




PyTorch Transformer多头自注意力机制:序列反转与图像异常检测应用附智能体代码数据

摘要 本文从理论解析到代码实现,系统拆解了Transformer模型的两大核心模块——缩放点积注意力与多头自注意力,并基于PyTorch框架从零构建了完整的Transformer编码器。我们将这一架构应用于两个实际场景:经典的序列反转任务,以及更具挑战性的集合异常检测任务。全文旨在解答以下核心问题:


摘要
本文从理论解析到代码实现,系统拆解了Transformer模型的两大核心模块——缩放点积注意力与多头自注意力,并基于PyTorch框架从零构建了完整的Transformer编码器。我们将这一架构应用于两个实际场景:经典的序列反转任务,以及更具挑战性的集合异常检测任务。全文旨在解答以下核心问题:自注意力机制如何通过查询-键-值三要素实现动态加权?多头注意力为何能显著增强特征表达能力?Transformer编码器为何必须依赖残差连接与层归一化?位置编码背后的数学原理是什么?学习率预热策略对训练稳定性有何重要作用?通过详尽的代码示例与结果分析,读者可以快速掌握Transformer的精髓,并将其灵活迁移至自身的研究课题中。
关键词:Transformer;多头注意力;自注意力;位置编码;学习率预热;序列反转;集合异常检测;PyTorch
Abstract
This paper thoroughly dissects the core components of the Transformer model—scaled dot-product attention and multi-head self-attention—and implements a Transformer encoder from scratch using PyTorch. We apply the architecture to two practical tasks: sequence reversal and set anomaly detection. Key questions addressed include: (1) How does self-attention compute dynamic weights via query-key-value? (2) Why does multi-head attention enhance feature representation? (3) Why are residual connections and layer normalization vital in the Transformer encoder? (4) The mathematical design and visualization of positional encoding; (5) How does learning rate warmup stabilize training? Complete code and experimental results are provided, enabling readers to quickly grasp the Transformer and adapt it to their own research.
Keywords: Transformer; multi-head attention; self-attention; positional encoding; learning rate warmup; sequence reversal; set anomaly detection; PyTorch
引言
近年来,Transformer架构席卷了深度学习领域的各个角落,从自然语言处理到计算机视觉,无不展现出其强大的序列建模能力。许多学习者经常困惑:如何从本质上理解并亲手实现一个Transformer?又如何将其应用于非NLP领域的实际问题?
本文将带你从一个最基础的起点出发,逐步构建一个完整的Transformer编码器,涵盖缩放点积注意力、多头注意力、位置编码、学习率预热等全套核心组件。随后,通过两个实际任务来验证其能力:第一个是序列反转,用于展示其对长程依赖关系的捕捉能力;第二个是图像集合异常检测,用于证明其在无序集合场景下的强大泛化性能。无论你是在准备毕业论文,还是在进行模型选型的技术评估,都能从中找到可直接复现的代码与可迁移的设计思路。
全文脉络流程图:
代码语言:ja vascript复制
Transformer核心组件 │ ├─ 缩放点积注意力 ──► 查询·键·值 │ ├─ 多头注意力 ──► 多子空间交互 │ ├─ 编码器块 ──► 残差 层归一化 前馈 │ ├─ 位置编码 ──► 正弦/余弦注入顺序 │ ├─ 学习率预热 ──► Adam稳定训练 │ └─ 应用任务├─ 序列反转 (准确率100%)└─ 图像异常检测 (准确率94%)
1. 环境与基础库
在开始运行前,需要安装若干依赖包。以下代码将静默安装指定版本的PyTorch Lightning、matplotlib、torchvision等组件。执行时若提示pip版本更新,可忽略。随后导入必要模块,并固定随机种子、配置计算设备。输出显示“使用设备: cuda:0”,即表明GPU可用。
2. Transformer架构精要
2.1 注意力机制的生活化理解
注意力机制可以类比为在图书馆检索资料:你心中有一个“查询”(即想了解的主题),每本书都有对应的“键”(目录关键词)和“值”(详细内容)。你通过比较查询与每本书的键,得出相似度分数,再根据这些分数聚合各本书的值,最终获取综合信息。这便是**查询(Q)、键(K)、值(V)**概念的由来。
而自注意力,则是序列中的每个元素都同时扮演查询、键和值的角色,让元素之间进行两两交互,从而动态决定“谁应该更关注谁”。
2.2 缩放点积注意力
对于一组查询Q、键K、值V(形状为 seq_len × d_k 等),其计算流程如下:
代码语言:ja vascript复制
Attention(Q,K,V) = softmax( QK^T / √d_k ) V
关键在于除以 √d_k 这个缩放因子。当 d_k 较大时,点积结果的方差会放大至 d_k 倍,导致softmax函数饱和到极端分布,进而引发梯度消失。经过缩放后,方差回归到1,梯度可以正常流动。以下是手动实现的版本,函数命名为 compute_scaled_dot_attn:
代码语言:ja vascript复制
def computttn(query, key, value, mask=None):dim_k = query.size()[-1]# 计算注意力分数矩阵scores = torch.matmul(query, key.transpose(-2, -1))scores = scores / mt.sqrt(dim_k)if mask is not None:scores = scores.masked_fill(mask == 0, -9e15)attn_weights = F.softmax(scores, dim=-1)output = torch.matmul(attn_weights, value)return output, attn_weights
2.3 多头注意力
单一的注意力头可能只能捕捉一种关联模式。多头注意力机制通过并行执行h个独立的注意力头,每个头拥有自己的W_Q、W_K、W_V投影矩阵,最后将各头结果拼接并再次进行线性投影,从而使模型能够同时关注多个不同的表示子空间。以下展示了 MultiHeadAttention 类的实现(关键部分,省略了参数初始化细节)。
2.4 Transformer编码器块
一个标准编码器块的结构为:多头自注意力 → 残差连接 → 层归一化 → 前馈网络(MLP) → 再次残差连接与层归一化。残差连接保障了深层网络中的梯度顺畅传播,而层归一化则加速训练过程并平滑特征尺度。
2.5 位置编码
由于自注意力机制本身是对称的,无法感知序列中的元素顺序。因此,我们通过正弦和余弦函数生成的位置编码,直接加到输入向量上:
代码语言:ja vascript复制
PE(pos,2i) = sin(pos / 10000^(2i/d_model))PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))
不同频率的波形让模型能够学习到元素之间的相对位置关系。下面展示了实现代码及其可视化结果。
可视化编码矩阵:
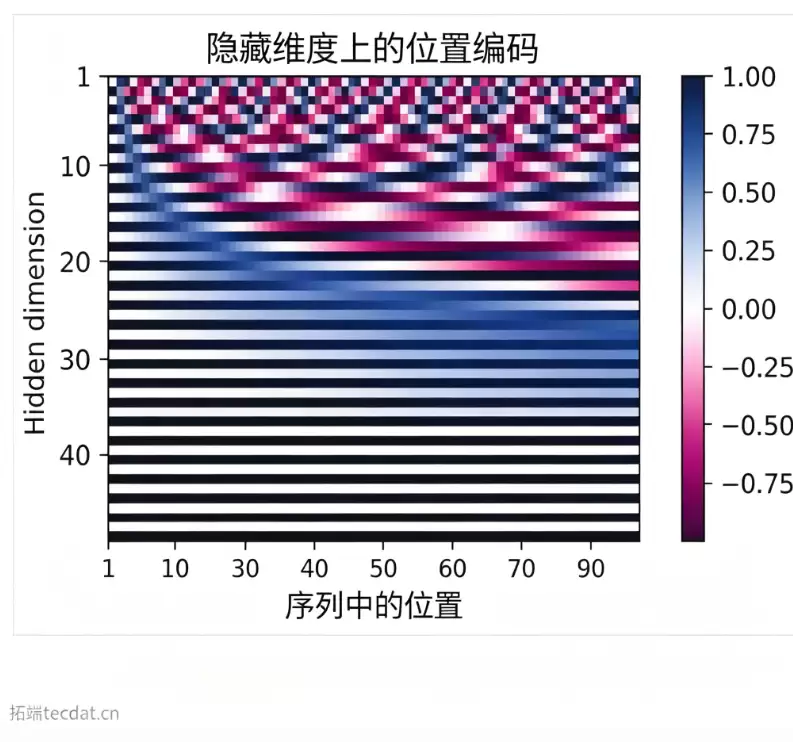
图中横轴代表序列位置,纵轴代表隐藏维度,颜色深浅表示编码值。可以清晰观察到正弦、余弦波的不同波长特征。
单独观察某几个维度的编码曲线:

隐藏维度1和2仅仅是初始相位不同,而维度3和4的波长则显著增大。这种设计使得任意两个位置之间的相对偏移都可以通过线性函数近似,这非常有利于模型学习相对距离。
2.6 学习率预热与余弦衰减
深度Transformer在训练初期容易出现梯度不稳定的问题,采用学习率预热(warmup)策略可以有效缓解这一现象。结合余弦退火机制,学习率先线性增长至设定值,随后再按照余弦曲线逐渐衰减。下图展示了学习率曲线的可视化效果:
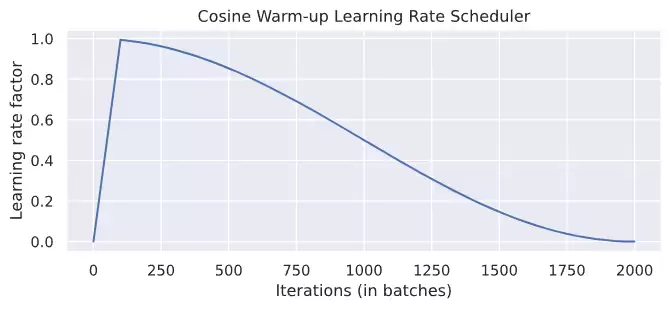
在前100次迭代中,学习率从0线性上升至1,之后便按余弦曲线下降。
2.7 PyTorch Lightning模型封装
我们将前述所有组件封装成一个通用的 TransformerPredictor 类,其中包含输入投影、位置编码、编码器模块以及输出分类头,并集成了优化器与学习率调度逻辑。后续针对具体任务的训练、验证与测试步骤,将在子类中进行重写。
3. 任务一:序列反转
3.1 数据集与加载器
首先构造一个简单的序列反转数据集:生成由0到9之间的随机整数构成的序列,其标签为该序列的倒序排列。序列长度固定为16。我们创建了训练、验证、测试三个数据加载器,其中训练集包含5万条数据。
3.2 模型定义与训练
在 TransformerPredictor 的基础上,定义 ReversePredictor 子类,并重写损失计算函数。训练配置上,使用单头、单层编码器,模型维度设为32,学习率为5e-4,预热步数为50步。最终模型可以轻松完美地实现序列反转。
3.3 注意力图可视化
调用 get_attn_maps 方法获取单层单头的注意力权重,并将其绘制为热力图。

图中横轴代表序列的输入位置,纵轴代表输出位置(均为原始标签)。每个单元格的颜色深度表示第i个输出对第j个输入的关注程度。可以看出,模型成功学习到了对角线翻转的注意力模式:输出位置i几乎完全聚焦于输入位置 (seq_len-1-i),从而实现了完美的反转效果。
4. 任务二:图像集合异常检测
4.1 任务描述与特征提取
在此任务中,模型需要从一组图像(包含9张同类图像和1张异类图像)中,找出那张“格格不入”的异常图像。为了减少计算量,我们首先利用在ImageNet上预训练的ResNet34网络,提取每张图像的高层语义特征(维度为512)。以下函数用于提取所有图像的特征并保存至磁盘,避免重复计算。最终,训练集特征形状为 [50000,512],测试集特征形状为 [10000,512]。
4.2 构建异常检测数据集
定义 AnomalySetDataset 类,每次返回一组图像特征,并约定最后一个元素为异常样本。训练阶段采用随机抽取方式,测试阶段则固定集合以保证结果的可比性。随后,按照类别均衡采样10%的数据作为验证集,并对训练/验证集进行划分。
4.3 异常检测模型与训练
考虑到集合中的元素是无序的,我们在模型中不添加位置编码,以保持模型的排列等变性。模型输出一个标量logit,经softmax函数处理后得到每张图像作为异常的概率,并与真实标签计算交叉熵损失。训练配置如下:4层编码器,维度256,4个注意力头,dropout为0.1,学习率5e-4,预热步数100。训练结果如下:
代码语言:ja vascript复制
训练准确率: 96.38%验证准确率: 96.20%测试准确率: 94.41%
模型成功识别出了绝大多数异常样本,并通过置换测试验证了其严格的排列等变性:当输入顺序发生变化时,输出概率仅按照相同的排列进行重排,数值几乎保持不变。
4.4 可视化分析
下面展示几个测试集样例。第一组:包含9张树图片和1张火山图片。

预测结果准确指向了最后一张异常图片。进一步绘制各层的注意力图进行分析:

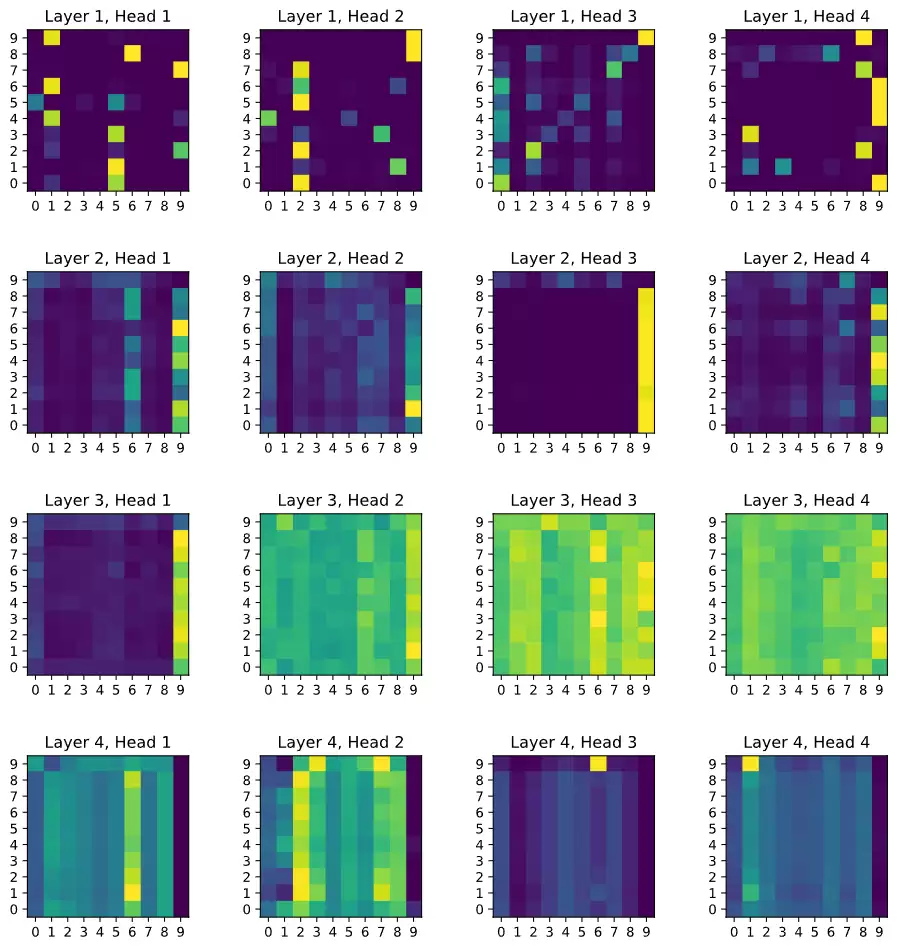
可以观察到,第二层的头1和头3,以及第三层的头1,显著关注了异常图像;而第四层的所有头则降低了对异常图像的注意力,这表明高层网络已经整合了信息并做出了最终判断。
我们还查看了部分错误案例:一张棕榈树图片被模型误判为建筑。

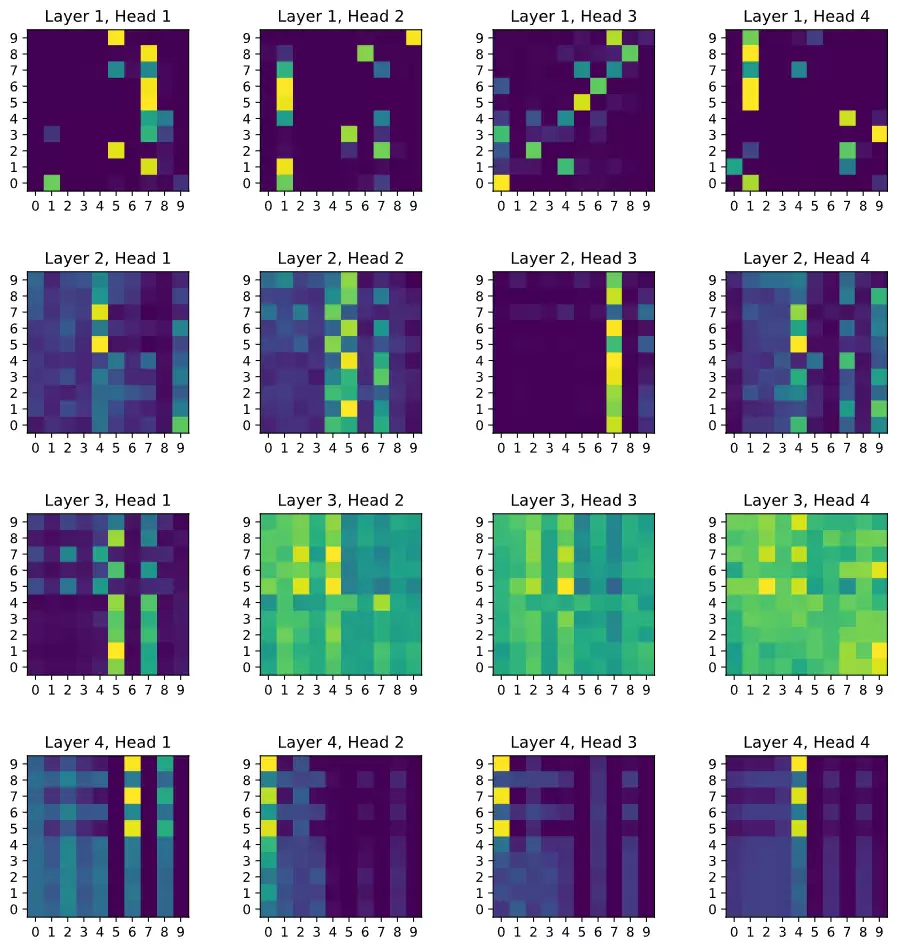
分析其错误原因,可能是由于该棕榈树的拍摄角度和颜色分布与同类别图像差异较大,从而导致模型产生了混淆。
5. 自注意力与其他机制的对比
下表引自Vaswani et al. (2017),对比了自注意力、循环神经网络、卷积神经网络在计算复杂度、并行能力以及最长路径长度方面的差异。
层类型 | 每层复杂度 | 顺序操作数 | 最大路径长度 |
|---|---|---|---|
自注意力 | O(n²·d) | O(1) | O(1) |
循环 | O(n·d²) | O(n) | O(n) |
卷积 | O(k·n·d²) | O(1) | O(logₖn) |
其中 n 为序列长度,d 为表示维度,k 为卷积核大小。自注意力在处理短序列时不仅计算效率高,而且拥有最短的梯度传播路径,这使得它非常有利于捕捉长距离依赖关系。
总结
本文从理论推导、代码实现到实际应用,完整呈现了Transformer编码器的核心组件。通过两个典型任务,我们验证了其强大的序列建模能力以及对无序集合的出色适应性。主要结论如下:
- 自注意力机制:通过查询-键-值的动态相似度计算,实现了与位置无关的内容交互,缩放因子则有效防止了梯度消失问题。
- 多头注意力:多个子空间并行关注,显著提升了特征表达能力,这是Transformer成功的关键要素。
- 编码器设计:残差连接与层归一化保障了深层网络的稳定训练,前馈网络则提供了位置独立的非线性变换能力。
- 位置编码:正弦/余弦编码以优雅的数学形式向序列中注入了顺序信息,并支持处理任意长度的序列。
- 学习率预热:有效缓解了训练初期的不稳定性,与余弦衰减策略配合,已成为训练深度Transformer的标准配置。
- 应用迁移:序列反转任务验证了模型对长程依赖的完美捕捉能力;图像集合异常检测任务则展示了其在非NLP领域的通用性,且模型天然具备排列等变性。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Sider AI Docker 一键部署教程:镜像拉取、端口映射与数据目录配置
SiderAIDocker部署需先确认镜像来源与运行需求,再完成镜像拉取、端口映射、数据目录挂载和环境变量配置,并通过日志、健康检查与权限控制降低运行风险。

Sider AI Linux 服务器部署教程:从环境准备到后台运行完整流程
SiderAI常见部署重点在服务器环境、依赖安装、服务启动、进程守护与安全配置。Linux上应先确认官方形态与使用边界,再通过Node、Docker或systemd完成稳定后台运行。

Sider AI macOS 安装教程:Apple Silicon 与 Intel 电脑配置步骤整理
SiderAI在macOS上可通过浏览器插件或桌面端使用,AppleSilicon与Intel电脑安装路径基本一致,重点在于选择正确版本、完成权限配置、核对账号与模型设置,并做好隐私与兼容性检查。

Merlin AI 新手入门安装指南:从下载安装到首次运行的保姆级教程
MerlinAI适合需要在网页中快速总结、翻译、改写和生成内容的新手用户。安装时应优先选择官方站点或浏览器扩展商店,完成登录、权限确认和基础设置后,再通过网页侧边栏或快捷入口进行首次体验。

Merlin AI 安装失败怎么办?常见报错、日志排查与升级回滚方案
MerlinAI安装异常通常与浏览器版本、插件包来源、权限策略、网络连接和缓存损坏有关。排查时应先确认环境,再查看扩展页报错与系统日志,必要时清理残留、切换官方渠道安装,并准备升级或回退方案。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-16 14:54
2026-07-16 14:54
2026-07-16 14:53
2026-07-16 14:53
2026-07-16 14:52
2026-07-16 14:52
2026-07-16 14:51
2026-07-16 14:51
热门教程
2026-07-16 14:54
2026-07-16 14:54
2026-07-16 14:53
2026-07-16 14:53
2026-07-16 14:52
2026-07-16 14:52
2026-07-16 14:51
2026-07-16 14:51
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















