




Redis SCAN源码解析:AI时代高效数据检索的底层逻辑

在技术领域,关于工具依赖的讨论从未停止。当AI技术进入编程与源码分析领域时,一种常见的担忧是:过度使用会削弱开发者深入理解系统的能力。传统的建议强调逐行阅读代码、避免在生产环境依赖AI、以及亲手编写代码的重要性。
面对这些观点,一个更务实的回应是:实践出真知。本文将以Redis中一个经典而精妙的设计——SCAN命令为例,展示如何将传统的调试方法与AI的深度分析能力相结合,进行一次透彻的Redis源码解析。这不仅是一次具体命令的学习,更是一次高效源码阅读方法论的实战演示。

本文源于对Redis SCAN命令的早期研究。当时受限于认知深度,未能完全揭示其底层算法设计的巧妙之处。如今,借助系统化的源码分析流程,我们得以重新审视这一设计,并将其作为“如何高效阅读复杂开源项目源码”的经典案例。
一、准备工作与环境搭建
1. Redis编译与调试环境配置
面对Redis这样成熟的大型C语言开源项目,仅靠静态阅读代码往往难以理清其复杂的数据流和状态变迁。第一步,永远是搭建一个可运行、可单步调试的环境。这一步可能因环境差异而充满挑战,但至关重要。
需要明确的是,我们遇到的大多数环境配置问题,开源社区早有成熟的解决方案。关键在于保持耐心,严格遵循官方文档指引,并善用现代开发工具。以Redis 3.2.8版本为例,其README文件详细说明了从拉取代码、编译到启动服务的完整流程。即使你的主力开发语言是Java或Python,只要具备基础的C语言知识,结合文档和网络上的GDB调试教程,完全能够成功搭建起调试环境。
2. SCAN命令核心概念速览
在深入源码之前,必须明确学习目标:这个命令解决了什么问题?它的基本用法和输入输出是什么?没有清晰的“目标”,后续的分析就会失去方向。
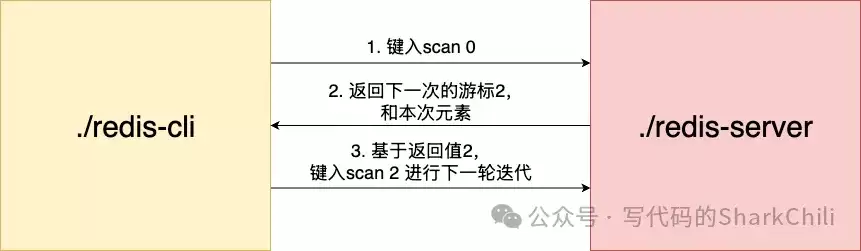
SCAN命令用于安全、增量地遍历数据库中的所有键(Key)。其基本工作流程是:
- 客户端提供一个游标(Cursor),起始值为0。
- 服务器根据游标定位到哈希表的一个特定“槽位”(Slot),返回该槽位中的部分或全部键。
- 同时返回一个新的游标值。如果新游标为0,则表示整个遍历结束。
例如,执行SCAN 0可能返回所有键,并告知下一次游标为0,表示迭代完成。
127.0.0.1:6379> scan 0
1) "0"
2) 1) "b"
2) "c"
3) "a"
4) "d"需要注意的是,迭代过程不保证返回的元素绝对不重复,尤其在字典发生缩容时。因此,客户端应用需要对结果集自行进行去重处理。
SCAN命令还支持两个重要参数:COUNT和MATCH。COUNT参数用于“提示”服务器每次希望返回的元素数量,但请注意,它仅仅是一个“提示”(Hint)。例如,指定COUNT 1,返回结果却可能包含2个元素:
127.0.0.1:6379> scan 0 count 1
1) "2"
2) 1) "b"
2) "c"这是Bug吗?并非如此。这恰恰体现了Redis在性能与精确性之间所做的精妙权衡。Redis的字典采用拉链法解决哈希冲突。SCAN的迭代单位是整个“槽位”。当游标定位到一个槽位时,它会遍历该槽位下的整个链表,将所有元素收集起来,之后才检查是否达到了COUNT参数的限制。因此,COUNT参数并不能精确控制单次返回的键数量,但这种设计保证了每次迭代的高效性,避免了在链表中间中断遍历带来的状态记录开销。
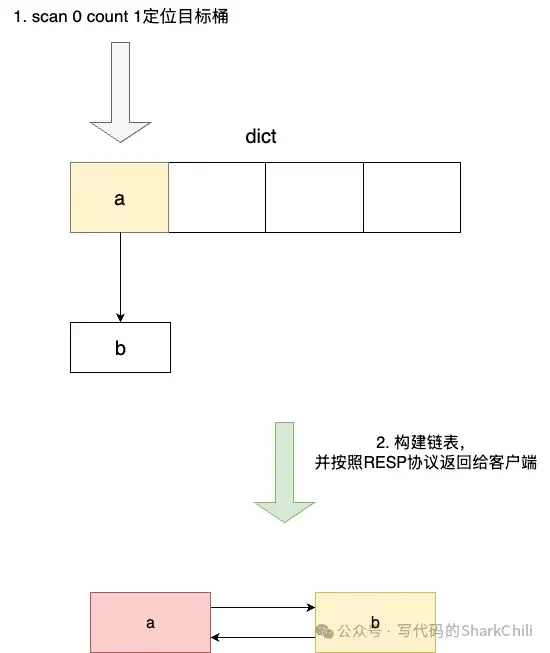
如果要在槽位内的链表上进行COUNT过滤,固然能提高返回数量的精确性,但实现复杂度会急剧上升,服务器需要记录更细粒度的游标状态(精确到链表中的某个节点)。这对于一个旨在提供高效、低状态开销遍历而非精确分页的命令来说,性价比太低。Redis的这种设计,堪称工程实践上的典范。
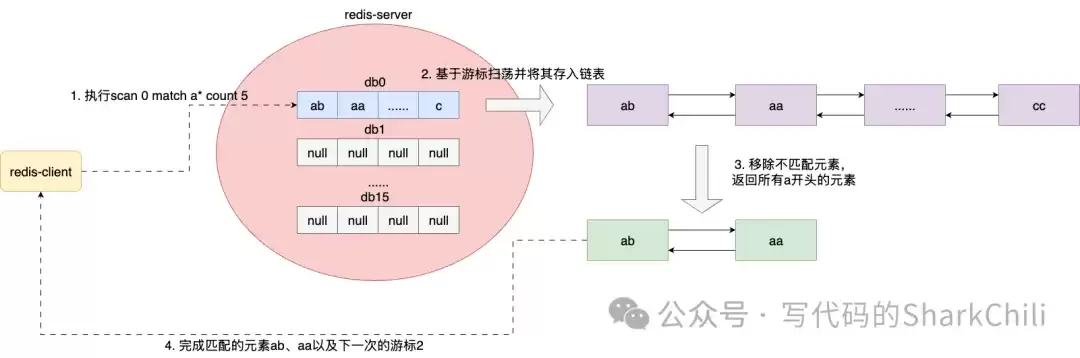
MATCH参数则用于基于模式的键过滤,例如查找所有以“c”开头的键:
127.0.0.1:6379> scan 0 match c* count 10000
1) "0"
2) 1) "c"二、深入剖析SCAN命令的设计与实现
1. SCAN命令执行流程总览
掌握了使用层面的知识后,便可以深入代码层了。首先定位到命令的入口函数:位于db.c文件中的scanCommand。从宏观来看,其执行流程非常清晰:
- 参数解析:校验游标有效性,解析可选的
COUNT和MATCH参数。 - 迭代收集:根据游标,使用特定的反向迭代算法遍历字典哈希表,将符合条件的键收集到一个链表中。
- 结果过滤:如果指定了
MATCH模式(且不是通配符“*”),则对链表中的键进行过滤。 - 组装返回:按照Redis协议格式,组装下一次的游标和过滤后的键列表,返回给客户端。
入口函数逻辑简洁,其主要工作是游标校验和调用核心逻辑函数:
void scanCommand(client *c) {
unsigned long cursor;
if (parseScanCursorOrReply(c,c->argv[1],&cursor) == C_ERR) return;
scanGenericCommand(c,NULL,cursor);
}核心逻辑封装在scanGenericCommand函数中,其结构清晰地对应了上述四个步骤:
void scanGenericCommand(client *c, robj *o, unsigned long cursor) {
// 1. 解析 COUNT / MATCH 参数
// 2. 迭代字典元素 (调用 dictScan)
// 3. 根据 MATCH 模式过滤链表
// 4. 组装并返回结果
}2. 游标参数解析
第一步是解析客户端传入的游标,确保它是一个有效的无符号长整型。实现简单直接,利用C标准库的strtoul函数进行转换,转换失败则向客户端返回“invalid cursor”错误。
int parseScanCursorOrReply(client *c, robj *o, unsigned long *cursor) {
char *eptr;
errno = 0;
*cursor = strtoul(o->ptr, &eptr, 10);
if (isspace(((char*)o->ptr)[0]) || eptr[0] != '\0' || errno == ERANGE) {
addReplyError(c, "invalid cursor");
return C_ERR;
}
return C_OK;
}3. COUNT与MATCH参数解析
接下来解析COUNT和MATCH参数。这里的实现有一个细节优化:它不是简单地顺序遍历参数列表,而是从索引2(即游标参数之后)开始,每次识别到一个已知的参数名(如“match”),就一次性跳过两步(参数名+参数值)去处理下一个参数。这减少了循环内的条件判断次数。
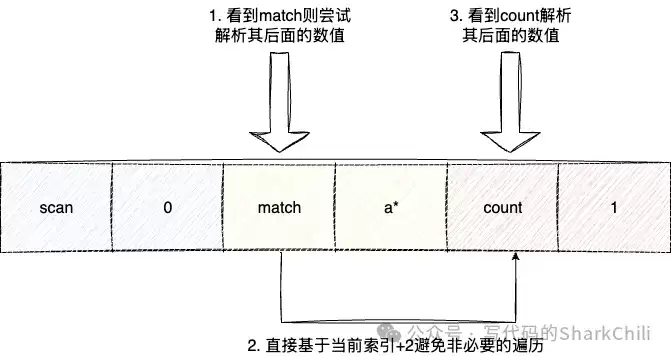
另一个性能优化点是:如果MATCH的模式是简单的通配符“*”,则后续直接跳过过滤逻辑,避免无谓的字符串匹配开销。
while (i < c->argc) {
j = c->argc - i;
if (!strcasecmp(c->argv[i]->ptr, "count") && j >= 2) {
// 解析COUNT值
i += 2; // 跳两步
} else if (!strcasecmp(c->argv[i]->ptr, "match") && j >= 2) {
pat = c->argv[i+1]->ptr;
patlen = sdslen(pat);
// 如果是“*”,则标记为无需模式匹配
use_pattern = !(pat[0] == '*' && patlen == 1);
i += 2; // 跳两步
} else {
// 参数错误
goto cleanup;
}
}4. 核心:反向二进制迭代算法
这是SCAN命令设计中最精妙、最核心的部分。Redis字典使用两个哈希表(ht[0], ht[1])来实现渐进式Rehash。如果采用简单的顺序遍历(0,1,2,3...),在Rehash过程中极易导致元素被重复遍历或遗漏。
假设哈希表大小为4,遍历完槽位2后,发生了扩容(大小变为8)。根据Rehash规则,原槽位2中的元素会分散到新表的槽位2和槽位6中。如果后续顺序遍历到槽位6,就会重复遍历到部分已迁移的元素。
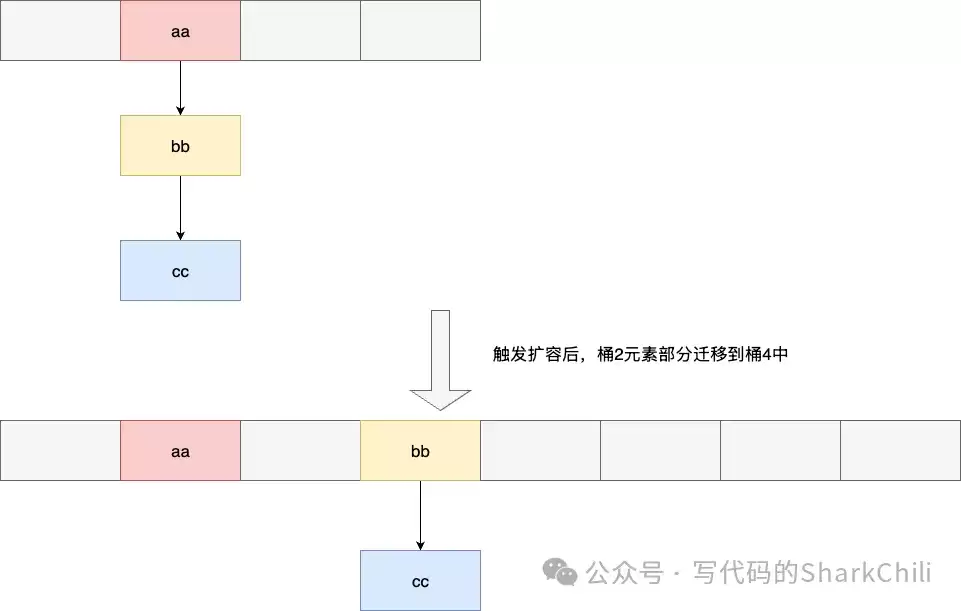
为了解决这个难题,Redis采用了独创的“高位优先反向二进制迭代算法”。其核心思想是:对游标的二进制位进行反转(reverse)、递增、再反转。这样产生的游标序列,能保证在哈希表扩容时,有映射关系的两个槽位(如原槽位x和扩容后的槽位x+size/2)会被连续访问到。
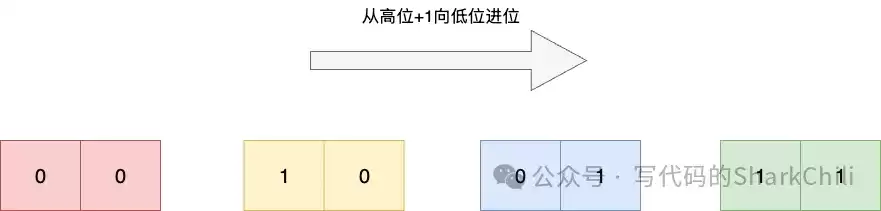
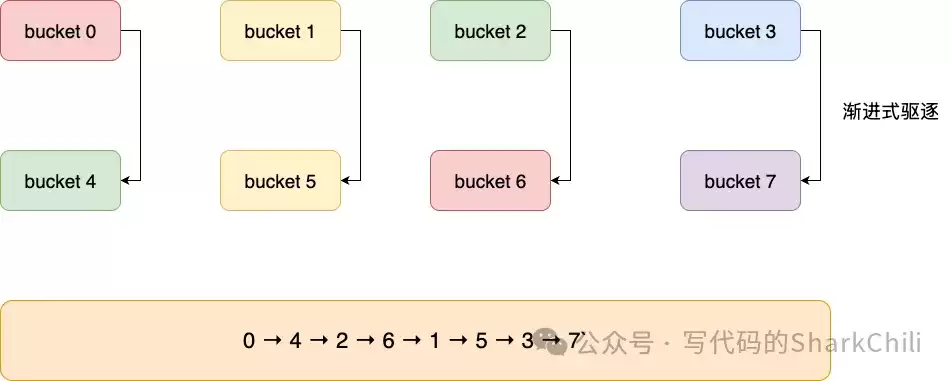
以一个大小为4(掩码m=011)的哈希表为例,该算法产生的遍历顺序是:0(00) → 2(10) → 1(01) → 3(11)。
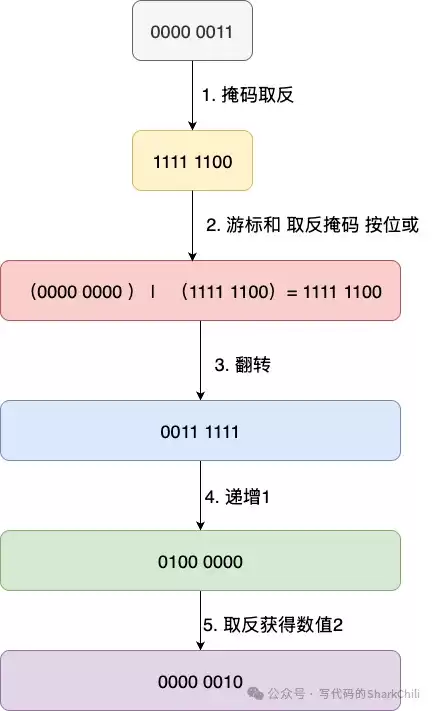
具体计算过程(以从游标0计算下一个游标2为例):
- 掩码取反:~m = ...11111100(高位全1,低两位为00)。
- 游标与取反后的掩码按位或:v |= ~m,确保高位全为1。
- 将结果二进制位反转:rev(v)。
- 反转后的值加1。
- 将加1后的结果再次反转:rev(v+1),得到新游标。
这个算法的威力在哈希表扩容时得以充分展现。当表从4扩容到8(掩码m=0111),从游标2(010)计算下一个游标时,结果是6(110)。整个遍历顺序变为:0→4→2→6→1→5→3→7。
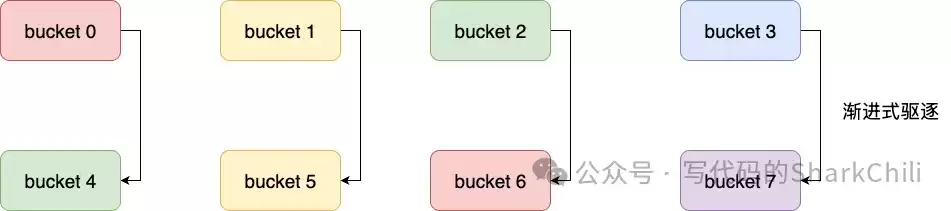
可以看到,有扩容映射关系的槽位对(0-4, 2-6, 1-5, 3-7)被紧挨着遍历。这最大限度地减少了在Rehash过程中元素被重复遍历或遗漏的概率,在保证迭代完整性的同时,兼顾了高性能。
该核心算法在dict.c文件的dictScan函数中实现:
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, void *privdata) {
// ...
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
de = t0->table[v & m0]; // 访问当前槽位
while (de) { // 遍历链表
fn(privdata, de);
de = de->next;
}
// 反向迭代算法计算下一个游标
v |= ~m0;
v = rev(v);
v++;
v = rev(v);
} else {
// 处理Rehash中的状态...
}
return v;
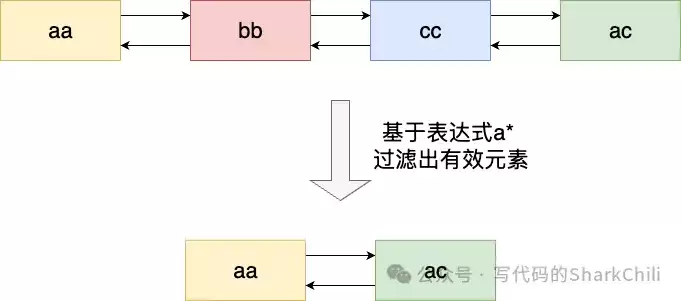
}5. 基于MATCH模式的结果过滤
迭代完成后,我们得到一个包含所有候选键的链表。如果用户指定了MATCH模式(且不是通配符“*”),则需要对链表进行过滤。逻辑非常直观:遍历链表,使用stringmatchlen函数检查每个键是否匹配给定的模式,不匹配则从链表中删除。
node = listFirst(keys);
while (node) {
robj *kobj = listNodeValue(node);
nextnode = listNextNode(node);
int filter = 0;
if (!filter && use_pattern) {
// 进行模式匹配,不匹配则设置filter=1
if (!stringmatchlen(pat, patlen, kobj->ptr, sdslen(kobj->ptr), 0))
filter = 1;
}
if (filter) {
// 删除不匹配的节点
decrRefCount(kobj);
listDelNode(keys, node);
}
node = nextnode;
}6. 组装并返回最终结果
最后,按照Redis RESP(REdis Serialization Protocol)协议格式返回结果。返回一个长度为2的数组:第一个元素是下一次迭代的游标,第二个元素是本次迭代返回的键列表。
addReplyMultiBulkLen(c, 2); // 数组长度2
addReplyBulkLongLong(c,cursor); // 下一次游标
addReplyMultiBulkLen(c, listLength(keys)); // 键列表长度
// 遍历链表,逐个返回键
while ((node = listFirst(keys)) != NULL) {
robj *kobj = listNodeValue(node);
addReplyBulk(c, kobj);
decrRefCount(kobj);
listDelNode(keys, node);
}至此,一次完整的SCAN命令调用流程便执行完毕。
三、总结与高效源码阅读方法论
至此,我们完成了一次对Redis SCAN命令从使用到源码的深度剖析。回顾整个过程,可以提炼出一套高效阅读复杂源码的通用方法论:
- 环境先行:搭建可运行、可调试的环境,这是理解动态逻辑和验证猜想的基础。
- 目标明确:清晰定义你要分析的模块或功能的输入、输出和核心行为。
- 由宏入微:先理清代码的主干流程和函数调用关系,再深入关键算法和细节实现。
- 善用工具:对于难以理解的算法,结合图示、手动演算、调试器观察,乃至利用AI进行辅助分析和解释,多角度交叉验证。
- 总结复盘:通过撰写文章、绘制流程图或思维导图,将你的理解固化为结构化的知识,加深记忆。
技术领域日新月异,工具在迭代,方法在演进,但追求高效、深刻理解系统本质的工程师精神是永恒的。面对复杂的开源系统,与其固守“手动至上”的教条,不如主动拥抱一切能够提升认知效率的合理工具与方法。源码面前没有秘密,但打开秘密之门的钥匙,正是一套科学、开放且高效的方法论。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Canva可画AI设计模板:高效创作生成式搜索内容
Canva可画的生成式搜索功能能快速匹配视觉风格与内容场景。使用“行业+用途”组合关键词或加入风格词可精准推荐模板,提升效率。节日热点支持自然语言触发,多模态提示词则能进一步提升素材匹配精度,适合各类定制化设计需求。

Trae AI能自动解决Git合并冲突吗
Trae为Git合并冲突提供智能化辅助,能理解语义并提供决策建议。它通过AI自动识别标准冲突标记并触发辅助机制,尤其在VSCode集成环境中,可借助编辑器捕获完整上下文,由AI模型进行推理分析。

矩阵超智MATRIX-3人形机器人发布:搭载英伟达AGX与自研关节,售价58万起
矩阵超智发布MATRIX-3人形机器人,身高170厘米,体重65公斤,搭载英伟达AGX算力平台与自研直线关节,峰值推力达5000N。机身覆盖3D仿生织物,具备触觉感知与碰撞即停功能。机器人支持4小时续航与20分钟快充,现已开启预订,标准版售价58万元起,主要面向高端制造与物流等企业级场景。

RAG性能瓶颈分析与ACL 2026最新优化方案
RAG系统瓶颈在于信息整合而非检索。Verbal-R3框架引入“口头注解”机制,通过口头重排序器对检索文档进行解释性分析,过滤噪声并建立逻辑关联,再交由生成器推理。该方法显著提升了问答性能,尤其在多跳任务中表现突出,且通过模型蒸馏实现了低成本高效部署。

Redis SCAN源码解析:AI时代高效数据检索的底层逻辑
针对依赖工具削弱能力的观点,通过分析Redis的SCAN指令源码进行回应。SCAN用于迭代数据库键,其设计在性能与精确性间权衡,采用反向迭代算法保证遍历效率,尤其在字典扩容时避免重复。解析了从参数解析、游标计算到结果过滤的完整流程,展示了结合传统调试与AI分析的高效源码阅读方法。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
