




如何从零开始微调Llama 3进行序列分类完整教程

利用HuggingFace库在Kaggle上微调Llama38B模型完成序列分类任务。通过4位量化与LoRA适配低显存GPU,使用ag_news数据集(4类新闻)训练子集。预处理包括标签均衡化、数据集拆分及类别权重计算,最后替换模型输出头为4神经元线性层。
大型语言模型之所以出名,靠的就是文本生成能力。预训练阶段,它们啃下了数百万个token,练就了一身理解英文文本、生成完整句子的本领。
不过,自然语言处理里还有一个常见的活儿:序列分类任务——把给定的文本分到不同类别里。用大模型通过prompt硬上,偶尔能行,但效果不稳定。真正靠谱的做法,是对大模型做一番调整,让它针对每个类别输出一组概率。这篇指南就带大家走一遍完整流程,看看怎么用微调后的Llama 3模型搞定序列分类。

导入库
这次我们直接在Kaggle上干活。先把微调Llama 3所需的一堆库装好,跑下面这行代码就行:
!pip install -q transformers accelerate trl bitsandbytes datasets evaluate huggingface-cli
!pip install -q peft scikit-learn
下载库
装的是这些家伙:
- Transformers:HuggingFace家的老牌库,下载模型、搭应用、微调深度学习模型(包括大语言模型)全靠它。
- 加速(Accelerate):同样是HuggingFace出品,给GPU上跑大模型推理加速的。
- Trl:HuggingFace的一个Python包,专门用来微调HuggingFace Hub上的模型,连大模型也能搞定。
- bitsandbytes:大模型吃内存太狠了,低显存GPU想直接用,得先量化——把精度降下来,这个库就是干这事的。
- 数据集(Datasets):HuggingFace的数据集库,图像分类、文本生成、文本摘要……各种开源数据集随便下。
- 评估(Evaluate):训练前后评估模型用的。
- Huggingface-cli:必须装,因为要用Llama 3得先登录HuggingFace。
- peft:手里的GPU显存有限,不可能把大模型所有参数都训一遍,只训一部分参数就行——peft库正是干这个的。
- Scikit-learn:机器学习常用工具,这里用它来计算误差指标,对比训练前后模型的效果。
装完之后,记得登录HuggingFace中心。用huggingface-cli工具:
!huggingface-cli login --token $YOUR_HF_TOKEN
代码解释
这里调用了huggingface-cli的login选项,后面跟上--token参数,把HuggingFace的访问令牌传进去。去这个链接创建或复制一个令牌,然后贴到YOUR_HF_TOKEN位置就行。下图展示了新建令牌的界面:
加载数据集
下面把训练用的数据集搞进来:
from datasets import load_dataset
dataset = load_dataset("ag_news")
- 先从
datasets库导入load_dataset函数。 - 然后用数据集名字
"ag_news"调用它。
跑完这行,ag_news数据集就下载到dataset变量里了。这个数据集长这样:

这是一个新闻分类数据集,新闻被分成世界、体育、商业、科学/技术四类。先看看每个类别的样本数量是否均衡:
import pandas as pd
df = pd.DataFrame(dataset['train'])
df.label.value_counts(normalize=True)

代码解释
- 先导入pandas。
ag_news数据集包含训练集和测试集,是DatasetDict类型。为了方便操作,转成pandas DataFrame。- 然后对DataFrame的
label列调用value_counts(normalize=True),查看比例。
输出显示四个标签比例相同,说明每个类别样本数一样。不过数据集很大,我们只需要一部分。下面从DataFrame里抽取子集:
# Splitting the dataframe into 4 separate dataframes based on the labels
label_1_df = df[df['label'] == 0]
label_2_df = df[df['label'] == 1]
label_3_df = df[df['label'] == 2]
label_4_df = df[df['label'] == 3]
# Shuffle each label dataframe
label_1_df = label_1_df.sample(frac=1).reset_index(drop=True)
label_2_df = label_2_df.sample(frac=1).reset_index(drop=True)
label_3_df = label_3_df.sample(frac=1).reset_index(drop=True)
label_4_df = label_4_df.sample(frac=1).reset_index(drop=True)
# Splitting each label dataframe into train, test, and validation sets
label_1_train = label_1_df.iloc[:2000]
label_1_test = label_1_df.iloc[2000:2500]
label_1_val = label_1_df.iloc[2500:3000]
label_2_train = label_2_df.iloc[:2000]
label_2_test = label_2_df.iloc[2000:2500]
label_2_val = label_2_df.iloc[2500:3000]
label_3_train = label_3_df.iloc[:2000]
label_3_test = label_3_df.iloc[2000:2500]
label_3_val = label_3_df.iloc[2500:3000]
label_4_train = label_4_df.iloc[:2000]
label_4_test = label_4_df.iloc[2000:2500]
label_4_val = label_4_df.iloc[2500:3000]
# Concatenating the splits back together
train_df = pd.concat([label_1_train, label_2_train, label_3_train, label_4_train])
test_df = pd.concat([label_1_test, label_2_test, label_3_test, label_4_test])
val_df = pd.concat([label_1_val, label_2_val, label_3_val, label_4_val])
# Shuffle the dataframes to ensure randomness
train_df = train_df.sample(frac=1).reset_index(drop=True)
test_df = test_df.sample(frac=1).reset_index(drop=True)
val_df = val_df.sample(frac=1).reset_index(drop=True)
- 数据有4个标签,先按标签拆成4个单独DataFrame。
- 然后用
sample打乱每个标签的数据。 - 再把每个标签DataFrame切成三份:训练2000条、测试500条、验证500条。
- 接着用
pd.concat把所有标签的训练数据拼成train_df,测试和验证同理。 - 最后再分别打乱一次,保证随机性。
检查价值很重要
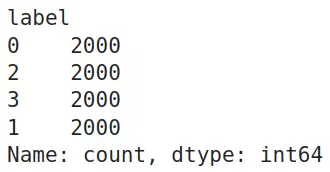
确认一下训练数据里每个标签的数量:
train_df.label.value_counts()
Pandas DataFrames 到 DatasetDict
OK,训练集四个标签数量一致。不过在送去训练之前,得把pandas DataFrame转成HuggingFace训练器能吃的DatasetDict:
from datasets import DatasetDict, Dataset
# Converting pandas DataFrames into Hugging Face Dataset objects:
dataset_train = Dataset.from_pandas(train_df)
dataset_val = Dataset.from_pandas(val_df)
dataset_test = Dataset.from_pandas(test_df)
# Combine them into a single DatasetDict
dataset = DatasetDict({
'train': dataset_train,
'val': dataset_val,
'test': dataset_test
})
dataset

代码解释
- 先从
datasets库导入DatasetDict类。 - 然后把
train_df、test_df、val_df分别转成HuggingFace的Dataset类型。 - 最后合并成一个
DatasetDict,存到dataset变量里。
从输出能看到,DatasetDict包含三个子集:训练、测试、验证,每个子集只有两列:文本和标签。
这里每个类别的比例是均匀的。但在实际项目中,类别不平衡才是常态。如果遇到不平衡,需要计算类别权重,让大模型不要偏向样本多的类别。类别权重越大,该类别的重要性越高。计算方法是取类别标签比例(value_counts(normalize=True))的倒数。代码如下:
import torch
class_weights=(1/train_df.label.value_counts(normalize=True).sort_index()).tolist()
class_weights=torch.tensor(class_weights)
class_weights=class_weights/class_weights.sum()
class_weights
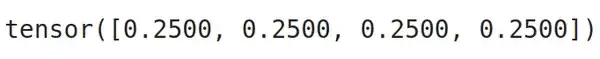
代码解释
- 先取标签值计数的倒数。
- 从列表转成torch张量。
- 然后除以总和做归一化。
输出显示所有类别权重相等——因为样本本来就是均衡的。
模型加载-量化
接下来下载并准备模型。手里的GPU显存不大,没法扛完整模型,得量化一下:
from transformers import BitsAndBytesConfig, AutoModelForSequenceClassification
quantization_config = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_quant_type = 'nf4',
bnb_4bit_use_double_quant = True,
bnb_4bit_compute_dtype = torch.bfloat16
)
model_name = "meta-llama/Meta-Llama-3-8B"
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
quantization_config=quantization_config,
num_labels=4,
device_map='auto'
)
代码解释
- 从
transformers导入BitsAndBytesConfig和AutoModelForSequenceClassification。 - 定义量化配置:
load_in_4bit=True表示量化到4位精度;bnb_4bit_quant_type选推荐的'nf4'(Normal Float);bnb_4bit_compute_dtype设为torch.bfloat16(取决于GPU);bnb_4bit_use_double_quant=True可以进一步省显存。 - 模型名字给
"meta-llama/Meta-Llama-3-8B"。 - 用
AutoModelForSequenceClassification加载,注意传了num_labels=4——这个类会自动把Llama 3最后一层换成含4个神经元的线性层,适配我们的分类任务。 device_map='auto'让模型自动加载到GPU。
跑完这步,Llama 3 8B就从HuggingFace Hub下载下来了,按量化配置压缩,输出头换成4神经元的线性层,然后送到GPU。接下来创建LoRA配置,只训练一小部分参数:
LoRA 配置
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
lora_config = LoraConfig(
r = 16,
lora_alpha = 8,
target_modules = ['q_proj', 'k_proj', 'v_proj', 'o_proj'],
lora_dropout = 0.05,
bias = 'none',
task_type = 'SEQ_CLS'
)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, lora_config)
代码解释
- 从
peft导入LoraConfig、prepare_model_for_kbit_training、get_peft_model。 - 实例化
LoraConfig:r=16(训练的参数矩阵秩);lora_alpha=8(超参数,通常设为r的一半);target_modules选所有注意力层(K、Q、V和输出投影);lora_dropout=0.05随机丢弃防止过拟合;bias='none';task_type='SEQ_CLS'(序列分类)。 - 用
prepare_model_for_kbit_training预处理量化模型,以便训练。 - 最后用
get_peft_model把模型和LoRA配置包装起来。
运行后,模型就准备好用PEFT(这里是LoRA)只训练部分参数了。
模型测试 – 预训练
正式训练之前,先在测试数据上看看Llama 3的原始表现。先下载分词器:
from transformers import AutoTokenizer
model_name = "meta-llama/Meta-Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name, add_prefix_space=True)
tokenizer.pad_token_id = tokenizer.eos_token_id
tokenizer.pad_token = tokenizer.eos_token
代码解释
- 导入
AutoTokenizer。 - 用
from_pretrained加载分词器。 - 把
pad_token和pad_token_id设为eos_token(因为Llama没有专门的填充标记)。
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = False
model.config.pretraining_tp = 1
再把模型配置也同步一下,关掉缓存。现在把测试数据喂给模型,收集输出:
sentences = test_df.text.tolist()
batch_size = 32
all_outputs = []
for i in range(0, len(sentences), batch_size):
batch_sentences = sentences[i:i + batch_size]
inputs = tokenizer(batch_sentences, return_tensors="pt",
padding=True, truncation=True, max_length=512)
inputs = {k: v.to('cuda' if torch.cuda.is_a vailable() else 'cpu') for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
all_outputs.append(outputs['logits'])
final_outputs = torch.cat(all_outputs, dim=0)
test_df['predictions']=final_outputs.argmax(axis=1).cpu().numpy()
代码解释
- 把测试DataFrame的文本列转成句子列表。
- 设置batch大小为32。
- 建一个空列表
all_outputs存输出。 - 按batch遍历句子,用分词器编码(padding、truncation、max_length=512)。
- 把编码后的输入移动到设备(GPU或CPU)。
- 在
torch.no_grad()下推理,将输出的logits追加到all_outputs。 - 最后用
torch.cat拼接所有输出,取每个logits的argmax(概率最高的标签),写入测试DataFrame的predictions列。
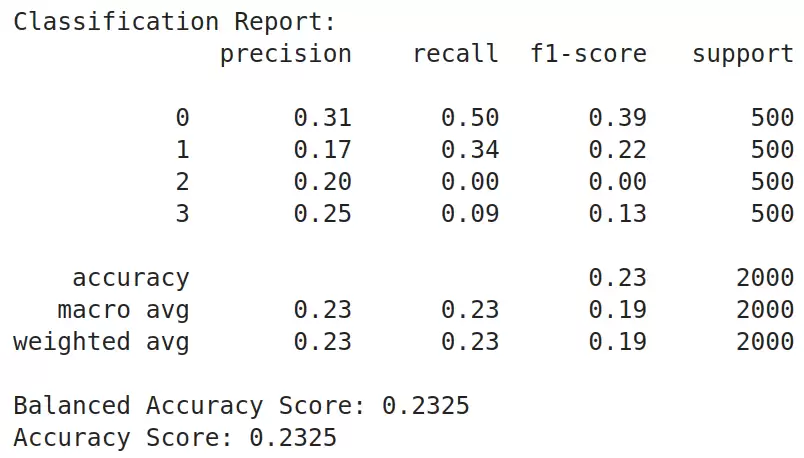
评估一下模型的表现:
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.metrics import balanced_accuracy_score, classification_report
def get_metrics_result(test_df):
y_test = test_df.label
y_pred = test_df.predictions
print("Classification Report:")
print(classification_report(y_test, y_pred))
print("Balanced Accuracy Score:", balanced_accuracy_score(y_test, y_pred))
print("Accuracy Score:", accuracy_score(y_test, y_pred))
get_metrics_result(test_df)
代码解释
- 导入
accuracy_score、balanced_accuracy_score、classification_report。 - 定义
get_metrics_result()函数,接收DataFrame,打印分类报告、准确率和平衡准确率。
跑出来准确率只有0.23,惨不忍睹。精度、召回率、F1也都不到50%。等训练完再测,就知道进步多大了。
开始训练之前,得先对数据做预处理:
def data_preprocesing(row):
return tokenizer(row['text'], truncation=True, max_length=512)
tokenized_data = dataset.map(data_preprocesing, batched=True,
remove_columns=['text'])
tokenized_data.set_format("torch")
代码解释
- 定义
data_preprocessing()函数,把每行文本传给分词器,设置截断、最大长度512。 - 用
dataset.map应用到整个数据集,同时删掉原始的text列。 - 最后把数据转成torch格式。
现在,DatasetDict里的每个子集都包含三列:label、input_ids、attention_mask。训练时需要一个数据整理器来批量处理:
from transformers import DataCollatorWithPadding
collate_fn = DataCollatorWithPadding(tokenizer=tokenizer)
- 导入
DataCollatorWithPadding,实例化时传入分词器。 - 这个整理器会把每个batch内的输入统一填充到当前batch的最大长度,用填充标记补齐——这是批量训练提速的关键。
Finetune Llama 3:模型训练和训练后评估
训练之前,需要定义评估指标。大模型默认用负对数似然损失,但我们改了模型做序列分类,得重新定义:
def compute_metrics(evaluations):
predictions, labels = evaluations
predictions = np.argmax(predictions, axis=1)
return {'balanced_accuracy' : balanced_accuracy_score(predictions, labels),
'accuracy':accuracy_score(predictions,labels)}
- 函数接收包含预测和标签的元组。
- 用
np.argmax取概率最高的索引。 - 返回平衡准确度和原始准确度。
因为要用自定义指标,而且我们还有类别权重,所以得写一个自定义训练器:
class CustomTrainer(Trainer):
def __init__(self, *args, class_weights=None, **kwargs):
super().__init__(*args, **kwargs)
if class_weights is not None:
self.class_weights = torch.tensor(class_weights,
dtype=torch.float32).to(self.args.device)
else:
self.class_weights = None
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels").long()
outputs = model(**inputs)
logits = outputs.get('logits')
if self.class_weights is not None:
loss = F.cross_entropy(logits, labels, weight=self.class_weights)
else:
loss = F.cross_entropy(logits, labels)
return (loss, outputs) if return_outputs else loss
代码解释
- 自定义
CustomTrainer继承自HuggingFace的Trainer。 __init__中若传了class_weights,就转成torch张量并移到设备上。compute_loss重写:从输入中取出标签,模型前向传播得到logits,然后计算交叉熵损失,若有类别权重就传入weight参数。
训练论点
定义训练参数:
training_args = TrainiAgrumentsngArguments(
output_dir = 'sentiment_classification',
learning_rate = 1e-4,
per_device_train_batch_size = 8,
per_device_eval_batch_size = 8,
num_train_epochs = 1,
logging_steps=1,
weight_decay = 0.01,
evaluation_strategy = 'epoch',
sa ve_strategy = 'epoch',
load_best_model_at_end = True,
report_to="none"
)
代码解释
- 实例化
TrainingArguments:指定输出目录、学习率1e-4、每个设备训练/评估batch大小8、训练1个epoch、每步日志、权重衰减0.01、每个epoch保存并评估一次、训练结束时加载最佳模型。
将物体传递给训练员
把TrainingArguments对象传给自定义训练器:
trainer = CustomTrainer(
model = model,
args = training_args,
train_dataset = tokenized_datasets['train'],
eval_dataset = tokenized_datasets['val'],
tokenizer = tokenizer,
data_collator = collate_fn,
compute_metrics = compute_metrics,
class_weights=class_weights,
)
train_result = trainer.train()
代码解释
- 创建
CustomTrainer对象,传入模型、训练参数、训练/验证数据、分词器、整理器、自定义指标、类别权重。 - 调用
.train()开始训练,结果存到train_result。

代码解释
- 训练走了1000步(8000条数据,batch=8,正好1000步)。
- 耗时2小时36分钟,完成1个epoch。
- 训练损失1.12,验证损失0.29,验证集准确率高达93%。
现在在测试数据上评估一下微调后的模型:
def generate_predictions(model,df_test):
sentences = df_test.text.tolist()
batch_size = 32
all_outputs = []
for i in range(0, len(sentences), batch_size):
batch_sentences = sentences[i:i + batch_size]
inputs = tokenizer(batch_sentences, return_tensors="pt",
padding=True, truncation=True, max_length=512)
inputs = {k: v.to('cuda' if torch.cuda.is_a vailable() else 'cpu')
for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
all_outputs.append(outputs['logits'])
final_outputs = torch.cat(all_outputs, dim=0)
df_test['predictions']=final_outputs.argmax(axis=1).cpu().numpy()
generate_predictions(model,test_df)
get_performance_metrics(test_df)
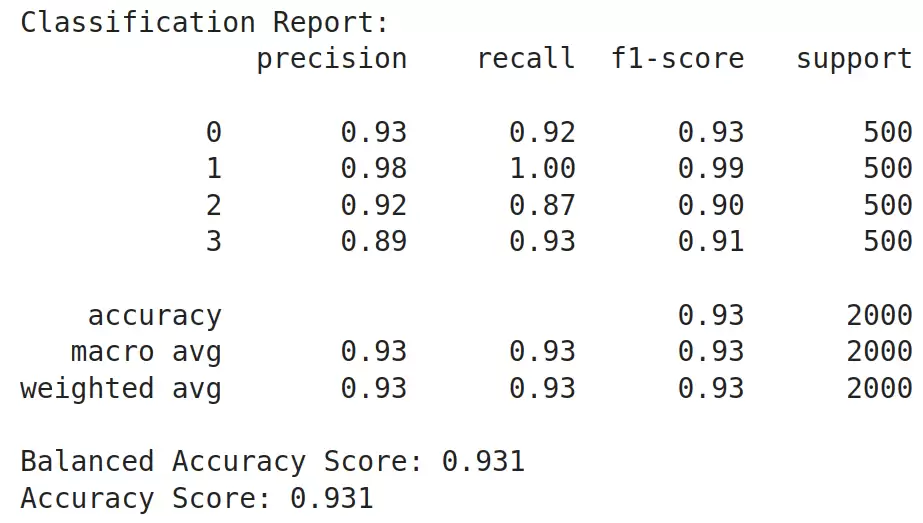
代码解释
- 定义
generate_predictions,流程和之前类似:取文本列表,分batch,分词,推理,取argmax,存回DataFrame。 - 然后调
get_performance_metrics输出结果。
结果很亮眼:准确率从训练前的0.23飙升到0.93,精度、召回率、F1也全面上涨。这充分说明,大语言模型稍加微调,就能成为非常优秀的序列分类器。
结论
总的来说,用Llama 3做序列分类的微调,从数据集准备、量化模型到训练评估,每一步都有讲究。借助HuggingFace的各种库,配合prompt工程和LoRA等技术,完全能在有限硬件上高效地让大模型完成新闻分类这类特定任务。这篇指南从零开始,走通了完整的流程:数据预处理、模型加载量化、LoRA配置、自定义训练器、评估对比,充分展示了LLM在自然语言处理任务中的灵活性和实力。
关键要点
- 大型语言模型(比如Llama 3)在大量数据上预训练后,生成和理解文本的能力很强。
- 光靠prompt有时不够,微调能带来更稳定的分类性能。
- 数据集的正确加载、拆分和平衡,是训练公平准确模型的基础。
- 自定义误差指标和训练循环,能灵活处理类别权重等特殊需求。
- 训练前后用准确率、平衡准确率等指标评估,能直观看到微调的效果。
(完)
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:如何从零开始微调Llama 3进行序列分类完整教程要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点最近国内AI厂商的动作相当密集,大模型纷纷降价,新应用层出不穷——百小应、海螺AI、腾讯元宝轮番登场,热闹非凡。紧跟这一节奏,豆包也放出了几项新功能: - **开放新版本抢先体验入口**:更强大的能力搭配全新视觉设计,用户体验显著提升; - **推出全新桌面客户端**:实测发现,这并非简单的网页打包
海螺水泥近日发布了2025年度业绩报告,全年实现营业收入825 32亿元,同比下降9 33%,但净利润逆势增长5 42%,达到81 13亿元。这是近五年来净利润首次恢复正增长,背后核心驱动因素清晰:极致成本管控、海外高毛利业务持续扩张,叠加“水泥+”产业链延伸带来的协同效应。 如果你翻阅海螺AI生成
大模型正通过自然语言推动数据治理向对话化演进,降低技术门槛并提升效率。应用场景包括元数据发现与知识图谱生成、代码生成与校正、对话式管理界面。但仍面临幻觉、安全隐私、成本上升及数据质量等风险,需人工干预与技能培训。
先说几个核心观察。狗狗币(DOGE)目前正逼近0 10美元这个关键心理关口,更重要的是,它正在测试一个重要的技术支撑位。回顾过去一周,DOGE价格下跌了5 97%,跌至0 099美元附近。自2024年12月的高点以来,狗狗币持续走低,高点与低点同步下移,甚至一度触及0 082美元的长期支撑位。这种走
- 日榜
- 周榜
- 月榜
热点快看