




微软新架构突破Decoder-Only,20GB显存运行Llama3 70B

微软清华提出YOCO架构,仅需一次缓存键值对,大幅降低GPU内存,性能媲美Transformer。处理512K上下文时,内存仅1 6 4,预填充延迟1 30 3,吞吐量提升9 6倍,长上下文准确率近100%。
西风 发自 凹非寺
微软与清华大学的最新联合研究,成功打破了GPT系列所开创的Decoder-Only架构垄断局面——他们提出了一种全新的Decoder-Decoder架构,命名为YOCO(You Only Cache Once)。
YOCO最突出的亮点在于:整个推理过程中仅需缓存一次键值对数据。这意味着什么?它能大幅降低GPU内存需求,同时完整保留全局注意力能力,显著提升长上下文处理效率。
下面通过一张图来直观对比YOCO与标准Transformer的差异。
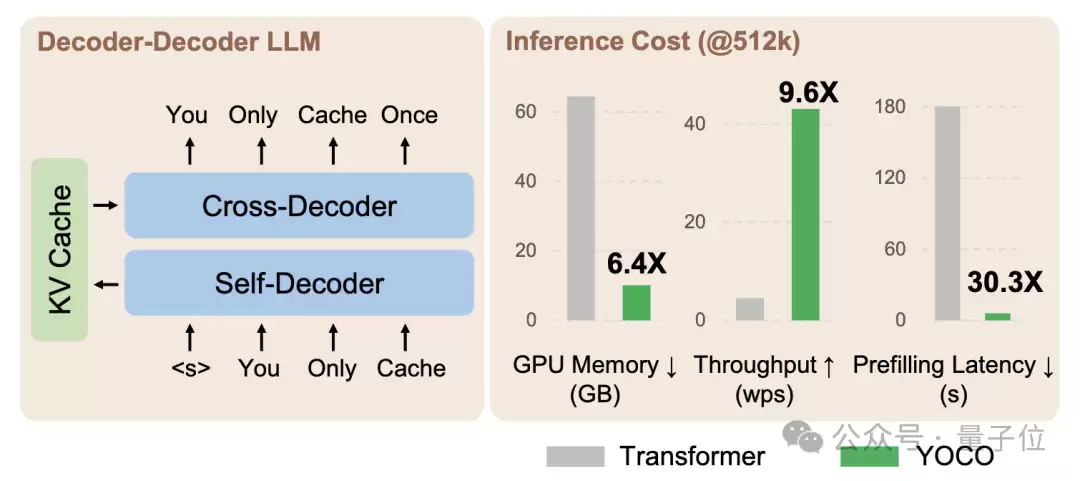
在处理512K上下文长度时,标准Transformer的内存占用是YOCO的6.4倍,预填充延迟更是高达YOCO的30.3倍。而在吞吐量方面,YOCO实现了9.6倍的惊人提升。
去年曾在学术圈广为流传的“大语言模型进化树”动图中,主流架构还只分为三大类:Decoder-Only、Encoder-Only、Encoder-Decoder。如今,全新的成员正式加入。
这个Decoder-Decoder架构究竟隐藏着怎样的技术玄机?接下来为您详细解读。

打破Decoder-Only垄断
YOCO的整体架构非常清晰,主要分为两大核心模块:自解码器(Self-Decoder)和交叉解码器(Cross-Decoder)。
具体来说,YOCO由L个块堆叠而成。前L/2层为自解码器,负责“生产”全局的键值缓存;后续模块为交叉解码器,负责“重用”这些缓存,实现高效推理。
自解码器的核心是高效自注意力(efficient self-attention)机制,用于获取键值(KV)缓存:它接收输入序列的嵌入表示,通过高效自注意力生成中间向量表示,同时使用因果掩码(causal masking)保证解码的自回归特性。自解码器的输出最终用于生成全局KV缓存。
而交叉解码器则通过交叉注意力(cross-attention)来重用自解码器生成的共享KV缓存:它在自解码器生成的KV缓存基础上进行堆叠,得到最终的输出向量。同样采用因果掩码维持自回归生成特性。这种设计使得交叉解码器层之间可以高效复用KV缓存,从而大幅减少了对GPU内存的消耗。
整体而言,自解码器和交叉解码器的模块设计与Transformer解码器层类似,都包含交错注意力和前馈网络子层。不过研究人员还引入了预RMSNorm、SwiGLU以及分组查询注意力等关键改进。
两部分之间的核心区别在于注意力模块。自解码器使用的是高效自注意力,例如滑动窗口注意力(Sliding-Window Attention)或门控保留(gated retention)。而交叉解码器则采用标准的、但效率更高的多头交叉注意力——其Query向量通过注意力机制与自解码器产生的全局键值缓存建立关联。
推理阶段大幅节省资源
在实验环节,研究人员将YOCO模型与同体量的Transformer模型进行了全方位的对比测试。
分析维度主要从四个角度展开:语言建模评估、可扩展性、长上下文评估以及推理优势。
语言建模评估
研究人员训练了一个3B参数的YOCO语言模型,并分别在1T和1.6T训练token下进行评估。在LM Eval Harness的多个下游任务中,YOCO与OpenLLaMA-3B-v2、StableLM-base-alpha-3B-v2、StableLM-3B-4E1T等Transformer模型表现相当,毫不逊色。
可扩展性对比
接下来,研究人员在160M到13B参数规模范围内,分别训练了YOCO(包含门控保留和滑动窗口注意力两个版本)和Transformer语言模型。对比它们在验证集上的语言模型损失,YOCO的表现与Transformer基本持平。
结果证明,YOCO在模型规模扩展方面具有很强的可扩展性。
长上下文评估
将3B的YOCO模型扩展到上下文长度达1M,在“大海捞针”等长序列的needle retrieval任务上,YOCO-3B-1M的准确率接近100%。
在多针检索任务中,YOCO-3B-1M的性能甚至优于部分参数规模超过3B的Transformer模型。
此外,YOCO模型在长序列上的NLL(负对数似然)随着上下文长度的增加而一致下降,表明它能够有效利用长距离依赖信息进行语言建模。
综合来看,YOCO在性能上完全不输Transformer。真正的亮点在于,它在推理效率上取得了质的飞跃。
推理优势
研究人员评估了YOCO在GPU内存占用、预填充延迟、吞吐量以及服务容量等方面的优势,评估的上下文范围从32K到1M。
如下图所示,与Transformer相比,YOCO大幅降低了GPU内存占用,并且其内存消耗随上下文长度增长的幅度极小。例如,在1M长度下,整体推理内存使用量仅为12.4GB,而传统Transformer则占用了高达9.38倍的GPU内存。
下面展示了每个token的KV缓存对GPU内存的占用情况。
YOCO模型只缓存一层全局的键值对,因此与Transformer相比,它所需要的内存大约少了L(指模型层数)倍。
举个例子,YOCO模型仅需1GB的GPU内存就能处理128K token。而采用GQA的Transformer 65B模型,只能支持1.6K token。这意味着,模型规模越大,YOCO的省内存效果越显著。
在预填充阶段,模型并行编码输入token。对于512K和1M长度的输入,Transformer分别需要大约180秒和300秒——这是因为Transformer的计算复杂度为O(N²),处理长上下文需要大量浮点运算。相比之下,YOCO的预填充时间为O(N),随序列长度线性增长。
YOCO将Transformer的512K上下文预填充时间从180秒锐减到不到6秒。
此外,预填充阶段可以在进入交叉解码器之前提前退出。这意味着,即使对于短上下文,预填充延迟的加速效果也至少达到两倍。例如,对于32K长度,YOCO比Transformer快2.87倍。
在吞吐量方面,YOCO在不同上下文长度下均实现了更高的吞吐量。以512K查询为例,Transformer的吞吐量为4.5 token/秒,而YOCO达到了43.1 token/秒,实现了9.6倍的加速。吞吐量提升的原因不难理解:一方面,YOCO减少了预填充所需的时间;另一方面,由于内存消耗大幅降低,推理时可以采用更大的批量大小,从而进一步推高吞吐量。
更多技术细节,建议直接查阅原论文。
论文链接:https://arxiv.org/abs/2405.05254
— 完 —
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:微软新架构突破Decoder-Only,20GB显存运行Llama3 70B要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点可灵AI生成的交通事故模拟还原视频,在法律场景中的定位,更准确地说是作为一份**辅助参考工具**,而非独立的法定证据。它能帮助律师、法官或事故调查人员更直观地理解事发经过,但若直接用于“举证”,仍需满足一系列实务规范与司法审查要求。以下结合当前司法实践,梳理几个关键操作要点。 如果您正在司法实务中考
在 VS Code 中借助 GitHub Copilot 编写代码时,默认的触发方式(或点击小灯泡图标)往往不够顺手。其实,只需自定义一个快捷键,就能让代码提示像老朋友一样随叫随到——完全按照你习惯的按键来操作。 修改 Copilot 默认触发快捷键 进入 VS Code 设置界面,点击右上角的“打
这套方法论的核心思路非常清晰:通过“主张、证据、限定”这三个核心要素,精准地从论文中提炼出最具分量的核心结论。然后,依据你具体的应用场景——无论是课堂展示、社交媒体文章,还是学术文献综述——套用合适的表达框架。最后,强制完成一轮可信度核查,确保每一个陈述都经得起验证。 利用Perplexity这类A
北京市发布推动“人工智能+文化和旅游”发展三年行动计划,聚焦场景应用、数据体系、安全保障、政策支撑四大方向,围绕公共服务、文艺创作、产业升级、全球推广、市场治理五大场景,构建智慧文旅体系,推动AI与文旅深度融合。
- 日榜
- 周榜
- 月榜
热点快看