




探索大型语言模型高效学习方法

大型语言模型的高效学习方法围绕模型、数据和框架三个维度展开。模型层面包括量化、剪枝、知识蒸馏等压缩技术及高效训练推理结构;数据层面涉及数据筛选与提示工程;框架层面依托DeepSpeed、Megatron等系统支撑。这些技术旨在降低资源消耗,推动模型实际落地。
大型语言模型(LLMs,简称大语言模型)无疑是近年来自然语言处理领域中最受瞩目的技术突破。从GPT系列到PaLM,从LLaMA到GLM,这类大模型所展现出的涌现能力令人惊叹。然而,它们的成功在很大程度上依赖于海量的参数规模和惊人的计算资源消耗。这就引出了一个核心挑战:模型越强大,对硬件性能的要求就越苛刻,从而导致部署与落地的难度不断上升。如何让这些“庞然大物”在维持卓越性能的同时,变得更加“轻量级”和“高效节能”,已经成为当前整个AI领域最紧迫的研究课题之一。
今天要介绍的这篇综述论文,正是对这一热点问题的系统性梳理。它聚焦于如何提升LLMs的运行效率,并提供了一个全景式的分析框架。文章首先明确了模型规模持续增长所带来的核心困境——传统的训练方法已经难以应对日益增长的资源需求。随后,它从三个关键维度——以模型为中心、以数据为中心、以框架为中心——对现有的高效技术进行了组织与归纳。在模型层面,涵盖了量化、剪枝、低秩近似、知识蒸馏等压缩方法,以及高效的训练与推理结构设计;在数据层面,探讨了数据筛选策略与提示工程方法;最后,还盘点了支撑这些技术落地的核心软件框架。本文的目标非常明确:旨在为研究人员和从业者提供一份全面且实用的“大模型效率提升指南”,期望能够启发更多有价值的探索与创新。
下面,我们将严格按照这三个维度,逐一拆解其中的关键技术思路。
以模型为中心
这是最直接、最直观的优化方向,核心目标是从模型本身入手,使其运行更快、资源消耗更少。具体可以拆解为模型压缩、高效预训练、高效微调、高效推理以及高效结构设计等多个环节。
模型压缩
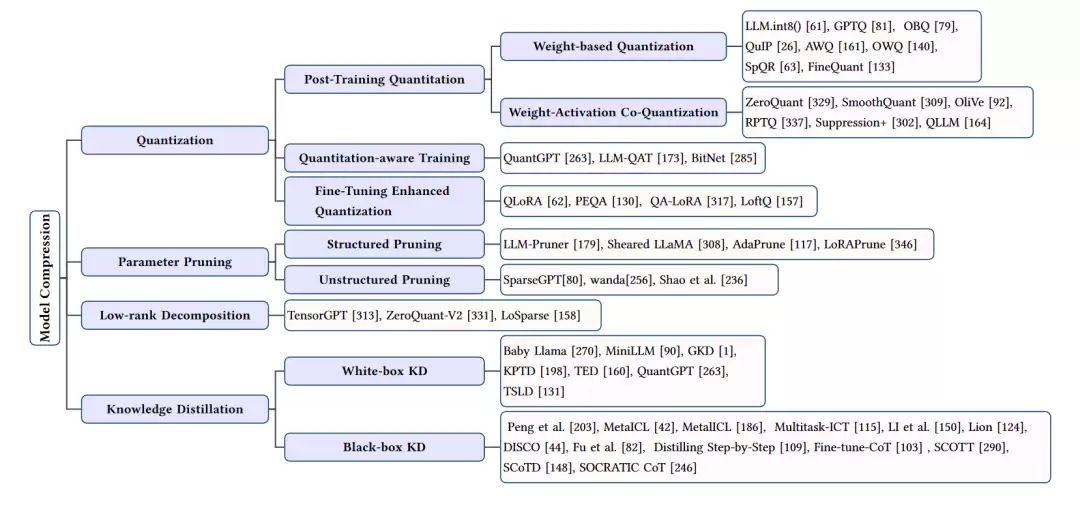
模型压缩的目标非常明确:在尽可能不牺牲性能的前提下,为模型“瘦身减重”。主要技术手段包括以下几种。
量化
简而言之,量化技术就是使用更少的比特数来表示模型中的权重和激活值。从常见的FP32精度降低到INT8甚至更低的精度,计算和存储的开销自然会显著下降。当然,精度降低可能会带来一定的性能损失。为了在压缩率与模型性能之间找到最佳平衡点,研究者开发了多种技术,例如动态范围量化(DRQ)和知识蒸馏量化(KDQ)等。
参数修剪
这种方法类似于给一棵大树修剪冗余的枝叶,直接“剪掉”模型中那些不重要的参数。修剪分为两种类型:结构化剪枝(直接整行或整列移除参数)和非结构化剪枝(逐个移除单个参数)。其中的关键问题是:如何准确判断哪些参数是“不重要”的?基于敏感度的剪枝方法、低秩分解技术等,正是为了解决这一判断难题,力求实现压缩率与模型性能的最优平衡。
低秩逼近
这种技术的核心思想是:用一个结构更简单的低秩矩阵去近似一个复杂的高秩矩阵。这种方法能够显著降低矩阵运算的计算复杂度。常见的实现方式包括矩阵分解、核方法等。为了保持模型精度,研究者还引入了迭代训练、低秩补偿等优化策略。
知识蒸馏
这是一种典型的“师生模式”。由一个性能强悍的大规模模型(教师模型)来指导一个结构更简单的小模型(学生模型)进行学习。学生模型的目标是模仿教师模型的行为模式,从而“继承”其强大的能力。蒸馏过程既可以是白盒的(利用教师模型的内部中间层信息),也可以是黑盒的(仅利用输入输出对进行学习)。多任务学习、多阶段训练等技巧可以进一步提升蒸馏效果。
高效预训练
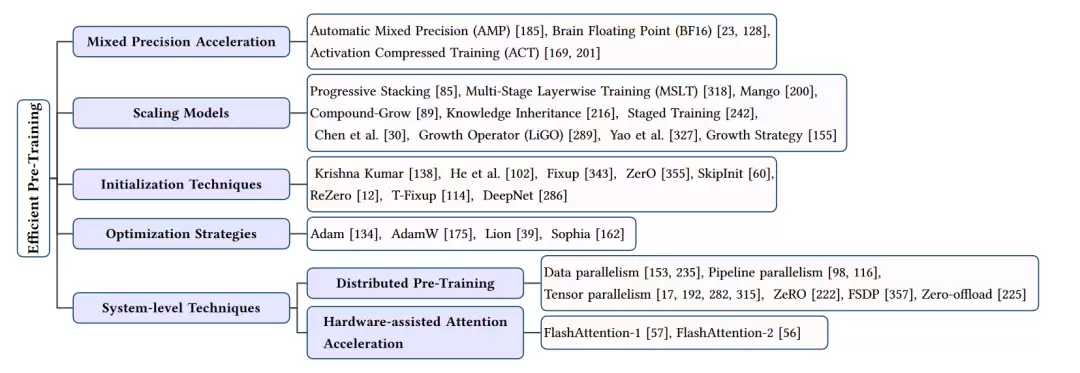
预训练是LLMs能力的基石,但也是整个流程中计算资源消耗最大的环节。如何为这个环节“减负增效”?主要思路集中在以下四个方面。
混合精度加速
利用FP16或BF16这类低精度数据类型执行大部分计算,只在必要时才回退到FP32精度。这种方法能显著降低内存占用和计算量,已经成为当前主流训练的标配。自动混合精度(AMP)和BF16技术是其典型代表。
模型缩放
既然直接训练超大模型非常困难,那么不妨先从小规模模型开始训练,然后逐步“长大”。渐进式堆叠、多阶段层训练(MSLT)等方法正是遵循这一思路。它们通过在训练过程中逐步增加模型的深度或宽度,使得大模型能够站在小模型的“肩膀”上更快地收敛。知识继承技术也属于这一范畴。
初始化技术
一个好的起点往往能带来事半功倍的效果。特殊的初始化方法,例如函数保留初始化(FPI)和高级知识初始化(AKI),旨在为大型模型的训练提供一个更有利的初始状态,从而加速收敛过程,有时甚至能提升最终模型的性能。
优化策略
传统的AdamW优化器虽然效果不错,但其效率仍有提升空间。像Lion和Sophia这类新型优化器,通过调整学习率策略或引入二阶梯度信息,在减少计算量和内存占用的同时,实现了更快的收敛速度。此外,数据并行、流水线并行、张量并行等分布式训练技术,也是从系统层面加速预训练流程的关键手段。
高效微调
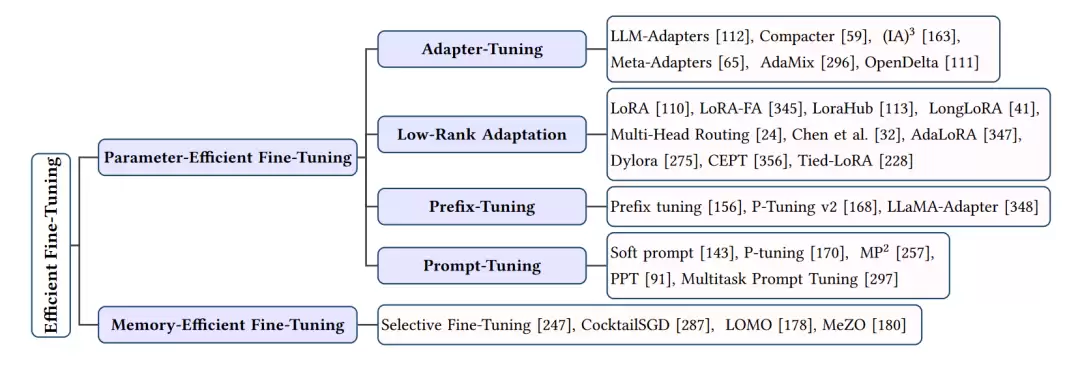
为了使一个通用大模型适配特定任务,全量微调的成本实在太高。于是,一系列“低成本”微调方案应运而生,主要分为参数高效微调和内存高效微调两类。
参数高效微调
这类方法只更新极少数模型参数,就能达到与全量微调相近的出色效果。
- 适配器调优: 在Transformer层内部或侧面插入一个体积很小的“适配器”模块,微调时只更新这个模块的参数。典型技术包括LLM-Adapters、Compacter以及(IA)³等。
- 低秩适应(LoRA): 这是当前最热门的微调方案之一。它通过两个低秩矩阵的乘积来近似权重的更新量,微调时只优化这两个小矩阵。LoRA及其变体(例如LoRA-FA、LongLoRA)在显著减少可训练参数量的同时,依然保持了出色的性能。
- 前缀调优: 在模型每一层的输入前面,添加一组可训练的“虚拟”Token(即前缀)。通过优化这些前缀,可以引导模型针对特定任务输出正确结果。代表技术有Prefix Tuning、P-Tuning v2以及LLaMA-Adapter。
内存高效微调
这类方法侧重于降低微调过程中的显存占用。
- 选择性微调: 与其更新所有层,不如只更新一小部分中间层激活。Selective Fine-Tuning、CocktailSGD、LOMO等方法便是这一思路的具体实践。
- 分阶段微调: 将微调过程拆分成多个阶段,每个阶段只更新模型的一部分参数。这种方法同样能有效控制峰值内存占用,Staged Training和MeZO是其代表技术。
高效推理
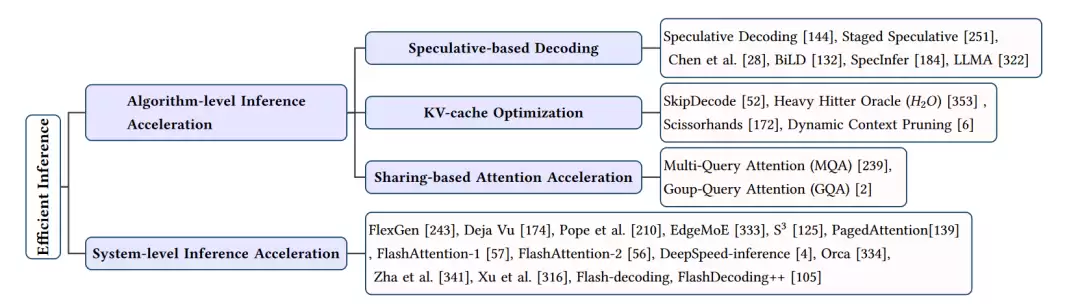
模型训练完成后,在实际部署中如何让它响应更快、运行成本更低?这就要依赖高效的推理技巧。这些技巧通常可分为算法层面和系统层面。
算法层面
- 投机解码: 核心思想是“以小博大”。首先用一个速度很快的“草稿”小模型生成候选结果,然后让大模型并行地验证这些结果。由于验证过程可以批量处理,整体推理速度往往比大模型逐个Token生成要快得多。
- KV-Cache优化: 在自回归生成过程中,需要反复计算并缓存Key-Value矩阵。KV-Cache优化的目标就是减少这个缓存的大小和计算开销。例如,SkipDecode和Heavy Hitter Oracle尝试跳过不那么重要的中间层计算;Dynamic Context Pruning和Scissorhands则动态地剪掉次要的KV-Cache Token。
- 分享式注意力加速: 在多头注意力机制中,让不同的注意力头共享同一组K和V矩阵。典型代表是多查询注意力(MQA)和分组查询注意力(GQA),它们用微小的性能下降换来了推理速度的显著提升。
系统层面
这部分关注的是如何在硬件和软件系统层面进行优化。
- FlexGen: 一个专为显存受限GPU设计的高吞吐量推理引擎。它巧妙地结合了CPU、GPU甚至磁盘的算力与内存资源,并通过线性编程搜索来优化资源分配。
- Deja Vu: 利用“上下文稀疏性”(即很多注意力计算是冗余的)这一发现,训练一个预测器来提前跳过不必要的计算,并结合内核融合等技术实现加速。
- EdgeMoE: 专为设备端推理设计的系统,基于混合专家(MoE)结构。通过将不同的专家模型分配到不同的存储层级,实现了高效的资源利用。
- S3: 通过预测输出序列的长度,并根据预测结果来规划和批处理推理请求,从而提高设备利用率。
- PagedAttention: 灵感来源于操作系统的虚拟内存分页技术。它将KV-Cache管理成不连续的块(Page),使得不同请求之间的KV-Cache可以高效共享,显著降低内存碎片,提升吞吐量。
- FlashAttention: 通过将矩阵乘法和Softmax操作融合,并利用硬件优化,实现了对标准注意力机制的高效加速。它无需频繁读写中间结果到显存,是加速长序列推理的关键技术。
高效结构
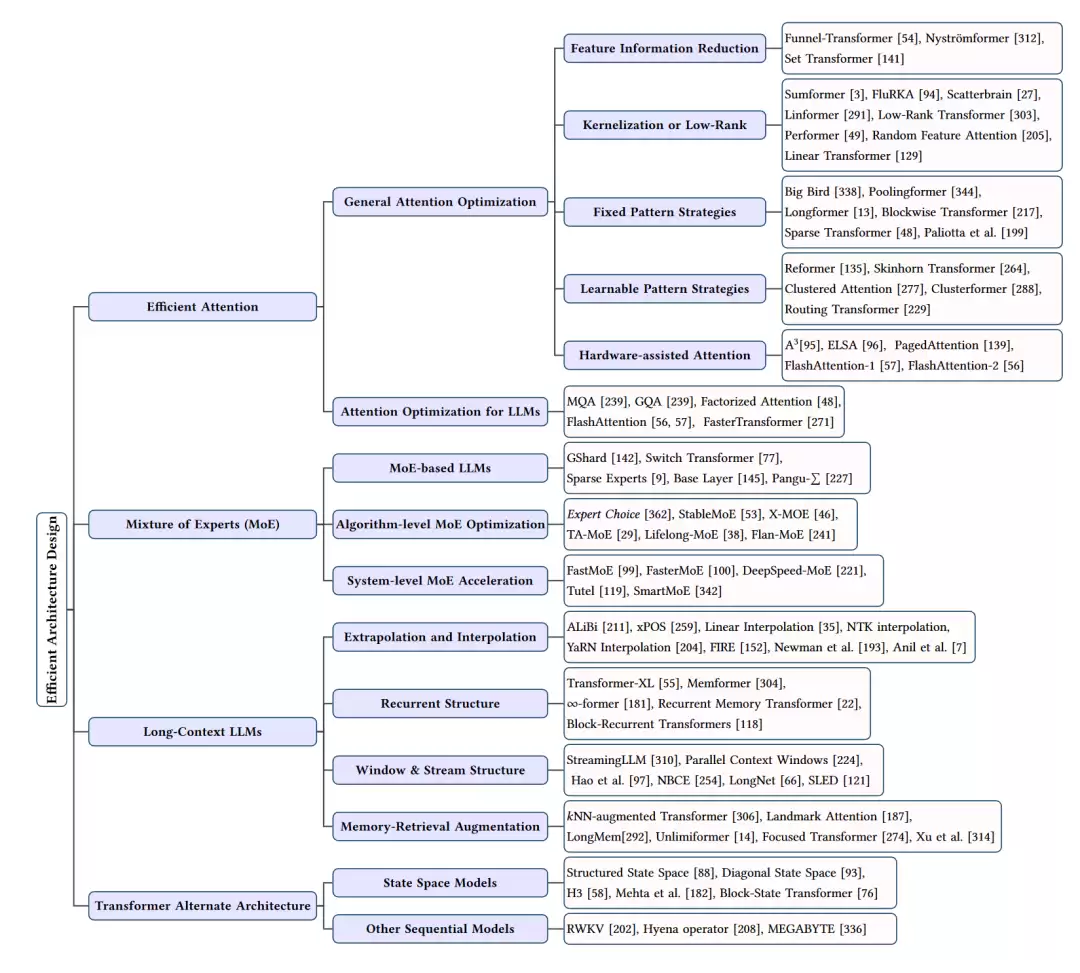
除了在现有架构上修修补补,设计全新的高效架构也是一个重要方向。这主要围绕注意力机制的优化和全新的模型结构展开。
注意力优化
自注意力机制是Transformer的核心,但其计算复杂度与序列长度的平方成正比。为了突破这一瓶颈,研究者想出了各种办法。
- 特征信息缩减: 通过池化或下采样来减少序列长度。
- 核化或低秩: 用低秩近似或核技巧来逼近注意力矩阵。
- 固定模式策略: 强制注意力只关注局部窗口或固定间隔的位置,实现稀疏化。
- 可学习模式策略: 让模型自己学习要关注哪些位置,例如通过聚类算法。
- 硬件辅助注意力: 通过定制硬件或系统级优化(如PagedAttention)来加速计算。
混合专家(MoE)模型
MoE的核心思想是“术业有专攻”。它将一个大模型拆分成多个专家网络,每个专家专注于处理一部分数据。推理时,一个门控网络会根据输入决定激活哪些专家。这样,虽然模型的总参数量可以非常大,但每次推理的计算量只取决于被激活的专家数量。GShard、Switch Transformer是典型的MoE架构。
长上下文LLMs
处理超长序列是LLMs的一个重要能力。除了优化注意力,还有几种解决思路:
- 外推和插值: 设计更好的位置编码,让模型能处理比训练时更长的序列。
- 循环结构: 引入记忆单元或循环机制,让模型能处理无限长的序列。
- 窗口和流结构: 使用滑动窗口或流式处理,让模型只关注近期的上下文。
- 记忆检索增强: 通过一个外部的显式记忆库来检索相关历史信息。
Transformer替代结构
完全抛弃Transformer的自注意力机制,寻找更高效的序列建模替代方案。
- 状态空间模型(SSM): 如S4、DSS,它们用状态空间模型替代自注意力,实现了近线性的计算复杂度。
- 其他序列模型: 如RWKV、Hyena Operator,它们融合了RNN和Transformer的优点,兼顾效率和长程依赖建模能力。
以数据为中心
这一维度强调的是,数据和输入方式本身对模型效率有着重要影响。
数据选择

训练模型所用的数据质量,有时甚至比模型本身的设计更加关键。高效的数据选择策略能降低训练成本,提升模型的泛化能力。
- 高效预训练数据选择: 核心是“少而精”。通过数据清洗(去噪、去重)、数据平衡、数据增强(如同义替换)、领域自适应等方法,构建高质量的精炼预训练语料库。
- 高效微调数据选择: 目标是为特定任务找到最优的少量训练数据。关键在于任务相关性、数据筛选(选择最具代表性的样本)、在线学习(动态调整数据)以及少样本学习技术。
- 其他技巧: 例如示范选择(挑选与任务最相关的示例进行提示学习)、示范组织(合理安排示例顺序)、模板格式化(设计清晰的任务输入格式)等,都能在不增加训练量的情况下提升模型表现。
提示工程
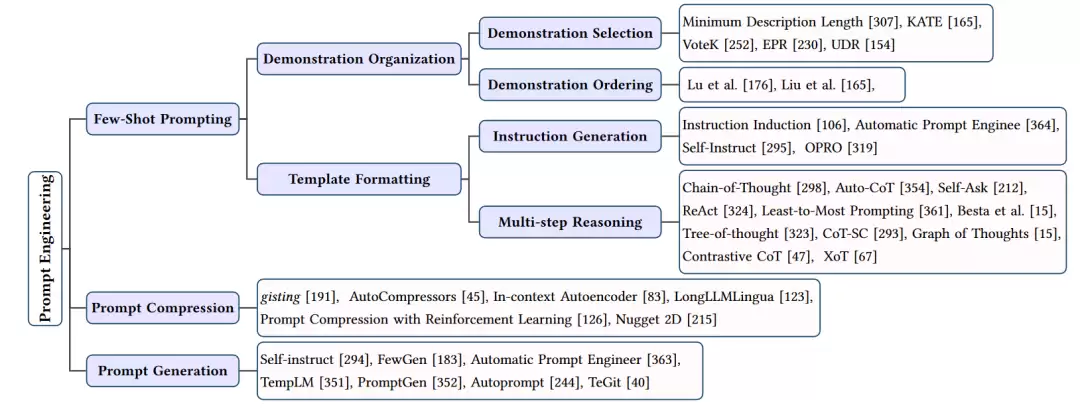
提示工程是当前与LLMs交互最主要的方式。一个好的提示,能让模型充分发挥出其“隐藏”的能力。
- 少样本提示: 在提示中给出几个输入输出示例(即示范),模型就能“照猫画虎”地完成新任务。关键在于如何选择和排列这些示例。
- 提示压缩: 为了降低长提示带来的计算成本,需要对提示进行压缩。方法包括提取摘要、转换为压缩向量、设计结构化的提示格式。
- 提示生成: 手动设计提示费时费力,能否让模型自己生成提示?自我指导(让模型根据自身输出反推提示)和强化学习(让模型与环境交互,根据反馈优化提示)是两种可行的路径。
以框架为中心

工欲善其事,必先利其器。有了高效的模型和数据策略,还需要一个强大的软件框架来承载和实现这一切。以下是几个代表性的框架。
- DeepSpeed(微软): 一个功能全面的框架,集成了ZeRO系列优化、数据并行、模型并行、流水线并行等多种技术,其ZeRO-Inference模块专门用于解决GPU显存不足的问题。
- Megatron(NVIDIA & 微软): 专注于模型并行,其核心技术是精细地分解模型张量操作,并将其分布到多个GPU上,极大提升了大规模模型的训练和推理效率。
- Alpa: 一个强调“自动并行”的框架。它能自动分析模型结构和计算图,并搜索出最佳的并行策略(包括数据、模型、流水线并行),从而简化了手动调优的复杂过程。
- ColossalAI: 另一个面向大规模并行训练的框架,同样集成了多种并行技术和优化方法,并以其模块化设计和用户友好的工具而著称。
- Hugging Face Transformers: 业界最流行的开源模型库,它最大的优势在于易用性和模型丰富性。虽然不像前几个框架那样专注于底层并行优化,但它提供了大量预训练模型和高效的部署API,极大降低了LLMs的应用门槛。
结语
这篇文章全景式地梳理了大型语言模型的高效学习方法。从模型层面的压缩、高效预训练与推理,到数据层面的筛选与提示工程,再到支撑这一切的软件框架,可以看到,解决LLMs的“效率危机”需要多管齐下、协同发力。这些技术共同构成了一个强大的工具箱,使得这些庞然大物能够在更多实际场景中得到落地应用。
当然,挑战依然存在。如何在压缩和加速的同时,最大程度地保留甚至提升模型性能?如何让这些技术自动适应千变万化的任务需求?这些都是未来研究需要持续探索的方向。但毫无疑问,对这一领域的持续投入,将是推动自然语言处理技术和人工智能走向更广泛应用的关键动力。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:探索大型语言模型高效学习方法要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点OmniParser是微软AI驱动的SaaS工具,基于YOLOv8和BLIP-2,将UI截图与漫画页面解析为结构化数据,支持UI元素检测、漫画面板分析、对话框及人脸识别,适用于自动化测试、漫画翻译等场景。
通义灵码是贯穿开发全流程的智能编码助手,具备代码智能生成、研发智能问答、多编程语言及编辑器支持、代码安全隐私保障四大核心能力,适用于学生、新手及企业开发者等多类人群,提升编码效率。
基于人工智能的自动化道路巡逻和资产数据收集方案,通过车载相机自动采集路面及周边资产数据,识别裂缝、坑槽等病害并建立数字化台账,同时自动删除隐私图像,实现从被动响应向主动预防的转变,降低巡检成本。
阿里旗下通义智文是一款智能阅读工具,支持网页、论文、图书和自由阅读四种场景,帮助用户快速提取核心观点,节省阅读时间,适合学生、研究人员及职场人士高效处理大量文本。
- 日榜
- 周榜
- 月榜
热点快看