




ICML 2026武大提出首个Any2Any遥感图像跨模态翻译统一转换框架

```html 遥感领域近期发布了一项颇具创新性的研究——Any2Any: Unified Arbitrary Modality Translation for Remote Sensing,由武汉大学、北京中关村学院与北京理工大学联合团队完成。论文已公开在 arXiv 平台(2603 04114)
遥感领域近期发布了一项颇具创新性的研究——Any2Any: Unified Arbitrary Modality Translation for Remote Sensing,由武汉大学、北京中关村学院与北京理工大学联合团队完成。论文已公开在 arXiv 平台(2603.04114),同时配套开源了代码与数据集,便于学界和产业界复现与扩展。
创新点
本研究包含以下几项核心贡献:
- 首次将遥感跨模态翻译任务形式化为“任意到任意(Any-to-Any)”统一框架,将建模复杂度从传统的 O(N²) 大幅降低至 O(1),显著提升了多模态扩展效率。
- 构建了首个百万级多模态遥感数据集 RST-1M,覆盖五种传感器模态(RGB、SAR、NIR、MS、PAN),支持任意模态对间的监督学习与零样本评估。
- 提出了基于共享潜在扩散框架的 Any2Any 模型,通过创新的“潜在锚点机制”将异构模态对齐到统一的语义空间,解决了模态间结构差异问题。
- 设计了轻量级目标模态残差适配器,在不增加推理复杂度的前提下,有效修正了模态间的系统性分布偏差,提升了翻译保真度。

背景
现代地球观测系统依赖多种异构传感器获取多模态数据——RGB、SAR、PAN、NIR、MS,每种传感器具有不同的物理成像机制,提供的场景信息高度互补。然而,由于采集约束和环境因素,真正大规模共配准的多模态观测数据十分稀缺,模态缺失几乎成为常态。
现有的跨模态翻译方法通常针对每一对模态单独训练一个翻译模型,这意味着需要训练 O(N²) 个方向特定的模型。随着传感器种类增加,训练和存储成本迅速膨胀。此外,各个翻译器在模态特定偏置下独立优化,语义知识难以跨模态对共享,泛化能力受到严重限制。而现有的多模态遥感数据集规模小、模态覆盖有限,难以支撑系统性的任意模态翻译学习需求。
数据
RST-1M
研究团队构建了目前首个百万级遥感任意模态翻译基准数据集——RST-1M。其核心指标如下:
- 包含约 120 万对空间对齐的跨模态图像对。
- 覆盖 7 种模态配对,支持 20 个有向模态翻译任务(其中14个为训练可见方向,6个为零样本不可见方向),为模型泛化评估提供了坚实基础。
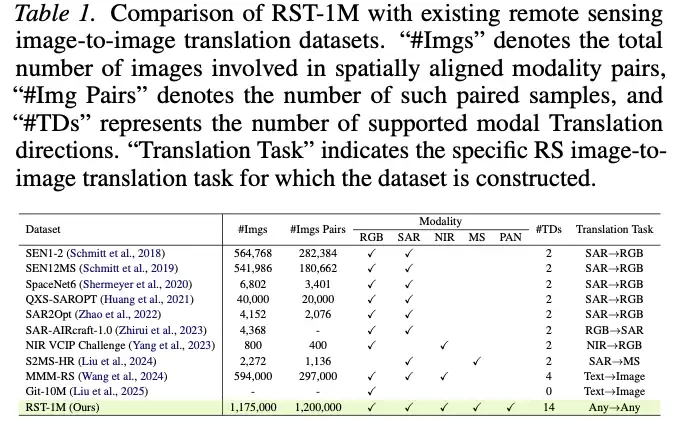
模态与分辨率
- RGB:256×256×3,约 42.5 万张
- SAR:256×256×1,约 25 万张
- NIR:256×256×1,约 20 万张
- MS:128×128×6,约 20 万张
- PAN:512×512×1,约 10 万张
数据来源
- SEN1-2:提供 SAR-RGB 配对(Sentinel-1/2)
- SEN12MS:提供 SAR、RGB、NIR、MS 配对(Sentinel-1/2)
- CACo:提供 RGB、NIR、MS(Sentinel-2)
- SpaceNet-3 & SpaceNet-5:提供 RGB-PAN 配对(WorldView-3)
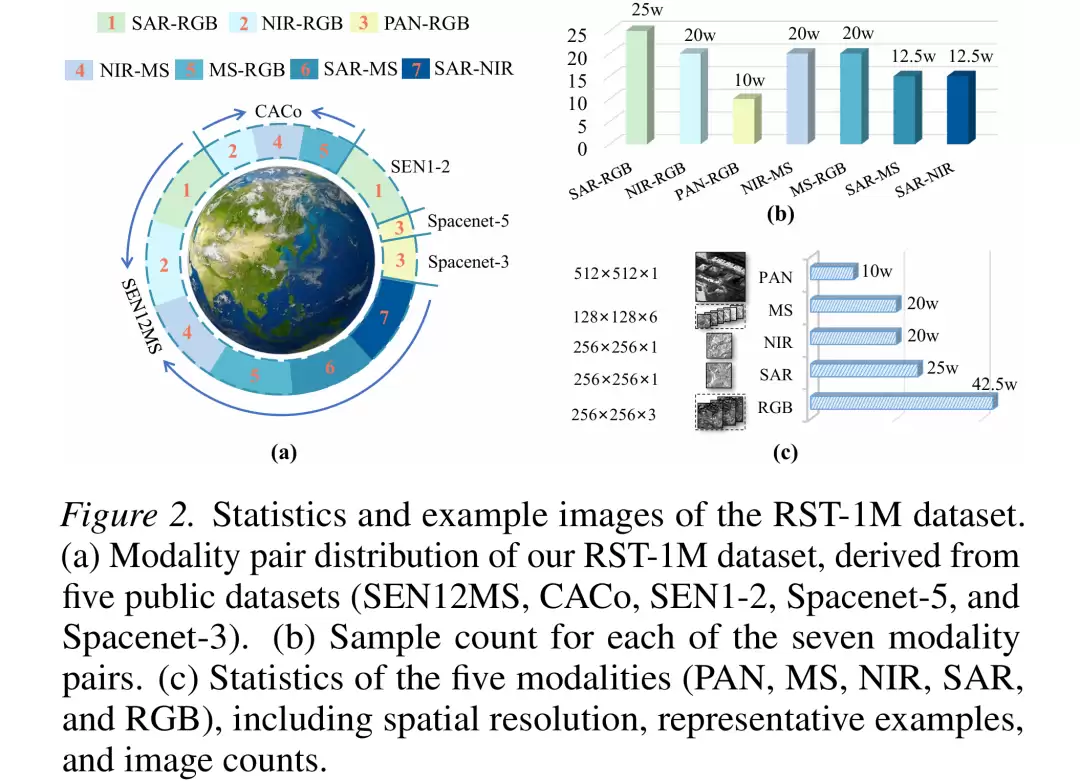
构建策略
数据集以 RGB 为枢轴模态,桥接原本不连通的模态对,确保全局跨模态可达性。对于 Sentinel-2 的原始数据,按照标准波段配置派生出 RGB、NIR 和 MS 图像,保证了数据一致性和多样性。
方法
Any2Any 的整体思路采用了解耦式潜在扩散生成框架。它将任意模态翻译分解为三个阶段:模态特定潜在投影、统一语义映射、流形校准,实现了高效且灵活的跨模态生成。
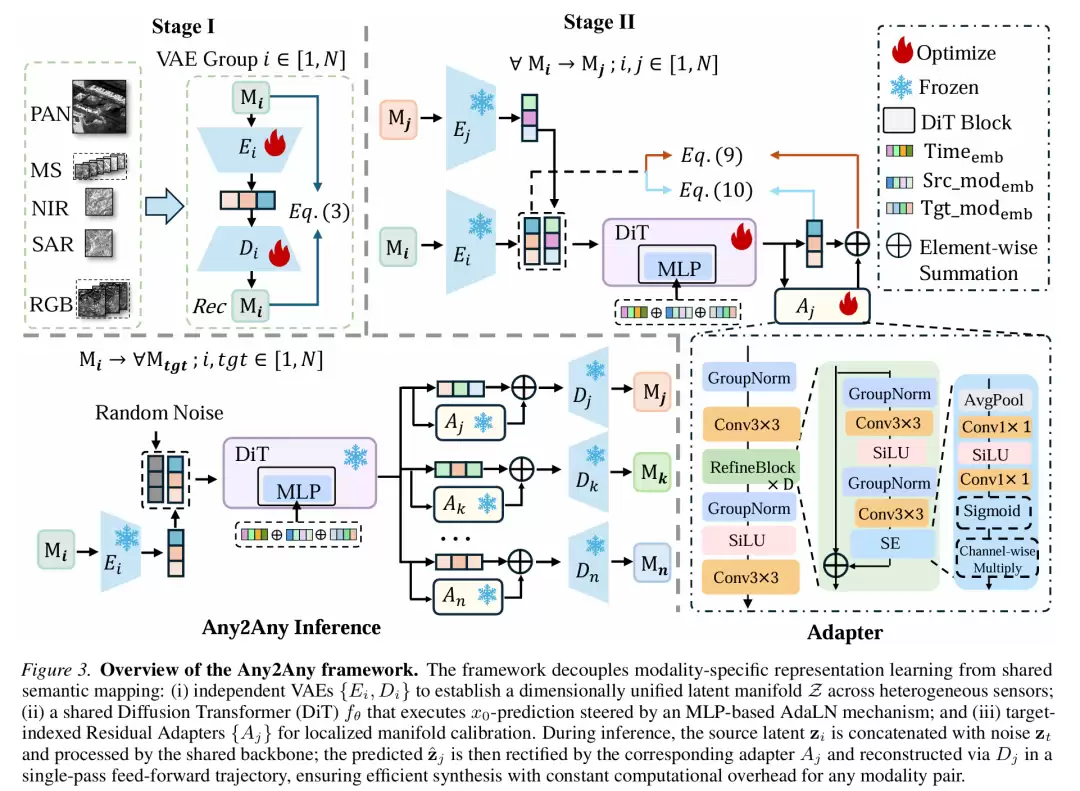
阶段一:模态特定潜在投影
为每种模态独立训练一个变分自编码器(VAE),将异构传感器数据投影到统一的几何对齐潜在空间。编码器将各模态原始观测压缩为维度统一的潜在表示,解码器则负责从潜在表示重建回对应模态图像。训练目标结合了像素级重建损失、感知损失与 KL 散度正则化,确保潜在表示具有良好的可重建性与语义保持能力。
阶段二:统一语义映射(潜在锚点机制)
训练好 VAE 后,冻结其参数,基于对齐的潜在空间训练一个共享的 Diffusion Transformer(DiT)骨干网络。具体做法是将含噪目标潜在表示与源模态潜在表示沿通道维度拼接,作为骨干网络的输入。通过自适应层归一化(AdaLN)把时间步嵌入、源模态标识与目标模态标识融合成一个联合调制向量。这里采用 x₀ 预测重参数化(而非常见的噪声预测),相当于将去噪轨迹直接锚定到目标模态的语义结构上,有效避免了跨模态结构退化问题。
阶段三:流形校准(残差适配器)
为每个目标模态配置一个轻量级残差适配器,用来修正骨干网络预测与目标解码器流形之间的系统性分布偏差。适配器采用紧凑卷积网络结构,附带 SE 通道注意力模块。最终投影层做零初始化,确保训练初期不会破坏骨干网络的预训练先验。通过停止梯度算子将适配器优化与骨干参数解耦。推理时,适配器仅需一次前向操作,计算开销维持在 O(1) 级别,实现了高效部署。
结果与分析
Any2Any 在全部 14 个模态翻译任务上均达到最优或接近最优的性能——值得注意的是,这是用一个统一模型实现的,而现有方法需要训练 14 个独立模型才能覆盖这些任务。更令人关注的是,尽管模型只在部分模态对上训练过,但对 6 个未见模态对展现出了很强的零样本泛化能力,这充分验证了共享潜在空间中语义表示的可迁移性,为遥感多模态统一建模开辟了新路径。





游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Sider AI Docker 一键部署教程:镜像拉取、端口映射与数据目录配置
SiderAIDocker部署需先确认镜像来源与运行需求,再完成镜像拉取、端口映射、数据目录挂载和环境变量配置,并通过日志、健康检查与权限控制降低运行风险。

Sider AI Linux 服务器部署教程:从环境准备到后台运行完整流程
SiderAI常见部署重点在服务器环境、依赖安装、服务启动、进程守护与安全配置。Linux上应先确认官方形态与使用边界,再通过Node、Docker或systemd完成稳定后台运行。

Sider AI macOS 安装教程:Apple Silicon 与 Intel 电脑配置步骤整理
SiderAI在macOS上可通过浏览器插件或桌面端使用,AppleSilicon与Intel电脑安装路径基本一致,重点在于选择正确版本、完成权限配置、核对账号与模型设置,并做好隐私与兼容性检查。

Merlin AI 新手入门安装指南:从下载安装到首次运行的保姆级教程
MerlinAI适合需要在网页中快速总结、翻译、改写和生成内容的新手用户。安装时应优先选择官方站点或浏览器扩展商店,完成登录、权限确认和基础设置后,再通过网页侧边栏或快捷入口进行首次体验。

Merlin AI 安装失败怎么办?常见报错、日志排查与升级回滚方案
MerlinAI安装异常通常与浏览器版本、插件包来源、权限策略、网络连接和缓存损坏有关。排查时应先确认环境,再查看扩展页报错与系统日志,必要时清理残留、切换官方渠道安装,并准备升级或回退方案。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-16 14:54
2026-07-16 14:54
2026-07-16 14:53
2026-07-16 14:53
2026-07-16 14:52
2026-07-16 14:52
2026-07-16 14:51
2026-07-16 14:51
热门教程
2026-07-16 14:54
2026-07-16 14:54
2026-07-16 14:53
2026-07-16 14:53
2026-07-16 14:52
2026-07-16 14:52
2026-07-16 14:51
2026-07-16 14:51
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















