




昆仑万维开源2000亿稀疏大模型天工MoE 支持4090推理

昆仑万维开源2千亿参数稀疏大模型Skywork-MoE,总参146B、激活22B,基于MoEUpcycling技术,单台8卡4090可推理,性能接近70B稠密模型,推理成本下降约3倍。
2024年6月3日,昆仑万维正式开源了一款名为 Skywork-MoE 的稀疏大模型,参数规模达到2千亿。这不仅是模型体量上的又一次重大突破,更关键的是,它在保持出色性能的同时,大幅降低了推理成本。从技术层面来看,Skywork-MoE 基于昆仑万维此前开源的 Skywork-13B 中间检查点扩展而来,其独特之处在于——这是业界首个完整应用并落地 MoE Upcycling 技术的千亿级开源模型,也是截至目前唯一一个支持在单台 4090 服务器上推理的千亿级开源 MoE 模型。
模型权重与技术报告已全面开放,可免费用于商业用途,无需另行申请。相关资源如下:
模型权重下载地址已提供(Hugging Face),同时包含 FP8 量化版本。
开源仓库与技术报告已在 GitHub 上同步发布,推理代码也已公开,支持在8卡4090服务器上采用8比特量化进行加载推理。
模型架构
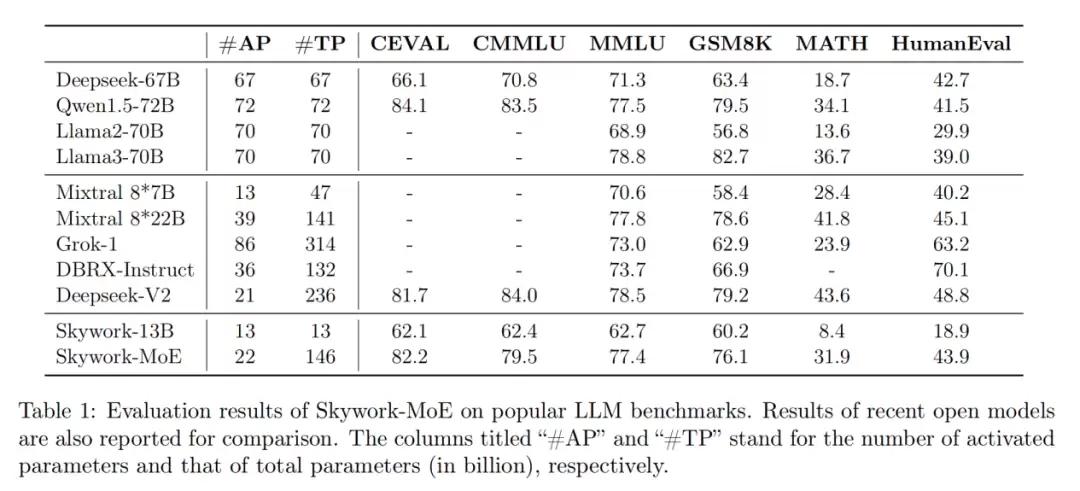
本次开源的 Skywork-MoE 模型,属于天工 3.0 研发系列中的中档规格(Skywork-MoE-Medium)。模型总参数量为 146B,其中激活参数为 22B。整个模型部署了16个专家(Expert),每个专家的大小为 13B,每次推理时仅激活其中 2 个专家。
值得一提的是,天工 3.0 还训练了 75B(Skywork-MoE-Small)和 400B(Skywork-MoE-Large)两个档位的 MoE 模型,但这两个版本并未包含在此次开源范围内。
模型能力
在相同的激活参数 20B(即推理计算量相当)基准下,Skywork-MoE 的表现已处于行业前列,能力接近 70B 的稠密(Dense)模型。这意味着推理成本可降低约3倍。同时,Skywork-MoE 的总参数量比 DeepSeekV2 整整小了三分之一,却以更小的规模实现了接近的性能水平。
技术创新
MoE 模型训练难度大、泛化性能差是业界公认的难题。相较于 Mixtral-MoE,Skywork-MoE 专门设计了两项训练优化算法:
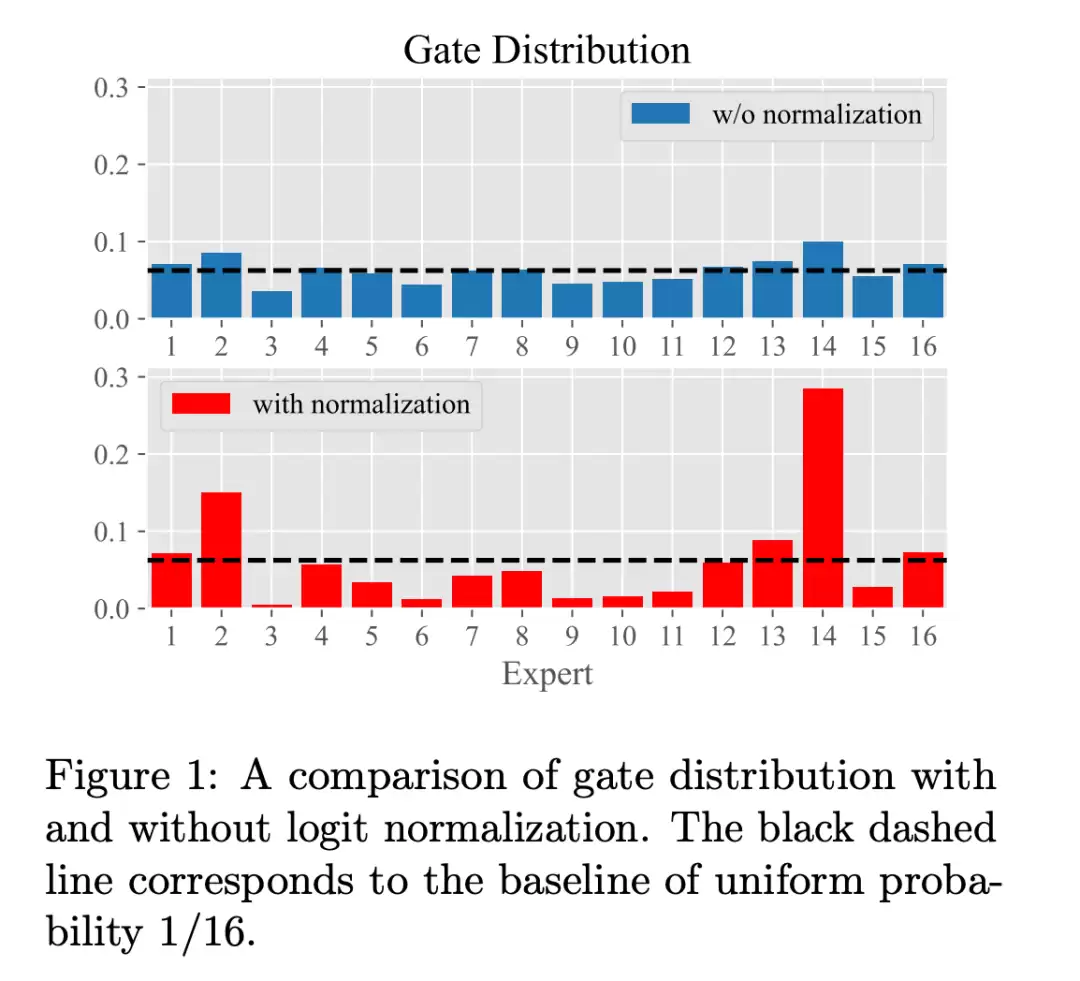
Gating Logits 归一化操作
具体而言,在门控(Gating)层的 token 分发逻辑中,新增了一个归一化(normalization)操作。这一改进的目的是让门控层的参数学习更倾向于被选中的 Top-2 专家,从而提升 MoE 模型对这两个专家的置信度。
自适应的 Aux Loss
传统辅助损失(aux loss)通常采用固定系数。Skywork-MoE 打破了这一惯例,让模型在训练的不同阶段自适应地选择合适的 aux loss 超参系数——核心目标是将“丢失 token 率”(Drop Token Rate)控制在一个合理的区间。这既能保证专家之间的负载相对均衡,又能让不同专家学习到具备差异化的能力,从而全面提升模型的性能和泛化能力。
具体来说,训练前期参数学习不到位,token 分布差异较大,导致 Drop Token Rate 偏高,此时需要较大的 aux loss 来辅助 token 均衡;而到了训练后期,希望专家之间仍保持一定的区分度,避免门控层随机分发 token,因此需要更低的 aux loss 来减少纠偏。
训练 Infra
MoE 模型的高效大规模分布式训练,向来是公认的挑战,社区目前尚无最佳实践。Skywork-MoE 提出了两个关键的并行优化设计,最终在千卡集群上实现了 MFU 38% 的训练吞吐(MFU 按 22B 的激活参数计算理论计算量)。
Expert Data Parallel
与社区常见的 EP(Expert Parallel)和 ETP(Expert Tensor Parallel)设计不同,Skywork-MoE 提出了一种名为 Expert Data Parallel 的并行方案。其最大优势在于:当专家数量较少时,仍能高效地切分模型,并能最大程度优化和掩盖引入的 all2all 通信开销。相比之下,EP 受限于 GPU 数量,ETP 在千卡集群上效率不足,而 EDP 较好地解决了这些痛点,设计简洁、鲁棒且易于扩展,部署和验证都十分迅速。
一个最简单的实例:在两卡情况下,设置 TP=2,EP=2 即可运行,其中 Attention 部分采用 Tensor Parallel,Expert 部分采用 Expert Parallel。
非均匀切分流水并行
传统流水并行若均匀切分各层,由于首阶段(Embedding 计算)和末阶段(Loss 计算)的存在,加上 Pipeline Buffer 的占用,各阶段的计算负载和显存负载会出现明显不均衡。Skywork-MoE 引入了非均匀的流水并行切分,并结合重计算层的分配优化,使得总体计算/显存负载更均衡,端到端训练吞吐提升了约10%。
对比之下,均匀切分与非均匀切分的差异一目了然:对于一个24层的LLM,均匀切分为4个 stage,每阶段层数为 [6,6,6,6];而非均匀优化后切分成5个 stage,层数分配为 [5,5,5,5,4]。在流水线打满的阶段,后者的气泡明显更低。
MoE Know-how
此外,Skywork-MoE 还进行了一系列基于 Scaling Laws 的实验,旨在探究哪些约束会影响 Upcycling 和 From Scratch 训练 MoE 模型的效果。
一个可供参考的经验法则是:如果训练 MoE 模型的总计算量(FLOPs)是训练稠密模型的2倍以上,那么选择 From Scratch 效果更优;反之,选择 Upcycling 可显著降低训练成本。
4090 推理
Skywork-MoE 目前是能在 8×4090 服务器上推理的最大开源 MoE 模型。单台8卡4090服务器总共有 192GB 的 GPU 显存。在 FP8 量化条件下,权重占用约 146GB。配合首创的非均匀 Tensor Parallel 并行推理方式,Skywork-MoE 可在合适的 batch size 内达到约 2200 tokens/s 的吞吐量。
结语
这次开源,不仅仅是把模型发布出来。我们希望 Skywork-MoE 的模型权重、技术报告,以及附带的一系列实验成果,能为社区贡献更多关于 MoE 模型训练的经验与 Know-how——从结构设计、超参选择、训练技巧,到推理加速等方方面面。归根结底,目标始终如一:用更低的训练和推理成本,去训练更大更强的模型,在通往 AGI 的道路上,贡献一份力量。
```你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:昆仑万维开源2000亿稀疏大模型天工MoE 支持4090推理要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点高认知觉醒个体基于理性计算主动选择AI情感陪伴,因其具备去人格化、自主可控、情绪安全、低冲突等优势,有助于降低认知负荷并构建安全心理空间,是情感需求的精准满足而非替代。
```html 解锁AI对话四象限模型,提问效率提升90%!告别模糊指令,释放AI真实能力。 核心要点: 深度拆解AI对话四象限模型及其心理学理论根基 掌握“我会AI也会”象限的高效协作实操技巧 攻克“我不会AI会”象限的分层提问核心方法 绝大多数人根本不会跟AI有效沟通! 三年前刚接触AI时,我一
资料越来越多,找东西却越来越难。笔记、网盘、文件夹分类再细,到用的时候还是一团乱麻。AI知识库不是多一个工具,而是换一种方式——把资料交给AI处理,提问就能获取答案。 这个系列文章里,我们将一步步探讨如何搭建一个能“理解”和“回答”的知识系统,让知识真正为你所用,不再只是堆在角落。 01 什么是AI
企业AI智能体如何真正落地?8个实战案例告诉你从 "写标书 "到 "查回款 ",AI正在成为企业的 "数字员工 "。 核心内容: 1 8个企业AI智能体落地实战案例解析 2 AI智能体落地的关键原则:场景驱动、小步快跑 3 企业应用AI智能体的5条实用建议 这半年,AI智能体确实火得不行,也是企业级应用的
- 日榜
- 周榜
- 月榜
热点快看