




清华提出TaH方法大幅提升训练效率与模型准确率

研究揭示循环Transformer存在“潜空间过度思考”现象,即对已预测正确的词元继续迭代反而降低准确性。为此,团队提出TaH方法,通过轻量级决策器动态识别困难词元并仅对其增加迭代深度。该方法在多个基准测试中平均仅对约7%的词元进行二次迭代,显著减少计算量的同时将模型准确率提升了3 8%至4 4%。
在AI推理模型的发展中,一个明确的共识是:增加计算量通常能提升答案的可靠性。从扩展思维链到深化内部推理,诸如o1、R1等前沿模型的演进,都验证了“让模型进行更深入思考”这一技术路线的价值。
然而,一个核心问题常常被忽视:模型在生成每一个词元(token)时,是否都需要付出相同的“思考”成本?
这对于参数量有限的小型模型而言,尤其是一个关乎性能与效率的关键挑战。小模型部署成本低、推理速度快,非常适合边缘计算场景,但其固有短板也相当突出——在处理数学运算、代码生成和复杂逻辑问答时,往往因为少数几个关键token的预测错误,导致整个推理链条崩溃。现有的“循环Transformer”方案试图应对此问题,其原理是在生成每个token前,将最后一层的隐藏状态反馈给模型进行额外的“潜空间迭代”,相当于在不增加参数的前提下,为每个token都增加了计算深度。
但这种方法真的最优吗?来自清华大学、无问芯穹、上海交通大学等机构的联合研究团队在最新论文中发现,事实并非如此。他们的研究揭示了一个反直觉的现象:有相当一部分token在模型第一次前向传播时就已经预测正确,后续的潜空间迭代不仅没有益处,反而可能将原本正确的预测“改错”。研究团队将这一现象命名为“潜空间过度思考”。
基于这一核心发现,该团队提出了 **Think-at-Hard(TaH)** 方法。这是一种面向小型模型的选择性潜空间迭代框架,其核心理念是“将计算资源用在刀刃上”——只让模型在真正难以预测的token上“停下来,多思考一步”。该方法已入选ICLR LIT Workshop最佳论文候选,并被ICML 2026接收。

潜空间迭代是一把双刃剑:既能纠正错误,也可能引入新的错误。
核心贡献
这项研究的主要贡献可总结为以下三点:
首先,它首次系统性地揭示并量化了循环Transformer中存在的“潜空间过度思考”现象,明确指出统一深度的迭代会同时产生“纠错”和“致错”两种相反的效果。
其次,提出了完整的TaH框架。该框架通过一个轻量级的“迭代决策器”、创新的双路因果注意力机制以及深度感知的LoRA模块,实现了在token级别动态分配计算资源。
最后,在涵盖数学、问答和代码的9个主流基准测试中,TaH均带来了稳定的性能提升。最关键的是,它平均仅让约7%的token进入第二轮迭代,跳过了93%不必要的额外计算。与那种强制所有token都“思考两遍”的基线方法相比,TaH在显著减少计算量的同时,准确率反而提升了3.8%到4.4%。

关键洞见:对简单Token进行迭代计算反而有害
已有研究表明,在语言模型的推理过程中,并非所有token都同等重要。真正决定推理走向的,往往是那些表示逻辑转折、因果关联或中间结论的关键性token。
为了量化“选择性迭代”的潜在收益,研究者设计了一个“先知”策略:仅当模型第一次预测某个token出错时,才允许它进行额外迭代;如果第一次预测正确,则直接输出。实验结果显示,仅凭这一理想化策略,就能为下游任务带来最高7.3%的性能提升,且仅需让11%到19%的token进行二次迭代。
这传递出一个清晰的信号:推理时的计算资源分配,必须细化到token级别。复杂问题中也包含简单token,简单问题里也可能隐藏着关键token。更重要的是,对简单token强行施加额外计算,不仅浪费算力,还会导致一部分原本正确的预测被“过度思考”而改错,这正是“潜空间过度思考”的具体体现。
TaH框架:在困难之处停下来深入思考
TaH的思路简洁而高效:简单的token快速通过,困难的token才值得投入更多计算资源进行“深思熟虑”。
具体实现上,TaH在模型中引入了一个轻量级的“迭代决策器”(一个小型MLP网络)。每完成一轮潜空间迭代后,决策器会基于模型骨干网络的当前状态,预测一个“继续迭代”的概率。如果该概率低于预设阈值,模型就直接输出当前token;如果高于阈值,则进入下一轮迭代。
在实际推理中,TaH平均每个token仅执行1.07次迭代,相当于跳过了约93%的token的二次计算。相比“所有token都想两遍”的暴力策略,TaH成功地将宝贵的计算力集中到了那些更容易出错、更能影响整体推理方向的关键位置上。
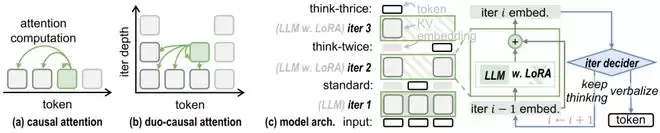
TaH的整体架构与双路因果注意力机制示意图。
为了让这种动态深度策略真正提升模型的精度和效率,TaH在模型架构和训练策略上都进行了针对性设计:
1. 双路因果注意力机制: 选择性迭代将模型处理的序列结构,从一维的token序列,转变为“token位置 × 迭代深度”的二维网格。TaH将传统的因果注意力扩展到了这个二维平面。对于某个位置第d次迭代的查询,它可以关注到前序位置中、迭代深度不超过d的所有键和值。这样既允许信息在不同迭代深度间有效流动,又保持了训练时序列维度的全并行计算能力。
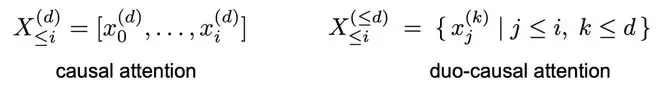
2. 深度感知LoRA架构: 研究者观察到,模型的第一次迭代主要负责常规的下一个token预测,而更深层的迭代则专注于修正当前遇到的困难token。因此,TaH只在第二次及以后的迭代中启用LoRA适配器,让LoRA专门学习如何修正困难token。再配合跨迭代的残差连接,深层迭代就被自然地训练为“在前一轮结果的基础上进行精细化修正”,而非从头开始推理。
3. 两阶段训练策略: 由于迭代决策器的判断依赖于骨干网络的预测质量,而骨干网络的训练目标又依赖于决策器决定的迭代深度,两者紧密耦合,端到端训练极不稳定。TaH采用了解耦的两阶段方案:第一阶段,使用静态的“先知”策略来训练骨干网络;第二阶段,冻结骨干网络,单独训练决策器去模仿“先知”的继续/停止决策。这种方法显著提升了训练的稳定性和收敛速度。
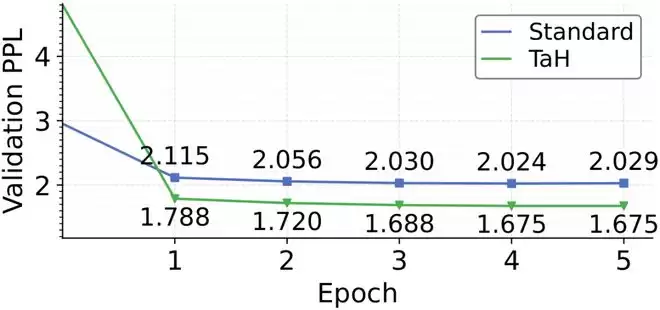
在Qwen3-0.6B基座模型上,TaH展现出更快的收敛速度。
实验效果:更少的迭代,更强的推理能力
论文在Qwen3系列的0.6B、1.7B和4B三个规模的基座模型上全面验证了TaH。训练数据来自Open-R1中数学、问答和代码任务的均衡混合,并在GSM8K、MATH500等9个主流基准上进行了综合评测。
准确性方面: 在不增加参数总量的前提下,TaH相比标准Qwen3模型提升了3.0%到3.8%。而“TaH+”版本在仅增加不超过3%额外参数(来自决策器等模块)的情况下,将提升幅度扩大到了5.3%到6.2%。与同类循环Transformer方法“Ouro”相比,TaH取得了3.8%到4.4%的优势,TaH+的优势则达到6.1%到6.8%。

计算效率方面: TaH平均每个token仅执行1.07次迭代,完成问答的平均FLOPs和显存访问量相比标准模型只增加了4%到5%。在实际解码测试中,TaH相比“始终迭代”的基线方法,显存占用降低了1.48倍,解码速度提升了2.48倍,同时保持了更高的准确率。
迭代选择的语义可解释性: 一个有趣的发现是,TaH自动学习到了具有明显语义偏好的迭代行为。在验证集上,“But”和“So”是最常触发额外迭代的token,概率分别达到34%和18%。这些词汇通常对应着推理中的逻辑转折、因果关联和方向切换,恰恰是复杂推理中最可能决定后续路径的关键位置。

模型预测在两次迭代之间的变化情况。
消融实验分析
为了验证TaH框架中每项设计的必要性,研究团队进行了系统的消融实验。
模型架构方面: 将动态深度的决策器替换为固定迭代1次或2次的策略,基准测试性能平均分别下降6.1%和16.4%,这证明了选择性迭代本身优于固定深度策略。将双路因果注意力替换为传统的因果注意力,性能下降5.4%到8.5%,说明了跨迭代深度信息流动的重要性。移除深度感知LoRA与跨迭代残差连接,效果下降4.9%,确认了针对不同迭代目标进行架构优化的重要性。
训练策略方面: 相比TaH的两阶段训练,简单地用相同目标监督所有深度的预测会使性能下降4.3%,这说明不同迭代层应该承担差异化的优化目标。在训练中用决策器或动态“先知”策略替代静态“先知”策略,会因骨干网络与决策器的强耦合而导致训练不稳定甚至崩溃,从而证明了TaH两阶段训练策略的必要性。
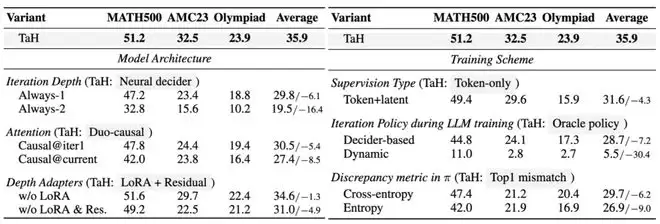
TaH在模型架构和训练策略上的消融实验结果。
总结与未来展望
TaH的意义,远不止于提出了一个新的循环Transformer变体或后训练方法。更重要的是,它探索了如何将“测试时计算扩展”推向更精细的token粒度。这项研究表明,更智能的动态算力分配策略,有时甚至比单纯堆砌更多计算资源能带来更优的效果。这为未来如何在有限资源下最大化模型推理能力的研究,指明了一个新的、富有启发性的方向。
参考文献
[1] Jaech, A., Kalai, A., Lerer, A., et al. OpenAI o1 system card. arXiv preprint arXiv:2412.16720, 2024.
[2] Guo, D., Yang, D., Zhang, H., et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[3] Yang, A., Li, A., Yang, B., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
[4] Abdin, M., Aneja, J., Awadalla, H., et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
[5] Team, M., Xiao, C., Li, Y., et al. MiniCPM4: Ultra-efficient LLMs on end devices. arXiv preprint arXiv:2506.07900, 2025.
[6] Hutchins, D., Schlag, I., Wu, Y., Dyer, E., and Neyshabur, B. Block-recurrent transformers. Advances in Neural Information Processing Systems, 35:33248–33261, 2024.
[7] Saunshi, N., Dikkala, N., Li, Z., Kumar, S., and Reddi, S. J. Reasoning with latent thoughts: On the power of looped transformers. arXiv preprint arXiv:2502.17416, 2025.
[8] Zhu, R.-J., Wang, Z., Hua, K., et al. Scaling latent reasoning via looped language models. arXiv preprint arXiv:2510.25741, 2025.
[9] Wu, Y., Wang, Y., Ye, Z., Du, T., Jegelka, S., and Wang, Y. When more is less: Understanding chain-of-thought length in LLMs. arXiv preprint arXiv:2502.07266, 2025.
[10] Wang, S., Yu, L., Gao, C., et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. arXiv preprint arXiv:2506.01939, 2025.
[11] Fu, T., Ge, Y., You, Y., et al. R2R: Efficiently na vigating divergent reasoning paths with small-large model token routing. arXiv preprint arXiv:2505.21600, 2025.
[12] Hu, E. J., Shen, Y., Wallis, P., et al. LoRA: Low-rank adaptation of large language models. ICLR, 2024.
[13] Hugging Face. Open R1: A fully open reproduction of DeepSeek-R1, January 2025. URL https://github.com/huggingface/open-r1.
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:清华提出TaH方法大幅提升训练效率与模型准确率要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点想要在个人电脑上部署小米开源大模型,打造专属的本地AI助手?这个过程看似技术门槛较高,但只要掌握正确方法,逐步操作,完全能够实现。本文将为您详细解析小米MiMo大模型的本地部署全流程,让您轻松在自有硬件上运行私有化大语言模型。 本地部署的核心优势在于实现“数据闭环”:将开源模型权重文件完全私有化,所
Anthropic收购了为OpenAI等多家AI巨头生成官方SDK的工具公司Stainless。此次收购旨在强化智能体连接外部系统的“接口”能力,是Anthropic构建智能体基础设施的关键一步。通过整合模型大脑Claude、连接协议MCP以及此次收购的SDK生成能力,Anthropic正着力打造智能体执行复杂任务所需的完整技术栈。
新石器推出AI智能体NeoClaw,可通过自然语言指令指挥无人车队,使单人管理效率从约10台提升至100台以上。公司基于无图自动驾驶方案与RaaS服务模式,已实现万台车辆运营,业务覆盖全球约20国,正从无人车向机器人领域拓展。AI管理旨在提升规模化效率、降低使用门槛,推动行业向高效易用发展。
想在OpenClaw框架中同时运行多个飞书机器人,实现不同部门或应用场景的指令独立处理?这个需求在企业级自动化部署中非常常见。虽然听起来技术复杂,但核心逻辑非常明确:为每个机器人实例创建完全隔离的运行环境,确保从配置文件、身份凭证到网络端口都互不干扰,最终实现稳定并行工作。 接下来,我们将详细拆解从
- 日榜
- 周榜
- 月榜
热点快看