




PyTorch深度学习实战 多头注意力机制详解与代码实现

多头自注意力机制通过多个线性层将输入投影到不同特征空间,并行计算缩放点积注意力捕捉全局关联,再拼接多头输出并加入残差连接和层归一化,最终输出与输入尺寸相同的特征张量。
Transformer里的多头自注意力机制,说穿了其实不复杂。它本质上就是一组线性层和注意力计算的有趣组合:输入先经过多个线性层投影成不同的特征空间,然后利用注意力机制去捕捉序列内部元素之间那些隐蔽的关联信息,最后输出和输入尺寸完全一样的特征张量。整个过程就好像给原始向量做了一次“全局上下文感知”的重新编码。
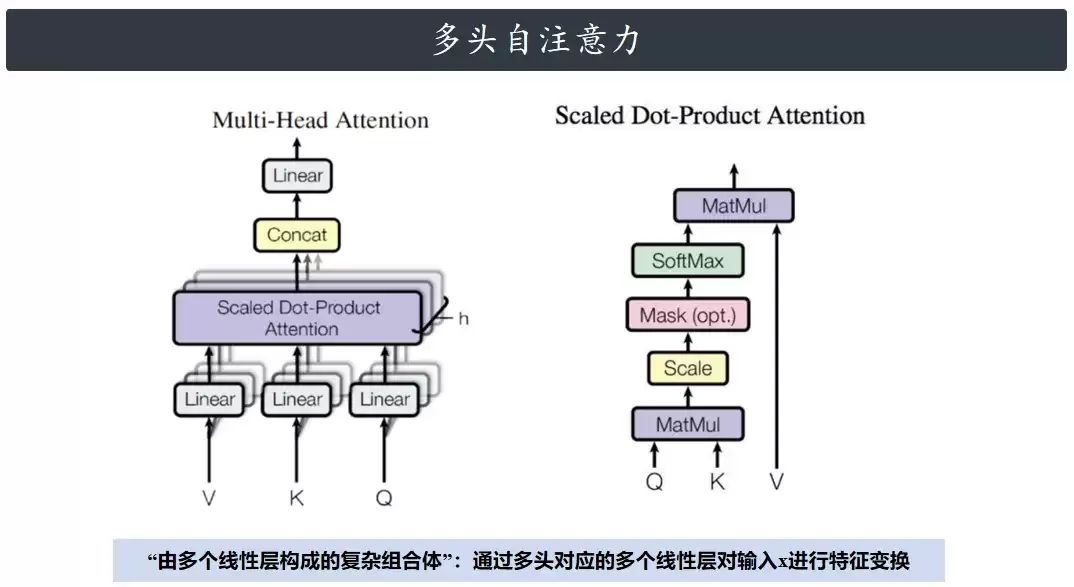
接下来,从四个维度把它彻底拆透:整体结构、内部细节、Attention公式的来龙去脉,以及代码实现。
多头自注意力的整体结构
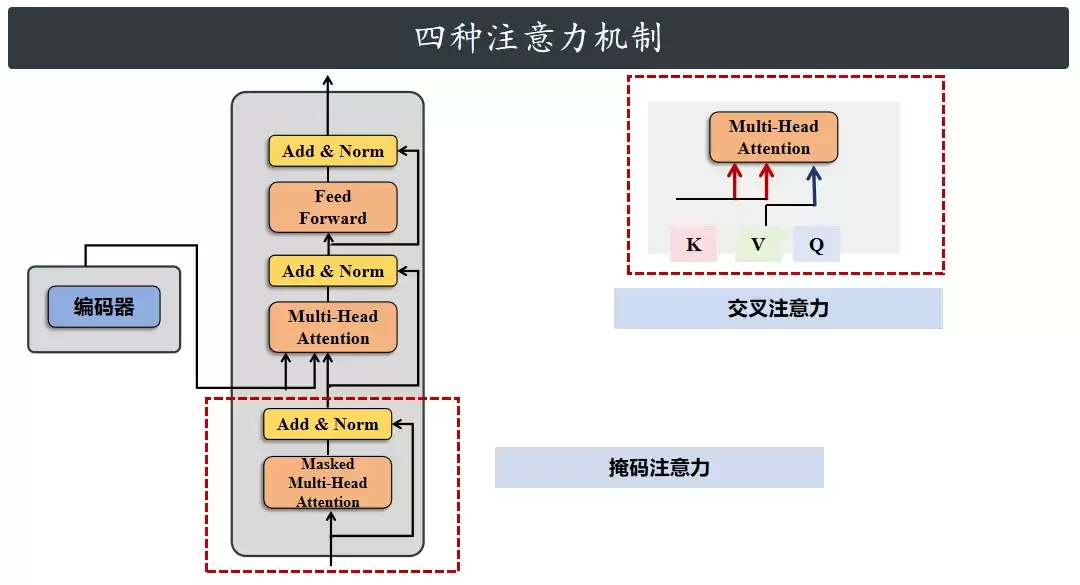
扫一眼Transformer的整体架构图,会发现里面藏着3个橙色的多头注意力模块:编码器里放了1个,解码器里放了2个。从核心的计算逻辑看,这三个模块底层完全一致,差别主要在数据源和掩码(Mask)的应用上。为了讲清楚,这里拿解码器里的多头注意力模块当作主角。
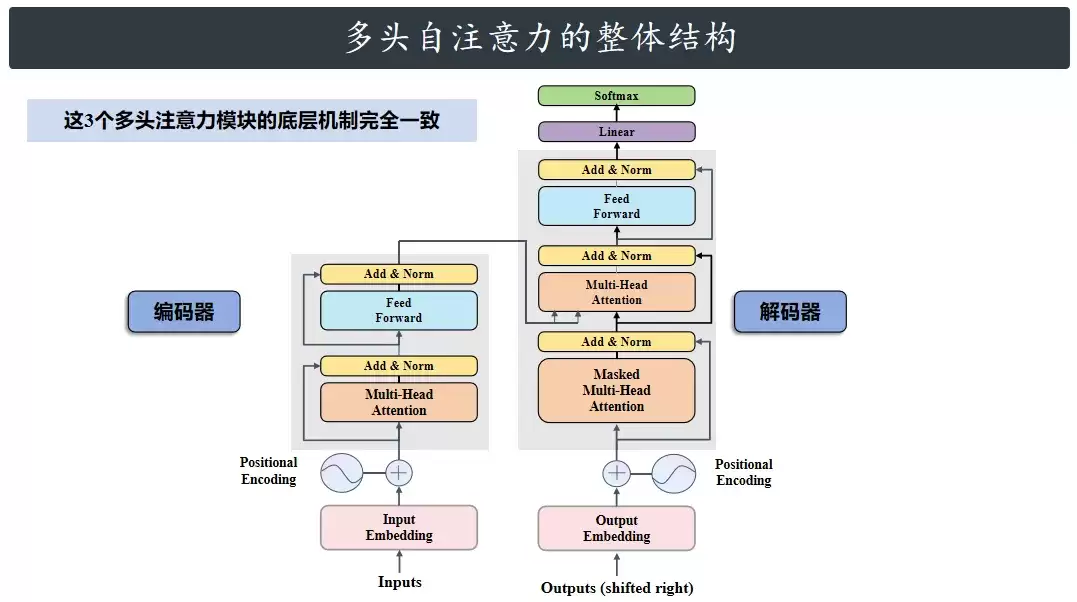
多头注意力模块有3个输入和1个输出。这三个输入分别叫查询(Q)、键(K)、值(V),其实你不需要被名字吓到,就当成三组数据(张量)就行。它们可以一模一样,也可以不一样。再说说编码器里的情况:Q、K、V都来自同一个输入——输入经过词嵌入和位置编码后得到特征,然后分成三路,分别作为Q、K、V喂给多头注意力。
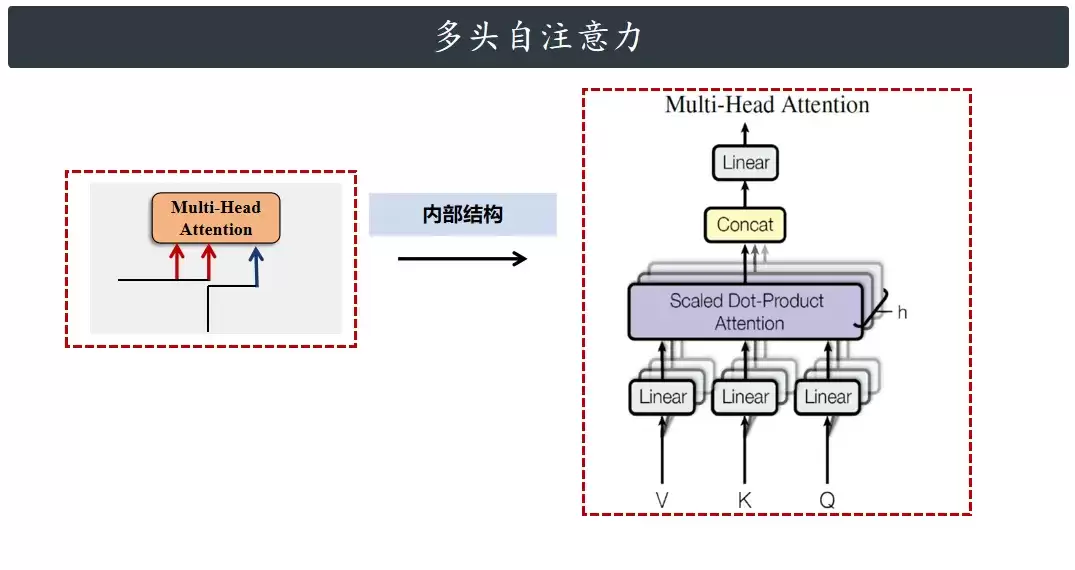
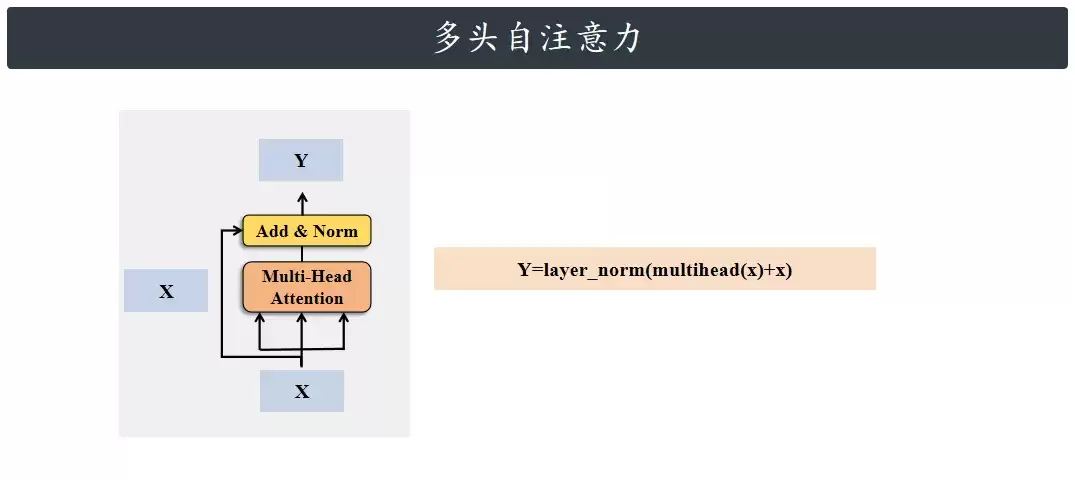
在编码器里,Q、K、V实际上指的是同一个张量,就叫它x吧。把x放进多头注意力,算出一个结果,称为multihead(x)。与此同时,x还会从左边直接送到Add&Norm那里。Add就是残差连接,说白了就是x和multihead(x)加起来;Norm是层归一化,把加完的结果处理一下,让数值稳定。所以最后从Add&Norm出来的,就是“x加上multihead(x)之后,再经过层归一化的结果”。
多头自注意力的内部细节
“多头”是什么意思?就是同时使用多个自注意力机制来提取特征。拿个例子说清楚吧。
假设输入是加了位置编码的句子“Are you OK?”,叫它x。x会分别经过3个线性层(简单说就是做些数学变换),得到三组结果:qx、kx、vx(也就是Q、K、V)。接着把这仨放进注意力的计算公式里一算,输出叫做y,这个y就把句子中各个词之间的全局关系(比如谁和谁关联紧密)全都融合进去了。
Attention 计算公式的深入理解

 编辑
编辑
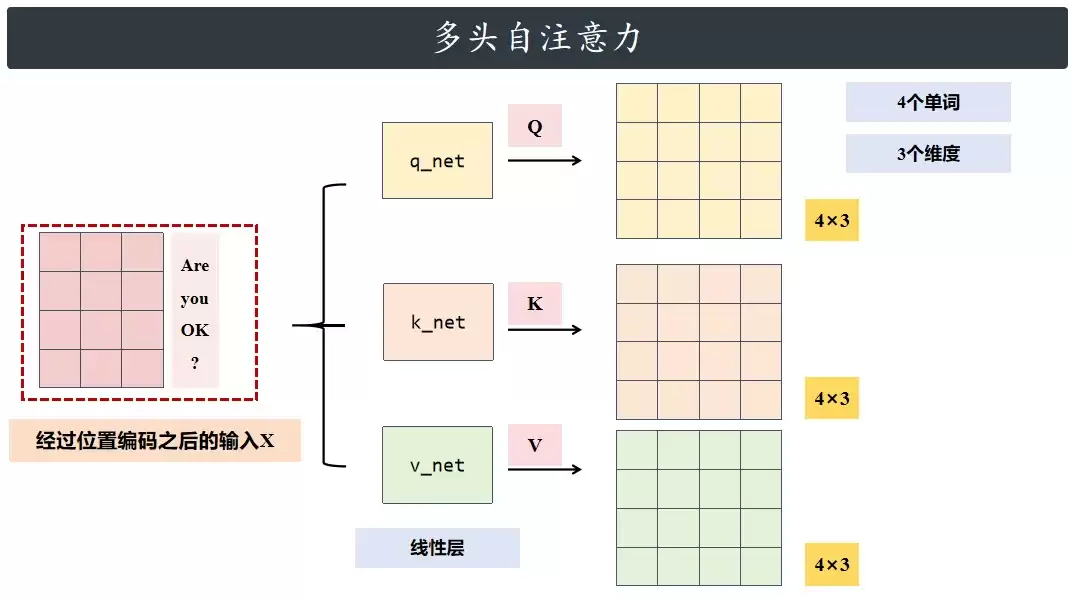
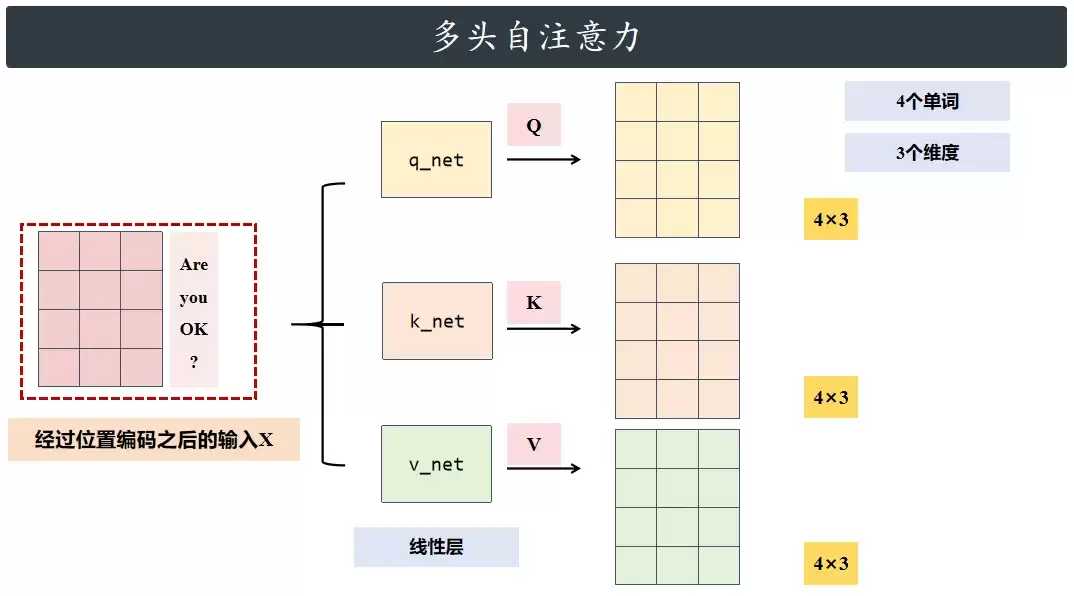
假设输入句子是“Are you OK?”,对应的序列叫X。把X分别送进qnet、knet、vnet三层结构计算,最终得到Q、K、V三组数据(张量)。每组数据的尺寸都是4×3:4代表句子里的4个单词,3代表每个单词用3个维度表示。

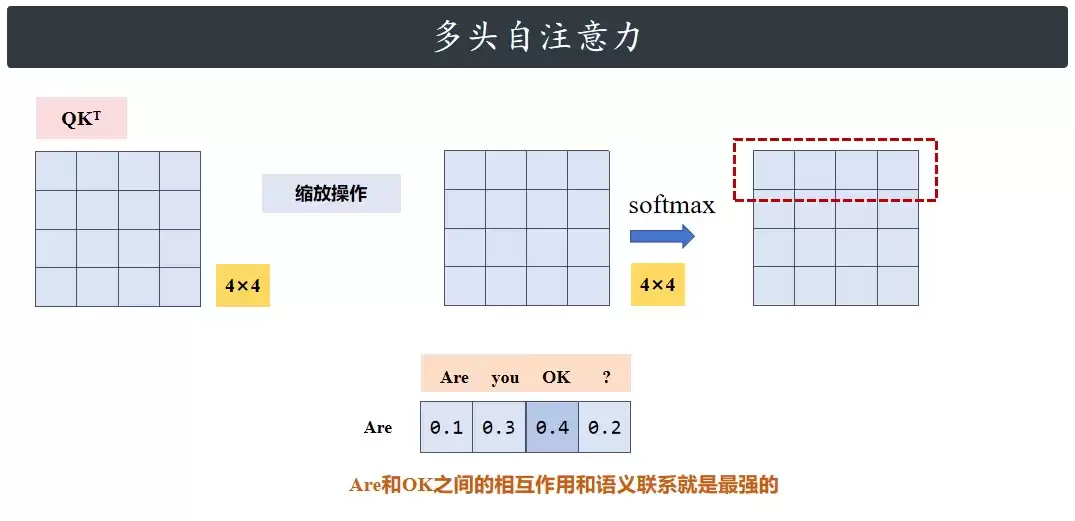
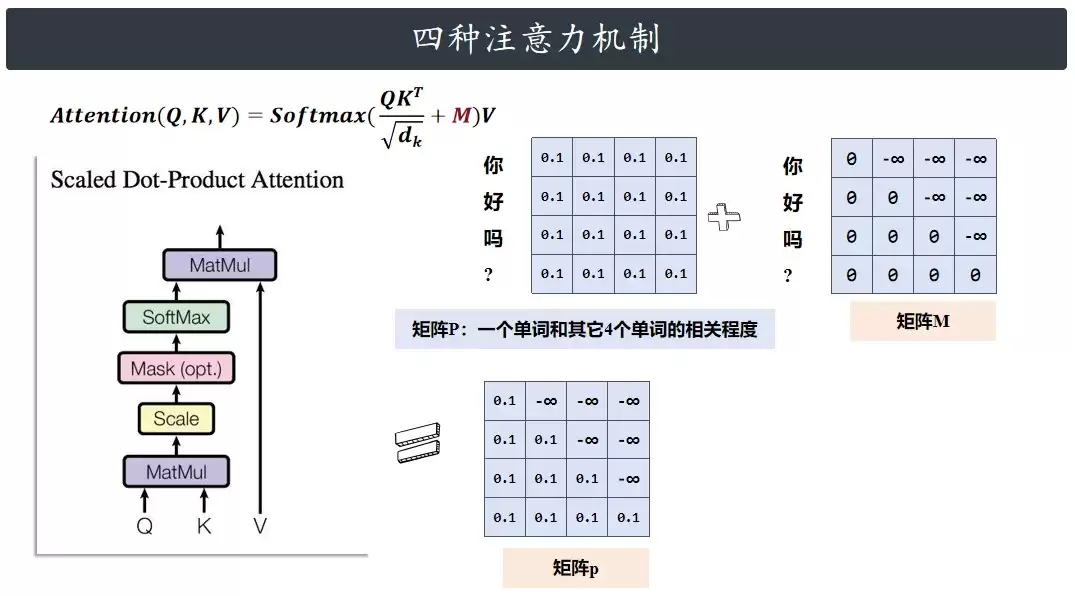
第一步,把Q和K的转置乘起来。Q是4×3的矩阵,K转置后是3×4,乘完得到4×4的矩阵。这个4×4矩阵代表了输入句子里所有单词之间的关系——矩阵里每一行对应一个单词,每一列也对应一个单词,行和列交叉的那个数值,就是这两个单词之间的关联程度。


然后对计算结果进行缩放——缩放操作可以调节点积计算的尺度。缩放后的结果再通过softmax函数转换成概率分布,假设这个矩阵叫P,每一行代表该单词跟其他单词的关系,且是一个概率分布。如果矩阵的第一行像下图那样,就说明are和ok之间的相互作用和语义联系最强。

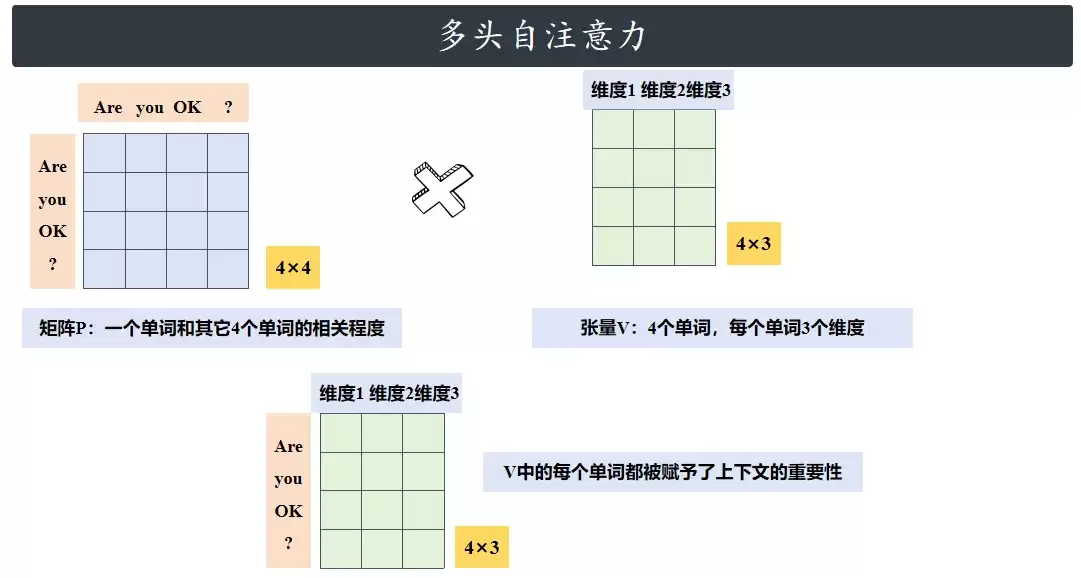
最后一步,把矩阵P和矩阵V相乘,相当于给V里的每个单词“加上上下文的重要性”。概率矩阵P是4×4,每一行对应一个单词,行里每个数代表该单词跟其他单词的相关程度;矩阵V是4×3,对应4个单词每个单词3个维度。相乘之后的结果还是4×3,但这时候,V里的每个单词已经把上下文的重要性融合进去了。

多头注意力的整体内容
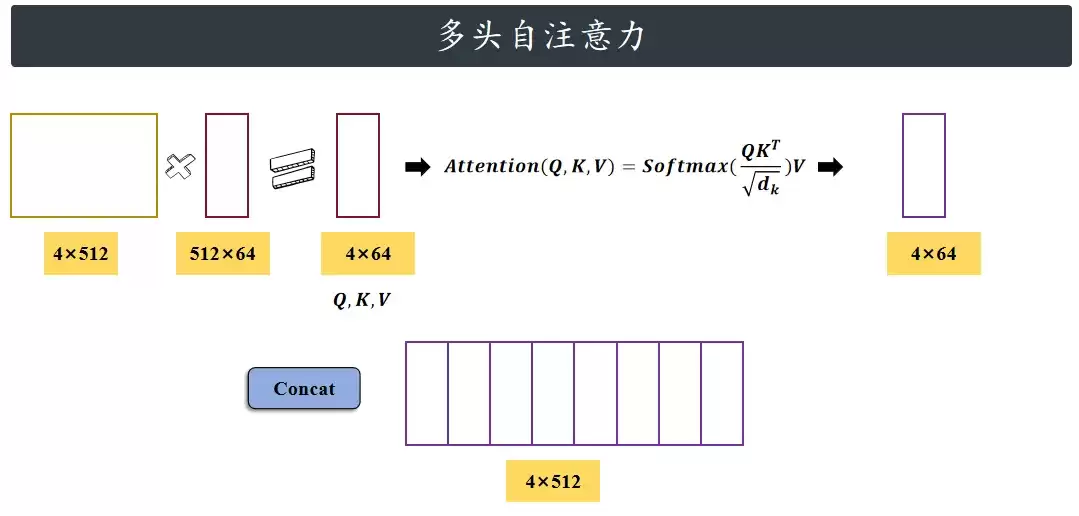
假设输入还是“Are you OK?”,每个单词用512维向量表示,那么输入X就是一个4×512的张量。原始论文设定8个注意力头,所以单个注意力头的输出维度就是512/8 = 64维。于是单个头的输出就是4×64的张量。最后把这8个4×64的张量按照列拼接,得到4×512的输出张量。

四种注意力机制
再看右边的解码器,里面有个多头注意力跟别的不一样——它多了个“Mask”(掩码),这就是掩码注意力。还有一个特殊情况:在编码器和解码器连接的地方,K矩阵和V矩阵都来自编码器,只有Q矩阵是解码器自己的,这就是交叉注意力。

掩码注意力怎么算的?其实就在原来基础上多了一步“加矩阵”——加的矩阵叫M(掩码矩阵)。它的样子很特别:主对角线下面的元素全是0,主对角线上面的全是负无穷大。具体做法是,把这个带负无穷大的掩码矩阵,和之前算出来的相似度矩阵对应位置相加。效果很直接:如果掩码矩阵里某个位置是负无穷大,相似度矩阵对应位置的数值就被改成负无穷;如果是0,原来数值保持不变。

代码实现
import torch import torch.nn as nn import torch.nn.functional as F class MultiHeadSelfAttention(nn.Module): def __init__(self, d_model=64, num_heads=8): """ 初始化多头自注意力 :param d_model: 输入/输出的特征维度(必须能被 num_heads 整除) :param num_heads: 头的数量 """ super().__init__() assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除" self.d_model = d_model # 整体特征维度 self.num_heads = num_heads # 头数 self.d_k = d_model // num_heads # 每个头的特征维度(d_model / num_heads) # 1. 定义3个线性层,分别生成 Q、K、V(输入输出维度都是 d_model) self.w_q = nn.Linear(d_model, d_model) # Q的线性变换 self.w_k = nn.Linear(d_model, d_model) # K的线性变换 self.w_v = nn.Linear(d_model, d_model) # V的线性变换 # 2. 定义输出的线性层(拼接多头后做最终变换) self.w_o = nn.Linear(d_model, d_model) # 层归一化(用于残差连接后) self.layer_norm = nn.LayerNorm(d_model) def scaled_dot_product_attention(self, q, k, v, mask=None): """ 缩放点积注意力(单个头的注意力计算) :param q: 单个头的Q (batch_size × seq_len × d_k) :param k: 单个头的K (batch_size × seq_len × d_k) :param v: 单个头的V (batch_size × seq_len × d_k) :param mask: 掩码(可选,batch_size × seq_len × seq_len),0/False 表示遮挡 :return: 注意力输出 + 注意力权重 """ # 第一步:Q·K^T,计算相似度(batch_size × seq_len × seq_len) scores = torch.matmul(q, k.transpose(-2, -1)) # k.transpose(-2,-1) 交换最后两个维度(seq_len 和 d_k) # 第二步:缩放(除以 sqrt(d_k),避免数值过大) scores = scores / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32)) # 第三步:应用掩码(如果有)—— 遮挡位置设为负无穷,softmax后为0 if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) # mask==0 的位置填 -1e9 # 第四步:softmax 归一化,得到注意力权重(batch_size × seq_len × seq_len) attn_weights = F.softmax(scores, dim=-1) # 第五步:权重 × V,得到注意力输出(batch_size × seq_len × d_k) output = torch.matmul(attn_weights, v) return output, attn_weights def split_heads(self, x): """ 将 Q/K/V 拆分成多个头(batch_size × seq_len × d_model)→(batch_size × num_heads × seq_len × d_k) """ batch_size = x.size(0) # 先拆分最后一维:d_model → num_heads × d_k x = x.view(batch_size, -1, self.num_heads, self.d_k) # 交换维度:把 num_heads 提到 seq_len 前面(方便后续并行计算) return x.transpose(1, 2) # 输出:batch_size × num_heads × seq_len × d_k def combine_heads(self, x): """ 拼接多个头的输出(batch_size × num_heads × seq_len × d_k)→(batch_size × seq_len × d_model) """ batch_size = x.size(0) # 先交换维度:num_heads 放回最后一维前面 x = x.transpose(1, 2) # 输出:batch_size × seq_len × num_heads × d_k # 拼接最后两维:num_heads × d_k → d_model x = x.contiguous().view(batch_size, -1, self.d_model) # contiguous() 确保内存连续 return x def forward(self, x, mask=None): """ 前向传播(核心流程) :param x: 输入(batch_size × seq_len × d_model) :param mask: 掩码(可选,batch_size × seq_len × seq_len) :return: 多头自注意力输出(batch_size × seq_len × d_model)、注意力权重 """ batch_size = x.size(0) # 1. 生成 Q、K、V(线性变换) q = self.w_q(x) # batch_size × seq_len × d_model k = self.w_k(x) v = self.w_v(x) # 2. 拆分多头(并行计算每个头的注意力) q = self.split_heads(q) # batch_size × num_heads × seq_len × d_k k = self.split_heads(k) v = self.split_heads(v) # 3. 计算缩放点积注意力(每个头独立计算) attn_output, attn_weights = self.scaled_dot_product_attention(q, k, v, mask) # 4. 拼接所有头的输出 attn_output = self.combine_heads(attn_output) # batch_size × seq_len × d_model # 5. 最终线性变换 output = self.w_o(attn_output) # batch_size × seq_len × d_model # 6. 残差连接 + 层归一化(Transformer 标准操作,稳定训练) output = self.layer_norm(x + output) # x 是原始输入(残差),加完后归一化 return output, attn_weights # -------------------------- 测试代码(运行看效果)-------------------------- if __name__ == "__main__": # 1. 设置超参数 batch_size = 2 # 2个样本 seq_len = 4 # 每个样本4个词(比如 "Are you OK ?") d_model = 64 # 每个词的特征维度 num_heads = 8 # 8个多头(64 / 8 = 8,每个头维度是8) # 2. 生成随机输入(模拟经过词嵌入+位置编码后的特征) x = torch.randn(batch_size, seq_len, d_model) # 形状:(2, 4, 64) print("输入形状:", x.shape) # 输出:torch.Size([2, 4, 64]) # 3. 初始化多头自注意力 multi_head_attn = MultiHeadSelfAttention(d_model=d_model, num_heads=num_heads) # 4. 前向传播(无掩码,默认计算所有词的关联) output, attn_weights = multi_head_attn(x) # 5. 输出结果查看 print("输出形状:", output.shape) # 输出:torch.Size([2, 4, 64])(和输入形状一致) print("注意力权重形状:", attn_weights.shape) # 输出:torch.Size([2, 8, 4, 4]) # 注意力权重解释:(batch_size, num_heads, seq_len, seq_len) → 每个头对每个词的关联权重

输入形状: torch.Size([2, 4, 64])
输出形状: torch.Size([2, 4, 64])
注意力权重形状: torch.Size([2, 8, 4, 4])
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:PyTorch深度学习实战 多头注意力机制详解与代码实现要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点AI生成甘特图时间线混乱源于提示词缺乏结构化约束。解决方法:强制指定起止日作为时序锚点;用箭头或括号显式声明任务依赖;以自然周为单位,禁用相对时间表述,仅使用绝对日期格式。
在Windows或macOS本地运行Sunov4需自行搭建环境。Windows必须使用WSL2子系统,macOS需启用Metal后端。关键步骤包括安装Python3 11+、正确配置CUDA驱动(≥536 67)及建立符号链接,否则无法调用v4模型。首次运行会自动下载约4 2GB权重文件,建议磁盘空间超10GB。
Manusv1 8在Mac上因沙盒机制无法同步iCloud。需授予完全磁盘访问权限,将项目路径设为~ Library MobileDocuments com~apple~CloudDocs ,并删除cloud_state json文件重置状态。前提:已登录iCloud并开启云盘。
用AI工具撰写季度目标拆解表时,许多初次使用者常在提示词环节出错。尝试几次便会发现:要么AI输出的内容缺少责任人和时间节点,要么直接生成一段密密麻麻的长篇大论。问题究竟出在哪里?核心在于提示词未能匹配妙鸭文档AI的解析逻辑,也没有兼顾实际使用中的理解盲区。 先明确一个关键判断:妙鸭文档AI无法识别诸
- 日榜
- 周榜
- 月榜
热点快看