




Gemma 4模型部署指南 显存内存占用与云端端侧选型

对于关注大模型实际落地的开发者和技术团队而言,Google最新开源的Gemma 4系列带来了全新的部署可能性。该系列不再单纯追求参数规模的宏大,而是将核心优化重点放在了“单位参数的智能效率”与“实际部署的可行性”上。通过创新的混合注意力机制显著优化内存占用,它使得在消费级硬件上运行顶尖的AI推理能力,从概念愿景转变为可实现的方案。
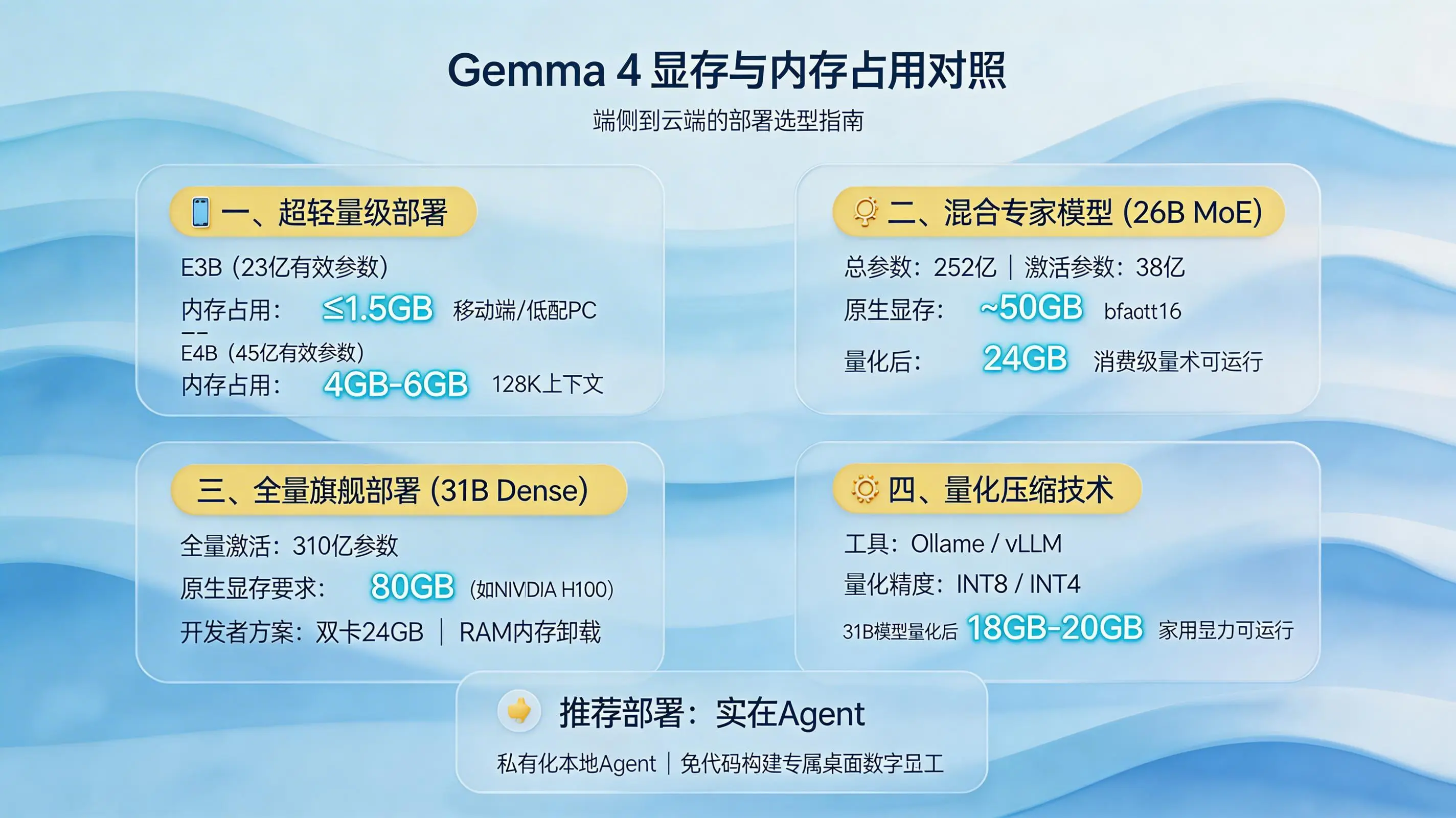
一、超轻量级部署:E2B 与 E4B 的内存需求解析
针对资源受限的物理部署环境,Gemma 4系列精心打磨了两款主打“高效参数”的轻量级模型:E2B和E4B。
首先是E2B模型,它具备23亿有效参数,是专为移动端和低配置PC深度优化的版本。在部分设备上,其内存占用可被极致压缩至1.5GB以下。这意味着,即便是仅配备CPU或仍在使用DDR4内存的普通办公笔记本电脑,也能流畅运行它来处理文本分类、简单问答等轻量化AI任务。
而E4B模型则更进一步,将有效参数提升至45亿。建议为其预留4GB到6GB的系统物理内存。它的核心价值在于,能够在维持较低系统负载的同时,提供长达128K上下文的强大文本解析与生成能力,为处理长文档摘要、多轮对话等复杂场景打开了通路。

二、混合专家模型:26B MoE 的显存优化与激活策略
若要在模型参数规模与推理速度之间寻找最佳平衡点,那么26B MoE模型(亦称A4B MoE)便是理想的解决方案。
其巧妙之处在于独特的混合专家架构设计:模型总参数量高达252亿,但每次推理时,系统仅会动态激活其中的38亿参数。这带来一个关键优势:虽然以bfloat16原生精度加载完整模型仍需占用约50GB的物理显存,但由于实际参与计算的参数量极少,推理过程中的显存带宽压力极低,其实际运行速度可媲美一个4B大小的稠密模型。
当然,50GB的显存需求对多数消费级显卡而言依然较高。但别忘了,我们还可以借助模型量化这一“利器”。通过应用适当的INT8或INT4量化方案,此模型完全有机会部署在拥有24GB显存的高端消费级显卡上,使得广大开发者的个人工作站也能流畅运行。

三、全量旗舰部署:31B Dense 模型的硬件配置指南
对于追求极致生成质量与性能上限的应用场景,31B Dense版本是Gemma 4系列的旗舰选择。它采用全量参数激活机制,一次性调用全部310亿参数进行推理。
此版本的“原生”硬件门槛非常明确:若不采用任何压缩技术,以原生精度完整加载模型权重,并维持其256K的超长上下文窗口,您需要配备一块拥有满血80GB显存的专业计算卡,例如NVIDIA H100。
对于普通的开发与实验环境,更现实的部署路径通常有两种:一是采用双卡并联方案,例如使用两块24GB显存的显卡来协同分担负载;二是借助系统主板的物理内存进行网络层权重卸载。但需注意,后一种方法会以一定程度牺牲文本生成速度为代价。

四、量化压缩技术:如何利用低成本硬件实现跨级部署
当物理硬件条件无法升级时,模型量化技术便成为跨越显存门槛的核心路径。其本质是在计算精度与运行效率之间做出最优权衡。
通过Ollama或vLLM等主流推理后端框架,可以将模型的计算权重从16位浮点数(FP16)高效压缩至INT8甚至INT4精度。其收益是立竿见影的。以31B旗舰模型为例,采用INT4量化后,其显存占用会出现显著下降,通常可降至18GB到20GB左右。
这带来了怎样的可能性?这意味着当您在本地终端执行 ollama run gemma4:31b 命令时,单张RTX 4090级别的高端家用显卡便有极大机会成功加载并运行它,让旗舰级的大模型能力变得触手可及。
总结
总而言之,Gemma 4系列为不同需求和资源条件的开发者提供了一份清晰的内存与硬件配置地图。从最低仅需1.5GB内存即可运行的E2B轻量版,到需要80GB专业显卡全力支撑的31B满血旗舰版,选择的关键在于如何根据您手头可用的物理硬件资源,以及业务场景对响应速度、推理精度的具体要求,来匹配最合适的模型尺寸与量化方案。
成功在本地完成模型部署仅是第一步,如何安全、高效地将其融入实际工作流才是释放价值的关键。一个可行的实践方向是借助智能体框架,它能够原生接入本地大模型接口,充当纯私有化的安全网关。通过自然语言指令即可敏捷构建专属的自动化AI工作流,高效调度内部软件与数据,从而将本地的强大算力,转化为真实、可控、高效的生产力工具。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

SaaS与PaaS平台核心区别:定义架构及应用场景详解
在数字化转型的进程中,SaaS(软件即服务)与PaaS(平台即服务)是两种至关重要的云计算服务模式。它们虽然同属云服务范畴,但在服务层级、目标用户和应用方式上存在根本性差异。简单来说,SaaS是可直接使用的应用软件,而PaaS是用于构建和部署应用的开发平台。准确理解SaaS与PaaS的区别,是企业进

电商评论数据分析教程 从采集到AI洞察全流程指南
在当今的零售与跨境电商领域,商品评论的自动化分析已成为品牌洞察市场、优化产品与驱动增长的关键引擎。无论是国内的淘宝、京东,还是海外的亚马逊、TikTok Shop,海量的用户评价中蕴含着决定性的市场情报。然而,面对评论数据的爆发式增长,传统的人工处理方式效率低下、洞察浅薄,已无法支撑数据驱动的精细化

Stable Audio 3 开源音频生成模型系列详解与应用指南
StabilityAI开源了StableAudio3音频生成模型系列。该系列基于流匹配潜空间扩散架构,提供多种规格,支持从文本生成、编辑到续写音乐与音效。其Small版本可在个人电脑本地运行,全系列模型生成时长可达6分钟以上,并支持LoRA微调与快速推理,兼顾专业创作与隐私需求。

企业级AI智能体核心价值解析与应用场景指南
在数字化转型的关键阶段,企业级AI智能体正迅速崛起,成为驱动新质生产力发展的核心动力。这已超越了单纯的技术工具范畴,演变为一场深刻重塑组织架构与业务流程的范式变革。本质上,它不再是等待指令的被动程序,而是集环境感知、自主规划、多技能调用与闭环执行于一体的智能化数字实体,致力于实现复杂业务逻辑的端到端

Gemma 4模型部署指南 显存内存占用与云端端侧选型
对于关注大模型实际落地的开发者和技术团队而言,Google最新开源的Gemma 4系列带来了全新的部署可能性。该系列不再单纯追求参数规模的宏大,而是将核心优化重点放在了“单位参数的智能效率”与“实际部署的可行性”上。通过创新的混合注意力机制显著优化内存占用,它使得在消费级硬件上运行顶尖的AI推理能力








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
