




视觉GPT时代开启:DeepMind用Vision Banana验证生成即理解

就在前两天,OpenAI 的 ChatGPT Images 2.0 以其惊艳表现刷屏,整体实力被认为已超越了此前的 SOTA 模型 Nano Banana Pro。当人们的注意力还聚焦在 AI 图像生成的卓越能力上时,谷歌 DeepMind 悄然发布了一篇重量级论文,系统性地论证了一个许多研究者早有预感的事实:图像生成器,本身就是强大的通用视觉学习器。

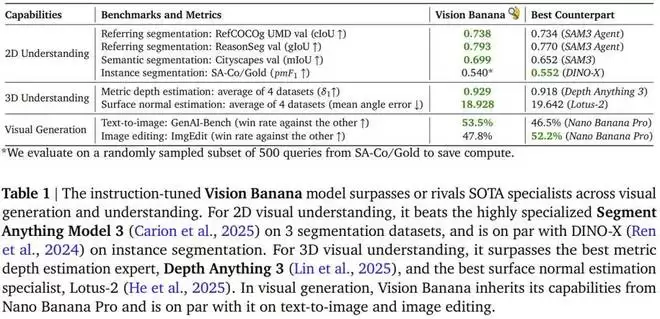
这篇题为《Image Generators are Generalist Vision Learners》的论文指出,正如大语言模型(LLM)通过生成式预训练涌现出理解和推理能力,图像生成训练同样能让模型学到强大且通用的视觉表征,进而在各类视觉任务中达到顶尖水平。基于此,研究团队以 Nano Banana Pro 为基础,构建了一个名为 Vision Banana 的通用模型。其表现相当亮眼,在多项任务上媲美甚至超越了 Segment Anything Model 3、Depth Anything 系列等零样本领域专家模型。
这项研究的深远意义在于,它表明图像生成可以成为视觉任务的统一通用接口。DeepMind 在论文中直言:「我们可能正见证计算机视觉领域的重大范式转变,其中生成式视觉预训练在构建同时支持生成和理解的基础视觉模型中扮演核心角色。」
论文作者阵容强大,其中不乏谢赛宁、何恺明等知名研究者的名字。谢赛宁在社交媒体上连续发文,强调了通用模型的崛起与超越:像 Vision Banana 这样的单一多模态通用模型,首次在图像分割、边缘检测等底层感知任务上击败了 SAM3 和 DepthAnything3 等顶尖专用模型。以往被视为不同问题的感知任务,如今通过简单的提示词就能在一个统一系统中完成。
研究背景:生成即理解的猜想由来已久
在 AI 研究领域,一直存在一个朴素而深刻的直觉:一个能创造出逼真视觉内容的模型,理应也能深刻理解视觉内容。道理很简单,如果模型不理解物体的形状、语义和空间关系,它又如何能生成高保真且语义精确的图像呢?
然而,现实与直觉之间存在着明显的落差。长期以来,视觉表征学习的主流方法并非生成式建模,而是由有监督的判别式学习、对比学习、自举法(Bootstrapping)和自编码器等主导。尽管早期的生成式视觉预训练探索展现出潜力,但其效果始终落后于非生成式模型。
相比之下,自然语言处理领域的局面早已被改写。GPT 系列模型证明,通过生成式预训练(即预测下一个词元),大语言模型能够涌现出强大的语言理解与推理能力,再经过指令微调,便能在各类任务上达到顶尖水平。这不禁让人思考:图像生成能否扮演与文本生成类似的角色?图像生成器,是否就是那个我们寻找的通用视觉学习器?
核心方法:把所有视觉理解任务「伪装」成画图任务
Vision Banana 的基座正是 Nano Banana Pro 图像生成模型。研究团队没有为其添加任何用于视觉理解(如检测、分割)的专用网络结构,也没有修改底层架构。他们的方法堪称巧妙——将视觉感知任务的输出空间,全部参数化为 RGB 图像格式。
具体来说,他们在原始图像生成训练数据中,混入了一小部分视觉任务数据,进行轻量级的指令微调。为了教会模型理解指令并直接「画」出任务结果,Vision Banana 采用了图像化输出解码。例如,在语义分割任务中,提示词会规定「把滑板画成纯黄色 <255, 255, 0>」,模型便会生成一张带有颜色掩码的 RGB 图片,随后只需提取对应颜色的像素,就能完美还原分割结果。

在进行 3D 深度估计时,设计则更为精妙。研究团队设计了一套严格可逆的数学映射机制(利用幂律变换),将物理世界中从 0 到无穷大的度量深度,映射到 RGB 色彩立方体的边缘上。模型输出一张渐变的「伪色彩图」,解码后就能直接换算成精准的物理深度距离。

通过这种「用画图来做题」的统一方法,单一的 Vision Banana 模型在 2D 和 3D 视觉理解任务上,击败或追平了当前一系列顶尖的专业模型。
深度估计的精妙色彩映射
在所有可视化方案中,深度估计的 RGB 编码设计最为精巧。深度值的范围是 [0, ∞),而 RGB 值的范围是有界的 [0, 1]^3,如何在二者之间建立一一对应的双射关系,是工程设计的核心。
研究者采用幂变换对深度值进行「弯曲」处理,将其映射到 [0, 1) 区间,再沿 RGB 立方体的棱边进行线性插值——这条路径类似于三维希尔伯特曲线的第一次迭代。由于幂变换和线性插值均可严格求逆,整个映射构成了从度量深度到 RGB 空间的完美双射,模型生成的彩色图像可以无损地解码回精确的深度值。此外,设计还特意对近场物体赋予了更高的颜色分辨率,因为对机器人操作等应用而言,近距离物体的精确度量往往更为关键。
表面法向量估计
相比深度,表面法向量的可视化则要自然得多。法向量由 (x, y, z) 三个分量构成,值域为 [-1.0, 1.0],与 RGB 颜色通道天然对齐。研究者采用右手坐标系,将三个方向分量直接映射为 R、G、B 通道。这种内在的对齐使得法向量估计几乎无需额外设计,直接沿用生成模型的原生能力即可。
实验结果:全面超越零样本专家模型
2D 理解:分割任务
在语义分割方面,Vision Banana 在 Cityscapes 数据集(19 类城市场景)上以 mIoU 0.699 超越了 SAM 3 的 0.652,领跑所有零样本迁移方法,进一步缩小了与闭集专有模型(如 SegMan-L)的差距。
实例分割方面,Vision Banana 采用「逐类推理」策略应对实例数量未知的挑战:每次推理仅针对一个类别,让模型自动为不同实例动态分配颜色,推理后通过颜色聚类解码出各个实例掩模。在 SA-Co/Gold 数据集上,其 pmF1 为 0.540,与 DINO-X(0.552)基本持平,远超 Gemini 2.5(0.461)等方法。
指称表达式分割是最能体现语言-视觉深度融合的任务。Vision Banana 在此表现尤为出色:在 RefCOCOg 数据集上取得 cIoU 0.738,在 ReasonSeg 验证集上取得 gIoU 0.793,均超越 SAM 3 Agent。更令人惊喜的是,当与 Gemini 2.5 Pro 结合使用时,在 ReasonSeg 上甚至能超越部分在训练集上完整训练的非零样本方法。这得益于其继承自生成式预训练的多模态智能,使其能更有效地推理「分割什么」,这正是判别式模型难以企及的优势。

3D 理解:深度与法向量估计
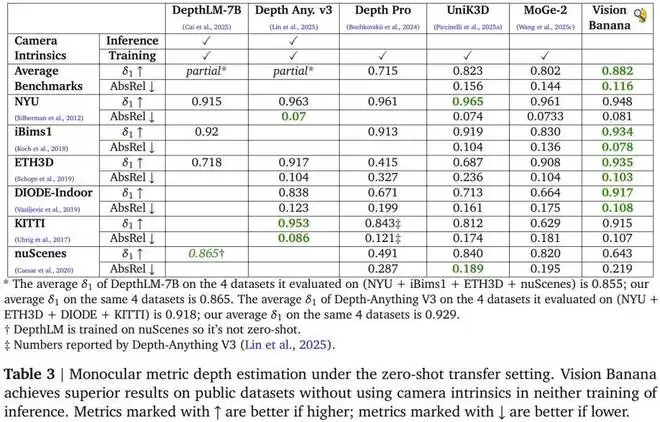
单目度量深度估计是公认的难题。现有顶尖方法通常需要引入相机内参来消解歧义,并配以专门设计的架构。Vision Banana 的策略截然不同:完全不使用相机参数,纯粹依靠基础模型在大规模图像生成预训练中习得的几何先验来推断绝对尺度。值得注意的是,所有训练数据均来自合成渲染引擎,未使用任何真实世界深度数据。
在六大公开基准上,Vision Banana 的平均 δ_1 精度达到 0.882,在与 Depth Anything V3 直接可比的四个数据集上平均 δ_1 为 0.929,超过了后者的 0.918。
研究者还做了一个颇具说服力的实地测试:论文作者用智能手机拍摄了一张照片,Vision Banana 估计出照片中标注点的深度为 13.71 米,实际用谷歌地图测量的距离为 12.87 米,绝对相对误差仅约 0.065。

表面法向量估计方面,Vision Banana 在室内场景平均值上取得最低的误差,在户外场景上与 Lotus-2 相当。定性对比显示,其生成的法向量图在视觉保真度和细节粒度上均更优。
生成能力验证
一个关键问题是:轻量级指令微调是否会损伤原模型的图像生成能力?研究团队在 GenAI-Bench(文生图)和 ImgEdit(图编辑)基准上进行了人类偏好评估,Vision Banana 对基础模型 Nano Banana Pro 的胜率分别为 53.5% 和 47.8%。这一结果清晰地表明,经过指令微调的 Vision Banana 与基础模型的生成能力基本持平,真正做到了「通晓理解,不忘生成」。
范式转变正在发生
这项研究的意义远不止于一组亮眼的基准数字,它更系统性地验证了两个深刻论断。
首先,图像生成器是通用视觉学习器。类比 LLM 领域的生成式预训练,图像生成训练使模型习得的视觉先验,不仅服务于生成任务,更内化为了通用的视觉理解能力。这些生成先验甚至能超越为特定任务精心设计的专有架构和训练范式。
其次,图像生成是视觉任务的通用接口。正如文本生成统一了语言领域的各类任务,将视觉任务输出参数化为 RGB 图像,使得图像生成也能成为视觉任务的统一界面。单一提示词驱动、单一模型权重共享——这种优雅的统一性与 LLM 的成功如出一辙。
此外,生成式建模天然能处理视觉任务中的固有歧义。判别式专家模型通常需要特殊设计来应对一对多的输出分布,而生成模型学习的是完整的数据分布,歧义问题在设计层面就被优雅地化解了。
当然,研究者也坦承了当前工作的局限与未来方向。评估目前专注于单目图像输入,向多视图和视频输入的扩展是自然的下一步。另一个值得期待的方向是探索基础视觉模型与 LLM 的协同融合,以增强跨模态推理。此外,与轻量级专家模型相比,基于图像生成器的推理开销仍然偏高,加速与成本优化将是走向广泛部署的必由之路。
结语
Vision Banana 的出现,让「能生成即能理解」这一长期猜想,从直觉变成了有据可查的事实。
图像生成,可能正在成为计算机视觉的「GPT 时刻」。就像生成式预训练重塑了自然语言处理的格局一样,以 Nano Banana Pro 为代表的大规模图像生成模型,或许正是构建真正意义上的「基础视觉模型」所缺失的关键拼图。
正如 DeepMind 在论文结尾所写:「这些生成先验超越了视觉专家模型长期依赖的专有架构与训练范式。我们正在目睹计算机视觉的范式转变,生成式视觉预训练将在构建同时支持生成与理解的基础视觉模型中扮演核心角色,并为基于视觉的 AGI 铺平道路。」
这一判断,值得整个计算机视觉社区认真思考。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

阿里千问AI语音助手上线 聊天即可查询预订机票与值机选座
【快讯】阿里千问正式对外开放AI办事能力,首家接入中国东方航空,推出全流程AI直连机票服务。这意味着,用户现在可以通过自然语言,直接完成从航班查询、购票、选座到值机等一系列操作,而退改签服务则由东航官方提供支持。这标志着千问AI的能力边界,正从信息问答向实际事务执行迈出了关键一步。 阿里千问事业部总

小米MIMO V25大模型公测开启性能对标全球顶尖模型
今天,小米正式宣布,其Xiaomi MiMo-V2 5系列大模型面向公众开启测试。这次亮相的阵容包括MiMo-V2 5、V2 5-Pro、V2 5-TTS Series以及V2 5-ASR,在推理能力、智能体稳定性、上下文长度、指令理解与全模态感知等多个关键维度上,都实现了全面升级。值得关注的是,其

火山方舟OpenClaw安装步骤与详细教程
OpenClaw 安装与火山方舟接入配置全攻略  成功配置一款高效的开发工具,就如同完成一次精密的

OpenClaw 一键安装脚本 快速部署龙虾服务器
想要快速部署一个功能全面、对中文支持出色的开源AI助手吗?今天介绍的OpenClaw,或许正是你寻找的解决方案。它基于先进的Llama 3 2架构进行深度优化,不仅具备出色的长上下文处理能力,还集成了代码解释器、实时联网搜索、多格式文件解析等强大功能。尤为重要的是,其部署流程经过极致简化,对中文用户

OpenClaw重置教程:人人养虾恢复出厂设置指南
当OpenClaw系统运行出现卡顿、状态异常,或是您希望彻底清理环境重新开始时,openclaw reset命令是您不可或缺的故障排除与初始化工具。它相当于为OpenClaw执行一次“深度重启”,能够有效清理临时数据、会话缓存及异常状态,帮助系统恢复到稳定、干净的起点。 命令概要 该命令的标准使用格








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
