




中山大学梁小丹团队CVPR论文实现物理正确视频生成新突破

想象这样一个场景:一勺蜂蜜缓缓倒入热茶,本该拉出细长、连续的丝线,但在许多AI生成的视频里,这根丝线却可能突然断裂,甚至凭空消失。再比如,一块冰在室温下融化,真实的过程是边缘逐渐软化、体积缓慢变化,最终化为一滩水,而模型生成的结果却常常是直接从“冰块”跳转到“水渍”,中间的逻辑演化消失了。 这些现象
想象这样一个场景:一勺蜂蜜缓缓倒入热茶,本该拉出细长、连续的丝线,但在许多AI生成的视频里,这根丝线却可能突然断裂,甚至凭空消失。再比如,一块冰在室温下融化,真实的过程是边缘逐渐软化、体积缓慢变化,最终化为一滩水,而模型生成的结果却常常是直接从“冰块”跳转到“水渍”,中间的逻辑演化消失了。
这些现象并不罕见,恰恰是当前视频生成技术最易“露馅”的地方。画面乍看精美,但过程经不起推敲,缺乏因果链条,也缺少真实世界那种连续、符合物理规律的演变逻辑。
随着从OpenAI Sora到Kling等模型的迭代,视频生成的视觉质量上限被不断刷新,清晰度和风格化已不再是核心瓶颈。行业逐渐意识到一个更深层的问题:模型缺乏对基础物理规律的理解能力。现有方法大多依赖于海量数据的模式匹配,本质上是在生成“看起来合理”的静态画面序列,而非模拟“真实发生”的动态过程。这直接导致了在涉及流体运动、热量传递、多物体复杂交互等场景时,生成结果往往显得生硬、失真。
在此背景下,四川大学雷印杰团队提出了一项新研究《Chain of Event-Centric Causal Thought for Physically Plausible Video Generation》。这项工作的思路颇具启发性:它不再试图让模型直接从文本“跳”到视频,而是引导模型先理解物理过程本身。其核心是将复杂现象拆解为一系列具有因果关系的关键事件,并引入物理规律作为约束,再逐步生成最终的视频内容。目标很明确——不仅要让画面“像”,更要让变化过程本身“对”,从而在更本质的层面提升生成视频的可信度与一致性。

性能表现:数据说话
研究团队首先在专门评估物理合理性的PhyGenBench数据集上进行了系统测试。该数据集包含160条物理描述,覆盖力学、光学、热学和材料四大典型场景。
在整体性能上,新方法取得了0.66的得分。作为对比,此前最优方法PhysHPO的得分为0.61,这意味着0.05的绝对提升,相对提升约8.19%。与主流基础视频生成模型相比,优势更为明显:Kling为0.49,Gen-3为0.51,CogVideoX为0.45。新方法的0.66分意味着相对提升幅度超过了30%,提升相当显著。
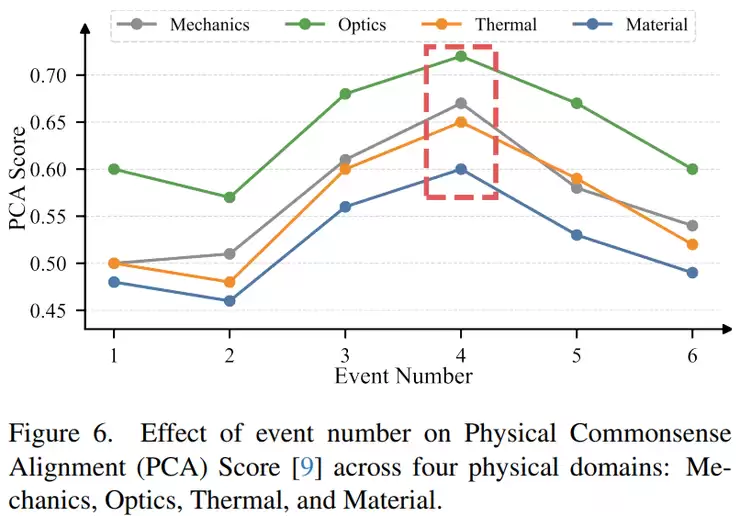
分领域来看,新方法在四个方向均表现不俗。其中,力学方向得分0.67(对比约0.55),光学方向0.72(对比0.68),热学方向0.65(对比0.58)。材料方向得分为0.60,虽略低于该领域最高值0.65,但仍处于领先梯队。综合来看,在四个物理领域中有三个取得了第一,综合表现最强。
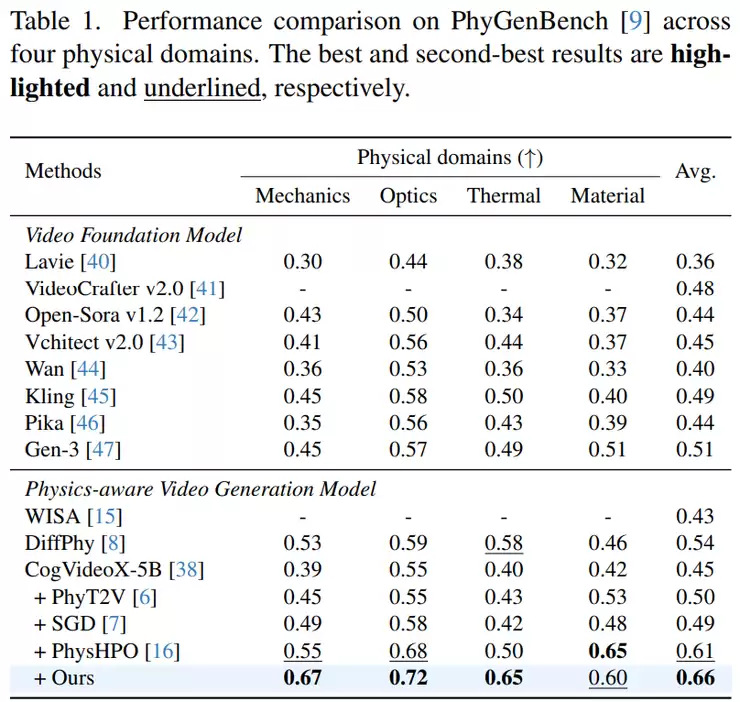
进一步的细粒度分析揭示了关键。研究将评估拆分为“物理现象识别能力”和“物理顺序正确性”两个指标。结果发现,最显著的提升集中在“物理顺序正确性”上。例如在力学场景中,新方法的顺序正确性得分达到0.79,而对比方法DiffPhy仅为0.53,提升幅度高达0.26。在光学和热学场景中,顺序正确性也分别有0.19和0.11的提升。这清楚地表明,新方法在理解事件的时间顺序和因果逻辑方面,能力得到了实质性增强。
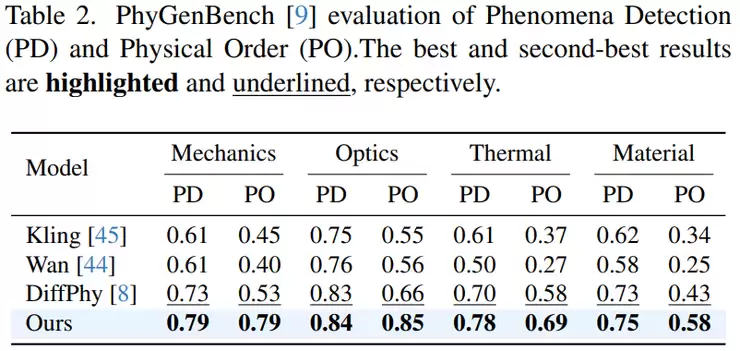
为了检验泛化能力,团队还在更贴近真实应用的VideoPhy数据集上进行了测试。该数据集包含688条提示,涵盖固体-固体、固体-液体、液体-液体间的复杂交互。评价指标是同时满足语义一致性和物理合理性的视频比例。
新方法取得了49.3%的结果,优于此前最优方法的约45.9%,提升3.4%。与基础模型CogVideoX的39.6%相比,提升达到9.7%。值得注意的是,在流体相关场景(如液体流动、蜂蜜倾倒)中,提升最为明显,整体超过10%。这说明新方法在处理连续、渐变的物理动态方面具有独特优势。
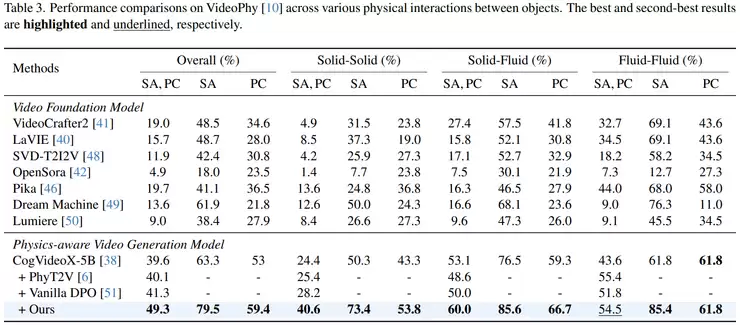
一系列消融实验则揭示了各个模块的重要性。移除物理公式模块后,性能从0.66降至0.62(下降约6%);移除事件分解模块后,降至0.59(下降约11%);移除文本渐进生成模块后,为0.64(下降约3%)。影响最大的是关键帧生成模块,移除后性能骤降至0.55,降幅达17%。这证实了事件链结构和关键帧机制是整个方法的核心支柱。
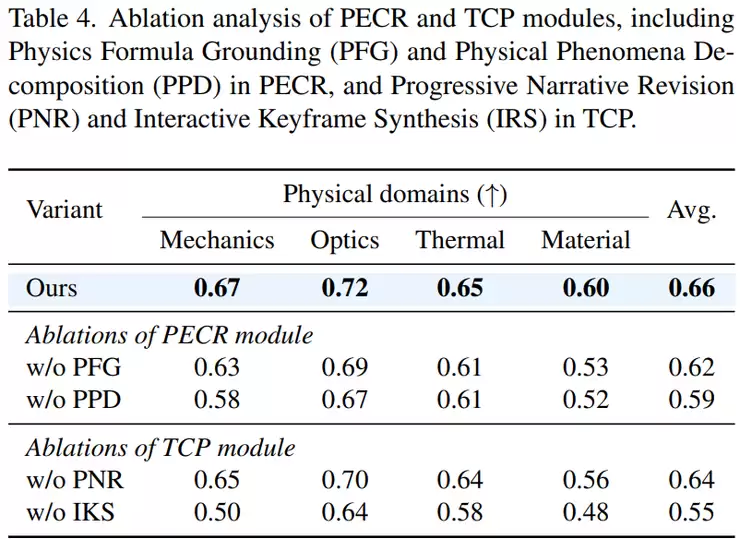
研究还分析了事件数量对性能的影响。当事件数量为1到3个时,因信息不足,性能不佳;事件数量为4时,性能达到峰值;当事件数量增加到5或6个时,由于误差在关键帧生成和推理过程中累积,性能反而下降。这说明事件链的长度存在一个“甜点区”,过少无法完整描述过程,过多则会引入不稳定性。
技术核心:如何让AI“理解”过程
那么,这套方法具体是如何工作的?研究团队设置了统一的实验基础:视频生成主干模型采用CogVideoX-5B,生成分辨率为1360×768、共161帧的视频。语言推理部分使用GPT-OSS-20B模型,图像编辑则使用Qwen-Image模型来生成引导视频生成的关键帧。
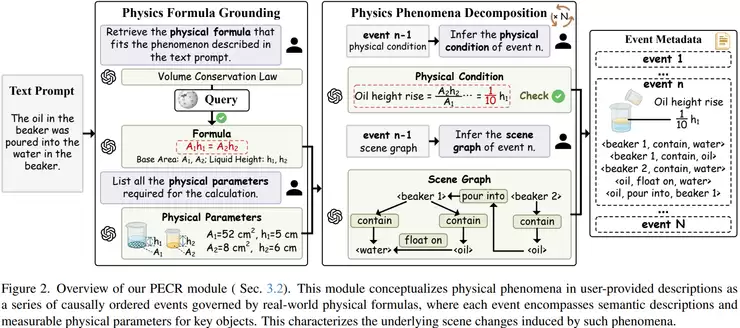
整个流程可以看作一个分步推理与生成的过程。首先,输入一个文本描述,例如“蜂蜜倒入杯中”。模型的第一步是理解文本并识别其中隐含的物理规律,比如判断这属于流体力学范畴,涉及体积变化和连续流动等特性。随后,系统会从知识库中检索与此过程对应的物理公式,为后续生成提供理论约束。
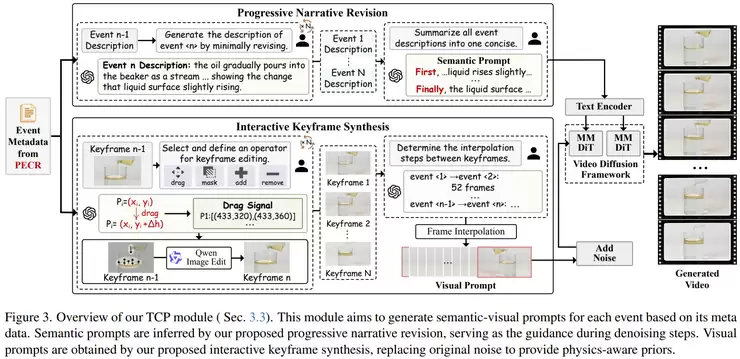
接下来是关键一步:构建事件链。研究通过PECR模块,将完整的物理过程拆解为多个连续、因果关联的子事件。以“蜂蜜倒入杯中”为例,它可能被分解为:开始倾倒、蜂蜜流柱接触杯口、液体在杯底堆积、液面逐渐上升等阶段。每个事件不仅包含语义描述,还包含了物理参数(如高度、体积变化)和场景关系(如物体的空间位置)。这样,一个连续的过程就被转化为了一个结构清晰、离散的事件序列。
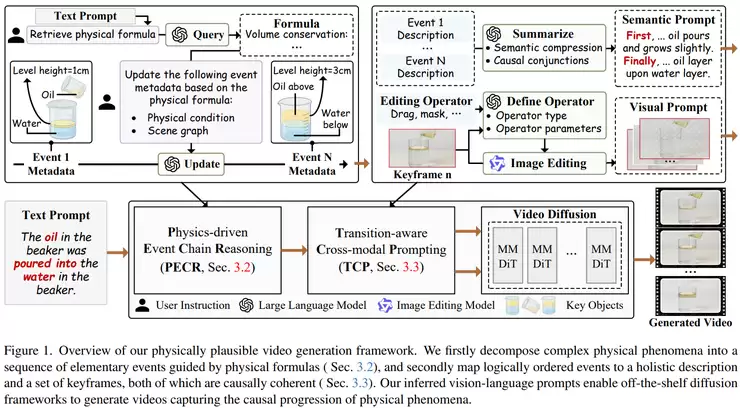
事件链构建好后,便进入提示生成阶段。模型会为每个事件生成对应的文本描述,再将这些描述整合成一个连贯的、带有“首先…然后…最后…”等逻辑连接词的完整提示。这确保了事件之间的顺序关系在语义层面就被锁定。
随后是视觉化阶段,即生成关键帧。针对事件链中的每一个关键节点,模型会生成一张对应的图像,并通过图像编辑技术,依据物理参数(如液体高度增加量)对画面进行可控的、渐进式的修改。这种方式避免了从零开始的完全随机生成,使得视觉变化更加平滑、稳定,且符合物理预期。
最后,系统在相邻的关键帧之间插入中间帧,通过插值形成流畅的过渡,再将整个序列输入扩散模型,生成最终的连贯视频。
在对比实验中,所有方法均在相同的文本输入、数据集和评价指标下进行,确保了公平性。对比对象既包括Kling、Gen-3这类通用视频生成模型,也涵盖了DiffPhy、PhysHPO等专注于物理合理性的增强模型。
从生成画面,到模拟现实
这项研究的意义,或许可以从一个根本性的转变来理解。过去的视频生成更像是在“拼凑画面”,模型的目标是让最终结果看起来逼真。但只要仔细观察过程,就常会发现反常识的细节:液体不连续、运动无因果、变化突兀。其根源在于,模型缺乏对因果关系、时间逻辑和物理规律的内在理解,导致视频“形似”而“神不似”。
新方法带来的改变,是将视频生成从“画面合成”问题,转向“过程建模”问题。它不再试图从文本直接映射到图像序列,而是先构建一条蕴含因果关系的事件链,再基于这条逻辑链去生成视频。这意味着模型不再仅仅输出一个“结果”,而是在结构上被迫去“经历”整个过程,自然地将时间顺序和前后逻辑嵌入到生成中,使得视频的动态更贴近现实世界的演化方式。
这种能力提升源于三方面的结合:一是物理约束能力,通过引入公式让变化不再随意;二是因果结构建模能力,通过事件链明确每一步该如何发生;三是视觉锚点能力,通过关键帧约束使中间过程变化更连续稳定。三者协同,推动模型从“生成看起来合理的结果”迈向“模拟真实发生的过程”。
这项进展的影响将是广泛而直接的。对于普通用户,未来在短视频创作时,只需输入简单描述,就能获得过程更真实、更连贯的动态内容,违和感大大降低。在教育领域,复杂的物理过程(如流体动力学、光路传播)得以直观可视化,让抽象概念变得可感可知。在游戏与虚拟现实中,环境交互将更加符合物理规律,提升沉浸感。甚至在自动驾驶模拟、机器人训练中,更真实的物理模拟能力也能帮助智能体更好地理解与适应现实环境。
从更宏观的视角看,这项研究将视频生成从一项纯粹的视觉任务,提升为一个物理过程建模问题,为构建真正理解现实世界的智能系统奠定了基础。
当然,研究团队也坦诚指出了当前方法的局限:在面对多个物理规律交织作用的极端复杂场景时(例如牛顿摆与水爆炸同时发生),模型仍会失效。这说明在组合物理推理方面,仍有很长的路要走,而这恰恰为未来的研究指明了清晰的方向。
研究者简介
本论文的通讯作者雷印杰,现任四川大学教授、博士生导师,并入选国家级青年人才项目,长期深耕人工智能领域。
雷印杰教授拥有系统的学术背景:他于2006年、2009年及2013年,分别在西南交通大学获得学士学位、在四川大学获得硕士学位、在澳大利亚西澳大学获得博士学位。2013年12月,他进入四川大学电子信息学院从事教学与科研工作,并于2017年9月起担任学院副院长。此外,他还入选四川省特聘专家、四川省学术和技术带头人后备人选,并获得四川杰出青年科学基金支持。
研究方向方面,雷印杰教授主要聚焦于人工智能、计算机视觉及多模态理解。他长期主持并参与多项国家级科研项目及企业合作项目,致力于推动学术研究与工程应用的有机结合。

你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:中山大学梁小丹团队CVPR论文实现物理正确视频生成新突破要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Dzine是一款强调构图控制与风格管理的AI图像设计工具,提供样式库、图层操作、定位和素描工具,支持文生图与图生图,具备生成填充编辑、一键修复增强及最高6144像素超高清导出功能,降低设计门槛,兼顾新手与专业用户。
3D虚拟空间的搭建,过去往往依赖专业建模软件和大量手动操作,技术门槛相当高。但现在,一款名为Arrival的云端SaaS解决方案正凭借AI与拖放功能,将这件事变得像搭积木一样轻松便捷。 什么是Arrival? Arrival本质上是一套专业的软件工具,核心目标就是帮助用户快速构建一个3D虚拟空间。它
ZENAI通过AI自动完成用户访谈,省去人工招募与主持流程,并自动总结用户场景、痛点及人物画像。产品经理、设计师、研究员可借此快速验证假设、提炼场景、获取市场洞察,加速产品市场契合度(PMF)达成,提供基础与专业两种套餐。
MeshcapadeMe基于SMPL人体模型技术,提供API接口支持图像、视频、测量及3D扫描输入,自动生成统一格式的逼真数字分身,无需专业建模技能即可将各类素材转化为可动画、跨平台使用的数字人类,适用于虚拟现实、游戏与影视等领域。
- 日榜
- 周榜
- 月榜
热点快看