




PMDformer长时序预测新方法用减法优化注意力机制解决尺度偏差

在能源管理、金融市场分析和交通流量预测这些领域,长期时间序列预测(LTSF)一直是个核心且棘手的任务。现有的方法,尤其是基于Patch的Transformer模型,虽然试图通过捕捉局部语义来理解长序列,却普遍面临一个根本性的瓶颈:非平稳数据中,不同时间片段(Patch)的数值尺度差异,会严重干扰模型
在能源管理、金融市场分析和交通流量预测这些领域,长期时间序列预测(LTSF)一直是个核心且棘手的任务。现有的方法,尤其是基于Patch的Transformer模型,虽然试图通过捕捉局部语义来理解长序列,却普遍面临一个根本性的瓶颈:非平稳数据中,不同时间片段(Patch)的数值尺度差异,会严重干扰模型对真实模式的判断。
简单来说,当模型试图通过“注意力”机制寻找相似模式时,它很容易被数值大小所迷惑,误将形状迥异但尺度相近的片段关联起来,而忽略了那些真正形状相似、只是处于不同数值水平的片段。这就像戴着有色眼镜看数据,看到的并非全貌。
针对这一痛点,来自西南财经大学、上海科学智能研究院、复旦大学和成都恒图科技的联合研究团队,提出了一种名为PMDformer的创新框架。其核心思路相当巧妙:将每个数据片段(Patch)的“均值”(代表长期趋势)和“残差”(代表局部形状)进行解耦,让模型能更纯粹地关注形状相似性。实验证明,这一方法在多项权威基准测试中,性能全面超越了现有最优模型。

目前,这项研究成果已被顶级学术会议ICLR 2026接收。
现有方法的痛点:尺度差异如何「扭曲」形状建模?
为了处理长序列,将数据切割成小块(Patch)进行分析是常见策略。但问题在于,现实世界的时间序列数据往往是非平稳的——今天的用电量和一年前的用电量,数值水平可能天差地别。这种尺度差异带来了两个关键挑战:
首先,是尺度偏差对形状相似性的遮蔽。注意力机制的计算会受到Patch均值的影响,导致形状高度相似但尺度不同的两个Patch被判定为不相关;相反,形状迥异但恰好处在相似数值区间的Patch,反而可能获得高注意力权重。模型捕捉到的可能只是由数值尺度制造的“幻觉”,而非真正的时序模式。
其次,是跨变量依赖建模的失准。在多变量预测中,不同变量(比如温度与湿度)之间的相关性并非一成不变。早期历史上的弱相关甚至虚假相关关系,如果被不加区分地用于预测近期走势,就会引入大量噪声,导致模型过拟合到无用的信息上。
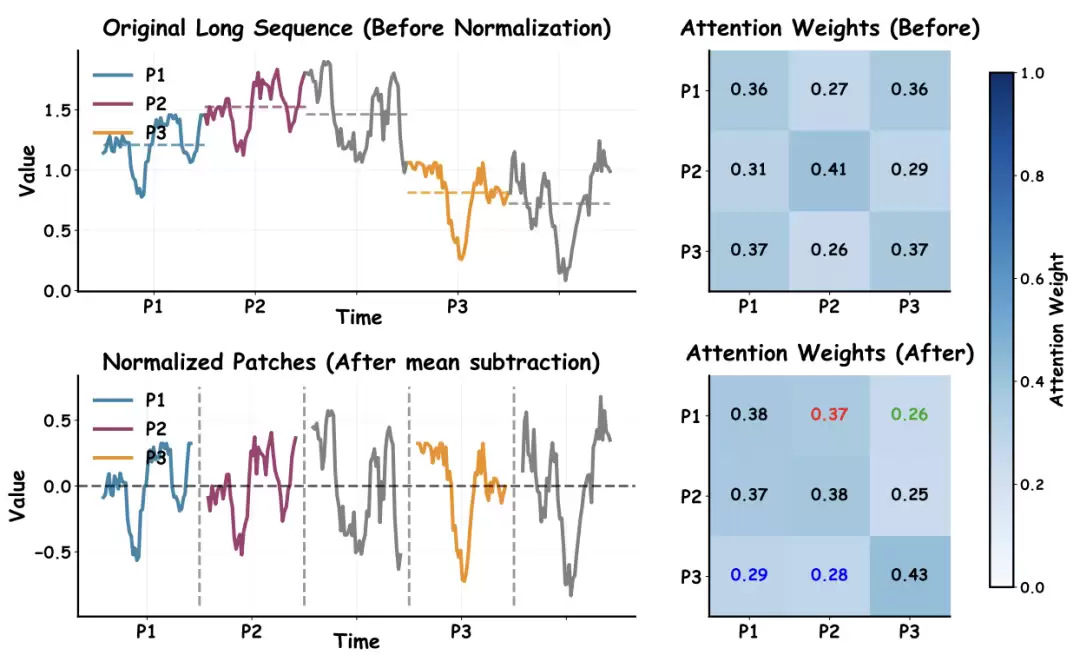
图1:PMD解耦前后的注意力权重对比。上图显示,在原始序列中,由于尺度差异,注意力错误地偏向了P3;下图显示,经过均值解耦后,注意力权重正确反映了P1与P2之间的形状相似性。
PMDformer:三位一体的解决方案
PMDformer的巧妙之处在于,它通过三个协同工作的核心模块,系统性地解决了上述问题,形成了一个完整的技术闭环。
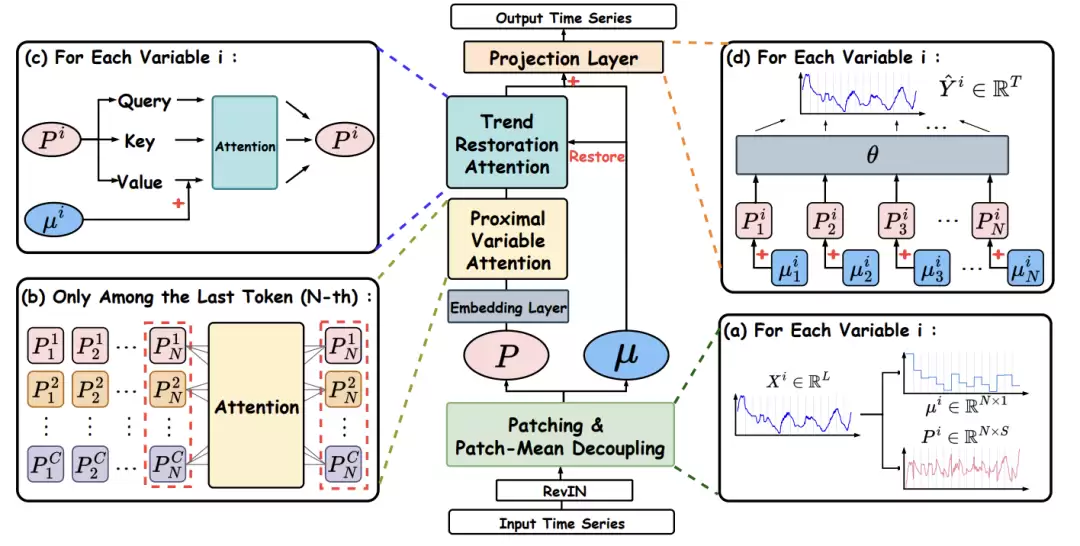
图2:PMDformer整体架构图
一、Patch均值解耦(PMD):还原形状本质
这是整个框架的基石。其操作非常简洁:对每个Patch,简单地减去其时间维度上的均值。这样一来,原始Patch就被分解为两部分:代表长期趋势的“均值”,和代表局部波动“形状”的残差。与普通的归一化方法不同,PMD只做减法,完整保留了Patch内部的振幅变化和细节结构,让模型能专注于形状本身的相似性比较。
二、近邻变量注意力(PVA):聚焦最相关的跨变量依赖
这个模块基于一个非常直观的洞察:当我们要预测未来时,最近期的历史信息通常最具参考价值。因此,PVA模块在计算不同变量之间的注意力时,不再“翻旧账”式地扫描整个历史窗口,而是将计算严格限制在最近的一个Patch上。
这样做的好处是双重的:一方面,它能精准捕捉对预测最有价值的近期跨变量交互模式,避免被早期不相关的噪声干扰;另一方面,它将计算复杂度从O(C²N)大幅降低到了O(C²),其中C是变量数,N是Patch长度,在处理高维数据时效率提升尤为显著。
三、趋势恢复注意力(TRA):兼顾形状与趋势
PMD模块虽然强化了形状建模,但客观上削弱了长期趋势信息。TRA模块就是为了弥补这一点而设计的。它采用了一种“分离式”的注意力设计:在计算注意力权重(Query/Key)时,只使用代表形状的残差嵌入,确保分数纯粹反映形状相似性;而在生成最终输出(Value)时,则通过加法将之前分离出的Patch均值(趋势信息)重新注入。这样,模型就能同时把握局部的形状模式和全局的趋势动向,做出更稳健的预测。
实验结果:在8个权威基准上全面领先
研究团队在电力、天气、能源、交通等领域的8个广泛使用的真实数据集上进行了系统评估。与8种最新的基线方法对比,PMDformer在7个数据集上的均方误差(MSE)和平均绝对误差(MAE)都达到了最低,展现了其稳定且全面的性能优势。
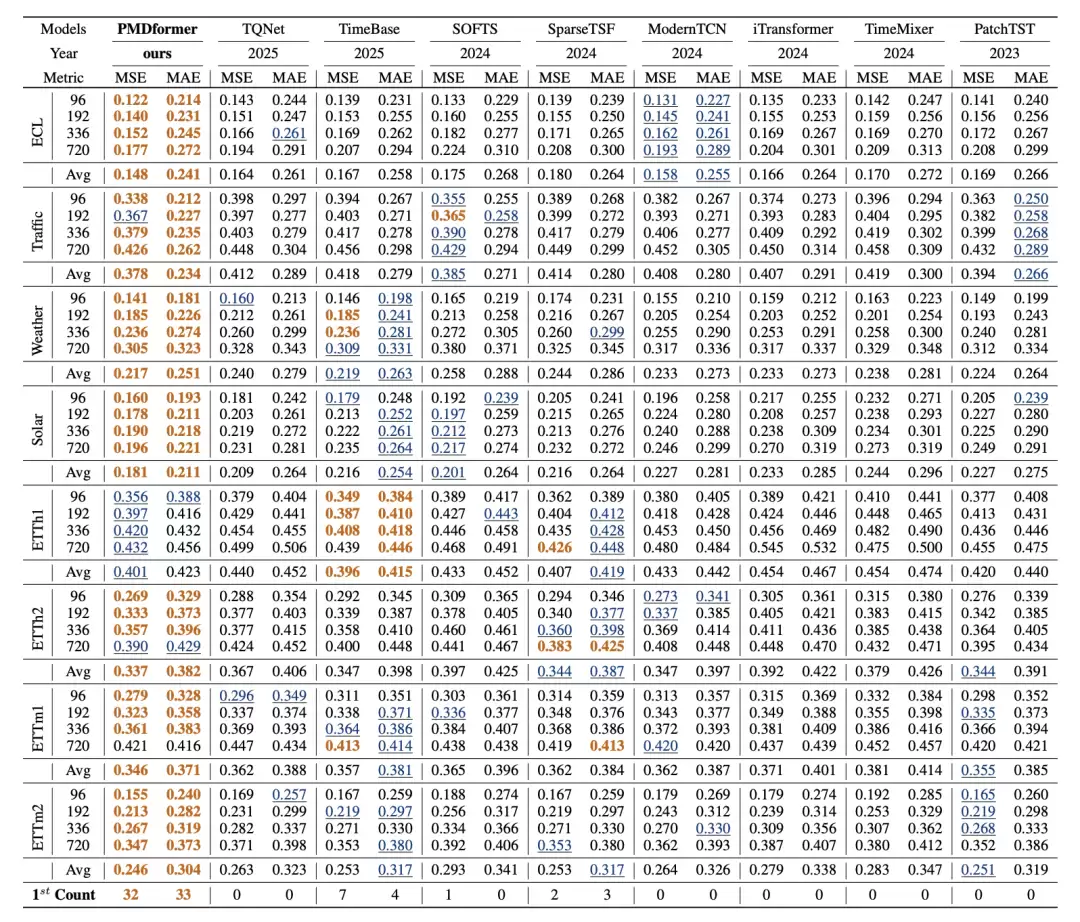
表1:长时间序列预测任务结果对比。展示了在8个数据集、4种不同预测长度下,各模型的MSE与MAE指标完整数据。
计算效率:以更少资源实现更高性能
除了精度高,PMDformer在计算效率上也表现突出。在变量数量从100激增到3000,以及序列长度从144扩展到5400的两组压力测试中,PMDformer相比PatchTST、iTransformer等主流模型,所需的GPU显存更少。这主要归功于PVA模块对计算复杂度的成功压缩,使得模型在处理高维多变量时序数据时更具 scalability(可扩展性)。
图3:计算效率对比。左图展示了不同变量数量下,右图展示了不同序列长度下,各模型的GPU显存占用情况。
总结与展望
PMDformer的成功揭示了一个在时序预测中长期被忽视的关键问题:数据片段中趋势与形状的耦合,会系统性损害模型对核心模式的识别能力。通过一个看似简单的均值解耦操作,配合精心设计的注意力机制,该框架在不增加模型复杂度的前提下,同步提升了预测的精度与效率。
展望未来,研究团队计划将这一框架扩展至更高维度的多变量时序建模场景,并探索其与文本、图像等多模态数据的融合应用,持续为金融、能源、交通等关键领域的智能决策提供新的技术动力。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:PMDformer长时序预测新方法用减法优化注意力机制解决尺度偏差要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点硕一最新推出的鲲鹏CL6N风冷散热器采用了双塔双风扇搭配六热管直触的设计,解热能力标称为260W。其最大特色是附带一块磁吸式数显屏幕,可实时显示CPU或显卡温度以及风扇转速,提升了使用的便捷性和视觉体验。产品兼容英特尔LGA1700 1851和AMDAM4 AM5等主流平台,提供了黑色无光、黑色
据最新小鹏汽车已组建团队正式进军游艇制造领域,项目内部代号“飞鱼”。该项目由整车架构负责人钱占伟负责,核心研发方向聚焦于底盘算法,旨在将智能电动汽车的技术积累应用于水上交通工具,目标客户为高净值家庭。目前项目仍处于研发阶段。此前,已有包括梅赛德斯-AMG、兰博基尼在内的多家豪华汽车品牌跨界涉足
丰田汽车副社长近日透露,其下一代电动汽车核心技术,包括大压铸工艺、新型电池和自走式组装线,在品质与成本上均已达到量产水平。尽管原计划承载这些技术的雷克萨斯LF-ZC概念车已中止量产开发,但公司已正式决定开发后继车型,并将所有核心技术平移至新项目。此举表明丰田的电动化技术研发并未放缓,而是以更灵活的方
微信鸿蒙原生应用的内测招募再次启动,此次测试规模显著扩大。此前因鸿蒙应用商店对单一软件的测试用户数量设限,内测资格较为有限。经过开发团队与平台方的沟通,测试用户上限得以提升,从而开启了新一轮的公开招募。参与报名的用户需填写华为账号、机型等信息,审核通过后将获得内测资格。官方鼓励获得资格的用户积极体验
- 日榜
- 周榜
- 月榜
热点快看