机器学习最炙手可热的方向之一,并在工业界催生了大量成熟应用。尽管技术脉络已从GAN演进至扩散模型,但DCGAN作为奠定整个领域的关键里程碑,其价值历久弥新。

论文的三位作者,人生轨迹也如同他们的研究一样,充满了戏剧性的交汇与重逢。
核心人物Alec Radford本科毕业于富兰克林·欧林工程学院。这所学院规模虽小,仅约400名学生,但以其高自由度的项目制教学和媲美常春藤的学术实力著称。在校期间,Alec便与同学共同创立了公司Indico,此后加入OpenAI,一待就是八年。他是早期GPT系列论文的核心贡献者,几乎参与了OpenAI所有重大突破,也是多模态模型CLIP的主导者。他提出的“Transformer架构+生成式预训练”方法,直接奠定了后来ChatGPT及众多大模型的基础。截至目前,其论文总被引数已超过35万次。
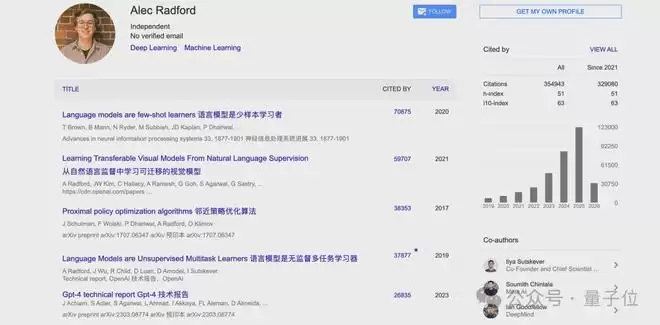
2024年底,Alec选择离开OpenAI追求独立研究,并于去年3月以顾问身份加入了由OpenAI前CTO Mira Murati创立的Thinking Machines Lab。
另一位本科生作者Luke Metz,与Alec师出同门,毕业后加入了Alec的Indico公司,同样是OpenAI的创始成员之一。他后来进入谷歌担任长期研究员,研究方向从生成模型转向优化算法与元学习,并在2024年短暂回归OpenAI,最终于同年年底加入Thinking Machines Lab。
第三位作者Soumith Chintala的故事则更为曲折。他更为人熟知的身份是PyTorch的核心作者和Meta前副总裁。本科就读于印度韦洛尔理工学院(VIT)的他,在申请硕士时曾连续被12所高校拒绝,最终才获得纽约大学的录取,并幸运地师从Yann LeCun,投身早期深度学习研究。硕士毕业后,他的求职之路再次受阻,几乎被所有申请的公司拒绝,最终进入一家名为MusiAmi的小型创业公司。转机发生在2014年,经LeCun引荐,他加入Meta,并带领团队主导开发了PyTorch——如今全球应用最广泛的开源机器学习框架之一。在Meta工作11年,他从L4工程师一路晋升至副总裁。2025年底,他离开Meta,出任Thinking Machines Lab的CTO。
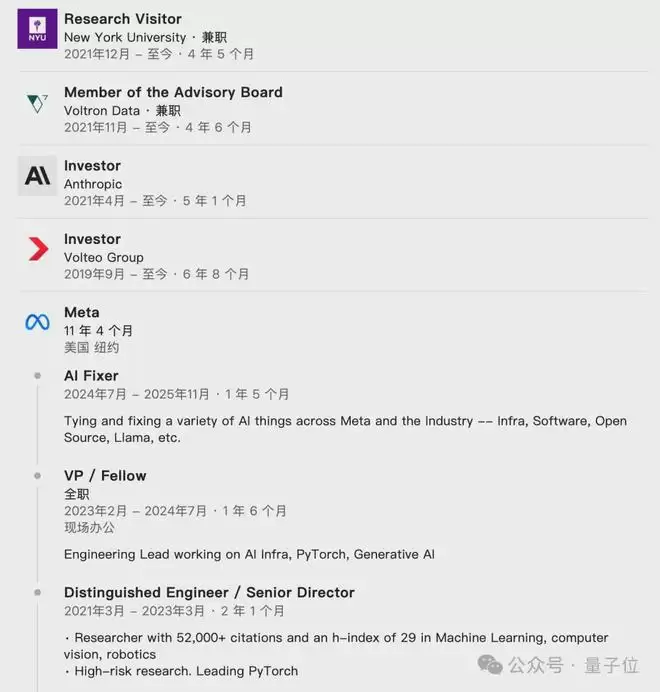
于是,一个奇妙的闭环形成了:DCGAN的三位作者,在各自历经辉煌与转折之后,于Thinking Machines Lab再度聚首。
其余获奖情况
除了时间检验奖,ICLR 2026还公布了两篇优秀论文奖和一篇优秀论文提名。
两篇优秀论文奖分别是:《Transformers are Inherently Succinct》率先提出“简洁性”是衡量Transformer表达能力的新维度,并证明其在描述某些复杂概念时,相比RNN等模型具有指数级甚至双指数级优势;《LLMs Get Lost In Multi-Turn Conversation》设计了一种可扩展的方法来评估大语言模型的多轮对话能力,同时发现当交互轮次增多且指令模糊时,模型的适应性与可靠性会显著下降。

获得优秀论文提名的研究,则运用逼近理论,为流行的Muon优化器设计了一套基于极分解的最优多项式逼近方案,获得了业界的广泛认可。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

吉利发布首款原生Robotaxi Eva Cab 千里科技AI全栈赋能
4月24日,在备受瞩目的第十九届北京国际汽车展览会上,吉利汽车集团正式揭晓了其重磅新品——中国首款原生正向开发的Robotaxi(自动驾驶出租车)原型车Eva Cab。这款车型不仅是前沿概念的展示,更是一款具备完整落地潜力的产品,其核心驱动力源自千里科技提供的全栈式Robotaxi解决方案。该方案深

Akamai与NVIDIA合作推动分布式AI推理从内容分发迈向智能分发
自2010年在中国设立团队以来,Akamai已深耕本地市场十六年。在服务中国企业出海的漫长征程中,其团队展现出卓越的稳定性与战略专注度。 回顾NVIDIA GTC 2026,其CEO黄仁勋曾预言,AI推理的规模将迅速达到训练负载的数十亿倍。进入2026年,行业共识已然明确:AI大模型竞争的焦点,正从

跑车品牌宣布暂停全面电动化转型计划
莲花集团发布“Focus2030”战略,宣布调整全面电动化路线,将同步发展燃油、混动及纯电车型,直至市场成熟。未来将推出燃油跑车Emira420,并于2028年上市搭载V8混动系统的超跑Type135,战略重心转向追求更高利润率。

大语言模型如何实现类人对话与思考的智能原理
我们每天都在与大语言模型(LLM)对话,一个直观的感受是,它们似乎真的“懂”我们在说什么,尽管偶尔也会“胡言乱语”。观察它们输出的思维链,那种逐步推理的语言痕迹,更让人觉得它们仿佛具备了某种思考能力。 这引出了一个核心问题:LLM的语言和思考能力,究竟是一种怎样的能力?这些能力又是如何通过其底层的实

ICML 2026论文解读:TGO标量反馈对齐视觉生成模型
生成模型的偏好对齐,可能正在进入一个新的阶段。 过去几年,大模型在训练后优化(post-training)最主流的方法,是让模型从“成对偏好”中学习。无论是经典的RLHF,还是后来更简洁的DPO,都绕不开同一个前提:反馈必须成对出现。 但在真实世界里,反馈往往不是这样。用户给一个结果打分、系统记录一








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
