




DeepSeek内容异常回应解析 特殊字符引发模型幻觉非安全问题

5月19日,DeepSeek官方针对近期用户反馈的模型内容返回异常问题,发布了正式声明。官方明确指出,此次异常是由特定字符触发的模型幻觉现象所导致,与系统安全漏洞或用户隐私数据泄露无关。同时,官方表示将通过专项训练持续优化模型,以彻底解决此类问题,提升用户体验。
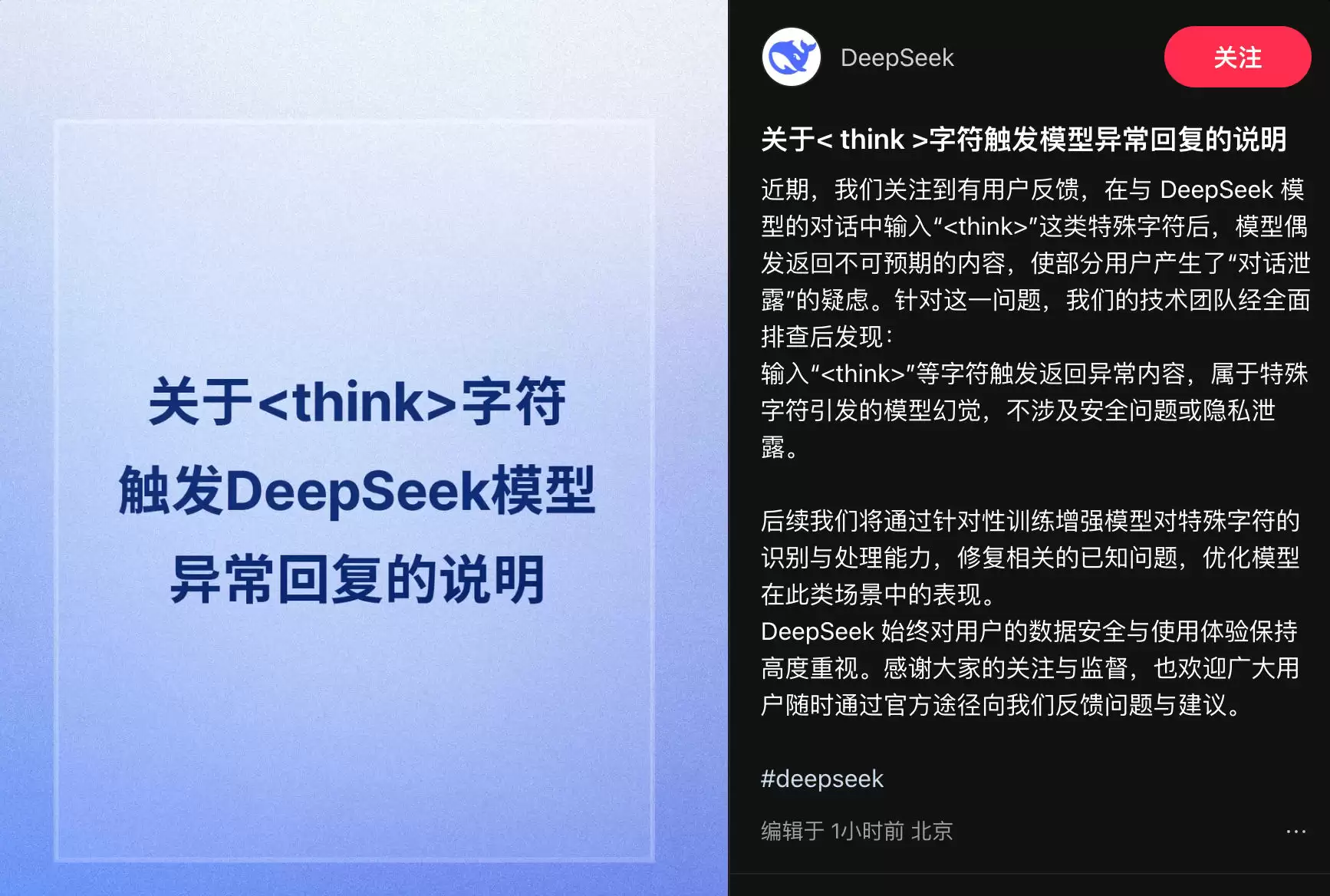
在声明中,DeepSeek技术团队详细解释了问题根源:当用户输入“
这一事件的起因可追溯到数日前。众多用户在社交媒体及技术社区反映,在使用DeepSeek网页版时遇到了一个奇特现象。当他们在新建的空白对话框中,仅输入“”或类似字符并发送后,模型并未请求澄清或报错,而是自动输出一系列结构完整、但与当前对话上下文完全无关的问答内容。这些生成内容范围广泛,涉及数学求解、物理概念阐释、线性代数、命理分析乃至教育理论等多个领域。
若仔细分析这些自动生成的回复,可发现其语言风格高度格式化,频繁出现“我们被问到……”或“需要询问……”等书面化、第三人称的引导句。令部分用户感到担忧的是,在测试中甚至出现了涉及个人生辰八字等敏感信息的生成内容。这引发了用户的疑虑:是否个人对话数据遭到泄露?或模型的训练数据发生了异常?
对此,DeepSeek技术团队从AI技术角度给出了专业解释——“模型幻觉”。在人工智能领域,“幻觉”特指模型生成看似合理、实则不正确或与输入无关信息的行为。具体到本次事件,特殊字符“”在模型复杂的内部推理机制中,可能被错误地识别为某种系统指令或分隔符,从而触发模型进入预设的“思维链”推理模式。
因此,当普通用户在前端界面无意中输入该字符时,模型误将其判定为内部指令。这导致了一种非预期行为:模型试图自动补全一个它“假设”存在、但用户并未实际提出的“问题”。随后,模型便从其庞大的预训练语料库中,依据概率分布,“创造性”地合成一段结构化的问答内容进行输出。需要强调的是,这并非调取了其他用户的实时对话记录,而是模型基于其固有训练数据所进行的一种惯性补全与生成。

有技术专家为验证此解释,在完全断网的本地部署环境中成功复现了相同现象。该实验从技术层面排除了“实时串扰其他用户会话”的可能性。因为在物理隔离的本地环境中,模型的输出完全依赖于其内置的权重与参数,这进一步证实了此次事件属于“模型幻觉”,而非“数据泄露”。
“模型幻觉”:大语言模型行业的共性挑战与风险应对
事实上,“模型幻觉”并非DeepSeek独有的问题,它是当前整个大语言模型(LLM)行业面临的核心技术挑战之一。根据上海申银万国证券研究所今年1月发布的行业分析报告,大模型的幻觉主要表现为无中生有、事实性错误、语境误解、逻辑谬误等多种形式。其成因复杂,涉及模型架构的固有局限、训练数据质量不均、奖励机制设计不完善以及上下文长度限制等多重因素。报告同时指出,通过引入RAG(检索增强生成)等工程化技术路径,预计到2026年,AI模型的幻觉问题将得到显著缓解,其在部分严肃应用场景下的可靠性正逐步提升。
然而,现实评测数据所揭示的挑战依然严峻。多项国际权威测评显示,不同大型语言模型的幻觉率存在显著差异。在通用任务中,主流模型的幻觉率通常介于20%至27%之间。但一旦进入法律咨询、医疗诊断等对事实准确性要求极高的高风险垂直领域,部分模型的幻觉率可能急剧攀升至69%至88%的水平。国内研究同样警示了这一风险,清华大学新闻与传播学院新媒体研究中心的一项评测发现,多个主流大模型的事实性幻觉率超过了19%。
更值得关注的是,AI幻觉正从一个技术缺陷,演变为一种潜在的系统性风险。今年4月初,《自然》(Nature)与《科学》(Science)等国际顶级学术期刊相继发表评论,警告大模型的“幻觉”缺陷正被有意或无意地系统性滥用。具体而言,这些工具被用于批量生成携带伪造数据、引用虚构“幽灵文献”的学术论文,这对全球科研诚信与学术生态构成了实质性的污染威胁。这提醒业界,治理模型幻觉不仅是优化用户体验的技术课题,更是关乎人工智能可信度与安全发展的关键议题。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

中芯国际封装技术最新布局与战略部署解析
5月15日,中芯国际在业绩说明会上披露了一项关键战略布局:公司自2015年起便已前瞻性地投入封装技术研发,尤其在先进封装领域进行了长期积累。经过数年的快速发展,其战略路径已非常明确——专注于为自身晶圆制造客户提供所需的关键前端封装技术支持。基于这一战略,中芯国际在过去十年间持续深耕3D CIS(CM

阿里巴巴推出AI工业知识考试系统确保回答准确性
最近,工业AI领域有一项研究值得关注。这项由阿里巴巴集团淘宝天猫多模态与工业AI团队主导的工作,已于2026年5月正式发布,论文编号为arXiv:2605 10267v2。其核心成果,是一套名为IndustryBench的专业测试系统。 不妨设想这样一个场景:你是一家工厂的采购经理,正考虑用AI来核

腾讯北大联合研发强化学习新方法提升机器人全局决策能力
强化学习是一种让智能体通过与环境交互、从试错中学习最优决策策略的人工智能技术。其核心机制类似于训练宠物:做出正确行为给予奖励,错误行为则没有。智能体在模拟或真实环境中不断尝试,根据反馈调整策略,最终找到获得最高累积回报的行动序列。然而,传统强化学习的样本效率低下是公认的难题——智能体往往需要数百万甚

香港中文大学研发频谱守护者优化器提升AI训练稳定性
训练大型语言模型,如同在云端构建一座持续生长的知识大厦。随着模型层数不断增加,任何微小的参数偏差都可能被逐层放大,最终导致训练过程失控。如何确保这座大厦在建造过程中始终保持结构稳定,一直是困扰研究人员的核心挑战。 近期,一项由香港中文大学、马克斯·普朗克智能系统研究所和西湖大学联合发布的技术报告,带

豆包服务中断原因与恢复时间详解
5月19日晚间,“豆包崩了”这一话题迅速冲上各大社交平台热搜榜首,引发广泛关注。众多用户反映,豆包AI服务突然出现中断,导致正在进行的在线学习、文案创作、代码编程等工作被迫暂停,一时间用户反馈激增。 事实上,这并非豆包首次出现服务异常问题。回顾今年1月28日,豆包就曾发生过一次影响范围较大的区域性服








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
