




C++ CUDA Tile 高性能 GPU 内核开发指南

对于长期使用CUDA进行GPU编程的开发者来说,一个好消息是:现在,你可以在现有的大型C++ GPU代码库中,直接使用NVIDIA CUDA Tile编程模型来开发高度优化的内核了。
这项能力随着CUDA 13.3的发布而到来。回想一下,CUDA Tile最初在CUDA 13.1中引入,它为GPU带来了基于“分块”(Tile)的编程范式。其设计包含一个顶层语言层和一个中间层,任何高级编程语言都可以以其为目标。它的妙处在于,能够自动利用NVIDIA硬件的先进特性——比如张量核心、共享内存和内存翻跟斗——而无需应用程序直接针对它们进行繁琐的底层编码。
最初,Python是首个支持分块GPU应用的语言。而新发布的CUDA 13.3,则增加了对C++编写分块内核的支持,这让开发者构建高度优化的GPU内核如虎添翼。
什么是CUDA Tile C++?
简单来说,CUDA Tile C++是CUDA Tile编程模型在C++中的实现,它构建在CUDA Tile IR规范之上。它允许开发者用C++编写分块内核,并使用基于“分块”的模型来表达GPU内核,这可以作为传统单指令多线程(SIMT)模型的一种补充或替代。
我们来快速回顾一下分块模型的核心概念:
- 多维数组是主要的数据存储单元。
- 分块(Tile)是数组中被内核操作的部分。
- 内核(Kernel)是由多个块(Block)并行执行的函数。
- 块(Block)是GPU的子集;对分块的操作会在每个块内的所有线程间并行化。
CUDA Tile C++的便利之处在于,它自动处理了块内的并行性、异步操作、内存移动等GPU编程中的底层细节。更重要的是,它具备跨不同NVIDIA GPU架构的移植性,这意味着开发者无需重写代码,就能利用最新硬件的特性。
从向量加法看CUDA Tile C++
熟悉CUDA C++ SIMT编程的开发者,肯定都写过经典的向量加法内核。假设数据已在GPU上,一个SIMT风格的向量加法内核接收两个向量,进行逐元素相加,并输出第三个向量。这是最简单的CUDA内核之一,代码通常长这样:
__global__ void vecAdd(float* A, float* B, float* C, int vectorLength){
int workIndex = threadIdx.x + blockIdx.x*blockDim.x;
if(workIndex < vectorLength) {
C[workIndex] = A[workIndex] + B[workIndex];
}
}在这个内核中,每个线程的工作被显式指定,程序员在启动内核时,还需要明确指定要启动的块和线程数量。
那么,用CUDA Tile C++编写的等效代码是怎样的呢?最大的区别在于,你不再需要指定每个线程具体做什么。你只需要将数据分解成块(Tile),并指定对这些块进行何种数学运算即可,其他的一切都由框架自动处理。
下面是一个完整的CUDA Tile C++向量加法内核示例,它详细展示了每一步:
#include "cuda_tile.h"
__tile_global__ void vectorAdd(float* a, float* b, float* out, size_t n) {
namespace ct = cuda::tiles;
using namespace ct::literals;
auto aSpan = ct::tensor_span{a, ct::extents{n}};
auto bSpan = ct::tensor_span{b, ct::extents{n}};
auto oSpan = ct::tensor_span{out, ct::extents{n}};
auto aView = ct::partition_view{aSpan, ct::shape{8_ic}};
auto bView = ct::partition_view{bSpan, ct::shape{8_ic}};
auto oView = ct::partition_view{oSpan, ct::shape{8_ic}};
int bx = ct::bid().x;
auto aTile = aView.load(bx);
auto bTile = bView.load(bx);
auto oTile = aTile + bTile;
oView.store(oTile, bx);
}乍一看,为了一个简单的向量加法写这么多代码,似乎有点“杀鸡用牛刀”。别担心,上面这个版本是为了清晰展示所有步骤。实际上,我们可以把它写得更简洁。我们来拆解一下关键部分:
- 内核声明:使用
__tile_global__来告诉编译器这是一个分块内核。参数传递和SIMT内核类似。 - 命名空间:设置
cuda::tiles命名空间及其字面量,方便使用编译时常量(如8_ic)。 - 创建张量跨度:使用
ct::tensor_span为每个数组创建跨度。它类似于C++23的std::mdspan,封装了指向多维数组的指针及其形状(维度)和布局信息。ct::extents{n}指明这是一个大小为n的一维数组。 - 创建分区视图:通过
ct::partition_view将张量跨度包装为一系列不重叠的、固定大小的分区。这里的ct::shape{8_ic}指定每个分区(即分块)的大小为8。 - 加载输入分块:通过
ct::bid().x获取当前块在X维度的索引,然后使用分区视图的load函数,自动获取并加载对应索引的数据块到分块对象中。 - 计算与存储:直接对分块对象进行逐元素加法运算,结果存储到输出分块,最后用
store函数写回对应的分区视图。
可以看到,计算逻辑(aTile + bTile)变得异常简洁,而数据移动和索引管理的复杂性被隐藏了起来。
完整的向量加法示例与优化
下面是一个完整、可运行的C++代码示例,展示了如何调用上述内核,并融入了一些关键的编译器优化提示:
#include
#include
#include "cuda_tile.h"
__tile_global__ void vectorAdd(float* __restrict__ a, float* __restrict__ b,
float* __restrict__ out, size_t n) {
namespace ct = cuda::tiles;
using namespace ct::literals;
a = ct::assume_aligned(a, 16_ic);
b = ct::assume_aligned(b, 16_ic);
out = ct::assume_aligned(out, 16_ic);
int bx = ct::bid().x;
auto aTile = ct::partition_view{ct::tensor_span{a, ct::extents{n}}, ct::shape{1024_ic}}.load_masked(bx);
auto bTile = ct::partition_view{ct::tensor_span{b, ct::extents{n}}, ct::shape{1024_ic}}.load_masked(bx);
auto oTile = aTile + bTile;
auto oView = ct::partition_view{ct::tensor_span{out, ct::extents{n}}, ct::shape{1024_ic}};
oView.store_masked(oTile, bx);
}
// ... (错误检查宏和main函数,包含主机端内存分配、初始化、数据拷贝等)
int main() {
constexpr size_t N = 2ULL << 25;
constexpr int TILE_SIZE = 1024;
constexpr int BLOCKS = (N + TILE_SIZE - 1) / TILE_SIZE;
// ... 主机和设备内存分配、初始化、数据拷贝代码 ...
// 启动内核
vectorAdd<<>>(d_a, d_b, d_out, N);
// ... 同步设备、检查错误、验证结果、清理资源 ...
} 这个版本做了几处重要优化:
- 使用
__restrict__:告知编译器指针之间没有别名,有助于生成更优的代码。 - 内存对齐提示:通过
ct::assume_aligned<16>告诉编译器指针是16字节对齐的(cudaMalloc分配的内存默认256字节对齐,满足此条件),以生成更高效的内存访问指令。 - 更大的分块尺寸:使用了1024作为分块大小,而非之前的8,以提升效率。
- 掩码加载/存储:使用
load_masked和store_masked来处理数据大小不能被分块尺寸整除的情况,保证边界安全。
对于熟悉启动SIMT内核的开发者,启动分块内核的过程类似,但有一个关键区别:
vectorAdd<<>>(d_a, d_b, d_out, N); 启动配置 << 中,第一个参数是分块块的数量(对应于SIMT中的线程块数量)。第二个参数必须固定为1。用于执行内核的线程数由编译器决定,因此在启动分块内核时,第二个维度始终设为1。
在CUDA 13.3或更高版本上,使用计算能力8.0(Ampere架构)或更新的GPU,用以下命令编译和运行:
$ nvcc -std=c++20 --enable-tile -arch sm_80 -o vectorAdd vectorAdd.cu
$ ./vectorAdd
N: 67108864
Max error: 0.000000e+00至此,你的第一个CUDA Tile C++程序就成功运行了。
开发者工具支持
分块C++内核可以像SIMT内核一样,使用NVIDIA Nsight Compute进行性能剖析。以下命令展示了如何创建剖析文件:
$ ncu -o VecAddProfile --set detailed ./vectorAdd在Nsight Compute的图形界面中打开生成的报告后:
- 从下拉菜单中选择
vectorAdd内核。 - 选择 Details 标签页。
- 展开 Tile Statistics 报告部分。
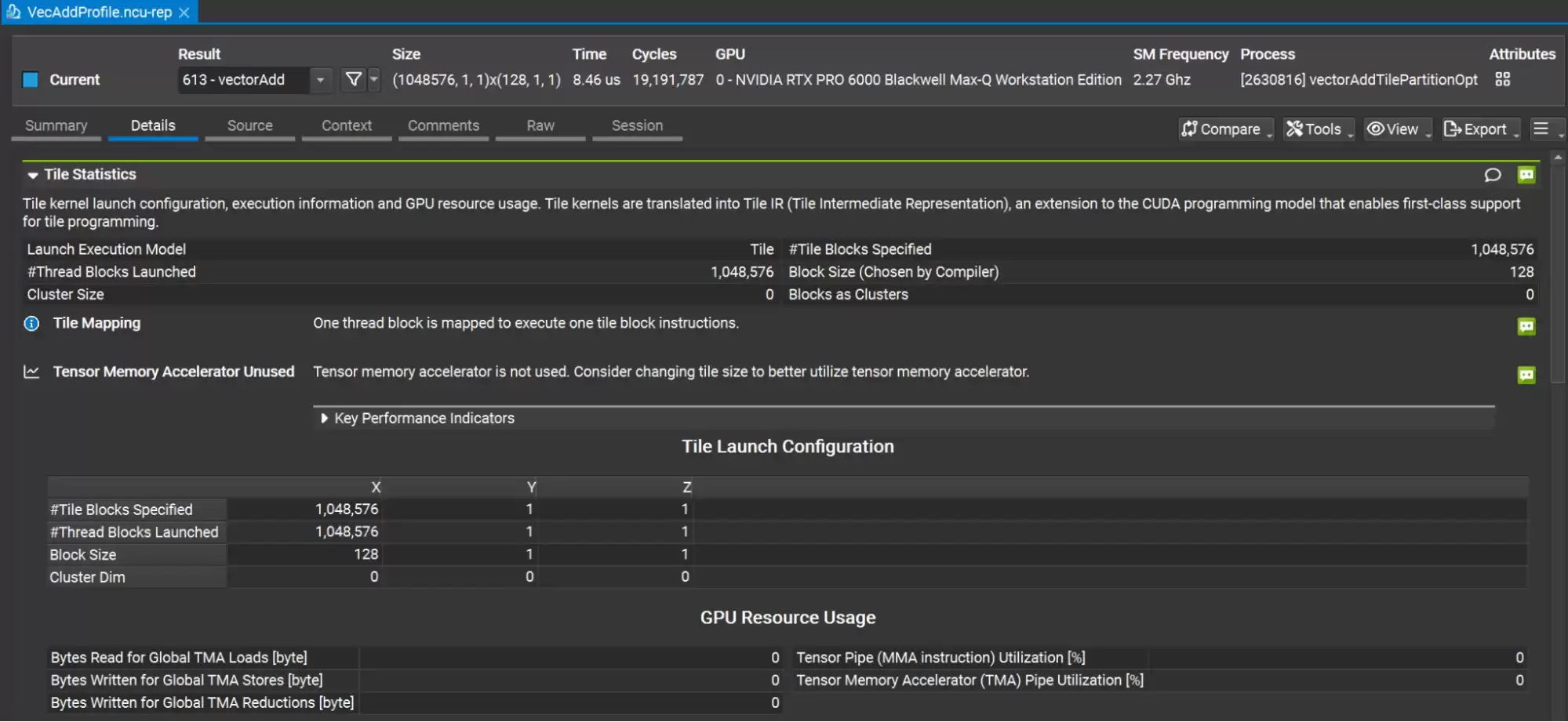
在 Tile Statistics 部分,你可以看到指定的分块块数量、编译器选择的块大小以及其他分块特有的信息。源码页面同样支持分块内核,可以像CUDA C++内核一样查看源码行级别的性能指标。
矩阵乘法示例
向量加法的例子详细展示了加载和存储分区视图的细节。下面这个矩阵乘法示例则能更好地体现如何用简洁的代码表达复杂计算。
这个内核计算一个MxK矩阵与一个KxN矩阵的乘积,得到MxN矩阵。本例中M=8,N=16,K可以是变量(只要它是8的倍数),这里设K=24。使用小尺寸仅是为了演示概念。
#include "cuda_tile.h"
__tile_global__ void kernel(float* __restrict__ a, float* __restrict__ b,
size_t length, float* __restrict__ c) {
namespace ct = cuda::tiles;
using namespace ct::literals;
a = ct::assume_aligned(a, 16_ic);
b = ct::assume_aligned(b, 16_ic);
c = ct::assume_aligned(c, 16_ic);
auto aShape = ct::extents{8_ic, length};
auto bShape = ct::extents{length, 16_ic};
auto cShape = ct::extents{8_ic, 16_ic};
auto aSpan = ct::tensor_span{a, aShape};
auto bSpan = ct::tensor_span{b, bShape};
auto cSpan = ct::tensor_span{c, cShape};
auto aView = ct::partition_view{aSpan, ct::shape{4_ic, 8_ic}};
auto bView = ct::partition_view{bSpan, ct::shape{8_ic, 4_ic}};
auto cView = ct::partition_view{cSpan, ct::shape{4_ic, 4_ic}};
using f32x4x4 = ct::tile>;
auto accTile = ct::full(0);
auto [xBlock, yBlock, dummy] = ct::bid();
for (auto idx : ct::irange(0, 1 + int(length - 1) / 8)) {
auto aTile = aView.load_masked(xBlock, idx);
auto bTile = bView.load_masked(idx, yBlock);
accTile = ct::mma(aTile, bTile, accTile);
}
cView.store_masked(accTile, xBlock, yBlock);
} 这个内核的核心步骤可以概括为:
- 定义矩阵形状:为输入输出矩阵创建
ct::extents对象。 - 创建张量跨度:基于形状和原始指针创建张量跨度。
- 创建分区视图:为矩阵创建分区视图。例如,将8x24的A矩阵划分为4x8的分块视图,将24x16的B矩阵划分为8x4的视图。这决定了C矩阵的视图是4x4的。
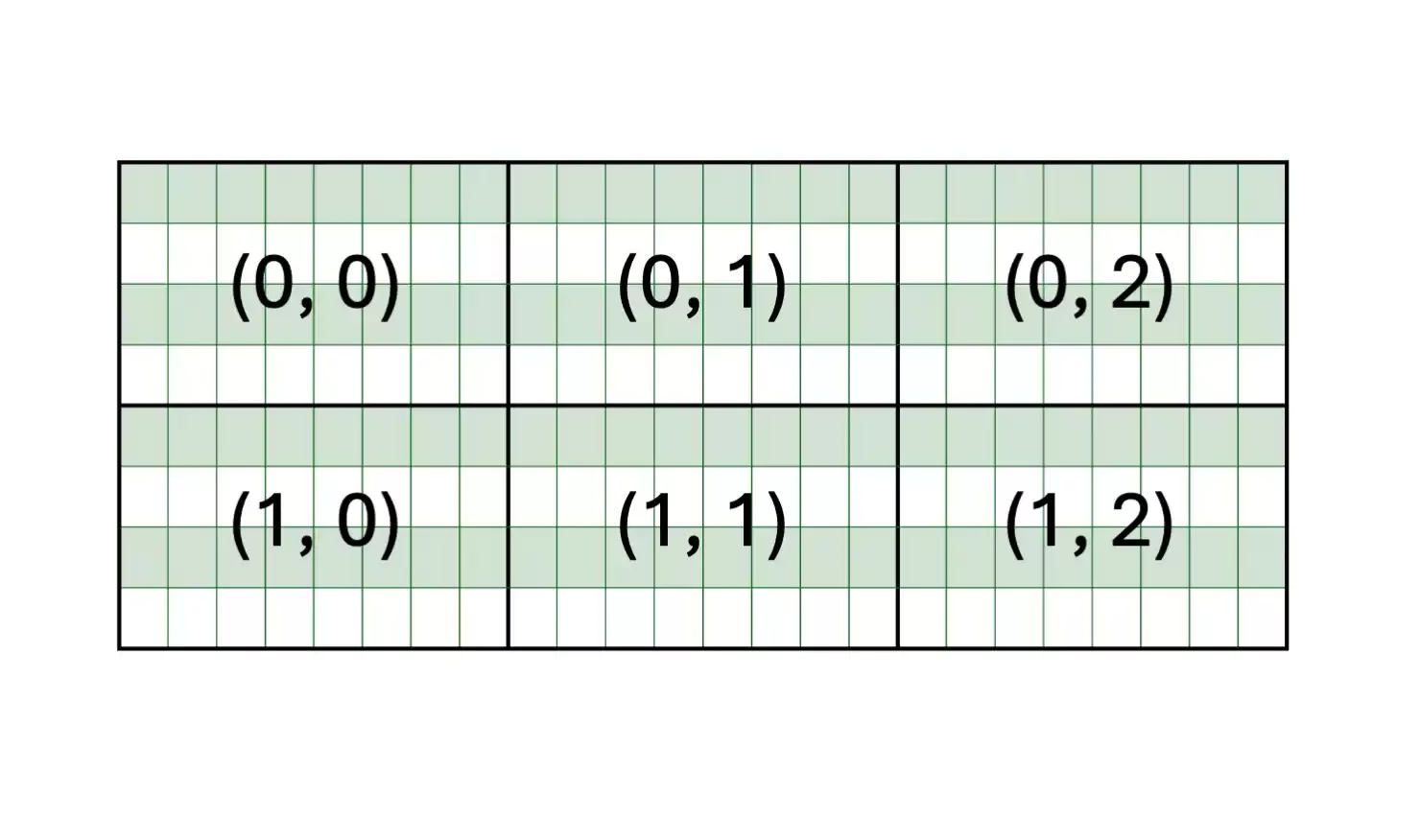
- 初始化累加分块:创建一个与C视图形状匹配的4x4分块,用于累加计算结果。
- 执行计算循环:获取当前块在网格中的二维索引。循环遍历K维度(除以8,与A、B视图的K维度匹配)。在循环内,加载A和B的对应分块,调用
ct::mma(矩阵乘加)函数进行计算并累加。 - 存储结果:将累加结果分块存储到C的对应分区视图中。
值得注意的是,内核中大部分代码用于设置数据视图和加载/存储数据,而真正的计算部分(ct::mma)非常简洁。
启动内核:由于C矩阵是8x16,而每个块计算一个4x4的分块,因此需要在X维度启动2个块(8/4),在Y维度启动4个块(16/4)。
kernel<<>>(d_a, d_b, K, d_c); 开始使用CUDA Tile C++
要运行CUDA Tile C++程序,你需要满足以下条件:
- 计算能力为8.x或更新的GPU。
- NVIDIA R580或更高版本的驱动程序。如果分块内核需要JIT编译,则驱动程序版本必须等于或高于用于生成代码的CUDA工具包所对应的版本。例如,CUDA Toolkit 13.3需要R610或更新的驱动。
- CUDA Toolkit 13.3。
分块编程的强大能力现已向C++开发者开放。查阅相关文档、API参考手册,并下载CUDA Toolkit 13.3,立即开始编写你的分块C++内核,亲身体验加速计算的新标准。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Red Hat技能包赋予AI智能体20年企业运维经验
RedHat发布专属AI技能库,基于检索增强生成技术与智能体结合,将二十年企业运维经验注入AI。智能体技能包封装任务理解、规划与防护规则,可在RHEL、OpenShift和Ansible上执行CVE查询、补丁建议等操作,受订阅与安全策略约束,实现受治理的超级用户目标。

谷歌AI摘要频现拼写错误 大模型固有硬伤遭曝光
这事儿说来也怪——能编写代码、解答复杂数学题的尖端AI,一到基础拼写这种幼儿园级别的问题上,反倒频频出错。谷歌最近升级的AI摘要功能(AI Overview)就因为一堆低级拼写错误,再次成为科技圈热议的笑柄。公开测试中,它不仅无法准确统计单词中的字母数量,甚至连自己的品牌名“Google”都拼写错误

夸克AI自动生成PPT演讲稿及每页备注
夸克AI提供四种自动生成PPT演讲稿与备注的路径:在编辑界面一键生成全部页备注、通过AI助手对话指令批量生成讲稿、从已导出的PPTX文件反向提取并生成备注、利用网页内容同步生成PPT与配套备注,覆盖不同工作场景。

如何实现私有代码库的许愿驱动开发体验
通过构建包含背景价值观、行为规范及偏好设置的万字提示词框架,使AI在私有代码库中实现理解架构哲学并主动协作,从被动执行转变为具备架构直觉的专业伙伴,恢复许愿式开发体验。

海螺AI Citypop创作指南:解决MiniMax无法生成特定城市曲风
生成特定城市曲风的Citypop音乐常因未将城市意象转化为声学参数而失败。通过MiniMaxM1Chat提取城市声景语义标签,在海螺AI中构建城市-节奏-音色三维绑定,启用Citypop专用微调权重,最后用剪映实现音画耦合,可精准还原城市霓虹质感。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
