




π0.7发布开启VLA新阶段机器人迎来GPT-3时刻

今天凌晨,机器人领域传来一声惊雷。由Physical Intelligence公司发布的全新VLA模型π0 7,以一种意想不到的方式,为“世界模型”的叙事敲下了一记重锤。 它的突破点在于,首次在机器人领域实证了组合泛化能力。简单来说,当面对一个全新任务时,这个模型能够像搭积木一样,组合运用过去学过的
今天凌晨,机器人领域传来一声惊雷。由Physical Intelligence公司发布的全新VLA模型π0.7,以一种意想不到的方式,为“世界模型”的叙事敲下了一记重锤。
它的突破点在于,首次在机器人领域实证了组合泛化能力。简单来说,当面对一个全新任务时,这个模型能够像搭积木一样,组合运用过去学过的原子技能,自己“琢磨”出解决方案。

这好比一位篮球运动员,只学过跳投和后仰,但在实战中面对新的防守姿态时,却能自发地组合出“后仰跳投”这一招。没人专门教过,但他就是会了。
演示视频中最令人印象深刻的有两点:
任务泛化:机器人从未见过空气炸锅,却能根据指令,组合机械臂动作,成功烤出红薯。
本体泛化:将从一台机械臂上学到的抓取策略,直接部署到另一台结构不同的机械臂上。
更有趣的是,连Physical Intelligence的研究员自己也坦言,他们尚未完全摸清π0.7的能力边界。模型展现出的潜力仍在探索中,效果相当令人惊喜——切黄瓜、削皮、倒垃圾、烤红薯,样样都能上手。
研究员Ashwin Balakrishna感慨道:“过去我总能根据训练数据猜出模型能做什么。但这一次,我猜不到了。”
π0.7:具有涌现能力的可控模型
π0.7的核心洞见可以浓缩为一句话:多样化的数据需要多样化的指令描述。 但这句话带来的连锁反应,远比字面意义深远。
用多样化的指令,消化多样化的数据
传统的VLA训练方式相对粗放。例如,只给模型一句“清理冰箱”的指令,模型接收到的信号是单一且模糊的。π0.7则把指令展开为四个层次:

包括总任务指令(如“清理厨房”)、子任务指令(如“打开冰箱”)、子目标图像(展示下一秒的理想画面),以及数据元信息(标记这条数据的质量、有无错误、执行速度等)。
有了这些丰富的上下文信息,模型就能分辨训练数据中的优劣、快慢、对错。于是,以往难以利用的数据——失败的尝试、低质量的演示、其他机器人的片段,甚至人类的第一视角视频——都变成了有价值的训练信号。
问题的关键从来不是数据本身是否杂乱,而在于模型是否“理解”它正在学习什么。π0.7增加的这层指令,正是为了让模型明确知道“这段数据质量如何,采用了什么策略”。
正是这一改变,催生了具身智能领域一个历史性时刻:通才模型首次追平了专才模型。
通才追平专才
Physical Intelligence联合创始人Chelsea Finn提到了一个有趣的对比。在大语言模型领域,“后训练”通常指针对下游任务进行微调。机器人领域也长期卡在这一步:想要极致性能,就必须为特定任务进行精细微调。
π0.7打破了这一范式:它开箱即用,并且在某些任务上超越了经过微调的专家模型。
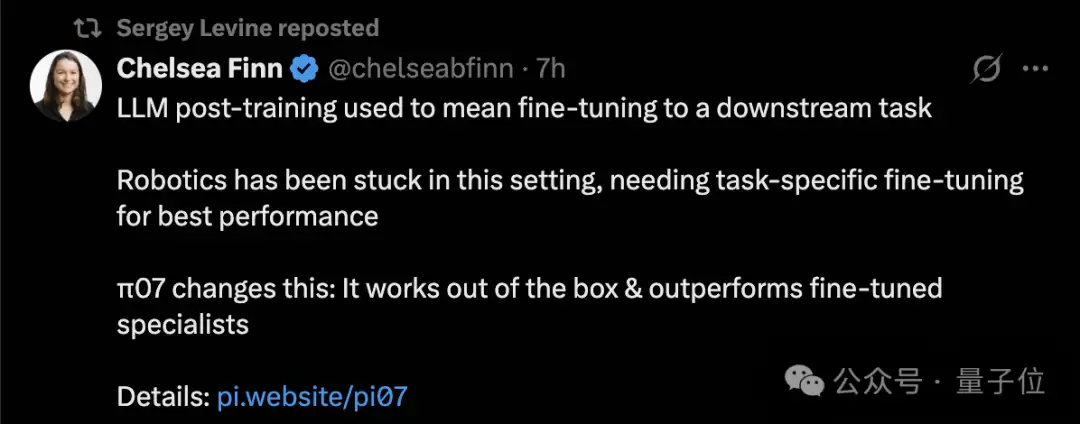
数据是最有力的证明。未经任何专项训练的π0.7,在制作咖啡、叠衣服、物品装箱这三个复杂任务上,其表现已经追平了经过微调的π0.6专家模型。
这里的专家模型分为两种:一种是基于π0.6、使用RECAP方法针对特定任务(咖啡、装箱、叠衣服)单独训练的强化学习专家;另一种是基于π0.6、针对每个任务单独进行监督微调的专家。
更令人惊讶的是,在叠衣服和装箱这两个公认的高难度任务上,π0.7在单位时间内完成任务的次数甚至超过了强化学习专家。这意味着,一个未经专门训练的通才,在某些维度上战胜了为特定任务而生的专才。这正是PI团队一直坚信并努力的方向。
组合泛化开始涌现
π0.7展现的涌现能力主要体现在四个方面:
开箱即用的灵巧操作:制作咖啡、叠衣服、剥蔬菜、削西葫芦、更换垃圾袋等任务,均无需额外专项训练。
指令泛化:在4个未见过的厨房和2个未见过的卧室环境中,能够遵循3到6步的开放式指令工作。它甚至能理解“拿起那个最大盘子里的水果”、“拿起我用来喝汤的那个东西”这类涉及复杂空间和语义指代的指令。
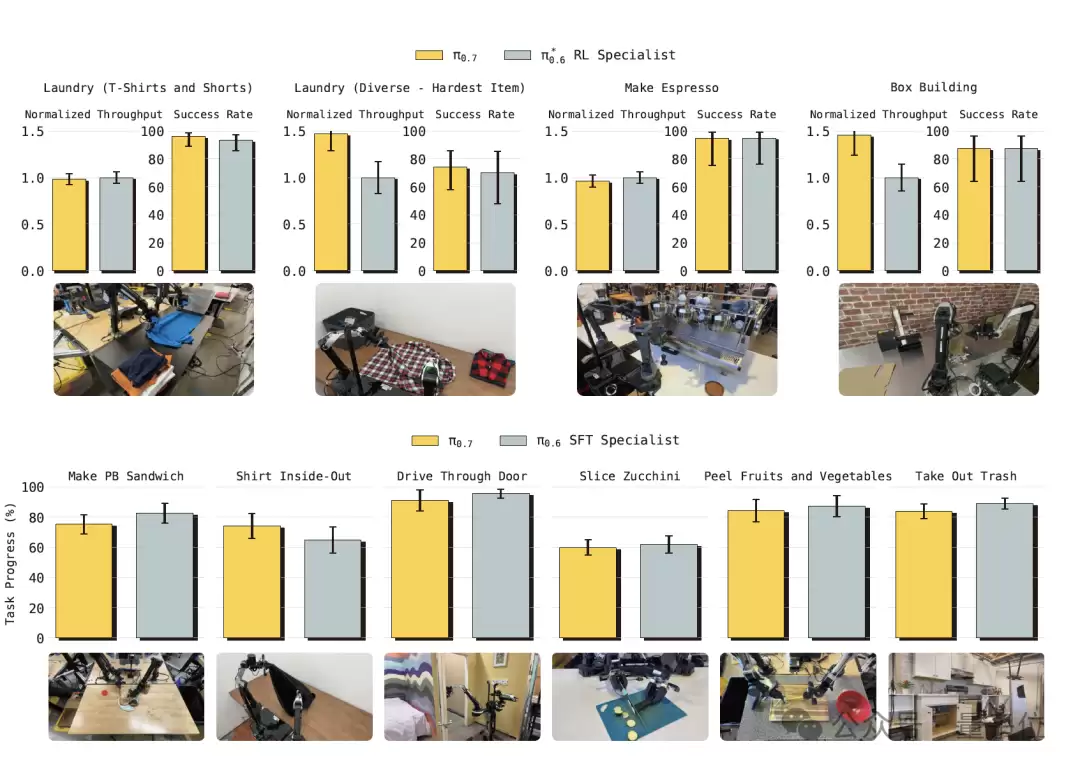
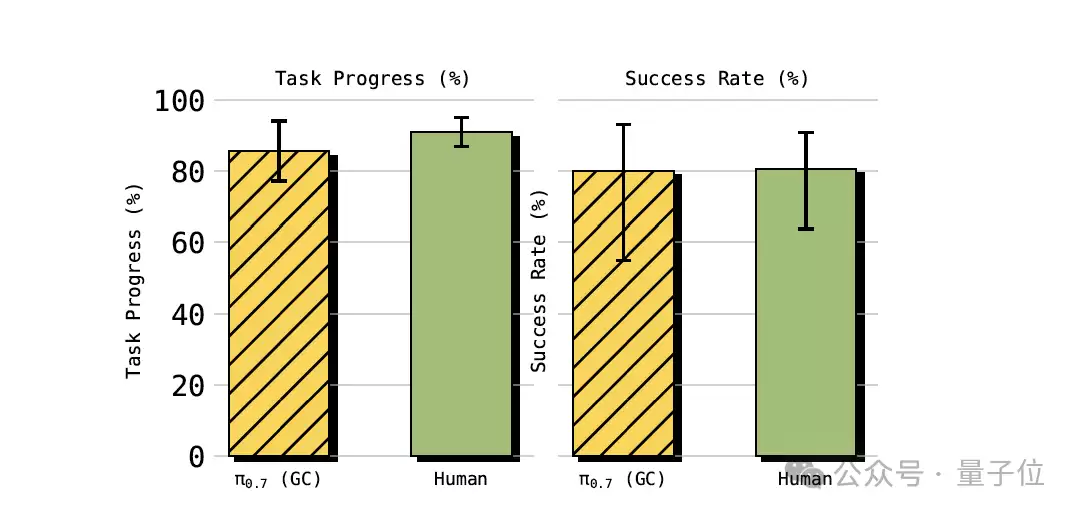
跨本体泛化:以叠T恤任务为例,训练数据中完全没有UR5e机械臂叠衣服的样本。然而π0.7不仅做到了,其任务完成度达到85.6%,与10位平均拥有375小时遥操作经验的顶级人类操作员90.9%的完成度基本持平。
更有意思的是,π0.7自己琢磨出了一套与源机器人完全不同的抓取策略。人类操作员在源机器人上采用倾斜夹爪贴住桌面抓取,而π0.7在UR5e上则采用了垂直抓取,因为这更适合UR5e更长的手臂运动学结构。
组合任务泛化:这是最核心的突破。诸如用空气炸锅烤红薯和贝果、按下特定按钮、用抹布擦拭耳机和尺子、拧动旋钮和桌面风扇等任务,在训练数据中一条都没有出现过。

这不再是简单增加任务数量的量变,而是标志着机器人首次像大语言模型那样,从训练数据中涌现出全新的、未经教授的能力。 正如Sergey Levine所言:一旦模型越过那个临界阈值,从“只能做收集过数据的事”转变为“开始重组出新事”,其能力将随数据量超线性增长。
数据过滤可能是个伪问题
论文中隐藏着一个极具碘伏性的实验。
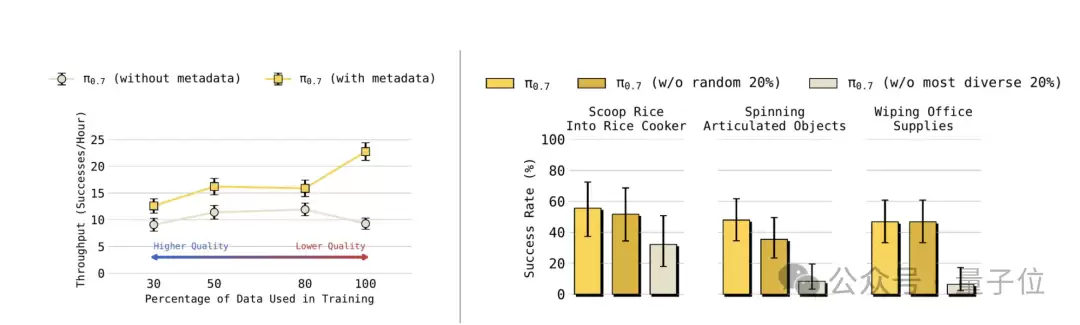
研究团队将叠衣服的数据按质量分为四档:前30%、前50%、前80%以及全部数据。然后分别训练两个版本的π0.7:一个版本为每条数据添加元信息标签(标明质量分数、有无错误、完成速度),另一个版本则不添加。
结果耐人寻味。
对于不添加元信息的版本,数据越多,性能反而越差——因为低质量数据混入后干扰了模型学习。
对于添加了元信息的版本,数据越多,性能越好——即使数据的平均质量在下降。
这一发现暗示,整个具身智能领域过去几年投入巨大精力的“数据清洗”工作,可能正在变成一个伪命题。
关键在于让模型“知情”。只要模型知道每条数据的质量标签,它就能自主决定学习什么、忽略什么。 所谓的“垃圾数据”不再是垃圾,而是带着“质量=1/5”标签的有用信号;失败数据也不再是需要丢弃的废料,而是告诉模型“此路不通”的反面教材。
过去,研究者们小心翼翼地筛选演示、删除失败、清洗数据。π0.7的思路则是:别洗了,直接告诉模型哪些是“脏”的就行。
π0.7是怎么做到的?
π0.7是一个拥有50亿参数的三模块模型。
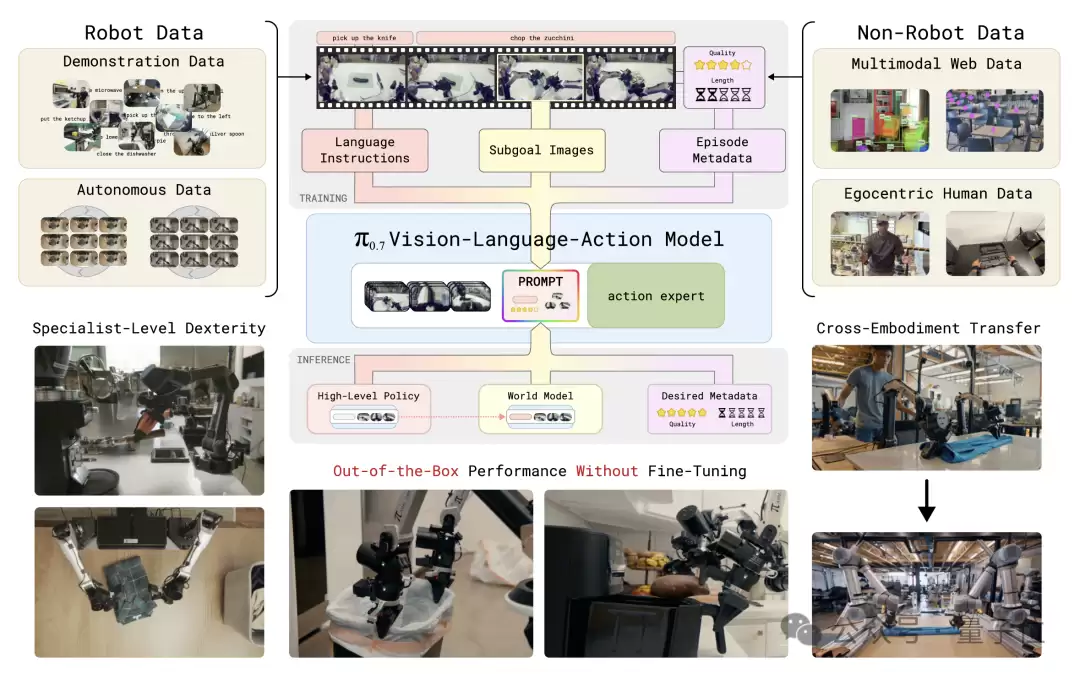
- 视觉语言模型骨干:采用40亿参数的Gemma3,负责理解视觉和语言信息。
- 动作专家模块:8.6亿参数的Transformer,使用流匹配技术生成连续的动作块,实现50Hz的高频控制。
- 世界模型模块:从140亿参数的BAGEL图像生成模型初始化,负责为π0.7描绘未来几秒的理想画面应该是什么样子。
在推理时,模型输入包括:4路摄像头画面(前视+两个腕部+可选后视)、每路6帧历史图像、机器人关节状态,再加上任务指令、子任务指令、元数据,以及世界模型实时生成的子目标图像。
输出则是一段50步的动作块,实际执行15到25步后,模型会重新推理生成下一段动作。
说到这里,或许会产生一个疑问:π0.7内置了一个世界模型,这是否意味着它与“世界模型”流派融合了?
答案是:半是,半不是。
世界模型流派的核心是让模型学会模拟物理演化:给定一个动作,预测世界状态将如何变化。策略网络基于这个预测来做决策。
π0.7中的世界模型不干这件事。它只负责一项任务:将任务指令“翻译”成成功那一刻应该呈现的画面。 它不预测动作后果,不模拟物理规律,也不参与决策链路。它本质上是一个“消歧器”,而非“规划器”。它借用了世界模型派的工具,却干了一件并非该流派初衷的事。
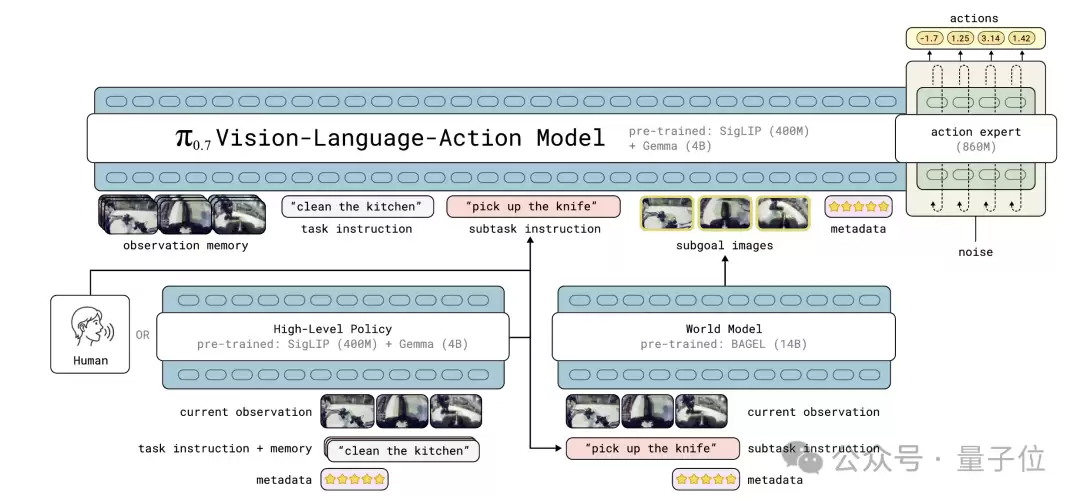
此外,π0.7还站在前人的肩膀上,继承了π0.6的架构基础,以及MEM模型的多尺度记忆编码器(结合短期视频记忆与长期语义记忆)。
在训练方法上,它采用了知识隔离技术——视觉语言模型骨干使用FAST token进行下一个token预测训练,而动作专家模块的梯度不会回传到视觉语言模型。这样,视觉语言模型从互联网海量数据中学到的语义知识得到了保护,不会被机器人动作数据所污染。
但必须指出,架构并非π0.7最重要的贡献。正如论文中所强调的:“我们的贡献不在于提出新的架构或模型设计,而在于提出了一套能让VLA模型利用更多样化数据源的方法论。”
VLM可以直接控制机器人,不需要先学会想象世界
在π0.7之前,具身智能领域最受瞩目的无疑是英伟达去年凭借Cosmos模型掀起的世界模型风潮。其核心理念是:让机器人先学会想象未来,再去操作现在。
这条路线看起来非常符合直觉,人类不正是这样规划行动的吗?闭上眼睛想象一下要做什么,然后再动手。
从2025年至今,这条路线吸引了最多的关注和资源投入。
然而今天,风向似乎又要变了——VLA路线强势回归!
而说到VLA,恐怕没人比Physical Intelligence的团队更懂。早在2023年,PI的联合创始人Karol Hausman、Sergey Levine和Chelsea Finn在谷歌研发RT-2时,就押注了一个判断:视觉语言模型可以直接控制机器人,无需先学会想象世界。
这意味着,你不需要让模型先学会预测下一帧画面、脑补物理规律、或建立一个内部的世界模拟器。你只需要将一个已经见识过互联网的视觉语言模型,连接上一个动作输出头,进行端到端训练,就足够了。
从RT-2到π0.7,VLA架构其实只演进了两代。
第一代是RT-2,它将机器人动作离散化为token,塞进视觉语言模型的下一个token预测框架中。这种方法能让机器人动起来,但控制精度不高,且自回归预测生成速度慢,难以满足50Hz的高频连续控制需求。
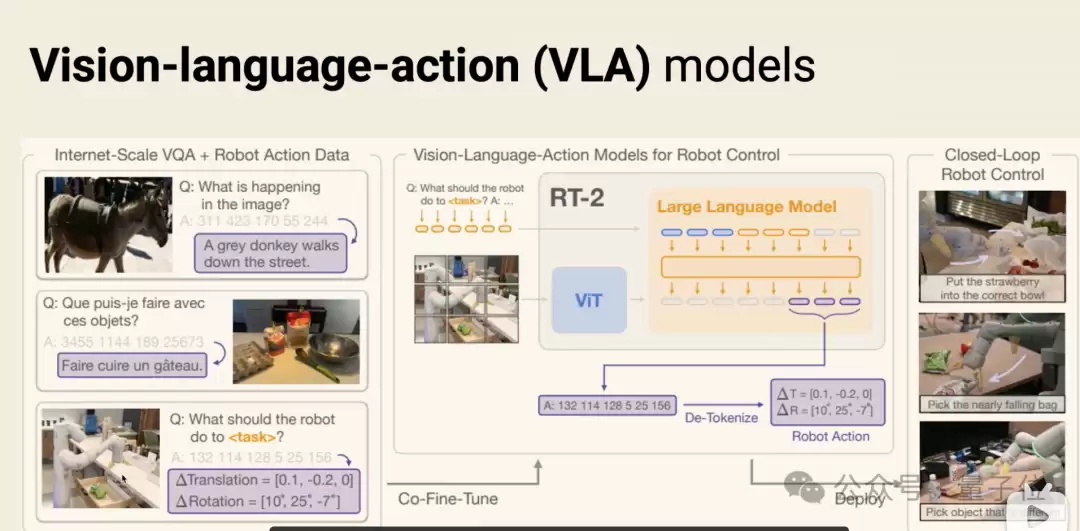
第二代则由π0系列开启,它为视觉语言模型连接了一个专门的“动作专家”模块,使用流匹配技术直接生成连续的动作块。
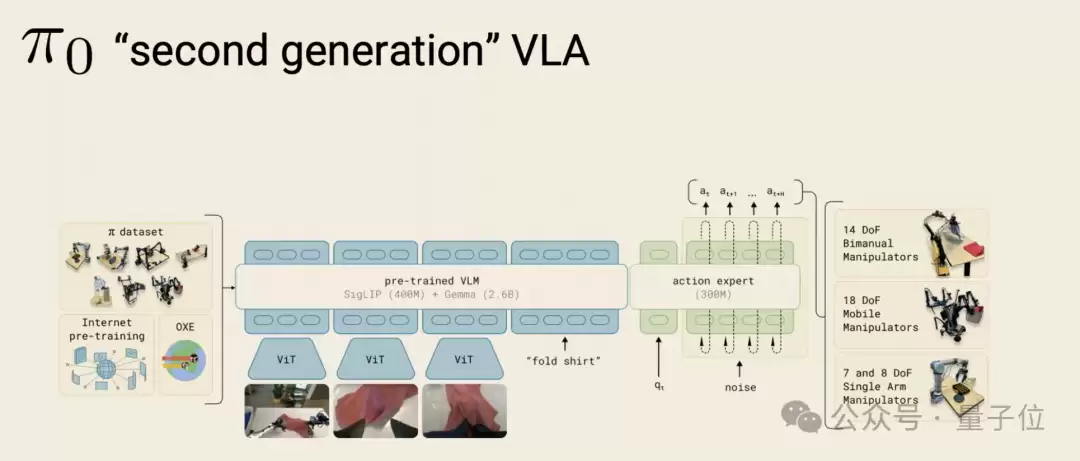
此后的诸多模型改进——π0.5的开放世界泛化、π0.6的强化学习自我练习、MEM的多尺度记忆——都未曾改动这个基础架构。它们都是在“视觉语言模型 + 动作专家 + 流匹配”这个核心结构上叠加新的能力。
π0.7也是如此。在架构层面,它与π0.6并无本质区别。它真正的增量在于“指令的多样性”。这也呼应了论文的观点:贡献不在于架构。
然而,这个故事里还有一个更耐人寻味的角色。
Lucy Shi,斯坦福大学在读博士生,师从Chelsea Finn,也是π0.7的核心作者之一。

她在社交媒体上分享了一个非常坦诚的故事。
此前,她曾跟随朱玉可、Jim Fan在英伟达从事世界模型的研究。

当时她押注的方向与Karol等人相反——她坚信世界模型才是关键钥匙,将在任务泛化上显著超越标准的VLA方法。
起初,实验结果似乎支持这个假设。她获得了令人惊艳的组合泛化效果,机器人能够遵循未见过的指令,完成训练数据中不存在的任务,并能从其他机器人和人类视频中迁移技能。
但一件奇怪的事情发生了。他们用作对比的VLA基线模型,性能一直在持续增强。
随着收集的数据越来越多,VLA基线变得越来越强,直到某一天,这个基线模型也开始展现出组合泛化的迹象。而且,VLA的方法要简单得多。
面对这一情况,Lucy感到一种无奈的幽默:“当你的基线模型‘吞噬’了你的研究假设时,你该怎么办?你只能写一篇论文,去搞清楚这个基线为什么这么强。”
那篇论文,就是π0.7。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:π0.7发布开启VLA新阶段机器人迎来GPT-3时刻要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点硕一最新推出的鲲鹏CL6N风冷散热器采用了双塔双风扇搭配六热管直触的设计,解热能力标称为260W。其最大特色是附带一块磁吸式数显屏幕,可实时显示CPU或显卡温度以及风扇转速,提升了使用的便捷性和视觉体验。产品兼容英特尔LGA1700 1851和AMDAM4 AM5等主流平台,提供了黑色无光、黑色
据最新小鹏汽车已组建团队正式进军游艇制造领域,项目内部代号“飞鱼”。该项目由整车架构负责人钱占伟负责,核心研发方向聚焦于底盘算法,旨在将智能电动汽车的技术积累应用于水上交通工具,目标客户为高净值家庭。目前项目仍处于研发阶段。此前,已有包括梅赛德斯-AMG、兰博基尼在内的多家豪华汽车品牌跨界涉足
丰田汽车副社长近日透露,其下一代电动汽车核心技术,包括大压铸工艺、新型电池和自走式组装线,在品质与成本上均已达到量产水平。尽管原计划承载这些技术的雷克萨斯LF-ZC概念车已中止量产开发,但公司已正式决定开发后继车型,并将所有核心技术平移至新项目。此举表明丰田的电动化技术研发并未放缓,而是以更灵活的方
微信鸿蒙原生应用的内测招募再次启动,此次测试规模显著扩大。此前因鸿蒙应用商店对单一软件的测试用户数量设限,内测资格较为有限。经过开发团队与平台方的沟通,测试用户上限得以提升,从而开启了新一轮的公开招募。参与报名的用户需填写华为账号、机型等信息,审核通过后将获得内测资格。官方鼓励获得资格的用户积极体验
- 日榜
- 周榜
- 月榜
热点快看