




Claude防话痨插件爆火 网友受够AI废话直呼实用

最近,Hacker News社区被一个叫“ca veman”(xue居人)的Claude Code插件给刷屏了。这事儿挺有意思,一个看似简单的工具,短短半天内GitHub star数就从几十飙升至500,如今已经冲破了2万大关。 先看这张图,感受一下它的热度曲线。 从增长轨迹来看,项目“Julius
最近,Hacker News社区被一个叫“ca veman”(xue居人)的Claude Code插件给刷屏了。这事儿挺有意思,一个看似简单的工具,短短半天内GitHub star数就从几十飙升至500,如今已经冲破了2万大关。
先看这张图,感受一下它的热度曲线。
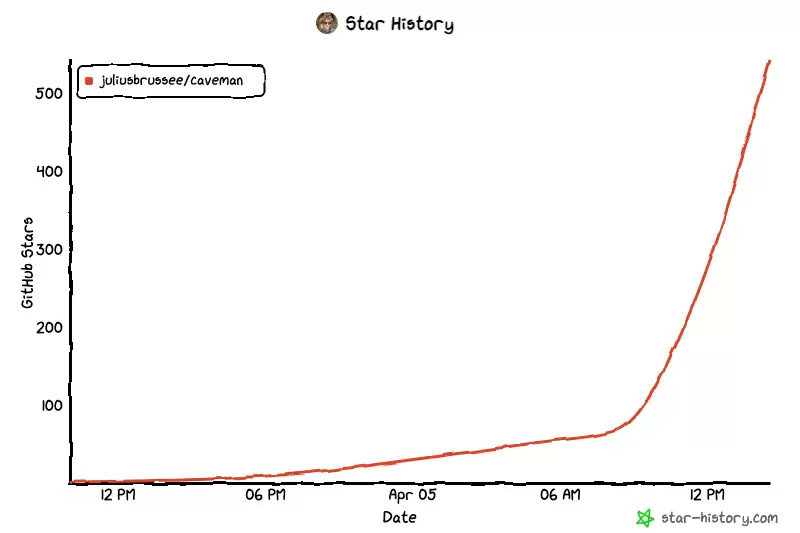
从增长轨迹来看,项目“JuliusBrussee/ca veman”在初期经历了一段漫长的平缓期,随后便迎来了近乎垂直的爆发。这张更详细的图表清晰地记录了它从默默无闻到一夜爆红的全过程。

一个宣称能“省Token”的插件能如此火爆,背后反映的其实是一种广泛的社区情绪共鸣。它精准地戳中了一个让无数开发者早已不堪其扰的痛点——“AI废话(AI Yap)”。
很快,就有网友将其誉为“2026年最厉害的提示词技巧”,因为它能砍掉那些浪费在“我很乐意帮你”这类客套话和冗长铺垫上的token。
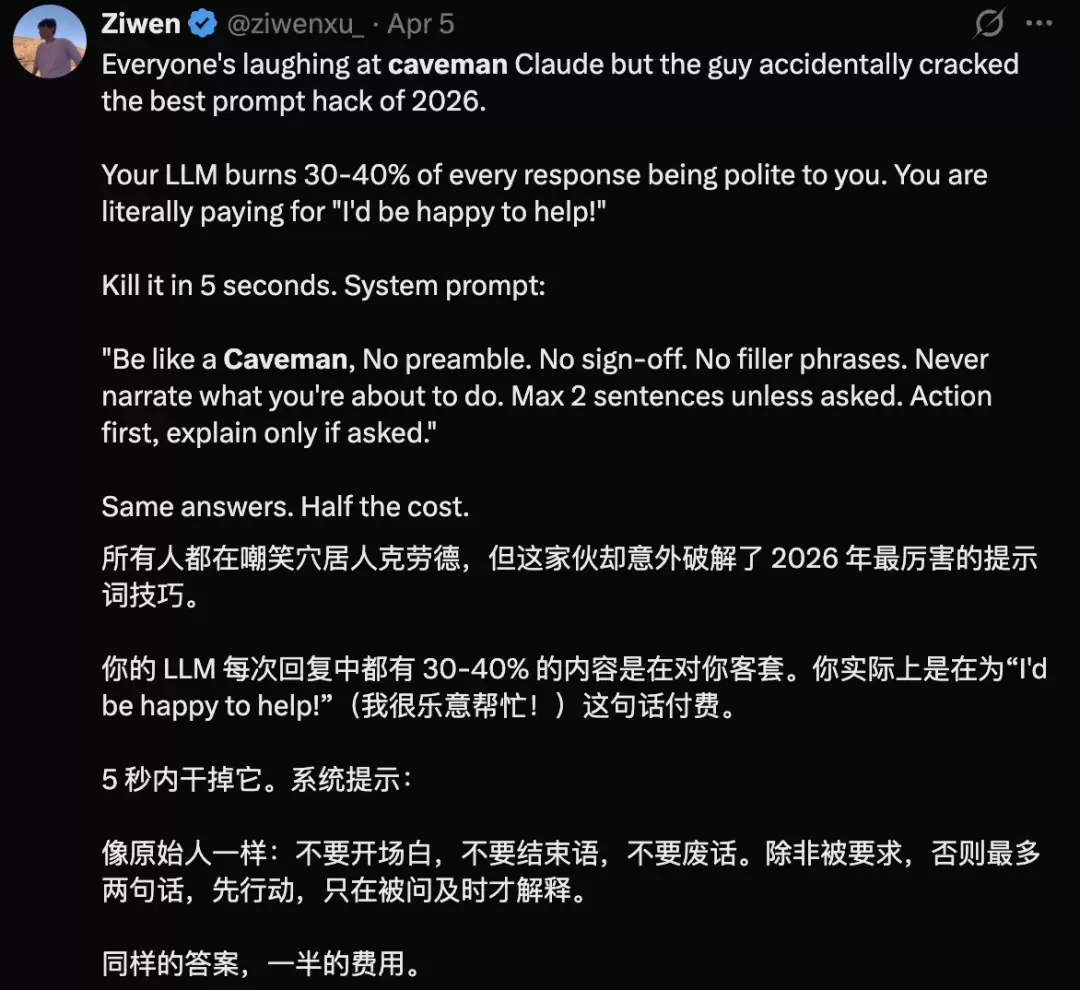
那么,这个插件究竟做了什么?它的核心理念简单到有些粗暴:让AI智能体像原始xue居人一样说话。

具体来说,就是删掉“the”、“please”、“thank you”这些不影响技术含义、却不断吞噬token的“人类客套语”。

项目出自开发者Julius Brussee之手。他在项目README里抛出的问题非常直接:为什么能用少量token说清楚的事,非要动用那么多token?
这是一款同时适配“Claude Code”和“Codex”的技能插件。其核心思路是在不牺牲技术准确性的前提下,将输出压缩到极致,声称可将token消耗降低约75%。

但问题也随之而来:仅仅删掉冠词和礼貌用语,真能为用户省下四分之三的成本吗?
扒开SKILL.md:网友傻眼,就这?
ca veman到底是怎么“省”的?打开它的核心文件SKILL.md,内容确实不长。
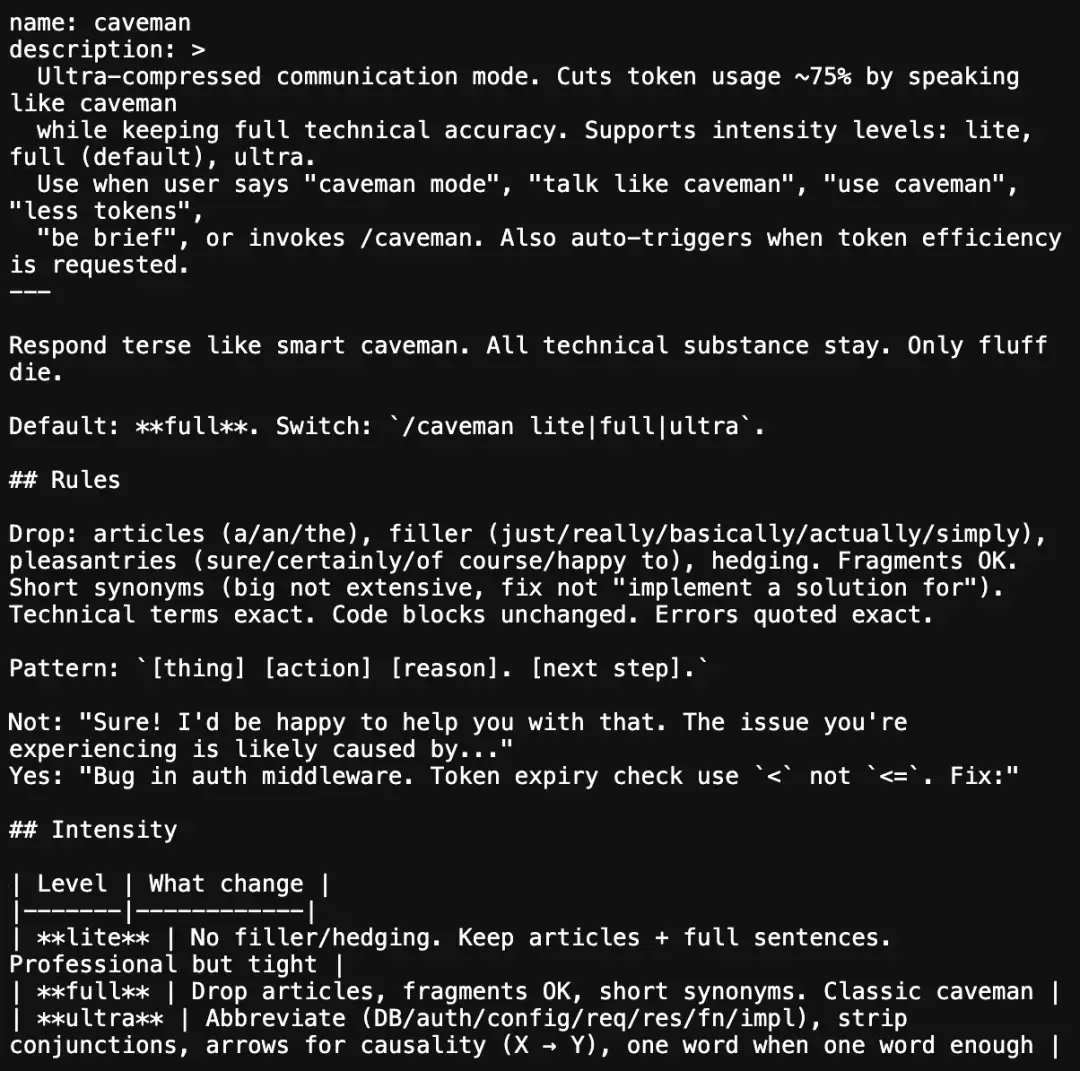
文件的frontmatter直接将其定义为“超压缩通信模式”,并写明目标是通过像xue居人一样说话来降低token用量。当用户说出“ca veman mode”、“talk like ca veman”等关键词或调用“/ca veman”命令时,该模式便会启用。
其节省token的规则简单粗暴:不用冠词,不说废话,别客气;技术术语和代码块保留,其他能砍就砍。具体包括:删除冠词、语气填充词、客套话、犹豫性表达;允许使用短句和碎片句;优先使用更短的同义词;技术术语必须精确;代码块和报错信息原样保留。
它推荐使用“[问题][动作][原因]。[下一步]。”这样的句式。例如,不要写:“当然!我很乐意帮你。你遇到的问题,很可能是由……引起的……”,而要写成:“Bug在认证中间件。Token过期判断用了<,没用<=。改这里:”
插件支持三档强度:lite、full(默认)和ultra。lite档仅去掉填充词,保留完整句子;full档进一步压缩,允许碎片句;ultra档则大量使用缩写,并尽量去掉连接词。
当然,遇到安全警告、不可逆操作确认或多步骤流程时,清晰表达仍然优先。这也是SKILL.md里明确写出的例外逻辑。
说到底,ca veman没有改动任何模型架构或推理机制,它的本质就是一条精心编写的system prompt,用于约束AI的输出风格。更关键的一点是,作者本人在Hacker News的讨论帖中主动澄清,这个技能不针对hidden reasoning tokens和thinking tokens。

这意味着,模型在后台“思考”的过程并不会因此变短,它主要压缩的是最终说出来的那部分。此外,Anthropic的最新文档提到,技能的名称和描述本身就会占用上下文预算。换句话说,加载ca veman这个技能本身就要消耗token。因此,端到端的真实成本节省,很可能达不到README里那个醒目的“75%”。
README里的75%,到底靠不靠谱?
从仓库公开内容看,作者确实提供了基准测试脚本,并在README里列出了多项任务的token对比数据,节省区间从22%到87%不等,平均约为65%。

但作者在HN帖子中也表示,这只是初步测试,并非严格的基准测试。不过,“简洁表达是否会伤害AI性能”这个问题,学术界确实已有相关研究。

例如,2024年的论文《The Benefits of a Concise Chain of Thought on Problem-Solving in Large Language Models》指出,当要求模型使用更简洁的推理链时,GPT-3.5和GPT-4的平均回答长度下降了48.70%,而整体解题能力未受明显影响,尽管GPT-3.5在数学题上的表现平均下降了27.69%。
2026年的论文《Brevity Constraints Reverse Performance Hierarchies in Language Models》则进一步发现,在部分基准测试中,对大模型施加简洁约束,其准确率可提升26个百分点,甚至可能改变不同规模模型之间原本的性能排序。

这些研究为“简洁未必伤性能”提供了理论背景。但必须说清楚,它们研究的是“简洁”作为通用提示策略的效果,并非对ca veman这个具体项目的专项评测。README引用这些研究,最多只能说明其思路有据可循,不能直接当作项目自身效果的严格验证。
Claude Code的插件生态开始起来了
ca veman能火,还有一个重要的背景原因:Anthropic已经为Claude Code提供了相对完整的技能与插件机制。

根据官方文档,开发者只需创建一个SKILL.md文件,Claude就能将其识别为技能。其中,description字段决定何时自动加载,name字段则会变成可直接触发的斜杠命令。

文档还明确了插件级技能的路径结构。而在ca veman仓库中,确实能看到.claude-plugin、plugins/ca veman、skills/ca veman等目录,这说明它并非一个停留在“几句提示词”层面的玩具,而是按照Claude Code的官方机制包装出来的正式扩展。
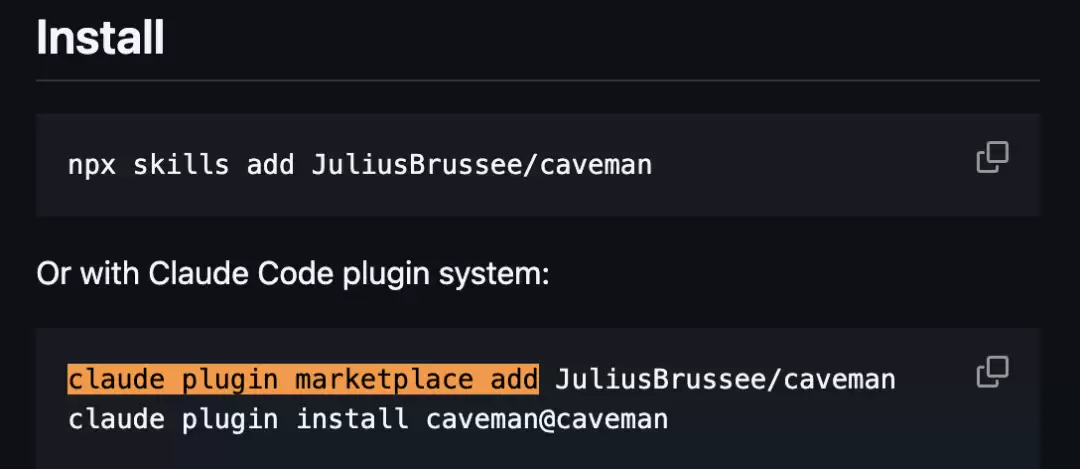
这意味着,开发者确实可以通过一个SKILL.md文件,在不改动模型底层的前提下,改变Claude Code在特定任务中的调用方式和输出风格。这有点像早期VS Code扩展生态的雏形:先有一批轻量甚至带点玩笑性质的扩展冒出来,随后才逐渐演化出更严肃、更细分的工作流工具。
开发者苦AI废话久矣
回到最初的问题:ca veman到底有没有用?如果把它当成一个严格意义上的“省钱工具”,那需要保持谨慎。它压缩的只是可见的输出文本,并不触及hidden reasoning tokens,而后者往往才是Claude Code成本的大头。再加上技能本身也会占用上下文,端到端算下来,真实节省大概率到不了75%。真正想优化token成本,关键战场在于模型分层调用、上下文窗口管理、提示词工程和缓存策略。
但ca veman真正值得关注的地方,不在于它是否提供了完美解决方案,而在于它本身就是一个强烈的信号。当一个开发者把“让AI少说废话”这件事做成插件,放到GitHub上,被上千人认真讨论并在HN爆火,事情的重点就已经变了。它说明,AI工具的冗长,不再是一个可以忍受的小毛病,而是严重到用户开始自己动手修正的程度。
实际上,开发者们的情绪早已“破防”。去各大社区看看,满屏都是对AI废话的哀叹:“我只需要两行正则代码,它非要给我写5个自然段的正则历史散文”;“求求你别再对我说‘Certainly! Here is the…’了,直接给我报错或者代码不行吗?”。在Hacker News上,这种抱怨更是直接与使用成本挂钩:“我简直是在花15刀/100万Token的价钱,来阅读AI对我的道歉和寒暄。”“只因为要改一个标点,它竟然把整个800行的文件重新输出了一遍,看着API余额肉眼可见地往下掉,我都快破产了。”
当大家宁愿让AI像“山顶洞人”一样说话,也不愿继续为冗余输出付费时,真正应当反思的或许是那些主流AI厂商。为什么直到今天,他们还没有把“输出克制”做成一种基础能力?是时候别总盯着算力生意,认真想想用户到底为什么越来越受不了这些没必要的输出了。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Claude防话痨插件爆火 网友受够AI废话直呼实用要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点UltimateToolbarGPT是一款强大的聊天助手工具栏,内置300种提示组合,支持语音输入与实时转录,并能将对话结果直接导出为Word或PDF格式,有效提升ChatGPT等聊天助手的输入、对话和输出效率。
一个集成GPT-4、Grok、Gemini等多种AI模型的内容生成平台,支持博客、广告文案、社交媒体贴文等类型创作。内置AI检测绕过和内容人性化功能,减少机器感。同时具备AI图像生成能力,并可灵活切换后端模型,形成写作、配图、规避查重的完整工作流,提升内容产出效率。
在内容创作领域,时间就是金钱,效率决定成败。如果有一款AI文案生成工具能让你从繁琐的撰写中解放出来,快速产出高质量内容,你愿不愿意试试?今天要介绍的,就是这样一个智能写作助手——Lek AI。 什么是Lek AI? 简单来说,Lek AI 是一款完全由人工智能驱动的文案创作工具,它的目标非常明确——
一款将图像转换为详细文本描述的AI工具,支持PNG、JPG、JPEG、GIF格式(6MB以内),通过拖拽或点击上传,几秒内生成自然流畅的描述。适用于SEO优化、内容创作、提升图片可访问性,辅助视障用户理解图像,也可用于社交媒体配文和文档插图说明。
- 日榜
- 周榜
- 月榜
热点快看