




面壁智能开源BitCPM-CANN:国产算力实现1.58比特训练,推理显存节省六分之五

2026年,AI专用HBM内存价格暴涨超过165%,显存/HBM正成为模型扩展最昂贵、最稀缺的资源之一,模型公司的核心推理成本居高不下。
与此同时,高端AI芯片对华出口管制政策反复,让国产算力生态在面临高昂“过路费”与供应链安全风险的双重夹击下艰难求生。
这两件事叠加,共同指向一个核心问题:在硬件条件受限的现实下,国产模型厂商,该如何继续推进大模型的发展?
就在近期,一个来自国产阵营的答案正式亮相。在2026年5月23日的华&为昇腾开发者大会上,面壁智能联合清华大学、OpenBMB开源社区,发布了BitCPM-CANN——这是全球首个完全基于国产华&为昇腾平台训练并开源的三值(1.58-bit)大模型。该模型开源了从0.5B到8B的全尺寸版本,最直观的收益是,推理显存消耗节省了惊人的5/6。
这个模型究竟有何不同?它的出现意味着什么?更重要的是,基于国产芯片的训练路线,真的能走通吗?
一、1.58-bit三值权重如何跑通昇腾,省下6倍显存?
BitCPM-CANN的核心标签非常明确:全球首个完全基于国产算力平台(华&为昇腾)训练并开源的三值大模型。
那么,什么是“三值”?传统大模型的参数通常使用16位或8位浮点数表示,而BitCPM-CANN的每个参数只能取三个值:-1、0、+1。从信息论角度看,其每个参数平均仅需1.58 bit来存储,远低于常规精度。
为了节省显存,行业常见的做法是将精度从32位降至8位,这确实能带来4倍的显存节省,但往往伴随着一定的精度损失。BitCPM-CANN的思路则有所不同:其研发团队认为,压缩后的每一个比特,都应该承载尽可能多的知识信息,而不是被白白浪费。
因此,尽管BitCPM-CANN只有1.58 bit,但其信息密度实际上非常高,并非简单的“牺牲精度换取内存”。这一特性,在HBM紧缺、长上下文处理、MoE扩展等极度消耗显存的场景中,价值尤为凸显。
具体是如何实现的呢?其技术路径可以拆解为三个关键步骤:
第一步:将1.58-bit三值权重嵌入训练算子。
研发团队采用了STE(直通估计器)方案。在训练阶段保留全精度残差用于梯度更新,而在模型导出阶段则输出严格的三值权重。这一过程成功地将离散的三值权重真正嵌入了华&为昇腾的训练算子之中,实现了底层算子的适配。
第二步:通过完整QAT与后训练蒸馏守住模型能力。
团队在昇腾平台上完整部署了量化感知训练(QAT)与后训练蒸馏流程。这套组合拳确保了模型效果不出现显著下降,同时将训练吞吐量的损失成功控制在仅5%的水平,在效率与效果之间取得了良好平衡。
第三步:将低比特能力沉淀为可复用的训练基础设施。
更进一步,团队基于Megatron‑LM框架,嵌入了可插拔的QAT并行线性层,统一了检查点格式并支持32K长序列训练。这使得低比特训练能力不再是某个模型的“独门绝技”,而是成为了昇腾平台上可复用、可扩展的公共技术底座,为后续研发铺平了道路。
二、60B入终端:BitCPM-CANN撬动端侧AI落地
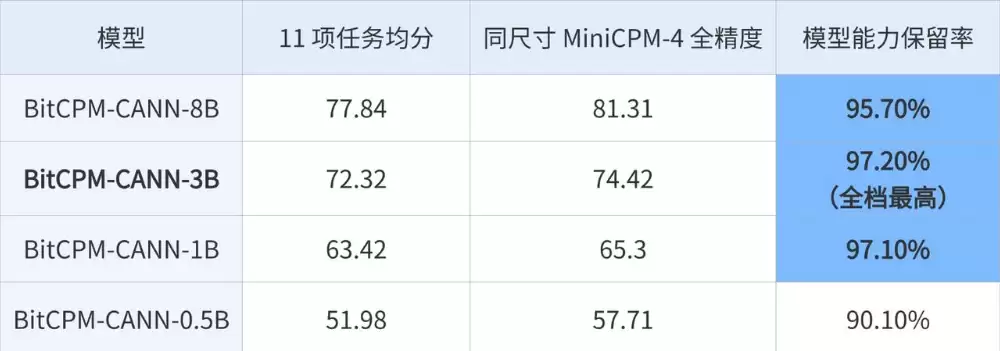
目前,BitCPM-CANN已经开源了从0.5B到8B的全尺寸版本。在1B、3B、8B这三个关键规格上,模型均保留了全精度版本95.7%以上的能力,其中3B版本更是达到了97.2%。即使在数学、代码等高精度敏感的任务上,3B版本的表现也已进入接近全精度的区间。
这些数据有力地证明,1.58-bit量化技术已经具备了面向真实模型族、真实评测集、真实训练栈的工程化说服力,不再是实验室里的概念演示。
端侧应用,是BitCPM-CANN价值最易被感知的领域,因为这里用户基数最大,应用场景也最广泛。
以8B模型为例,传统的BF16格式需要占用大约16GB显存,这个数字已经超过了绝大多数手机的运行内存容量,更不用说还要为其他应用预留空间。
而BitCPM-CANN将其压缩至2-3GB,使得在手机内存中流畅运行成为可能。这意味着手机厂商无需为了搭载大模型而盲目堆砌昂贵的超大内存,普通旗舰机型就能流畅运行8B级别的对话模型。
如果再向前展望,结合MoE(混合专家)架构——每次推理只激活部分参数——未来甚至有望将60B级别的“庞然大物”塞进笔记本电脑、平板,乃至高端手机之中。
硬件侧的进展也在同步推进。高通8850/8397等新一代端侧芯片,已经原生支持2-bit以下的低比特推理。芯片厂商早已铺好了跑道,只等待一个优秀的模型。BitCPM-CANN提供的1.58-bit权重,恰好与硬件能力实现了完美匹配。
更值得关注的是,BitCPM-CANN完全基于华&为昇腾芯片搭建,实现了全链路原生适配国产算力,与英伟达CUDA生态没有任何依赖关系。
这意味着其整个训练流程——从前向计算、反向传播,到量化算子的实现、分布式训练的调度——全部在昇腾平台上原生完成。中间不需要借助CUDA进行验证或中转,实现了真正的自主闭环。
这是昇腾平台上首个完整跑通1.58-bit训练,并进行了全精度对标评测的公开成果。而且模型规模直接推到了8B量级,并非仅作演示的几百兆小模型。
可以说,国产NPU在大规模三值量化训练这个高难度方向上,此前几乎没有公开的系统化成果。BitCPM-CANN的出现,算是填补了这块空白。
未来,昇腾生态内的低比特模型研发,都可以依托这套已经沉淀下来的底座继续前进。环境层、长序列支持、并行策略、融合算子、调试工具,一整套技术链路已然就绪。后续其他团队若想在昇腾上开展低比特训练,无需再从零开始“踩坑”。
一个由国产芯片、国产模型、国产训练框架共同构成的一体化自主产业链条,正在从蓝图一步步变为现实。
三、四年深耕,全栈自研:面壁智能如何掌握端侧AI话语权?
BitCPM-CANN并非凭空诞生,而是面壁智能在端侧AI路线上长期深耕后的自然产物。
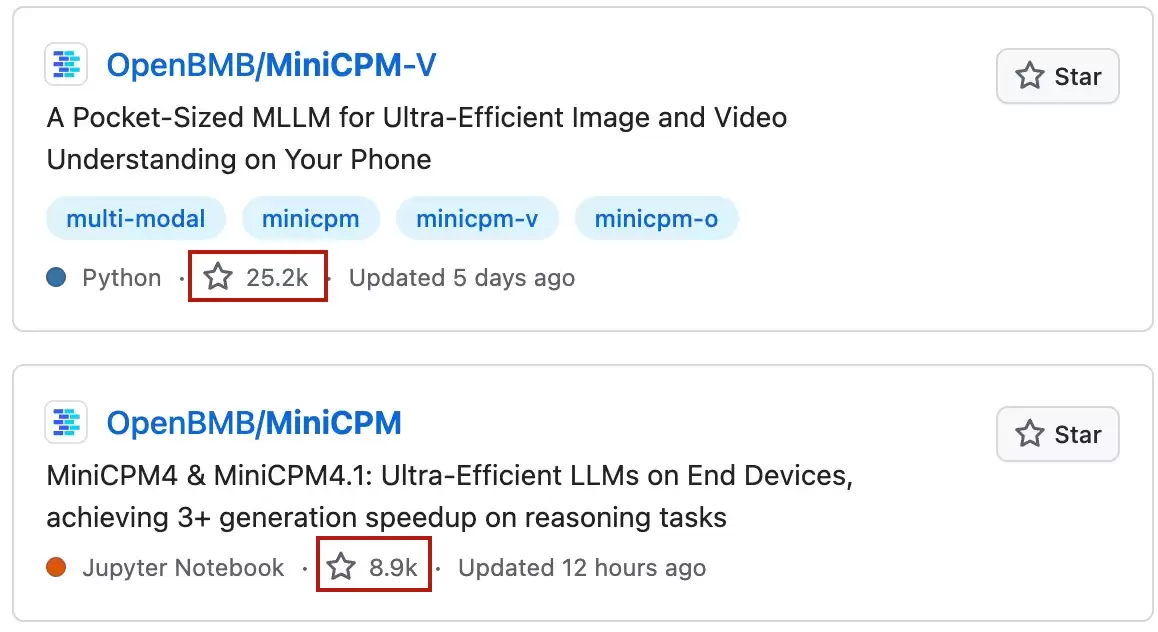
针对端侧AI,面壁智能已经形成了自己的模型矩阵——“小钢炮”系列(MiniCPM)。顾名思义,这是一系列参数虽小、能力却强的模型。MiniCPM在GitHub上累计收获超过3万星标,Hugging Face开源总下载量超过3000万,成为中国端侧AI领域最受欢迎的开源模型家族之一。
然而,将时间拨回面壁智能成立之初,情况远非如此乐观。2022年,国产芯片在大模型训练上尚不成熟,国内AI基础设施与国外存在明显差距。也正因如此,绝大多数公司选择了最省事的路径——直接依赖成熟的英伟达CUDA生态。
面壁智能却做出了一个截然不同的决定:自己编写框架,自己搭建底座。这意味着从一开始就没有绑定CUDA,其工程师必须亲手解决所有底层问题,例如显存如何高效分配、通信如何优化、算子如何融合。
更重要的是,这个艰难的起点引发了一连串深厚的技术积累。此后,他们自研了一套训练框架,命名为BM-Train(Big Model Train)。
从稀疏架构InfLLM,到低比特量化方法BitCPM,再到推理框架CPM.cu,面壁智能逐步构建起覆盖从训练到推理的全栈端侧技术体系。正是这些深厚积累,使得团队能够将验证成熟的1.58-bit训练方法,完整地迁移到昇腾平台上,做出BitCPM-CANN,实现从底层算子到训练框架的全链路原生跑通。
更难得的是,他们在国产芯片生态上的积累并不仅限于昇腾。此前,面壁智能曾参与协助华&为昇腾、鲲鹏,以及寒武纪、天数智芯等多家国产芯片构建和优化软件栈。这些经历让面壁智能建立起了对国产芯片生态的独特认知:既清楚“坑”在哪里,也知道如何“绕过去”。
端侧大模型的性能充分释放,离不开模型厂商与芯片厂商的深度协同与共同投入。在这个赛道上,面壁智能追求的从来不只是参与,而是成为关键的推动者与生态构建者。
结语:硬件受限,模型效率先行
过去两年,行业将“规模定律”(Scaling Law)奉为圭臬,算力几乎成了唯一的竞争门槛。
而BitCPM-CANN代表了一条不同的技术路线:在硬件条件给定的前提下,将模型的信息密度推向物理极限。更重要的是,它用事实证明了这条高难度路线可以在国产算力平台上完整跑通。
回到文章开头那个尖锐的问题:“在硬件受限的情况下,国产模型厂商,该怎么继续做大模型?”
面壁智能通过BitCPM-CANN给出了自己的答案:当硬件的追赶需要时间,模型的效率可以率先突围。这或许是在当前复杂产业环境下,一条更为务实和可持续的发展路径。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

千问模型如何优化智能推荐系统的内容理解模块
推荐系统常因语义、多模态和意图理解不足产生偏差。通义千问系列模型可针对性补强:通过轻量模型重排序提升相关性,多模态模型确保图文匹配,指令模型解析用户行为提炼兴趣标签,OCR提取图像文字,并结合PID控制算法动态融合多源信息,依据实时反馈自动优化权重。

Claude与Cursor通用技能编写指南与资源获取
你是否厌倦了为每个项目手动编写冗长的 cursorrules 文件?或者每次开启新的AI编程会话,都要把同一套开发规范重复粘贴一遍?现在,是时候深入了解 Agent Skill 这项革命性技术了。 这项由 Anthropic 在 2025 年 10 月推出、并于同年 12 月作为开放标准发布的机制

面壁智能开源BitCPM-CANN:国产算力实现1.58比特训练,推理显存节省六分之五
2026年,AI专用HBM内存价格暴涨超过165%,显存 HBM正成为模型扩展最昂贵、最稀缺的资源之一,模型公司的核心推理成本居高不下。 与此同时,高端AI芯片对华出口管制政策反复,让国产算力生态在面临高昂“过路费”与供应链安全风险的双重夹击下艰难求生。 这两件事叠加,共同指向一个核心问题:在硬件条

AI全栈开发实战指南:模块化思维与前后端项目落地
在当今技术快速演进的背景下,若开发者仍局限于前端或后端单一领域,可能难以把握市场机遇。技术融合已成为明确趋势,特别是AI能力向实际业务场景的渗透,催生了市场对“AI全栈工程师”的迫切需求。这并非简单叠加前端、后端与AI知识,而是要求开发者具备贯通用户界面、业务逻辑、数据持久化及智能算法全链路的能力,

Claude代码操作必知的五个高效技巧
大多数人用Claude Code的方式,是不是都这样:打开终端,敲需求,等结果,出错了就纠正,纠正完继续改。三个月过去了,操作习惯还停在第一天。 问题其实不在工具本身。你的CLAUDE md配置文件可能已经写得相当完善了——技术栈、编码规范、禁止事项都列得清清楚楚。但真正决定效率的,往往是那些没人提








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
