




请提供原始文章标题以便优化

大语言模型输出存在不准确信息、偏见及恶意使用三类问题。控制技术包括编辑预训练数据、监督式微调、人类反馈强化学习及提示词过滤。目前可控性尚无完美解,需多种技术组合使用,并依赖多方协同推动持续优化。
大语言模型的复杂性,让“控制它的嘴”这件事成了一道公认的技术难题。2023年底,美国安全与新兴技术中心(CSET)发布了一份题为《控制大语言模型的输出:初级指南》的报告,系统梳理了LLM可能产生的有害输出,以及目前开发者用来应对这些挑战的主要技术手段。读完这份报告,一个核心结论会浮出水面:LLM可控性目前并没有完美解。在实际部署中,各种输出控制技术需要搭配使用,才能尽可能发挥实效。

为什么要控制大语言模型的输出?
说直白点,LLM本质上就是一个极其复杂的概率计算机器。它建立语言token(可以是一个单词、短语、词根,甚至标点符号)之间的关联,然后计算在给定提示词的情况下,每个token出现的概率有多大。模型反复挑选那个“最有可能出现”的token,一直到输出结束。这就意味着,语言模型压根不理解什么叫事实,什么叫真实性——它不是从某个知识库里去检索答案,更像一台“即兴表演机器”:擅长模仿模式,但没有任何内置机制去判断自己的输出到底对不对、有没有用、会不会伤到人。
具体来说,主要有三类让人头疼的输出问题:
1. 不准确信息
很多普通用户并不了解模型的局限性,容易盲目信任,觉得它说的就是事实——研究人员管这叫“过度依赖”。举个简单的例子:如果有人在健康问题上听信了LLM的“建议”,拿到了错误信息,很可能把自己置于危险境地。同样,整治领域里如果模型给出不实信息,用户也可能因此对候选人无端失去信任。随着LLM渗透率越来越高,这种“过度依赖”带来的风险只会越来越大。
2. 偏见或有毒输出
当然,不是说只有虚假内容才伤人。LLM一旦产生带有偏见(比如关于种族、性别、宗教等)或明显有害的文本,同样会引发大的麻烦。已有研究证实,LLM在整治立场、宗教信仰、性别议题上都存在可测度的偏见。更有意思的是,有研究把这些偏见一路追溯到训练数据,发现一些基于关键词从训练语料中剔除的内容,反而会不成比例地删除关于少数群体的文本——这就像一种“好心办坏事”的反噬。
3. 恶意使用
如果前面两种问题更多是模型“无心之失”,那恶意使用就是有人故意拿它当武器了。最极端的案例是:不良行为者利用LLM学习如何制造冲击波或生物武器。其他常见的恶意场景包括:用LLM搞黑客攻击、生成反诈文案、批量制造虚假信息文章等。

控制大语言模型输出的四种技术
从开发流程来看,LLM的诞生大致分成三个阶段:预训练、微调、部署。与之对应,不同的输出控制技术可以在不同阶段介入,从源头到出口层层设防。
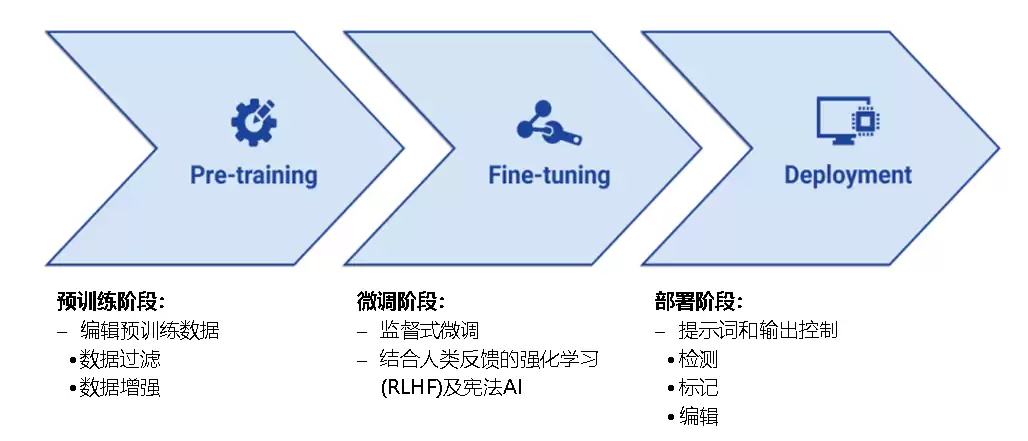
图1 LLM开发的三个阶段及相关的语言模型控制技术(来源:CSET,2023.12)
1. 编辑预训练数据
一个流行的误解是:既然模型学了什么数据就产出什么内容,那是不是直接修改训练数据就能轻松控制它的行为?想象很美好,现实却要复杂得多。LLM预训练的数据量庞大到难以想象,想提前判断某一批数据的变化会如何影响模型最终的表现——尤其是有害输出的倾向——几乎是不可能的。
理论上,操纵训练数据确实是控制模型行为的强力机制,但它绝不是包治百病的“万能药”。尤其当危害和意义都高度依赖上下文语境时,单纯靠数据过滤根本不够。内容过滤器和数据来源最终确实会影响模型的行为,但研究人员至今没有完全搞清楚:到底该怎么操控数据才能既有效影响模型,又把性能损失降到最低?相比之下,在精心策划的小型数据集上预训练那些小尺寸、专门化的语言模型,数据过滤或增强也许更容易出效果。但对于大模型开发者来说,恐怕还得靠其他方法。
2. 监督式微调
预训练之后,开发者可以在专门的数据集上进一步训练模型,调整它的行为——这个过程叫监督式微调,也是修改模型最常用的手段之一。它的目标通常是提升模型在某个特定领域的表现。模型接触的高质量领域数据越多,它在匹配上下文中预测下一个token的方式就越对人类胃口。
在合适的场景下,只要有合适的数据,监督式微调是非常强大的工具,尤其是针对特定领域或应用场景做定制化调整。注意这里的“监督”是指模型拿到了人工标注过的数据,因此省去了先自己从数据里找模式和关联性这一步。但问题在于,有效的监督式微调高度依赖于能否获取专业、高质量的数据集,而这类数据集在某些领域要么根本不存在,要么无法准确捕获研究人员想要控制的行为。因此,业界的目光也转向了那些不依赖专业数据,或者能更灵活引导模型行为的技术。
3. 人类反馈强化学习(RLHF)及符合“宪法”的AI
RLHF是一种借助另一个机器学习模型(即“奖励模型”)来微调LLM的技术。它的流程是:先让原始LLM生成一批文本输出,然后由人工标注者根据某些准则对这些输出排序。与前面提到的监督式微调不同——监督式微调更多是打造一个在专业领域表现优异的模型,不一定涉及对“对/错”的判断——RLHF的核心逻辑很明确:让人类的偏好直接参与到模型行为塑造中。
但RLHF有个硬伤:它太依赖“人”了。只要还需要人工标注,LLM创建者在这个环节能拿到的反馈量就注定有限,毕竟人的时间成本和金钱成本都相当高。更糟糕的是,如果反馈流程设计得不够科学,模型很可能会学会“讨好”,即最大化获得好评,但这并不等于它真的输出了人类用户偏好的内容。
Anthropic开发的“宪法”AI(Constitutional AI)则提供了一种另类思路。它试图尽可能少用人类指导来约束模型行为。和RLHF不同,“宪法”AI不直接依靠人工标签或注释,而是由研究人员提供一套指导规则(即“宪法”),本质上是通过另一个模型来评估、修订自己的输出。尽管“宪法”AI有望成为RLHF的替代品(毕竟它大大减少了人工标注量),但从行业现状来看,RLHF目前仍然是微调阶段引导LLM的公认标准。
4. 提示词和输出控制
哪怕经过了预训练和多轮微调,LLM依然可能跑偏。因此在把模型包装成面向消费者的产品之前,开发者还会在输出前/后阶段补充一些控制技术。这类技术通常被称作“输入过滤器”(用在输出前)和“输出过滤器”(用在输出后),核心动作就三个步骤:检测、标记、编辑。
在用户输入还没进模型之前,开发者可以先筛一遍提示词,评估它会不会引发有害文本,必要时刻直接显示警告或拒绝响应。这相当于模型自己长出了一层“嘴巴把门”的能力。
一旦模型已经对提示词做出了响应,但在输出内容呈现在用户眼前之前,开发者还可以再做一道检查。和监督式微调类似,这些过滤技术同样依赖人类标注的数据。微调阶段之后的控制,通常还会与监控或用户举报机制协同运作,具体包括自动内容检测/过滤、人工内容审核以及用户举报的组合拳。最后一道防线,则是用户反馈机制。如果所有已有的控制手段都失灵了,LLM界面上的反馈按钮,至少能让用户把漏网之鱼标记出来。毕竟开发者很难穷尽每一种可能引发有害输出的提示词或场景,最终还得靠用户来帮助“纠偏”。

思考与启示
2023年8月,《生成式人工智能服务管理暂行办法》正式施行。这不仅是禁止生成违法违规内容那么简单,它还明确要求:在模型生成和优化过程中,必须采取有效措施防止产生民族、信仰、国别、地域、性别、年龄、职业、健康等歧视;并且要提高生成内容的准确性和可靠性。这套监管逻辑,与LLM输出控制的目标高度契合。
1. LLM可控性尚无完美解
可控性,可以说是LLM研究中最受关注的课题之一。但坦率地说,学术界目前没有完美方案。用CSET报告的原话讲:“即使是最前沿的控制措施,也不能保证LLM永远不产生非期望输出。” 开发者再怎么努力,翻车的时刻依然无法完全避免。更麻烦的是,任何试图以特定方式控制模型的行为,都可能引发意想不到的连锁反应。所以,实践中唯一的可行路径,就是把各种输出控制技术组合起来用,力争把综合效果最大化。
2. 多方协同推动各环节逐步逼近
这条路显然不是单靠某个角色就能走通的。一方面,监管部门和产业界需要形成合力,坚持包容审慎的原则,共同搭建可信可控的大模型监管体系。另一方面,要提升LLM输出结果的可控性,就不能只盯一个维度——内容的准确性、价值观的一致性、决策过程的透明度与可解释性、输出内容的安全合规性,缺一不可。最后,行业评测体系的建设也迫在眉睫。只有依托科学有效的评测工具和方法,才能真正高效地评估LLM生成内容的质量,推动大模型向着更可控的方向持续进化。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:请提供原始文章标题以便优化要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GLM-5与MiniMaxM2 5性能出众,但OpenClaw原生不支持新模型,需等待官方发版升级。针对此痛点,HigressAI网关通过热更新与解耦配置,仅需一句话即可添加任意新模型,无需重启即时生效,显著简化模型接入过程,快速解决适配难题。
英伟达季度股息从0 01美元升至0 25美元,回购计划增加800亿美元,营收同比增85%至816亿美元,净利润增长两倍,市销率近21倍,股息收益率不足0 5%,人工智能处理器主导地位稳固。苹果股息提升4%至0 27美元,自研AI处理器,服务收入出色,市值4 5万亿美元,年销售额4160亿美元,股息收益率0 3%。
豆包AI同声传译需配置五项操作:启用麦克风、存储和无障碍权限,启动实时双语对话模式,开启字幕与语音播报联动,使用翻译工具页精确控制,或通过钉钉与豆包组合实现跨设备同传。
在Windows系统下,使用Ollama部署本地大语言模型,通过Docker运行OpenWebUI提供网页交互界面,再借助cpolar内网穿透实现公网访问并可配置固定二级子域名,打造私有、可控、可远程调用的AI助手。
- 日榜
- 周榜
- 月榜
热点快看