




生成式人工智能赋能边缘计算视觉AI智能体开发

在NVIDIAJetsonOrin边缘设备上,利用视觉语言模型(VLM)与Jetson平台服务构建视觉AI智能体,支持自然语言交互与实时视频分析,可自定义警报规则并通过移动应用推送通知,实现低延迟边缘智能监控。
视觉语言模型(VLM)的突破性进展,确实令人耳目一新。它将视频分析从传统的“机械检索”升级为“智能交互”。过去,我们需要预先设定规则、编写脚本,才能从视频中提取有价值的信息。如今,只需用自然语言提问——“画面中是否有消防车?”“停车场还剩几个空位?”——即可轻松获取答案。而且,这些模型既能在 NVIDIA Jetson Orin 等边缘设备上运行,也能部署在独立 GPU 上。本文的目标非常明确:梳理如何构建一套既能运行在边缘、也能部署在云端的视觉 AI 智能体系统。
什么是视觉AI智能体
所谓视觉 AI 智能体,本质上就是为视频赋予了“理解能力”。它让你能够用自然语言与实时或录制的视频画面进行互动,提出真实意图,获得带有上下文洞察的结果。这些智能体对外提供简洁的 REST API,易于集成到其他服务中,甚至可以与手机 App 联动。
新一代的视觉 AI 智能体,功能远不止“识别”那么简单。场景总结、告警规则设置,以及通过自然语言从视频中提炼可执行的洞察——这才是它的核心竞争力。如果你正在开发此类应用,NVIDIA Metropolis 提供的参考工作流是一个很好的起点。这套方案无论是在边缘还是云端,都能让应用通过理解上下文,从视频中提取出有价值的讯息。
在云端部署时,开发者可以借助 NVIDIA NIM 来驱动视觉 AI 智能体。NIM 系列包含了标准的行业 API、特定领域的代码、优化后的推理引擎以及企业级运行时。想快速上手?可以先访问 API 目录,在浏览器里直接试用各种基础模型;Metropolis NIM Workflows GitHub 仓库中也提供了现成的参考示例。
本文的重点仍集中在边缘侧。我们将在 Jetson Orin 上展开,利用 NVIDIA JetPack SDK 的新功能——也就是适用于边缘部署的 Jetson 平台服务——来搭建一个完整的生成式 AI 应用。最终效果如图 1 所示:用户能用自然语言设定监控事件,系统在实时视频流中检测到事件后,立即通知用户。

图 1. 在视频流中检测火灾的 AI 智能体移动应用
使用Jetson平台服务为边缘构建视觉AI智能体
Jetson 平台服务是一套预构建的微服务,专为在 Jetson Orin 上构建计算机视觉解决方案而设计。它的价值在于“开箱即用”——零样本检测、各种主流 VLM 能力都已打包就绪。
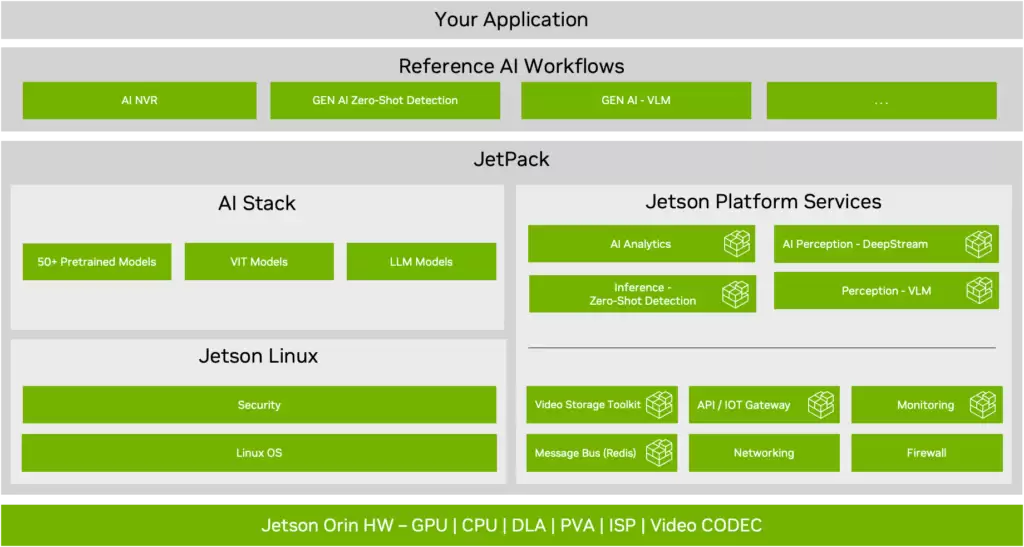
图 2. NVIDIA JetPack 6.0 堆栈
VLM 之所以独特,是因为它融合了大语言模型与视觉 transformer。它能够对输入的文本和视觉画面进行复杂的推理,这意味着它的适应性很强,只需调整提示词,就能适配各种不同的场景。
在 Jetson 上,VILA 是首选模型。它的推理能力处于业界领先水平,并且通过优化每张图片的 token 数量,在速度上也占据优势。图 3 展示了 VILA 的架构和基准性能。更详细的技术细节,可以参阅“视觉语言智能与边缘 AI 2.0”那篇文章。
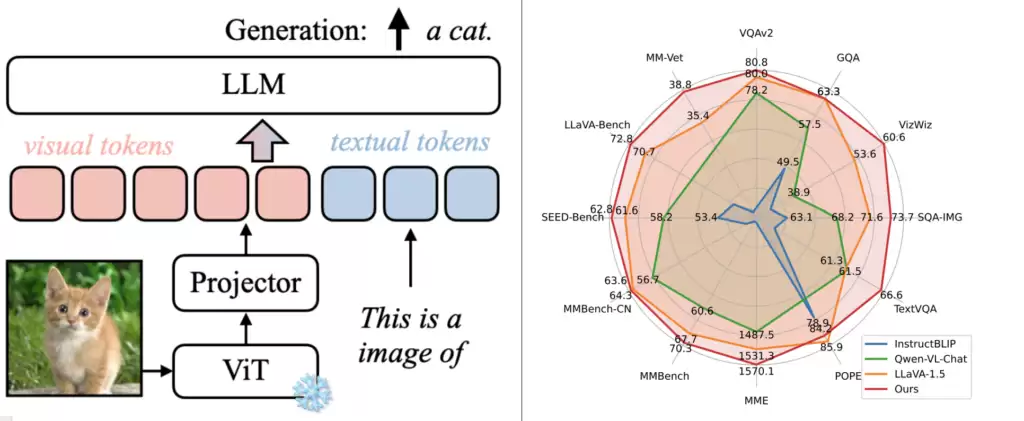
图 3. VILA 结合视觉 transformer 和大语言模型
在输入图像上通过 VLM 进行对话固然有趣,但真正的价值在于将这项技术落地到实际场景中。因此,我们需要让大语言模型执行有意义的任务,并将其整合进更大的系统。结合 VLM 与 Jetson 平台服务,就能创建一个智能体应用:实时检测网络摄像头上的事件,再通过手机 App 向用户推送通知。图 4 展示了这个应用中各组件的协同工作方式。
此外,该应用可以与防火墙、物联网网关、云服务配合使用,实现安全的远程访问。
构建基于VLM的视觉AI智能体应用
下面来看具体的构建步骤。完整源代码可在 GitHub 仓库“jetson-platform-services”中找到。
VLM AI 服务
第一步,围绕 VLM 构建一个微服务。Jetson Orin 上对 VLM 的支持,主要依赖 nanoLLM 项目。如图 4 所示,我们通过 nanoLLM 的 Python API 在 Jetson 上下载、量化、运行 VLM,然后将其封装成一个微服务。具体步骤如下:
- 用一个函数封装模型,方便调用;
- 用 FastAPI 添加 REST API 和 WebSocket 服务;
- 用 mmj_utils 处理 RTSP 流的输入和输出;
- 将元数据输出到你所需的目标——例如 Prometheus、Websocket 或 Redis。

图 4. VLM AI 服务架构
微服务启动后,就是一个不断重复的主循环:检索帧、更新 REST API 的提示词、调用模型、输出结果。下面的伪代码清晰地说明了这个过程:
# Add REST API
api_server = APIServer(prompt_queue)
api_server.start()
# Add Monitoring Metrics
prometheus_metric = Gauge()
prometheus.start_http_server()
# Add RTSP I/O
v_input = VideoSource(rtsp_input)
v_output = VideoOutput(rtsp_output)
# Load Model
Model = model.load()
While True:
#Update Image & Prompt
image = v_input.capture()
prompt = prompt_queue.get()
# Inference Model
model_output = predict(image, prompt)
# Generate outputs
metadata = generate_metadata(image, model_output)
overlay = generate_overlay(image, model_output)
# Output to Redis, Monitoring, RTSP
redis_server.xadd(metadata)
Prometheus_metric.set(metadata)
v_output.render(overlay)
我们在 GitHub 上提供了一个实用程序库,里面已经集成了这些常见组件,可以作为起点。完整的参考示例也在其中。
提示工程
如图 5 所示,VLM 的提示词主要包含三个部分:系统提示、用户提示和输入框。通过调整系统提示和用户提示,我们可以教会模型如何评估实时流上的警报,并要求它用结构化的格式输出结果——这样后续的服务才能方便地解析和集成。
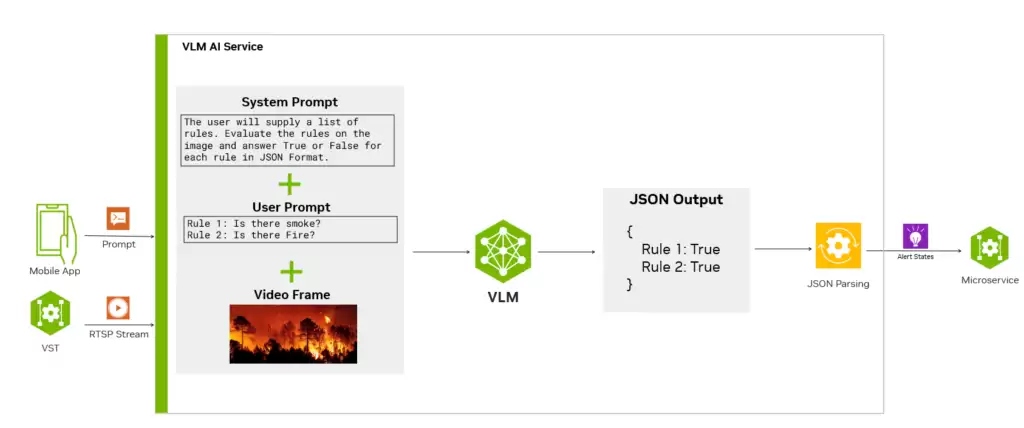
图 5. 使用 VLM 生成警报流程
举个例子:系统提示用来解释输出格式和模型目标。我们可以告诉模型,用户会提供一个警报列表。模型的任务是逐个评估每条警报的真假,最终以 JSON 格式输出结果。而用户提示则通过 REST API 动态提供。一个端点负责接收查询和警报输入,用户输入的内容与系统提示组合后,与实时流中的一帧画面一同喂给 VLM。模型对完整的提示进行评估后,生成一个回答。
回答被解析成 JSON 后,我们将其与警报监控服务、WebSockets 集成,这样就可以追踪警报状态,并实时推送到移动应用上。
与Jetson平台服务和移动应用集成
现在,一个完整的端到端系统已经成型。图 6 展示了 VLM、Jetson 平台服务、云端和移动应用之间的架构关系。
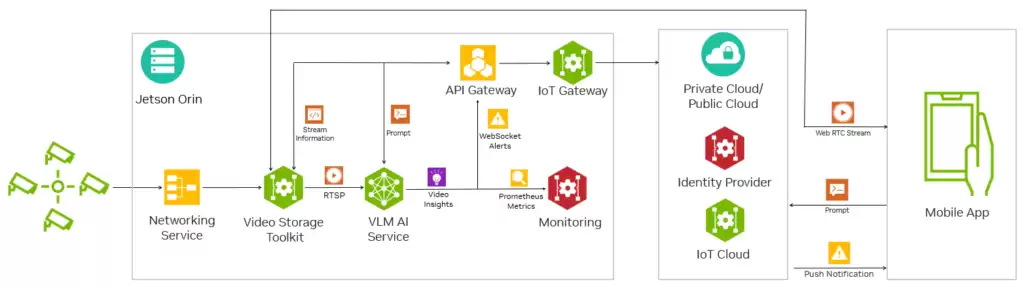
图 6. 使用 Jetson 平台服务的 VLM AI 服务工作流
视频输入由 Jetson 平台服务中的“网络服务”和 VST 组件自动发现并管理。联网的 IP 摄像头会被自动识别,并通过 VST 的 REST API 统一提供给 VLM 服务和移动应用。移动应用通过 API Gateway 访问 VST 和 VLM 的服务。
在应用中,用户可以看到 VST 提供的实时流列表,并进行预览。接着,用户可以用自然语言对选中的实时流设置自定义警报——例如“是否发生火灾”。提交后,应用会调用 VLM 服务的“流控制”API,指定使用哪个摄像头作为输入;然后调用“警报”API 来设置 VLM 的警报规则。收到这两个请求后,VLM 就开始评估实时流上的规则。
当 VLM 判定警报为“真”时,它会通过 WebSocket 将状态推送到移动应用,触发手机上的通知弹窗。用户点击通知,就能进入聊天模式,继续追问更多细节。

图 7. 通过移动应用进行视频直播和聊天
如图 7 所示,用户可以和 VLM 就输入的实时流进行来回对话。甚至还能利用 VST 的 WebRTC 功能,直接在应用内查看实时画面。
通过 VLM、Jetson 平台服务和移动应用的组合,现在,你可以为连接到 Jetson 的任何实时流摄像头,设置任何你想要的自定义警报,并在第一时间收到通知。
视频 1. 在边缘构建生成式 AI 驱动的视频智能体演示
结论
总体而言,本文梳理了如何将 VLM 与 Jetson 平台服务相结合,构建出真正的视觉 AI 智能体。如果想快速上手,可以访问 Jetson 平台服务产品页面,那里提供了预构建的 VLM AI 服务容器和预构建的安卓应用 APK。GitHub 上也有 VLM AI 服务的完整源代码,是学习如何用 VLM 构建微服务的绝佳参考资料。
```你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:生成式人工智能赋能边缘计算视觉AI智能体开发要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点“训练数据的质量,直接影响大模型的最终表现,这一观点绝非夸张”决定大模型最终质量的关键因素,除了模型架构设计,更重要的其实是训练数据。从某种意义上讲,数据的质量几乎直接决定了模型能力的上限。那么,面对海量且杂乱无章的原始信息,如何才能梳理出真正适用于大模型训练的高质量数据集?这无疑是值得深入探讨的问
基于WordEmbedding与LSTM构建编码器-解码器架构,实现新闻正文到短标题的序列生成。预处理包括分词、词表截断及长度统一,双向LSTM编码正文,单向LSTM解码并加入注意力机制,采用TeacherForcing训练及AdamW优化,最终导出ONNX部署。
(文章来源:润建股份) 2025年5月28日,润建股份有限公司与环江毛南族自治县人民政府正式签署战略合作协议。此次政企合作聚焦于城市AI生态建设,致力于借助人工智能技术为县域数字化高质量发展注入全新动能。 签约仪式现场,环江毛南族自治县党委副书记吴履伟、党委常委副县长聂云鹏,县发改局、大数据局、文旅
多模态大模型在处理单张图像时已经表现得相当出色,但一旦涉及长序列图片的理解,挑战便接踵而至——计算成本急剧上升,信息丢失也几乎难以避免。那么,如何突破这一瓶颈?近期,阿里开源的mPLUG-Owl3提出了一种颇具巧思的解决方案。它不仅擅长单图任务,更重要的是,在面对长图文序列、混合图文内容乃至长视频场
- 日榜
- 周榜
- 月榜
热点快看