




Agent Harness最全综述:一文掌握核心要点

近期,一篇由卡内基梅隆大学(CMU)、耶鲁大学(Yale)、约翰霍普金斯大学(JHU)、弗吉尼亚理工大学(Virginia Tech)及亚马逊(Amazon)等机构联合发表的系统综述《Agent Harness Engineering: A Survey》,深入剖析了Agent在真实运行环境中,包裹
近期,一篇由卡内基梅隆大学(CMU)、耶鲁大学(Yale)、约翰霍普金斯大学(JHU)、弗吉尼亚理工大学(Virginia Tech)及亚马逊(Amazon)等机构联合发表的系统综述《Agent Harness Engineering: A Survey》,深入剖析了Agent在真实运行环境中,包裹在模型外部的整套工程系统层。

论文主页地址:https://picrew.github.io/LLM-Harness/
该综述采用ETCLOVG七层框架对Agent Harness进行解构,涵盖执行环境(Execution)、工具接口(Tooling)、上下文管理(Context)、生命周期编排(Lifecycle)、可观测性(Observability)、验证评估(Verification)以及安全治理(Governance)。此外,还系统梳理了170余个开源Agent Harness项目,完整勾勒出从提示工程(Prompt Engineering)、上下文工程(Context Engineering)到Harness工程(Harness Engineering)的技术演进路径。
以下我们在忠实原意的基础上,进行了核心观点整理与提炼。
仅更换模型,未必是Agent性能提升的最佳路径
论文开篇便明确指出一个长期存在的偏向:学术界一直将Agent的研究重心集中在模型本身。
模型是否具备规划能力?能否调用外部工具?能否有效记忆上下文?能否与其他Agent协作?这些固然关键。
但问题在于,当Agent开始面对长周期任务、真实工具链和复杂现实环境后,失败的根源往往并非模型“不够聪明”,而是系统层没有做好管控与支撑。
论文列举了多组实验数据:有研究仅调整了编辑工具的格式和周边Harness组件,在未改动模型的情况下,编码基准(benchmark)性能最高提升了10倍。另一个使用固定GPT-5.2-Codex Agent的实验中,通过重构系统提示词、加入中间件上下文注入、自验证挂钩(hooks),在Terminal-Bench 2.0上的得分从52.8%提升至66.5%。Meta-Harness则通过自动化优化Harness,在Terminal-Bench-2上达到了76.4%,超越了人工设计方案。
这些数字的具体实验条件值得深入推敲,但共同指向一个核心现象:
同一个模型,换一套执行外壳,表现可以完全不一样。许多团队仍习惯将问题归因于“模型能力不足”。而真实情况很可能是:模型已经足够强大,薄弱环节是你的工具接口、上下文管理、沙箱环境、验证逻辑以及权限系统。
Agent工程经历了三次关键迁移
这篇综述提供了一个尤其适合中文读者理解的分析框架:Agent工程从2022年至2026年大致经历了三个阶段。
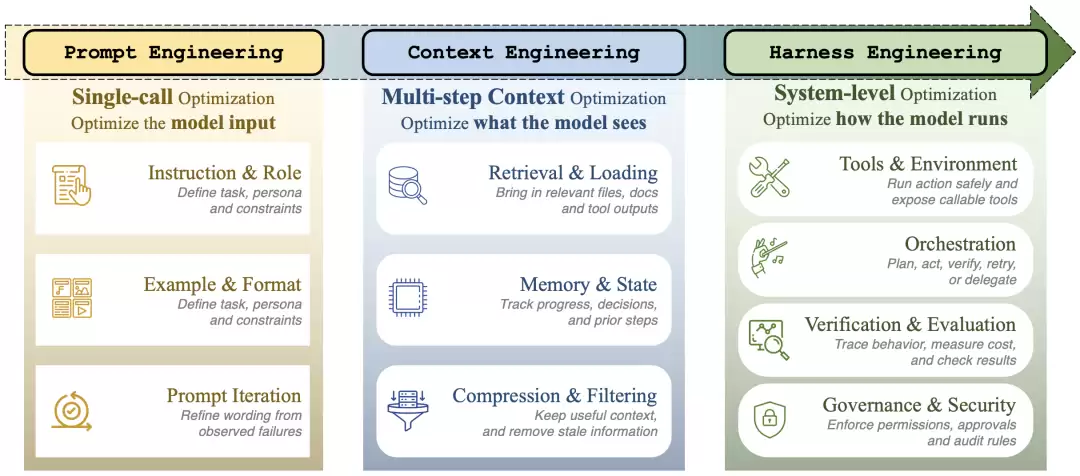
第一阶段是Prompt Engineering。当时的核心竞争集中在提示词设计:如何编写系统提示(system prompt),如何安排少量示例(few-shot),如何引导模型按步骤推理。工程对象非常狭窄,本质上是优化一段输入文本。
第二阶段是Context Engineering。随着Agent开始处理更长任务,关键问题转变为:模型在每一步中到底应该看到什么?并非所有信息都适合塞入上下文,必须决策哪些信息进入窗口,哪些记忆需要检索,哪些工具返回结果需要压缩,窗口满载后如何处理,长期任务中哪些状态需要持续保留。
第三阶段,即Harness Engineering。当模型已经具备处理复杂任务的能力时,瓶颈迁移到模型外部:谁来维护状态?谁来调度工具?谁来控制权限?谁来注入反馈?谁来验证进度?谁来记录执行轨迹?谁来负责失败后的恢复机制?
简单归纳:Prompt Engineering解决“如何与模型沟通”,Context Engineering解决“模型应该看到什么”,而Harness Engineering解决“如何让模型在真实世界中可靠地完成工作”。
一个完整的Harness究竟包含哪些组件?
论文提出了一个名为ETCLOVG的七层分类法。名称虽略显拗口,但逐层拆解后十分实用。
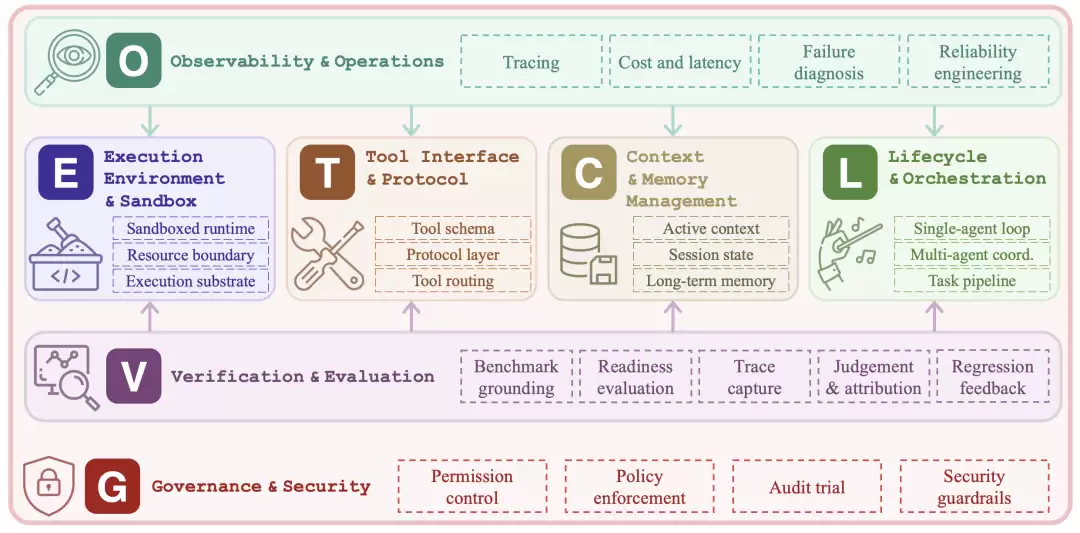
- Execution:执行环境。Agent在哪里运行?本地、容器、浏览器、桌面还是远程沙箱?边界和约束是什么?
- Tooling:工具接口。工具如何描述、如何被发现、如何被调用?怎样防止模型误选或滥用工具?
- Context:上下文和记忆。短期上下文、会话状态、长期记忆分别如何管理?
- Lifecycle:生命周期和编排。Agent是单轮执行还是多轮循环?是单一Agent独立完成,还是由规划器(planner)、执行器(executor)、审查器(reviewer)分工协作?
- Observability:可观测性。每一次模型调用、工具调用、信息检索、报错、重试、token消耗、响应延迟,都必须能被追踪和记录。
- Verification:验证和评估。结果是否正确?失败原因究竟是模型错误、工具错误、上下文错误,还是测试环境本身的问题?
- Governance:治理和安全。Agent拥有哪些权限?能否发送邮件、修改代码、调用API、读取私有数据?哪些操作需要审批?谁来审计?
这七层组合在一起,才构成了一个能够稳定执行长任务的生产级Agent系统。
许多人对于Agent的理解仍停留在“模型 + 工具调用”的层面。但论文明确传达:工具调用仅仅是其中一层。真正的Agent产品,必须拥有完备的执行环境、上下文管理、生命周期编排、监控体系、验证机制以及安全治理。
否则,它很容易沦为一个“会动的演示”——能演示,并不等于能上线部署;能成功运行一次,并不等于能长期稳定运行。
可观测性与安全治理为何需独立成层?
这篇综述的一项关键贡献,在于将Observability(可观测性)和Governance(治理)从“附属功能”中独立出来,作为专门的工程层对待。
过去许多Agent框架习惯将日志、监控、权限、审计视为周边功能,优先保证Agent能跑起来,之后再补充日志记录和审批控制。
但在真实生产环境中,这两个环节绝非可有可无的装饰。
Agent会调用工具、执行Shell命令、修改代码、读写数据库、发送邮件、访问第三方API。它不再是普通的聊天机器人——它在真实世界中行动。
一旦Agent开始行动,你必须明确两件事:第一,它究竟做了什么;第二,它被允许做什么。前者是可观测性,后者是治理。
缺乏可观测性,Agent失败时你无法定位原因;缺乏治理,即使Agent成功完成操作,你也未必敢放心使用。
有了Harness,Agent的评估方式也必须变革
论文还有一个值得深入探讨的判断:Agent的评估不应只关注最终成功率。
过去我们习惯于观察基准测试结果:某个模型的通过率(pass rate)是多少?某个Agent在榜单上排名第几?SWE-bench分数上涨了几个百分点?但对于执行长任务的Agent来说,这些信息远远不够。
因为Agent的最终输出结果,背后混合了大量变量:模型、提示词、工具、上下文、沙箱环境、测试策略、重试机制、权限配置、评估器本身。
两个Agent如果拥有相同的成功率,可能代表完全不同的系统质量。一个Agent可能依赖大量重试才刷过任务,成本极高;另一个Agent可能走了危险路径,虽然结果正确但过程不合规;还有一个Agent可能靠利用测试漏洞获得高分;而失败的Agent未必是模型不会做,也许仅仅是测试环境缺少某个依赖包。
因此,论文主张评估应当以轨迹(trace)为核心——也就是把完整的执行轨迹作为评估对象。
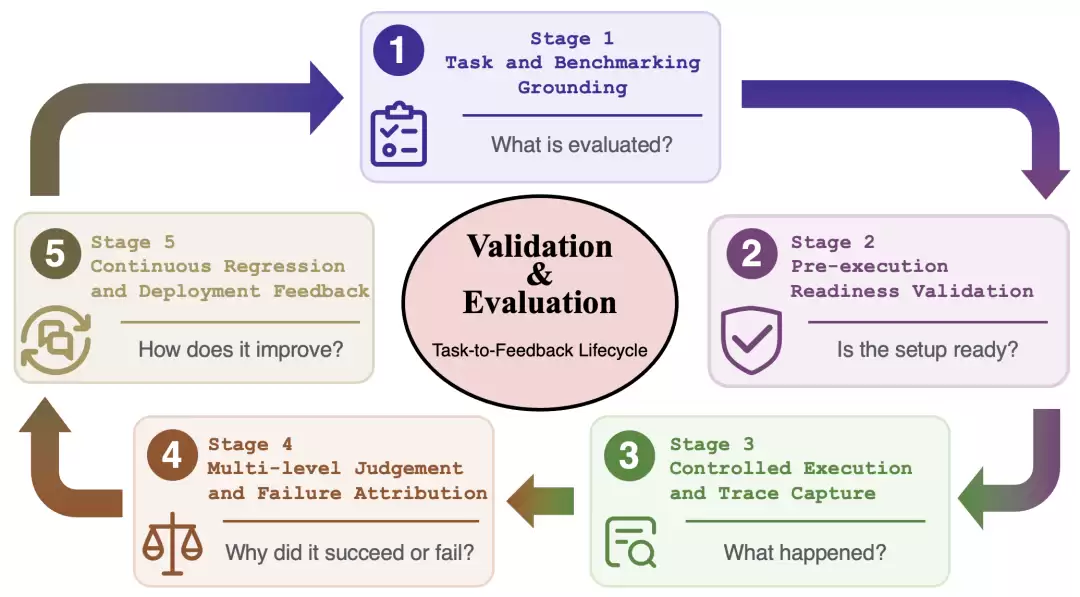
需要记录的信息包括:模型输出内容、工具调用情况、工具返回结果、环境状态变化、上下文快照、错误信息、重试过程、恢复动作、token消耗量、响应延迟以及总成本。然后从三个维度进行判断:结果是否正确?路径是否合理?评估器本身是否可信?
这种模式将Agent评估从“排行榜机制”拉回到“质量控制机制”。排行榜回答的是“谁得分更高”,质量控制回答的是“为什么失败?应该改进哪一层?”
生产环境中Agent面临的最大矛盾:能力越强,控制越难
这篇综述还清晰点出了几个跨层矛盾。
第一个是成本、质量与速度的三角矛盾。为了让Agent更安全,你需要更强的沙箱、更细粒度的权限、更完整的执行轨迹;为了让Agent更可靠,你需要更多的验证、更复杂的回归测试、更长的上下文窗口。但这些都会显著增加成本和延迟。
第二个是能力与控制的矛盾。赋予Agent更多工具,它能够完成更多任务,但也更容易选错工具,且面临更大的提示注入(prompt injection)风险。赋予Agent长期记忆,它能够持续工作,但会带来隐私泄露、过期信息、来源不可靠等问题。提供更开放的执行环境,Agent更加有用,但失控的半径也随之增大。
第三个是Harness耦合(harness coupling)问题。Harness的各层并非独立运作。工具描述会占用上下文窗口,从而影响模型行为;执行环境的差异(如包版本、重置机制、延迟等)会直接影响评估结果;可观测性轨迹如果未记录身份和权限状态,就无法作为治理证据使用。
因此,修改提示词、调整工具、优化记忆、更换沙箱、改进验证器,这些都不是局部优化——它们可能改变整个系统的行为特征。
从Agent Framework到Agent Platform的演进
从工具生态的角度看,这篇论文还揭示了明确的趋势:Agent正从Framework(框架)走向Platform(平台)。
Framework解决的是局部抽象问题:agent、tool、memory、loop等基础组件。而Platform需要解决的是完整生产系统:持久化工作空间(durable workspace)、托管沙箱(managed sandbox)、身份认证、计费系统、可观测性、评估体系、治理机制以及人工交接(human handoff)。
早期竞争的核心是:谁能最快搭建一个Agent循环(loop)。现在竞争的核心变成:谁能让这个循环长期可靠地运行。
所以,Agent平台的竞争可能不会仅仅停留在模型层或开发框架层,而会全面聚焦于整套Harness能力。
谁的执行环境更稳定,谁的工具协议更清晰,谁的上下文更容易避免漂移,谁的轨迹追踪更好用,谁的验证更贴近真实任务,谁的权限和审计更可控——谁就更有可能将Agent真正送进生产流程。
下一阶段,Agent需要学会“减少脚手架”
不过,这篇论文并不是简单地鼓励给Agent套上越来越多的控制层。
随着模型能力的增强,Harness也需要被重新审视。每一个包装器(wrapper)、重置机制(reset)、验证器(verifier)、规划器(planner)、记忆规则(memory rule)、权限门(permission gate),本质上都代表一个假设:模型自己做得不够好,所以需要在外部加一层控制。
但如果模型能力已经发生质的飞跃,这些控制可能就不再必要,甚至会拖累性能。论文引用了Anthropic的一个案例:在长时间的应用开发任务中,某些上下文重置(context reset)策略对旧模型有效,但对更强的模型已可移除,移除后成本显著降低,而质量并未下降。
这恰恰说明,Agent工程并非越复杂越好。优秀的Harness不仅要懂得如何添加控制,更要懂得何时移除控制。
结语:Agent的下一场竞争,是模型外部的工程外壳
如果用一句话总结这篇长达71页的综述,那就是:
Agent的下一场竞争,不只是模型能力,而是模型外面的工程外壳。过去几年,我们首先学会了编写Prompt。随后开始学习管理Context。如今,真正的短板在于构建完善的Harness。
因为Agent一旦从聊天界面走向真实任务,它就不再是一个“会回答问题的模型”。它变成了一个能读取上下文、调用工具、修改环境、执行操作、留下痕迹、接受验收的系统。
系统就需要系统工程。
对于开发者而言,别再只追问“哪个模型更强大”。你还需要思考:它运行在什么环境中?工具接口是否为Agent专门设计?上下文会不会发生漂移?状态能否跨轮次恢复?失败能否从轨迹中定位?结果是否有验证器把关?权限、身份、审计是否形成闭环?
Prompt Engineering是把模型唤醒。Context Engineering是让模型看到正确的信息。Harness Engineering是让模型在真实世界中可靠地行动。
Agent要从玩具变成基础设施,欠缺的正是这层外壳。

你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Agent Harness最全综述:一文掌握核心要点要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点描述-执行差距”可判断工作被AI取代的可能性:描述简单、执行复杂的任务易被自动化,如修改语法、提交报销;描述复杂、执行也复杂的任务难以替代,如规划个性化旅行或购买特定食材。人类应聚焦于需要深度上下文和主观判断的工作。
MiniMaxAgent作为一款“最强数字员工”,整合编程、视频生成与多模态能力,支持长程复杂任务规划,具备记忆与反思机制。可将企业官网开发从3天缩短至18分钟,市场分析报告从8小时压缩至6分钟,并以低成本生成电影级宣传片,显著提升生产力。
针对实干者工作价值被低估的问题,提出将“工作事实”转化为“价值叙事”的方法,通过量化成果、关联业务目标、突出个人贡献等技巧,借助大模型提示词工具辅助提炼,实现从“做了十分”到“讲出十分”的表达升级。
利用AI模拟苏格拉底式提问,通过分层追问剖析观点盲区,直达思维底层逻辑。借助DeepSeek工具实现单句交互,结合澄清、质疑、索证、转换视角等提问类型,并设置复盘环节,以认知里程碑判断对话终结,实现深度思考与认知升级。
- 日榜
- 周榜
- 月榜
热点快看