




结构化RAG约束JSON响应格式提升AI系统成功率82.55%

最近,不少朋友在折腾 Dify、Coze、元器这类 Workflow 工具时,应该都感受到了一个明显的变化:最牛的人工智能结果,越来越不是靠一个模型单打独斗能拿下的了,而是得靠多个组件拼起来的复合AI系统。但这里有个让人头疼的问题——这些组件之间要能顺畅交流,往往需要特定的输出格式,才能被下一个流程
最近,不少朋友在折腾 Dify、Coze、元器这类 Workflow 工具时,应该都感受到了一个明显的变化:最牛的人工智能结果,越来越不是靠一个模型单打独斗能拿下的了,而是得靠多个组件拼起来的复合AI系统。但这里有个让人头疼的问题——这些组件之间要能顺畅交流,往往需要特定的输出格式,才能被下一个流程正确解析。
可怎么让大模型老老实实地按规矩输出,比如生成结构严谨的 JSON 数据,一直是老大难。就在这个节骨眼上,向量数据库巨头 Wea viate 团队主导的 StructuredRAG 研究登场了。它不仅揭示了复合AI系统的巨大潜力,也为我们理解大模型在结构化输出这件事上的能力边界,提供了前所未有的视角。

要聊 StructuredRAG,得先搞明白“复合AI系统”这个概念。简单说,它就是把多个专门化的AI模型或工具组合起来,协同完成复杂任务的系统。这已经不再是靠一个超大模型包打天下的思路了。
Wea viate 作为向量数据库的领头羊,对复合AI系统的潜力自然门儿清。在这个体系里,向量数据库常常是核心枢纽,为不同组件提供高效的数据存取和检索。StructuredRAG 这项研究,正是为了解决复合AI系统里一个关键难题——如何保证大模型能稳定输出符合预设格式的结构化数据。下面,我们就来好好拆解这项开创性研究,看看它对AI行业到底意味着什么,以及它和 DSPy 这类前沿框架之间有什么内在联系。

01 为Compound AI Systems打地基
为什么结构化输出这么要紧?
很多朋友在搞智能体时都踩过类似的坑:明明设好了变量,加了约束语句,AI 助手的回复还是五花八门,格式乱成一锅粥。这会导致后续处理变得异常棘手。所以,提升大模型的结构化输出能力,是构建稳定、可靠AI系统的关键一环。
StructuredRAG 就提供了一种新思路,它把大模型的输出进行格式化,让结果变得更友好。它不只是给你一大段文字,而是把信息分层组织,给不同类型的内容打上标签(比如事实、观点、说明),再附上额外的元数据,帮你快速理解。
举个例子。以前它可能这么回复:
{
"text": "The capital of France is Paris. The Eiffel Tower is a famous landmark in Paris. Paris has a population of over 2 million people."
}用了 StructuredRAG 之后,返回的内容就变成了这样:
{
"facts": [
{
"text": "The capital of France is Paris.",
"type": "geographic"
},
{
"text": "The Eiffel Tower is a famous landmark in Paris.",
"type": "landmark"
},
{
"text": "Paris has a population of over 2 million people.",
"type": "demographic"
}
],
"meta": {
"topic": "Paris, France",
"source": "Wikipedia"
}
}这种结构化格式的好处显而易见:层级分明、类型清晰、还有上下文元数据,用户理解和交互起来都方便多了。它大大提升了LLM输出的可用性和可解释性。
StructuredRAG基准测试包含六个精心设计的任务:

1. 输出单个字符串
2. 输出单个整数
3. 输出布尔值
4. 输出字符串列表
5. 输出复合对象(包含答案和置信度)
6. 输出复合对象列表
这些任务看着简单,却基本覆盖了复合AI系统里常见的数据交换场景。比如,在多轮问答中,第一个组件可能得输出一个查询列表(任务4),第二个组件则要生成带置信度的答案(任务5)。从简单到复杂,这些任务为全面评估大模型的结构化输出能力,搭好了舞台。
StructuredRAG 的核心,就是把大模型那堆非结构化的文本,转成更有条理、带注释的 JSON 格式。这个过程大致分四步:
- 分段:先把LLM的输出切分成更小、语义清晰的片段(比如单个事实、观点或说明)。
- 类型注释:给每个片段标上具体类型(例如地理、人口统计、地标),说明它是什么信息。
- 分层组织:把片段组织成层级结构,相关内容放一起,该嵌套就嵌套。
- 上下文元数据:附加上下文元数据,比如主题、来源,帮用户更好地理解信息。
这么一来,最终的 StructuredRAG 格式对用户就直观多了,能快速抓住内容要点,识别不同类型的信息,更高效地浏览整个回复。
02 实验设计:两种模型,两种提示策略
这次实验选了两个有代表性的模型来摸底:
1. Gemini 1.5 Pro:代表了当前最先进的大规模语言模型。
2. Llama 3 8B-instruct (4位量化版本):代表了较小但经过指令微调的模型。
同时,还比较了两种不同的提示策略:
1. f-String提示:把任务相关的变量直接嵌入到提示里。
Task Instructions:{task_instructions}
References:{references}
Output the result as a JSON string with the following format:{response_format}
IMPORTANT!!Do not start the JSON with 'json or end it with2. Follow the Format (FF)提示:采用更严格的格式,先解释任务,再给出响应格式,最后提供输入变量。
Follow the task_instructions(Input Field) and generate the response(Output Field)
according to the output format given by response_format(Input Field). You will be
given references from(Task-Specific Input Field)
Follow the format.
---
task_instructions:{task_instructions}
response_format:{response_format}
references:{references}
response:这个实验设计,既能比较不同规模模型的能力差异,也能评估不同提示策略的效果。
WikiQuestions:模拟真实场景的数据集
为了让测试更贴近实际,研究人员专门建了个 WikiQuestions 数据集:
- 从维基百科随机选了56个标题和摘要
- 每个标题-摘要对应一个可回答的问题和一个不可回答的问题
- 总共112个问题用来测试
这个数据集很好地模拟了检索增强生成(RAG)系统里的真实情况,让测试更有实际意义。
惊人的结果:高方差与意外表现
实验结果一出,有点出人意料:
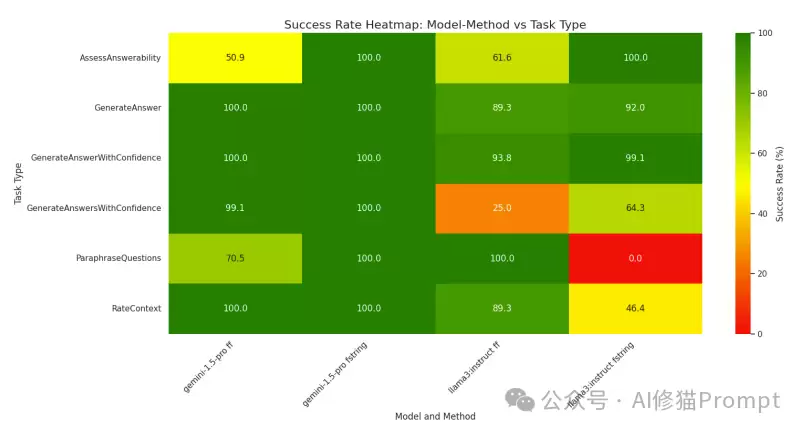
1. 总体成功率:在24次实验中,平均成功率达到82.55%。
2. 高度方差:有11次测试做到了100%成功,但也有2次测试掉到了25%以下。
3. Gemini vs Llama:Gemini 1.5 Pro 平均成功率93.4%,表现更好;Llama 3 8B-instruct 是71.7%。
4. 任务难度:单一类型输出(字符串、整数、布尔值)成功率普遍较高,列表和复合对象输出挑战更大。
5. 提示策略:对 Gemini 1.5 Pro 来说,f-String 提示更管用;而对 Llama 3 8B-instruct,FF 提示略胜一筹。
这些结果揭示了一个现实:大模型在结构化输出这件事上,情况相当复杂。哪怕是最先进的模型,在某些任务上也可能翻车。
成功与失败的原因
研究人员发现,最常见的翻车情况包括:
1. 模型只是确认了一下任务,却没去执行。
2. 输出中多了不少解释性的“废话”。
3. 类型搞错了(比如把整数输出成了字符串)。
这些失败模式告诉我们,即使是高度先进的LLM,在理解和严格执行结构化输出指令上,还有不小的改进空间。
OPRO:优化提示,突破极限
面对 Llama 3 8B-instruct 在某些任务上“低得可怜”的成功率,研究人员祭出了 OPRO(优化提示)技术。这个方法通过迭代优化提示,效果立竿见影:
1. 把 GenerateAnswersWithConfidences 任务的成功率从25%直接拉到了100%。
2. 优化后的提示包含了更详细的指导,比如“仔细审查任务说明”、“确保输出纯净且正确的 JSON”。
OPRO 的成功说明,哪怕是相对小的模型,只要提示设计得足够巧妙,也能在复杂任务上大放异彩。
关于 OPRO,可以看看这篇文章:谷歌DeepMind重磅:提示工程师必须掌握OPRO,用LLM就能自动优化Prompt|ICLR2024
03 StructuredRAG与DSPy
虽然 StructuredRAG 研究不是直接基于 DSPy 的,但它俩在不少方面表现出了惊人的默契:
1. 结构化输出的重要性:两者都强调在复杂AI系统里,处理结构化数据是核心。
2. 提示策略:StructuredRAG 的 FF 提示策略,跟 DSPy 的提示方法有异曲同工之妙。
3. 优化技术:OPRO 的成功,和 DSPy 的提示优化功能形成了有趣的呼应。
4. 评估方法:StructuredRAG 的基准测试,可以看作是给 DSPy 等框架补充的评估工具。
这些共性不仅反映了当前AI研究在复合AI系统方向上的共同趋势,也为未来的协同研究指了条路。来看看下面这段 DSPy 代码:
import dspy
from typing import Optional, Any, Dict
from structured_rag.dspy_signatures import GenerateResponse
class dspy_Program(dspy.Module):
def __init__(self,
test_params: Dict[str, str],
model_name: str, model_provider: str, api_key: Optional[str] = None) -> None:
super().__init__()
self.test_params = test_params
self.model_name = model_name
self.model_provider = model_provider
self.configure_llm(api_key)
self.generate_response = dspy.ChainOfThought(GenerateResponse)
def configure_llm(self, api_key: Optional[str] = None):
if self.model_provider == "ollama":
llm = dspy.OllamaLocal(model=self.model_name, max_tokens=4000, timeout_s=480)
elif self.model_provider == "google":
llm = dspy.Google(model=self.model_name, api_key=api_key)
else:
raise ValueError(f"Unsupported model provider: {self.model_provider}")
print("Running LLM connection test (say hello)...")
print(llm("say hello"))
dspy.settings.configure(lm=llm)
def forward(self, test: str, question: str, context: Optional[str] = "") -> Any:
references = {"context": context, "question": question}
references = "".join(f"{k}: {v}" for k, v in references.items())
response = self.generate_response(
task_instructions=self.test_params['task_instructions'],
response_format=self.test_params['response_format'],
references=references
).response
return response虽然论文里没直接点明,但要注意的是,DSPy 的一些核心开发者(比如 Omar Khattab)也参与了类似领域的研究。这说明 StructuredRAG 和 DSPy 背后可能有着共同的研究背景和思想源流。
尽管 StructuredRAG 论文不直接聊 DSPy,但它们在研究目标、方法论和未来发展方向上有很多共通之处。StructuredRAG 的研究成果,很可能会给 DSPy 的进一步发展和应用提供有价值的参考;反过来,DSPy 的实践经验也可能影响 StructuredRAG 这类基准测试的设计和应用。这种相互影响,恰恰是当前AI研究领域紧密联系、快速发展的一个缩影。
关于输出约束,可以看看这几篇“惊雷”系列文章:一记惊雷:改一下Prompt的输出顺序,就能显著影响LLM的评估结果;又见惊雷,结构化Prompt格式小小变化竟能让LLM性能波动高达76%,ICLR2024
04 对开发者的深度启示
StructuredRAG 的研究成果,给复合AI系统的开发者提供了好几点实用的指导:
1. 模型选择策略
- 根据任务复杂度和资源限制,在大型通用模型和小型专门模型之间找到平衡点。
- 可以考虑在系统里混搭不同规模的模型,平衡好性能和效率。
2. 提示工程的艺术
- 为不同的模型和任务,定制对应的提示策略。
- 利用 OPRO 这类技术动态优化提示,提升系统整体表现。
3. 错误处理机制设计
- 根据研究揭示的常见失败模式,设计健壮的错误检测和恢复策略。
- 做好跨组件的错误传播控制,防止局部问题拖垮整个系统。
4. 持续评估与优化
- 把 StructuredRAG 这类基准测试纳入开发流程,定期给系统“体检”。
- 建立动态优化机制,根据实时性能数据调整系统配置。
5. 接口设计与标准化
- 基于研究中的结构化输出任务,设计标准化的组件间通信接口。
- 推动行业内的接口标准化,让不同的复合AI系统之间更好配合。
6. 更多优化策略
研究人员还指出了几个值得探索的优化方向:
1. 集成:利用LLM的随机性,每次输入生成多个输出,然后“投票”选最好的。
2. 重试机制:对失败的输出,再试一次,并加上“重试”提示。
3. 思维链提示:加上“理由”键,让模型先想清楚再回答。
4. 高级提示优化:探索像 MIPRO 这种更复杂的优化技术。
这些方向为进一步提升大模型的结构化输出能力,留出了广阔的想象空间。
StructuredRAG 这项研究,展示了 Wea viate 在尖端AI研究领域的硬实力。它也在从单纯的数据存储提供商,向复合AI系统的核心基础设施提供商转变。说白了,用好 StructuredRAG 的研究成果,不断打磨你的提示策略和系统设计,你完全有可能搞出更厉害的 AI 产品。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:结构化RAG约束JSON响应格式提升AI系统成功率82.55%要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在日常基于 QClaw 进行微服务开发时,不少开发者会遇到这样的困境:代码虽然生成了,但服务间的调用逻辑并不完整,应有的服务发现与负载均衡配置常常缺失。问题到底出在哪里?通常不是工具本身能力不足,而是 QClaw 未能准确识别项目当前的技术栈上下文。 简单来说,要让 QClaw 生成真正可用的服务调
大模型幻觉指生成内容不准确或虚假,原因包括数据偏差、训练过拟合与解码随机性。评估方法有人工评审、准确性测试、自动化检测等。减少策略包括提高数据质量、模型校准、引入知识库等。
阿里云百炼核心能力正式实现 CLI 化,Agent 开发者只需一条命令即可无缝接入超过 150 款模型、十余款应用,并同步获得知识库、记忆、联网搜索等完整能力。百炼 CLI 专为 Agent 场景量身打造,原生兼容 Claude Code、Qoder、OpenClaw、Hermes Agent 等主
HuggingFace作为自然语言处理领域的重要基础设施,提供模型库、数据集、工具库及云计算资源。开发者可借助Transformers、Datasets等库加载预训练模型,通过Trainer类进行微调训练,并将结果保存至ModelHub共享。该平台大幅降低了AI模型开发门槛。
- 日榜
- 周榜
- 月榜
热点快看