




SentiAvatar革新3D数字人动作生成技术

与3D数字人互动时,你是否曾感到一丝难以言喻的“不自然”?它的嘴唇在同步发音,表情却略显呆板;手臂虽有动作,却与对话内容缺乏关联。更常见的是,那些外观高度拟真但动作僵硬、节奏失调的数字人,很容易将用户体验带入“恐怖谷”效应。
问题的核心在于,人类的高效沟通从来不是单一维度的信息传递。一个细微的耸肩足以传达无奈,一次肯定的点头就能建立共识,而眉梢的微动则可能泄露内心的疑虑。这些由手势、身体姿态和面部表情共同构成的非语言信息网络,才是真实人际交流中不可或缺的“血肉”,承载了超过一半的沟通信息。
目前,许多3D数字人的动作生成技术仍依赖于通用动作库的机械组合,难以精准表达复杂的语义内涵和细腻的情感层次。而这种自然、连贯且富有表现力的动作生成能力,正是3D数字角色实现深度交互的灵魂:对于虚拟偶像或客服,它是建立情感连接与信任的桥梁;对于服务型机器人,它是实现人机无缝协作的基石;对于游戏与影视角色,它则是赋予其生命力和沉浸感的关键。
转机已经到来。AI初创公司SentiPulse与中国人民大学高瓴人工智能学院的研究团队联合提出了一项创新成果——SentiAvatar 3D数字人动作生成框架。这一全新范式旨在构建具备高度表现力的交互式3D数字人。基于该框架开发的虚拟角色“SUSU”,已能够实时协调语言内容、肢体动作与情绪表达,实现多模态同步输出。

目前,SentiAvatar技术框架、3D数字人SUSU角色模型及其高质量多模态动作数据集SuSuInterActs已面向全球研究者和开发者开源。

为何3D数字人显得“不真实”?三大技术瓶颈待突破
让3D数字人在实时对话中做出自然、得体的动作,看似是动画优化问题,实则涉及三个长期未被协同解决的核心挑战:
第一,高质量中文多模态数据稀缺。现有公开数据集多以英语为主,且普遍缺乏与语音精确同步的高精度面部表情数据。针对中文对话场景,包含全身动作、表情和语音的高质量对齐数据几乎处于空白状态。
第二,复合语义动作生成失真。当指令从简单的“挥手”变为“无奈地耸肩”或“兴奋地鼓掌”这类包含情感和意图的复合语义时,现有模型的生成效果往往大打折扣,导致动作与表达意图严重不符。
第三,动作与语音节奏脱节。生成的动作要么节奏单调缺乏变化,要么无法匹配语音中的重音、停顿和语速起伏,造成视听体验上的割裂感。
那么,能否让数字人既能准确理解对话的深层语义,又能生成与语音韵律严丝合缝的流畅动作?这需要从问题建模的底层进行革新。
技术本质:语义规划与韵律驱动需分层处理
现有方法在对话驱动动作生成上常面临权衡困境:全局语义对齐要求模型理解句子层面的行为意图(例如“表达质疑”),并规划出整体的动作序列;而帧级韵律对齐则要求动作的细微节奏能实时响应语音每一帧的韵律特征。这两者分别作用于句子和帧两个不同的时间尺度,强行融合到一个模型中往往导致效果不佳。
传统的共语音手势生成方法(如EMAGE、TalkShow等)倾向于将动作视为音频的直接映射,缺乏高层语义指导;而纯文本驱动的动作生成方法(如T2M-GPT、MoMask等)则完全忽略了音频信号,无法捕捉韵律对动作时序的精细影响。SentiAvatar的创新之处,正是将这两个目标解耦,采用“先规划语义,后驱动细节”的分阶段处理策略。
SentiAvatar:3D数字人动作生成的新一代解决方案
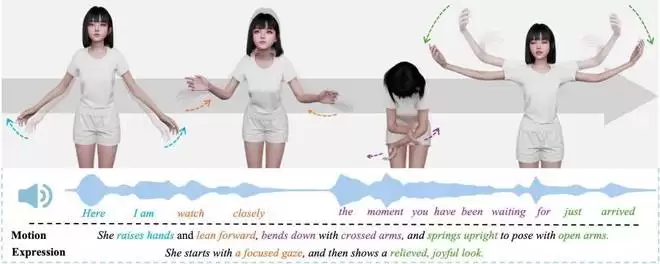
为了系统性地解决上述挑战,SentiPulse团队基于统一的SentiAvatar技术框架,打造了虚拟角色SUSU,并构建了高质量的SuSuInterActs中文多模态对话数据集。该数据集包含2.1万段高质量对话片段,总时长37小时,通过专业光学动作捕捉系统采集,围绕单一角色同步收录了语音、全身动作与面部表情数据。此外,团队在超过20万条多样化动作序列上预训练了一个动作基础模型,使其学习了丰富的通用运动先验知识。在此基础上,团队创新性地提出了“先规划,后填充”的全新架构,将句子级语义规划与帧级韵律驱动解耦,从而生成既符合高层语义意图,又在节奏上与语音高度同步的自然动作。
SuSuInterActs数据集:填补中文高质量多模态数据空白
高质量数据是模型训练的基石。现有共语音数据集主要存在两大局限:一是以英语语料为主,二是缺乏精确同步的面部表情数据,这在中文场景下制约了模型的表现。
SentiPulse团队围绕虚拟角色SUSU(设定为22岁,性格温柔活泼),从头构建了SuSuInterActs数据集。该数据集包含2.1万段片段、37小时的多模态对话数据,涵盖同步的语音、带有行为意图标注的文本、全身骨骼动作及面部表情参数。
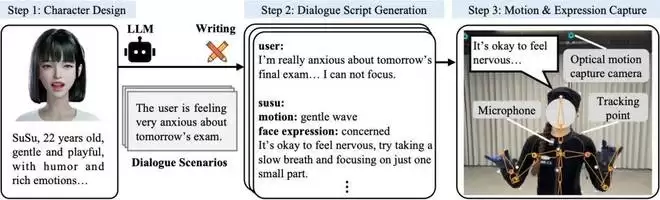
数据构建流程分为四步:首先,利用大语言模型生成带有详细行为标注的中文对话脚本。接着,由专业动捕演员使用Nokov光学动捕系统、MANUS数据手套及iPhone ARKit进行多模态同步录制。随后进行数据清洗、对齐与后处理(统一至20FPS)。最终数据集规模达21,133条样本,总时长36.9小时,覆盖日常交流、情感陪伴、趣味问答等多种交互场景。每条样本包含四路精确同步的数据:中文对话文本(含语义标注)、语音音频(WAV格式)、全身骨骼动作(63个关节,6D旋转表示)、面部混合形状系数(51维ARKit参数)。其中,超过1.4万条包含非默认动作标注,超过9千条包含非默认表情标注。聚焦单一角色的设计,有助于模型学习更一致、更具个性化的行为风格。
动作基础模型:海量数据预训练积累通用运动先验
对话数据集的动作多样性受限于特定场景。为了突破这一限制,团队在预训练阶段引入了自研的动作基础模型,在超过20万条多样化动作序列(约676小时)上学习通用运动模式。训练数据来源广泛,包括:
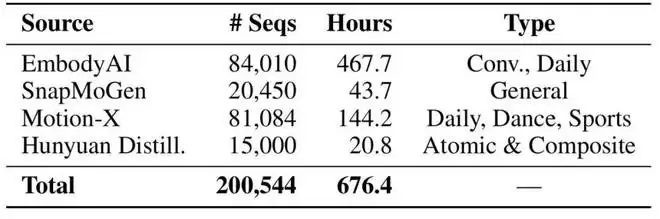
其知识构建流程经过精心设计:通过挖掘基础动作动词、利用大语言模型扩展同义描述、组合模板生成复合动作指令,并引入专项运动数据,系统性地扩展了模型对动作语义的理解边界。该基础模型以Qwen-0.5B为骨干网络,词表扩展至包含2,048个动作Token和音频Token,通过文本-动作生成任务进行预训练,所有文本描述均统一为中文,确保语言空间的一致性。
核心架构:分而治之的“规划-填充”双阶段模型
基于对话生成动作的核心,在于理解高层语义并规划执行。SentiAvatar采用双通道并行架构,将身体动作与面部表情分开处理。身体动作通道由两个串联阶段构成。
1. 身体动作通道
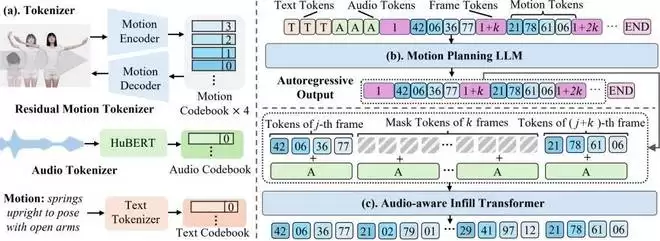
第一阶段,大语言模型语义规划器接收带有行为标签的文本和稀疏的音频Token,输出一系列稀疏的关键帧动作Token。为支持多轮连续对话生成,模型会以前一句末尾的关键帧作为上下文,实现跨句动作的平滑过渡。
第二阶段,身体填充变换器负责在关键帧之间插入自然的中间帧。它以从音频中逐帧提取的HuBERT连续特征作为条件信号。模型采用5帧滑动窗口,已知首尾帧,预测中间3帧。推理时采用迭代置信度解码策略,逐步生成高置信度的结果,确保动作质量。
2. 面部表情通道
面部表情的动态与语音韵律高度耦合,因此无需经过句子级语义规划。面部填充变换器直接根据音频特征生成面部Token序列,再解码为面部动作参数。两个通道共享音频特征提取器,端到端延迟低,支持实时流式生成。
性能表现与实验验证:多项指标达到领先水平
在工程落地方面,SentiAvatar实现了低延迟实时生成,可在0.3秒内生成6秒的动作序列,支持流式交互,满足实时对话应用需求。
整体实验结果:在多个数据集上表现优异
实验表明,SentiAvatar在自建的SuSuInterActs测试集和公开的BEATv2数据集上均取得了当前最优或接近最优的结果。在SuSuInterActs上,其文本-动作检索召回率显著优于基线模型;FID分数大幅降低,表明生成动作的真实性更高。在跨数据集评测BEATv2上,SentiAvatar刷新了FGD和BC两项关键指标,展现了优秀的泛化能力。同时,其生成动作与语音节奏的事件同步距离也达到了最佳水平,证明其动作与语音同步性更好。
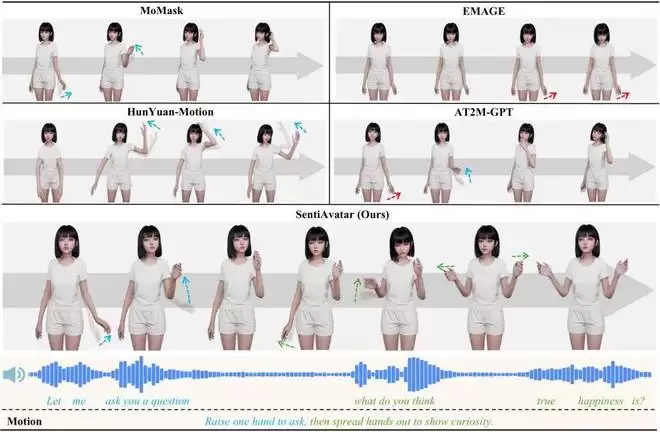
定性分析对比:SentiAvatar生成效果更自然
团队将SentiAvatar与主流3D动作生成模型进行了可视化对比。结果显示,SentiAvatar生成的动作语义正确性最高,且与音频波形在时间线上对齐得最好。其他模型或在语义理解上存在偏差,或在节奏同步上表现不足,或存在不自然的身体姿态。
消融实验:验证各模块不可或缺
架构消融实验证明,移除大语言模型规划器会导致语义理解能力大幅下降;移除填充变换器则会导致动作不连续、节奏不自然。音频条件消融实验进一步表明,连续音频特征对帧级同步至关重要,而离散音频Token有助于整体动作规划,验证了分层设计的有效性。
开源与展望:从“数字形象”到“数字生命”的演进
随着SentiAvatar框架、数据集及模型在GitHub上全面开源,SentiPulse团队期待与全球研究者和开发者共同推动3D数字人动作生成技术的发展。当前,3D数字人领域的竞争焦点正从视觉逼真度,转向更深层的认知与表达能力。未来的技术突破,将在于构建更完整的表达模型、统一的人格系统和长期的交互记忆。当数字人能够真正理解语境、表达情绪并进行主动交互时,人机关系的范式将被重塑。下一代具备认知表达能力的“数字生命”,正在从愿景走向现实。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

大模型训练合成数据生成的十大实用策略
合成数据,这个曾经被视为“辅助工具”的技术选项,如今正快速演进为驱动大模型开发与迭代的核心基础设施。对于任何致力于长期模型训练、优化和持续升级的团队而言,构建高质量的合成数据能力已成为一项战略性任务。 背后的驱动力非常现实:获取大规模、高质量的训练数据始终是AI团队面临的主要瓶颈。数据或许存在,但面

Claude代码能力更新引争议思考深度下降难处理复杂工程
近期,AI编程工具Claude Code的性能表现引发了开发者社区的广泛关注与深度讨论。一份在官方仓库引发热议的Issue直指核心问题:这款曾被寄予厚望的AI编程助手,在经历特定更新后,其处理复杂工程任务的能力似乎出现了显著退化。 核心指控聚焦于一次关键更新:据称,该更新导致模型的内部推理深度骤降约

SentiAvatar革新3D数字人动作生成技术
与3D数字人互动时,你是否曾感到一丝难以言喻的“不自然”?它的嘴唇在同步发音,表情却略显呆板;手臂虽有动作,却与对话内容缺乏关联。更常见的是,那些外观高度拟真但动作僵硬、节奏失调的数字人,很容易将用户体验带入“恐怖谷”效应。 问题的核心在于,人类的高效沟通从来不是单一维度的信息传递。一个细微的耸肩足

Claude Code内置工具与技能完整清单揭秘
在上一篇文章中,我们深入剖析了Claude Code的System Prompt架构与提示词工程。今天,我们把目光转向它的“能力体系”——一个由40多个内置工具、5个专用Agent以及一套完整的斜杠命令构成的强大工具箱。所有洞察,均源自对源码的深度分析。 一、工具全景:40+ 个内置工具 Claud

匹兹堡大学新作实现一句话生成逼真3D场景
视觉语言大模型(VLM)在描述图像内容时往往头头是道,可一旦面对三维空间推理,短板就暴露无遗。物体一多,视角一换,模型的认知底线很容易被击穿。 更棘手的是,想精准评估这种能力也困难重重。真实世界的数据集采集成本高昂,且难以灵活调整参数;而程序生成的3D场景又常常显得虚假、违背物理规律。业界一直缺少一








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
