




李飞飞发布空间智能基准数据集ImageNet时代来临

继ImageNet之后,李飞飞团队再次引领AI评测新方向,聚焦于更具挑战性的具身智能领域。他们最新发布了ESI-Bench,一个专门用于评估智能体空间认知与推理能力的新基准。这标志着AI评测范式从静态感知向主动交互的重要演进。

传统的空间智能评测,往往为模型提供“上帝视角”的完美观测。而ESI-Bench的核心创新在于,它将智能体从“被动观察者”转变为“主动探索者”,真正实现了“感知-决策-行动”的闭环。这一基准为具身空间智能领域提供了首个系统性的评测框架,旨在全面覆盖人类空间认知的四大核心维度。
研究揭示了一个关键结论:当前的人工智能虽然在图像识别上表现出色,但距离具备“主动移动、交互操作、自主探索”能力的真正空间智能,仍有巨大差距。

ESI-Bench评测基准:从“被动识别”到“主动探索”的范式转变
ESI-Bench的提出,直指当前AI评测体系的一个根本性问题:它们大多测试的是“被动感知”能力。
向模型输入一两张图片,询问“A在B的左边还是右边”或“这个杯子的容量是多少”——这类任务评估的更像是模型的“视觉识别力”,而非深层的空间推理与问题解决能力。
人类是如何解决此类问题的?我们不会静止不动。我们会起身绕到物体后方观察;会伸手拉开抽屉检查内部;会通过倒水来测量容量。这种主动与环境交互、通过行动获取关键信息的能力,才是空间智能的本质。
ESI-Bench正是基于这一核心理念构建:将智能体从观察者转变为行动者。

在真实物理世界中,智能体必须像人类一样,主动规划下一步行动以收集证据,并基于新的观测进行推理和决策。研究团队将这一循环过程定义为“感知-行动回路”。
ESI-Bench是一套超越现有基准的全新评测体系。它包含10个主要任务类别、29个子类别,总计3081个任务实例,全部在OmniGibson高保真仿真平台上构建,场景素材来源于BEHAVIOR-1K大规模场景库。

所有任务均围绕发展心理学家Elizabeth Spelke提出的四大核心知识系统设计,这些被认为是人类婴儿与生俱来的空间直觉基础:物体表征、空间布局与几何关系、数量表征、目标导向的行动规划。
该基准的关键设计在于“强制行动”。每项任务中,AI智能体都必须通过主动探索和操作才能获得足够信息来回答问题。模型无法被动接收图片,它必须自主决定移动方向、观察角度、抓取对象以及操作方式。

举例来说,一道“刚性物体容纳”题目:给定几个容器和若干物体,要求将所有物体装入容器。有些容器开口狭小,有些内部设有隔板,有些则需要打开盖子才能看清真实容量。
模型必须走近容器、俯身查看、甚至拿起容器从底部观察,才能准确判断是否能够容纳。
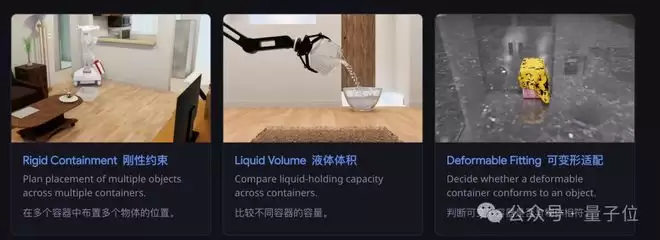
再如“液体体积比较”任务:两个外观完全相同的杯子,无法直接判断容量差异。模型需要将水倒入杯中测试,或者拿起杯子掂量重量来推断。
从这些实例可以清晰理解ESI-Bench的设计哲学:正确答案并不存在于任何单一静态视角中,智能体必须通过主动交互、多角度观察和逻辑推理,才能逐步揭示事实全貌。
研究团队特别强调,与以往工作相比,ESI-Bench在三个维度实现了显著突破:


从空间感知到空间能力:评测重点不再是智能体“看到了什么”,而是它“知道如何运用何种能力”来解决复杂的空间任务。
选择性感知与信息获取:智能体必须学会判断哪些观察是关键的,优先收集与任务目标高度相关的信息,过滤冗余或无用的感官输入。
解决感知歧义与推理隐藏属性:智能体必须能够处理具有误导性的表面观察,推理出隐藏的空间结构、物理约束和物体潜在属性。
基准实测结果:揭示三大核心发现
研究团队利用当前最先进的多模态大模型进行了全面测试,包括GPT-5和Gemini系列模型。

上图为核心实验结果,对比了在被动感知、主动探索以及“上帝视角”三种不同范式下,各类模型在ESI-Bench各项任务上的准确率表现,涵盖了2D视觉语言模型、3D大语言模型以及人类表现基线。
深入分析后,团队总结出以下三个核心发现。
发现一:主要瓶颈在于“行动策略”,而非“视觉感知”
首先是一个积极信号:主动探索策略本身是有效的。在没有明确指令的情况下,智能体自发涌现出多种空间探索行为,例如绕到物体背后观察、切换俯视与平视角度、拿起物体检查、倒出液体验证等。

一个典型例证是,在“部分遮挡”任务中,如果直接为Gemini 3.1提供最佳观测视角,其准确率能从14.6%大幅提升至95.1%。这表明,模型本身的视觉感知能力并不弱,只要获得合适的视角,它就能正确理解场景。

但关键问题在于,模型自身缺乏能力去主动寻找那个正确的视角。
更令人意外的是,被动的“多视角输入”策略不仅无益,反而可能有害。实验显示,让GPT-5观看多张随机角度的图片,其在空间距离估算任务上的准确率反而从53.9%下降至49.1%。视图增多,性能却下降了。
GPT-5和Gemini 3.1在主动探索中达到正确答案所需的平均步数对比

团队将这种现象命名为“动作盲视”:一个糟糕的行动选择导致一个无效的观测视角,而这个无效视角又会引发更差的后续决策,最终形成难以挽回的级联失败。在“结构围合”任务上,主动探索策略的表现与“上帝视角”下的表现差距高达49.7%。
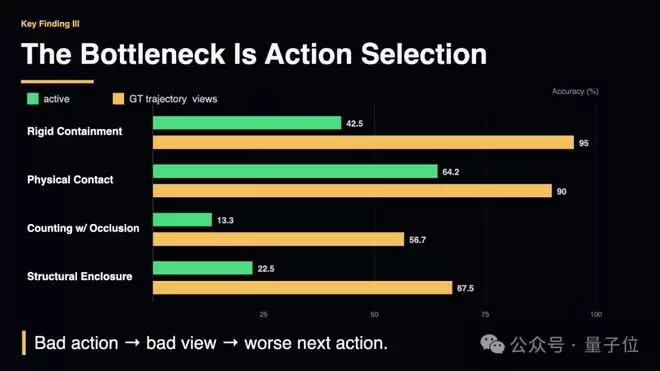
这意味着,当前空间智能发展的主要障碍,可能并非视觉模型不够强大,而在于行动规划与探索策略几乎处于空白状态。
发现二:不完美的3D重建,效果可能逊于2D图像
既然2D被动看图存在局限,那么引入3D信息呢?这也是当前许多具身智能研究团队的思路:先进行三维场景重建,再在重建的3D场景图上进行推理。
测试发现,如果提供的是“真值3D”(即几何完美的上帝视角3D模型),性能确实强劲。例如在“材质透明度”任务上,Gemini的2D版本得分为44.0%,而3D版本达到60.4%,提升了16.4个百分点。在需要精确深度信息的任务上,3D表征具有天然优势。
但如果使用的是现有技术“实时重建”出来的不完美3D场景呢?团队采用了先进的VGGT模型进行场景重建,再将重建结果输入给推理模型。
结果令人惊讶:在“几何配置”任务上,2D基线得分尚有27.5%,而使用VGGT重建后的3D场景图进行推理,得分骤降至9.9%。

这表明,质量不佳的3D重建并非中性的失败,而是会产生负面影响的“噪声源”。几何伪影、遮挡补全错误、深度估计偏差……将这些失真信息编码成场景图,相当于为推理模型提供了带有误导性的输入。相比之下,2D图像虽然信息维度较低,但至少保真度较高;而质量不过关的3D重建,其效果可能还不如朴素的2D图像输入。
发现三:元认知缺陷——模型缺乏对自身认知状态的评估能力
论文中还有一组对比实验,深入揭示了智能体与人类在空间推理能力上的本质差异。
结果发现,尽管存在感知差距,但这种差距可能比普遍认为的要小。在部分任务类别中,模型的被动感知表现甚至能与人类持平或略胜一筹。例如,在“真实轨迹”(即提供人类探索路径上的观测)条件下,Gemini在部分遮挡任务上达到88.4%的准确率,人类为87.4%;GPT-5在材质透明度任务上达到96.3%,人类则为97.2%。

然而,一旦切换到需要完全自主探索的场景,差距便急剧扩大。人类凭借明确的观察目标、高效的探索策略和适时的停止机制,表现远超模型,且其主动探索的表现更接近“真实轨迹”下的被动表现。例如在“物理接触”判断任务中,人类准确率为88.3%,而GPT-5仅为64.2%;在“材质透明度”任务中,人类准确率为93.6%,Gemini 3.1则为52.3%。
通过分析探索轨迹,团队发现人类表现出更强的“认知谨慎性”:在做出最终判断前会收集更多观测证据,主动寻找可能证伪当前假设的视角,并在证据模糊时降低判断置信度。
而模型则倾向于过早停止探索。即使证据尚不充分或存在矛盾,模型也常在少数几步探索后便以高置信度做出判断,从而产生与真实场景状态不符的“空间幻觉”。

模型的这种“过度自信”问题,还因其动作选择的方向性偏差而加剧:模型不会主动探查正交角度或寻找能推翻初始印象的反证据视角,而是倾向于在相似方向上重复移动,积累了大量冗余信息而非有效证据。
团队将这一问题定性为元认知缺陷:模型缺乏对自身知识状态的监控与评估能力。它没有内建的“不确定性评估”机制,无法判断当前信息是否充分,也难以根据矛盾的证据动态调整自身信念。这个问题在根本上区别于感知能力的不足,是一个更深层次的挑战,仅靠增强视觉编码器或单纯增加探索步数无法解决。
作者团队介绍
最后,让我们了解这项重要工作的作者阵容。

论文第一作者是Yining Hong(洪艺宁),斯坦福大学博士后研究员,导师为Yejin Choi教授,并受到Leonidas Guibas教授、吴佳俊教授和李飞飞教授的密切指导。

她曾在加州大学洛杉矶分校(UCLA)获得计算机科学博士学位,本科毕业于上海交通大学电子工程系。值得一提的是,她还是一位职业音乐家,经常与乐队巡回演出,同时担任CVPR 2026的社交主席,负责组织招待会和音乐表演。
Jiageng Liu(刘家耕),加州大学洛杉矶分校Mobility Lab的博士生。
其本科就读于浙江大学竺可桢荣誉学院及计算机科学与技术学院的图灵班,获人工智能学士学位。
Han Yin(尹涵),清华大学本科生,斯坦福大学访问学生,专业为计算机科学与技术。

李飞飞教授、吴佳俊教授、Yejin Choi教授三位斯坦福大学知名学者也位列作者名单。

此外,西北大学的Manling Li教授和斯坦福大学的Leonidas Guibas教授也参与了此项研究。
[1]https://arxiv.org/abs/2605.18746
[2]https://esi-bench.github.io/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

第四届链博会人工智能专区亮点前瞻 未来科技集中亮相
第四届中国国际供应链促进博览会将于6月22日至26日在北京举办,首次设立人工智能专区,英伟达、阿里巴巴等领军企业参展,系统展示从数据、算力到应用的全产业链生态。AI技术将渗透至先进制造、健康生活等多个展链,机器人将承担现场服务。本届链博会升级打造“四链融合”平台,旨在促进创新成。

OpenAI推出ChatGPT for PowerPoint测试版可自动生成编辑幻灯片
OpenAI推出PowerPoint的ChatGPT测试版插件,用户可通过自然语言指令生成、编辑和完善幻灯片。该工具还能分析文稿内容盲区,预测听众可能提出的问题。系统设有确认机制以确保用户控制权。测试版已向全球用户开放,免费用户亦可使用。

李飞飞发布空间智能基准数据集ImageNet时代来临
李飞飞团队发布空间智能新基准ESI-Bench,将AI评测从被动感知转向主动交互,要求智能体通过行动获取信息以评估空间认知能力。测试显示,当前AI在视觉感知上表现尚可,但缺乏有效行动策略与元认知能力,在主动探索任务中远逊于人类。研究还发现,不完美的三维重建会损害模型性能,而模型的“过度。

深圳企业如何将旧系统升级为AI能力库获4100万用户青睐
当前企业AI应用多停留在对话层面,难以实际执行业务操作。核心在于构建独立的AI调度层,通过API连接各业务系统,将其功能封装为可调用技能。用户用自然语言提出需求,AI即可自动完成意图识别与流程执行,将系统转变为能力库。此举能显著提升效率,且无需重构原有IT架构。建议企业从高频、低风险。

算力服务行业乱象解析与Token高质量流通解决方案
Token好用才是硬道理。 “今年各家token服务商的服务质量,明显比去年差了。” 这并非空xue来风,而是一位算力服务商负责人的切身体会。他提到,过去一个请求3到5秒就能返回首token,如今却可能拖到30秒甚至更久,类似情况的发生频率显著提高。究其原因,行业内的“超售”现象难辞其咎——部分服务








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
