




火山引擎TempR1模型提升多模态大模型视频时序理解能力

在智能视频检索、人机交互或是长视频内容分析这类实际应用中,多模态大模型对视频动态和时序语义的理解能力,无疑是决定其智能水平的关键。然而,现有的技术路径似乎总有些“顾此失彼”:要么方法过于专一,换个任务就水土不服;要么在训练中陷入僵化,难以捕捉那些微妙而重要的时序依赖关系。
最近,一项由多媒体实验室与南京大学合作的研究带来了新的思路。他们提出的TempR1方法,基于时序感知的多任务强化学习,系统性地提升了模型在各类视频时序理解任务上的推理能力。在五大主流时序任务上,这一方法均取得了领先的性能,为处理更长的视频、进行更复杂的时序推理,奠定了一个可扩展的新范式。

核心痛点:现有方法的两大局限
要理解TempR1的价值,得先看看当前的主流方法遇到了什么瓶颈。目前,基于多模态大模型的视频时序理解方法,主要走两条路:监督微调(SFT)和强化学习(RL)。但这两条路,都各有各的“坎儿”。
监督微调方法,依赖大规模指令数据进行精细调整,虽然能提升时序理解,却容易在有限的数据集上“学得太死”,导致过拟合。更棘手的是,这种刚性的监督信号,有时会以牺牲模型的通用推理能力为代价。
强化学习方法则更直接,通过优化特定任务目标来训练模型,通常数据效率和泛化性更好。但问题在于,现有研究大多只聚焦于“时序定位”这一单一任务。对于需要同时处理多个事件、进行动作定位,或者回答与时间点紧密相关的问题等更复杂的场景,支持力度明显不足。传统任务专用的架构设计,也让模型难以跨任务、跨领域迁移,每面对一个新数据集,都可能需要从头训练,灵活性和扩展性大打打折扣。
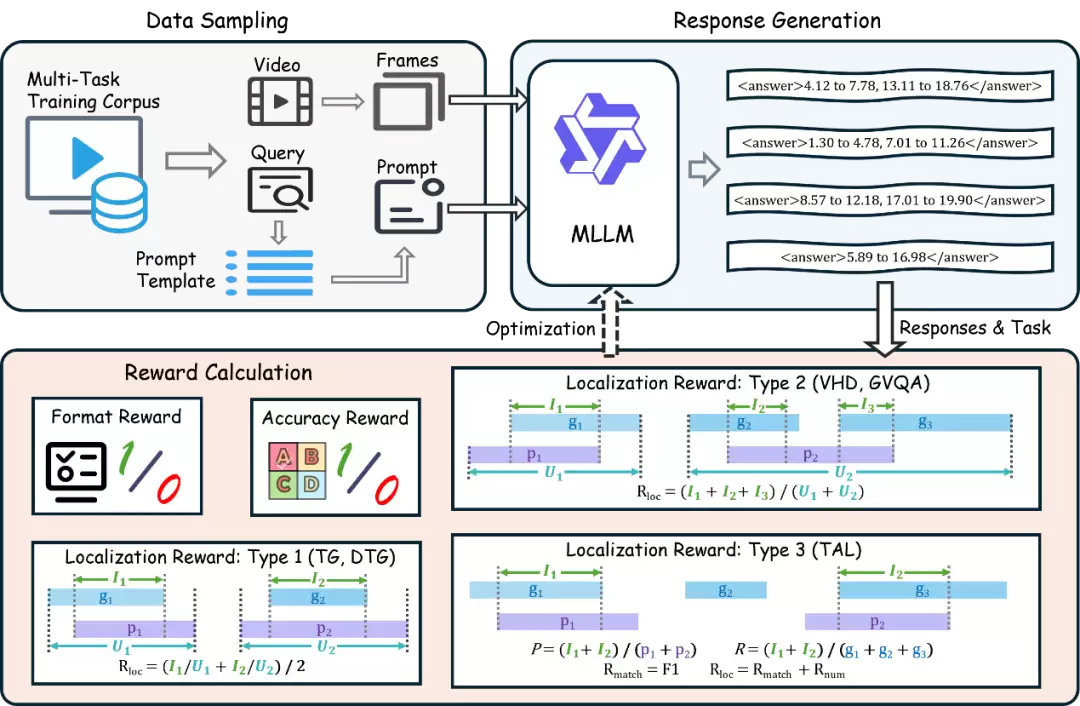
TempR1的核心创新:多任务强化学习+定制化时序奖励设计
面对这些局限,TempR1的解决方案围绕两个核心展开:一是构建一个能协同训练多种任务的学习框架,二是为不同任务设计精细化的奖励机制。其底层采用了Group Relative Policy Optimization(GRPO)算法,以实现稳定的跨任务优化。这样一来,模型既能学到不同时序任务背后的共通逻辑,又能精准适配每个任务的独特时序特征。
1. 组织6万+样本的多任务时序语料库
研究团队首先构建了一个覆盖五大典型视频时序理解任务的高质量语料库,样本量超过六万。这些任务包括:时序定位(TG)、稠密时序定位(DTG)、时序动作定位(TAL)、视频亮点检测(VHD),以及基于定位的视频问答(GVQA)。这个多样化的语料库,旨在让模型充分暴露于各种时序事件结构中,学习不同场景下的推理逻辑。
2. 三类时序区间-实例对应关系,定制化定位奖励
这是TempR1设计中的一大亮点。研究团队没有使用“一刀切”的奖励函数,而是根据预测的时间区间与真实事件实例之间的对应关系,将时序定位任务细分为三种类型,并为每一类“量身定制”了奖励函数:
一对一(如TG/DTG):预测区间与真实事件严格一一对应。这种情况下,直接采用预测区间与真实区间的平均时序交并比(IoU)作为奖励,鼓励精准定位。
多对一(如VHD/GVQA):多个预测区间可能共同对应一个真实实例。处理方式是先将所有相关的预测区间和真实区间分别聚合,再计算聚合后的IoU作为奖励。
多对多(如TAL):预测的实例数量可能与真实数量不同,情况最为复杂。为此,TempR1融合了两种奖励:一是实例数量奖励(惩罚数量不匹配),二是通过动态规划算法进行最优匹配后计算的总IoU(进而得到F1值)。这种设计同时兼顾了对实例计数的准确性和对时序边界定位的精度要求。
3. 统一强化学习框架,多奖励协同优化
在上述基础上,TempR1在GRPO算法框架下,整合了多种奖励信号:首先是“格式奖励”,确保模型输出机器可解析的规范时序格式;其次是上述针对不同任务的“专属定位奖励”;此外,对于基于定位的视频问答(GVQA)任务,还增加了评估答案准确率的“分类奖励”。所有这些奖励被组合成一个统一的总奖励函数,驱动模型进行端到端的多任务联合优化。值得一提的是,这种方法避免了引入单独的“批评者”网络,显著降低了训练的计算开销。
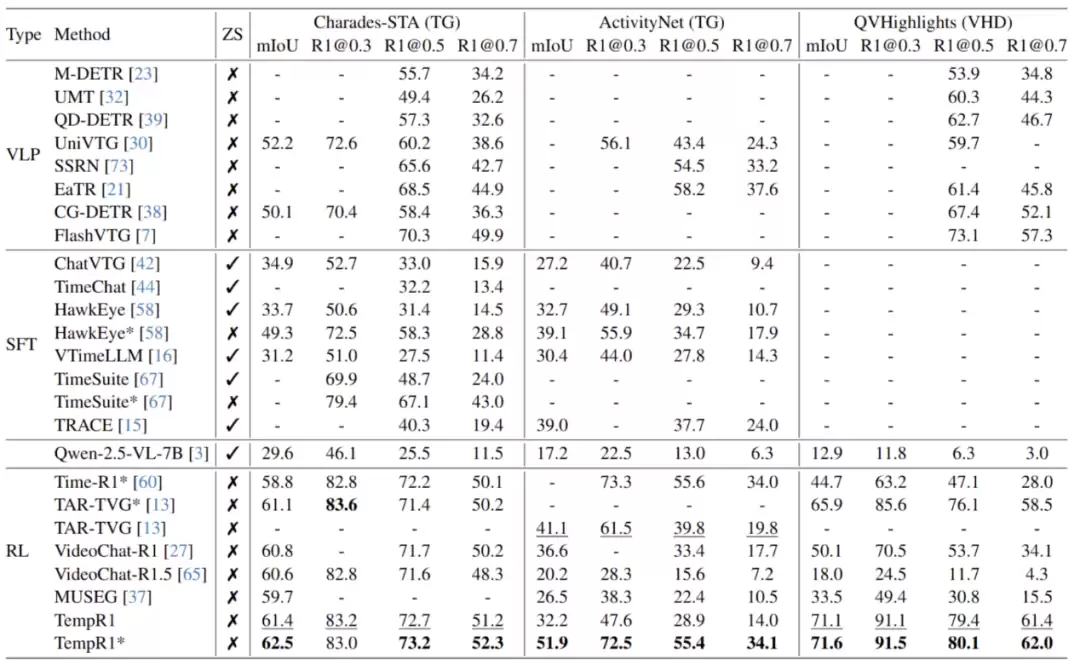
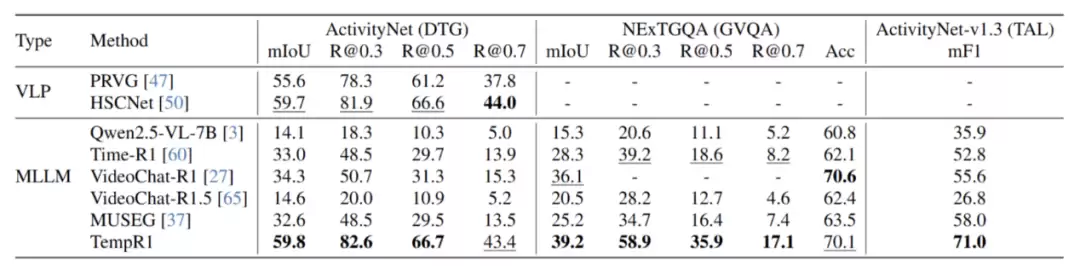
实验结果:五大任务全面领先,泛化性与单任务性能双提升
研究团队以Qwen2.5-VL-7B作为基础模型,在多个公共基准数据集上进行了全面评估。结果证实了TempR1框架的有效性:
核心时序任务全面领先:在Charades-STA、ActivityNet-Caption的时序定位/稠密时序定位任务,QVHighlights的视频亮点检测任务,NExT-QA的基于定位的视频问答任务,以及ActivityNet-v1.3的时序动作定位任务中,TempR1均取得了当前最优的性能。例如,在QVHighlights数据集上,其mIoU达到了71.1,超出第二名5.2个百分点;在ActivityNet-v1.3的时序动作定位任务上,其mF1分数达到71.0,大幅超越MUSEG基线模型13个百分点。
多任务协同效应显著:消融实验揭示了一个有趣的现象:随着参与联合训练的任务数量增加,模型在各个基准测试上的性能持续提升,当五大任务一同训练时,效果达到最佳。这有力地验证了不同时序任务之间存在知识迁移和能力互补的强协同效应。
保持通用视频理解能力:与监督微调常导致模型“偏科”不同,TempR1通过强化学习进行微调,在专项时序能力提升的同时,并未牺牲通用性。在VideoMME、MVBench等通用视频理解基准测试上,其表现也显著优于原始基础模型及仅经过监督微调的模型。
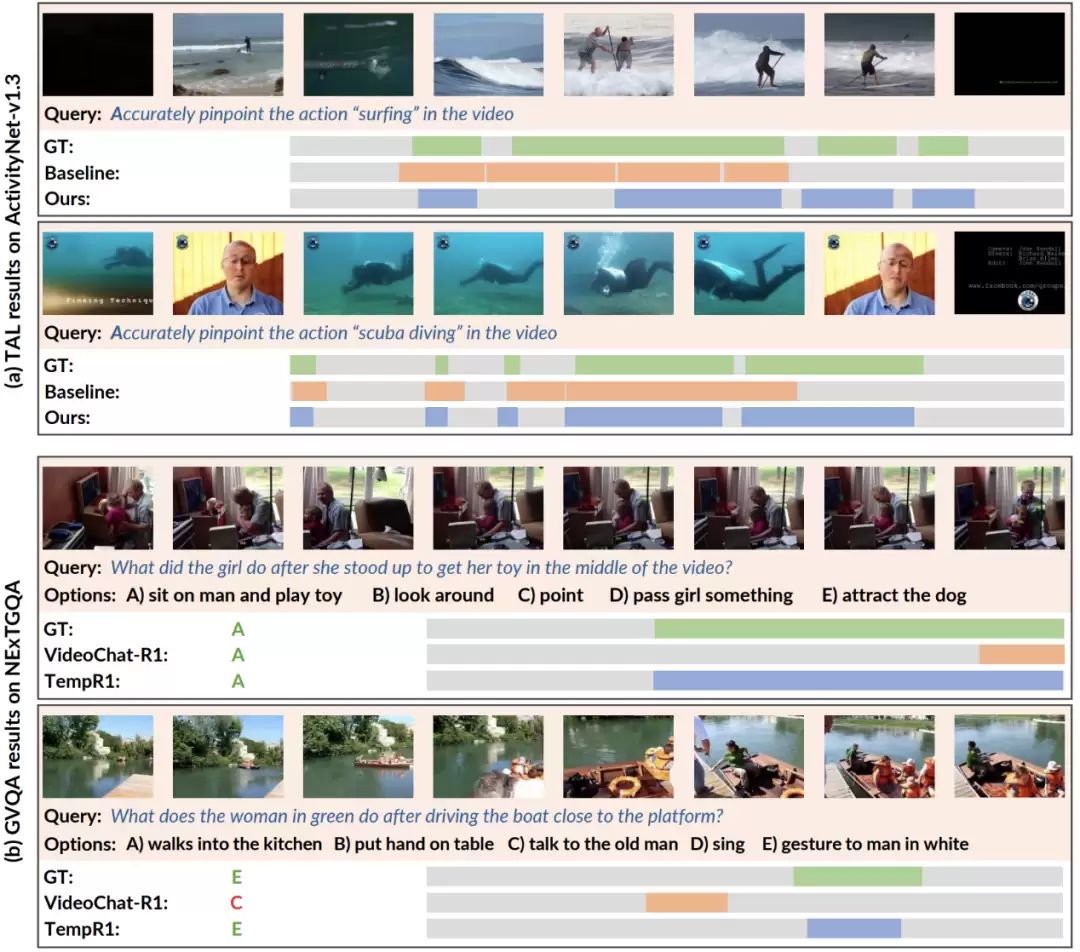
定性分析:更精准的时序定位,更一致的推理逻辑
除了冷冰冰的数字,可视化分析更能体现模型的“思考”过程。在时序动作定位任务中,TempR1采用的动态规划匹配策略,能够在包含多个实例的复杂场景下,实现预测区间与真实实例的精准对齐,定位结果更加准确和一致。
在基于定位的视频问答任务中,TempR1不仅能够给出正确答案,还能提供更为完整和精准的时序片段作为证据,实现了视觉证据与文本答案之间的推理一致性,其表现优于VideoChat-R1等基线模型。
总结与展望
总体来看,TempR1通过引入多任务强化学习框架、构建覆盖广泛的高质量时序语料库,以及针对不同时序特性设计定制化奖励,系统性地提升了多模态大模型在视频时序理解上的准确度与泛化能力。它成功实现了跨任务的性能协同增益,并保持了模型原有的通用视频理解水准。
这项研究为优化多模态大模型的时序推理能力提供了一条可扩展的新路径,也为长视频分析、智能视频检索等实际应用带来了更强的技术支撑。展望未来,基于这一框架,可以进一步拓展到更多、更复杂的视频时序理解场景中,持续推动多模态大模型对动态视觉世界的深度理解和推理。
论文链接:https://arxiv.org/abs/2512.03963

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

DeepSeek模型幻觉源于特殊字符输入不涉及安全隐私问题
近期,DeepSeek用户社区中流传着一个有趣的发现:部分用户在对话中输入“think”等特定字符时,模型偶尔会产生一些预期之外的回复。这一现象迅速引发了广泛关注和讨论,许多用户不禁产生疑问:这是否意味着对话隐私存在风险?或是模型出现了安全漏洞? 针对用户反馈的DeepSeek模型异常回复问题,官方

AI原生IDE对决Cursor与IDEA Java程序员选择指南
Cursor vs IDEA:AI原生IDE的碘伏之战,Ja va程序员该如何选择? 2026年,AI编程工具的战场硝烟弥漫。Cursor凭借其AI原生的设计理念横空出世,而传统巨头JetBrains也宣布与Cursor达成深度集成(ACP协议)。面对这场变革,Ja va开发者是应该拥抱新锐的Cur

AI一键生成海量课程讲解文案的实用技巧
你是否想过将复杂的知识主题拆解为系列课程,再通过三人脱口秀的形式生动呈现?如今,这一创意已固化为一个名为“三人行技能”的实用工具。 简而言之,它是一个“任意主题 → 三人脱口秀课程文档”的批量生成器。用户只需提供课程主题、分节大纲及三位主播的人设,该工具便能自动生成一批格式规范、内容详实的Word文

宇树科技发布人形机器人实时动作生成一镜到底视频
5月19日,宇树科技发布了一则一镜到底的演示视频,展示了其G1人形机器人仅通过语音指令,即可自主实时生成并执行多样化动作的突破性能力。 视频内容清晰直观:操作者直接通过语音发出各种动作指令,宇树G1机器人便能实时理解并响应,自主生成对应的肢体动作。整个演示采用一镜到底的拍摄方式,现场同步收音,无任何

高校AI通识课如何设计才能满足不同学生需求
全国大学生机器人大赛ROBOTAC赛事在山东烟台举办,来自全国71所高校的183支代表队同场竞技。孙文潭摄 光明图片 江苏大学举办的计算机文化节上,智能机器人、循迹小车、混合现实、飞行模拟等现代科技集中亮相。杨雨摄 光明图片 【AI与教育】 下午两点,某高校阶梯教室。老师在讲台上讲解“机器学习的基本








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
