




PyTorch深度学习实战 手算FCN全卷积神经网络

FCN全卷积网络通过将全连接层卷积化实现语义分割,输出像素级分类热图。采用双线性插值或反卷积完成上采样,利用跳跃连接融合低层细节。以VGG16为骨干,损失函数为逐像素交叉熵,最终输出与输入同尺寸的分割图。
在计算机视觉的几个核心任务里,“语义分割”听起来可能有点陌生,但说直白点就是:让算法把图像里的每一个像素点都给你标上类别。比如,这张图里哪些像素属于“人”,哪些属于“车”,哪些又属于“天空”。这跟图像分类那种只给整张图打个标签不同,它追求的是像素级别的精细化理解。
之前聊过图像分类,本质上是通过各种特征提取手段,判定一张图属于哪一个大类。而语义分割要做的,是精确描绘出每个物体的轮廓和位置。从效果上看,就好比给图像中每个已知物体都涂上了不同的颜色。

从分类到分割,这个跨越是怎么实现的?一个经典的里程碑就是 FCN(Fully Convolutional Network,全卷积网络)。
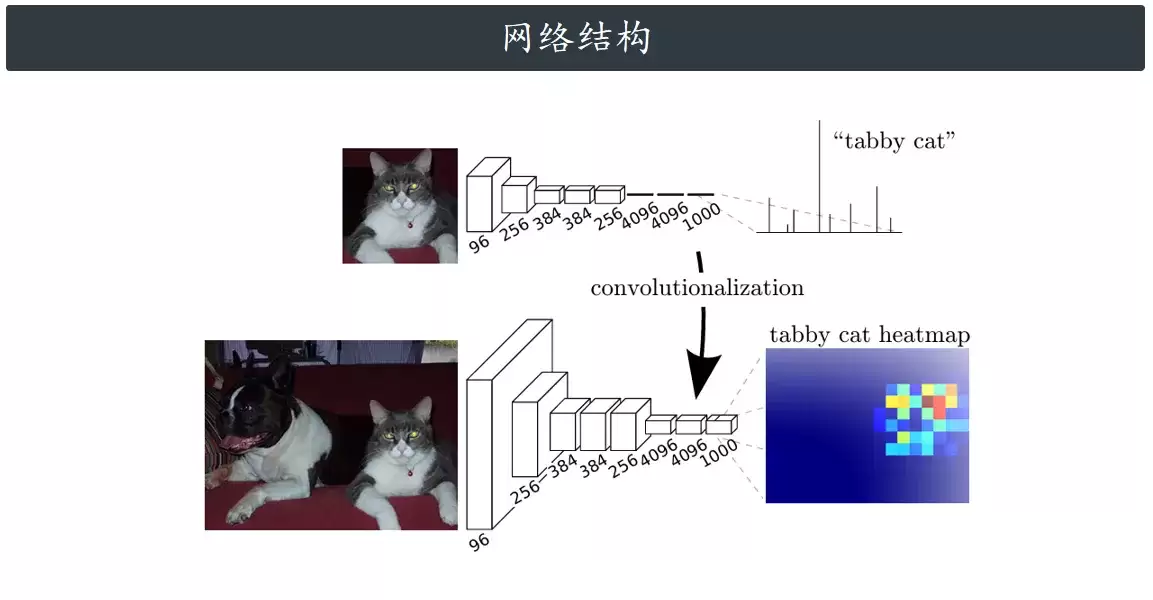
网络结构
FCN 和普通卷积网络最直观的区别就在“尾巴”上。普通的 CNN 最后面接的是几层全连接层,用来输出一个一维的类别向量。而 FCN 把这些全连接层全部“卷积化”了,最后的输出变成了一个二维的特征热图,用来逐个像素地判断类别。
以经典的 VGG16 为基础来改造 FCN,作者就是把手的那几层全连接层(FC6, FC7, FC8)给做了个魔改:
- FC6 变成了一个 7x7 的大卷积核(Conv6),用来捕捉全局语义信息。
- FC7 变成了 1x1 的卷积(Conv7),增加非线性,进一步提纯特征。
- FC8 也变成了 1x1 的卷积(Conv8),但它的输出通道数被设定为任务要分类的数目 N。
假设要区分三类物体:背景、水体、污泥。那么最后 Conv8 输出的维度就是 (1, 3, H, W)。这里面,第 1 层通道记录的是全图每个位置属于“背景”的分数,第 2 层通道是“水体”的分数,第 3 层通道是“污泥”的分数。
为了更直观地理解特征图尺寸在整个网络中的变化,VGG16 的下采样过程大致如下表所示:
| 阶段 | 关键操作 | 输出特征图尺寸 | 尺寸缩小倍数 |
| 输入层 | 原始图像 | 224* 224 *3 | - |
| Conv1 | 卷积 + MaxPool | 112* 112 *64 | 2x |
| Conv2 | 卷积 + MaxPool | 56* 56 *128 | 4x |
| Conv3 | 卷积 + MaxPool | 28* 28 *256 | 8x |
| Conv4 | 卷积 + MaxPool | 14* 14 *512 | 16x |
| Conv5 | 卷积 + MaxPool | 7* 7 *512 | 32x |
上采样
到这里就面临一个现实问题:语义分割要求输出和原图一样大的像素级标签图,但经过一连串的卷积和池化后,特征图已经缩小了32倍。怎么把这张缩小的图恢复到原始大小?这就需要上采样。
一种最朴素的上采样方法叫最近邻插值法。它的计算逻辑很简单,就是通过目标位置乘上缩放因子,找到它在原图像中对应的位置坐标,然后四舍五入取最近的那个像素值。举个例子,上采样后的图像中 (3, 1) 这个点的值,就是原图中 (3x2/4, 1x2/4) = (1.5, 0.5) 这个位置,四舍五入后就是 (2, 1) 那个像素点的颜色值。原理虽然简单粗暴,但也意味着上采样出来的图像会非常粗糙,有明显的锯齿感。
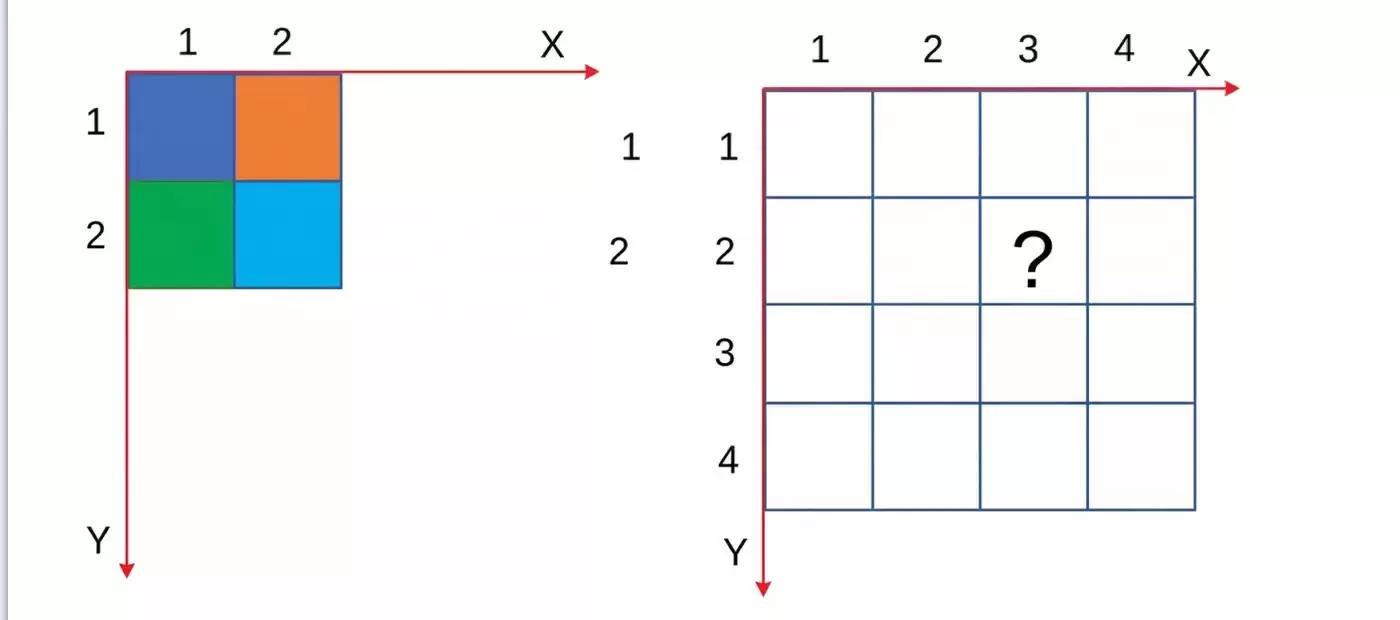
比最近邻插值更精细一点的是双线性插值。先看看它的一维版本——线性插值是怎么工作的。
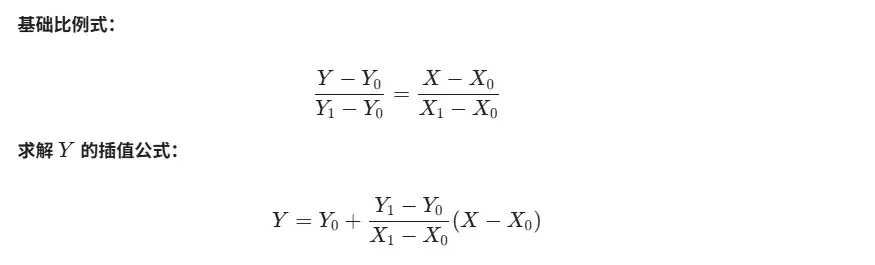
线性插值只在一个方向上做估算,误差和偶然性比较大。而双线性插值,顾名思义,就是在 X 和 Y 两个方向上各做一次线性插值,也就是用原图像中 2x2 这四个点的像素值来综合计算出新图像中那个点的像素值,准确性自然高得多。
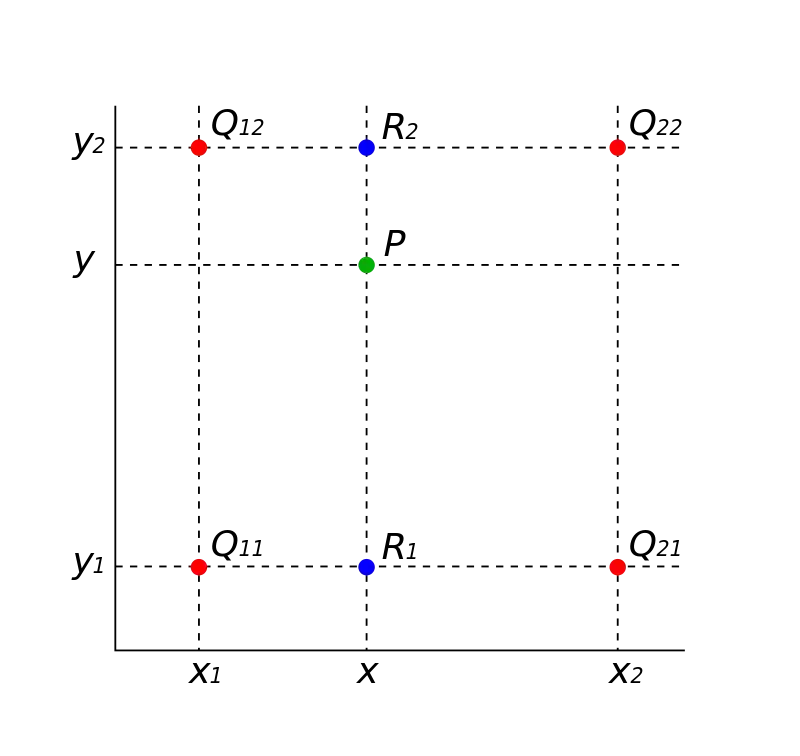
在深度学习里,还有一种更“聪明”的上采样方式,就是反卷积,它的核心职责就是把缩小的特征图通过可学习的参数恢复到更大的尺寸。

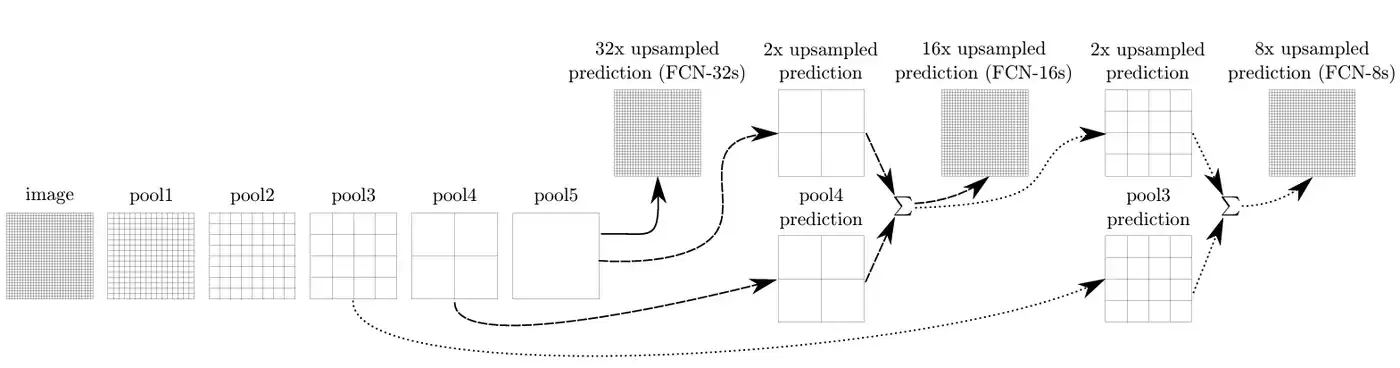
跳跃连接
网络在提取特征时,是一个从低级语义到高级语义的过程。底层的特征图往往保留了更多图像的纹理、边缘等细节信息,越往高层走,语义越抽象,但空间细节损失得也越多。如果直接用最后那层高层特征来做上采样,还原出来的分割图在细节上肯定会一塌糊涂。
怎么解决?低层信息丢了,那就把它加回来。这个思路简单粗暴,但极其有效。这,就是跳跃连接(Skip Connection)。注意,虽然它和后来残差网络里的残差连接很像,但 FCN 的跳跃连接出现得更早,甚至可以看作是残差结构的前身。
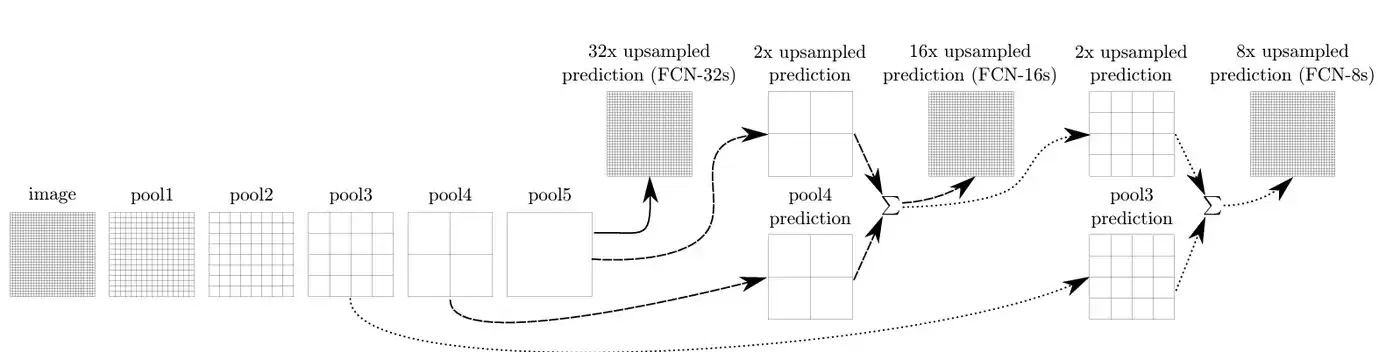
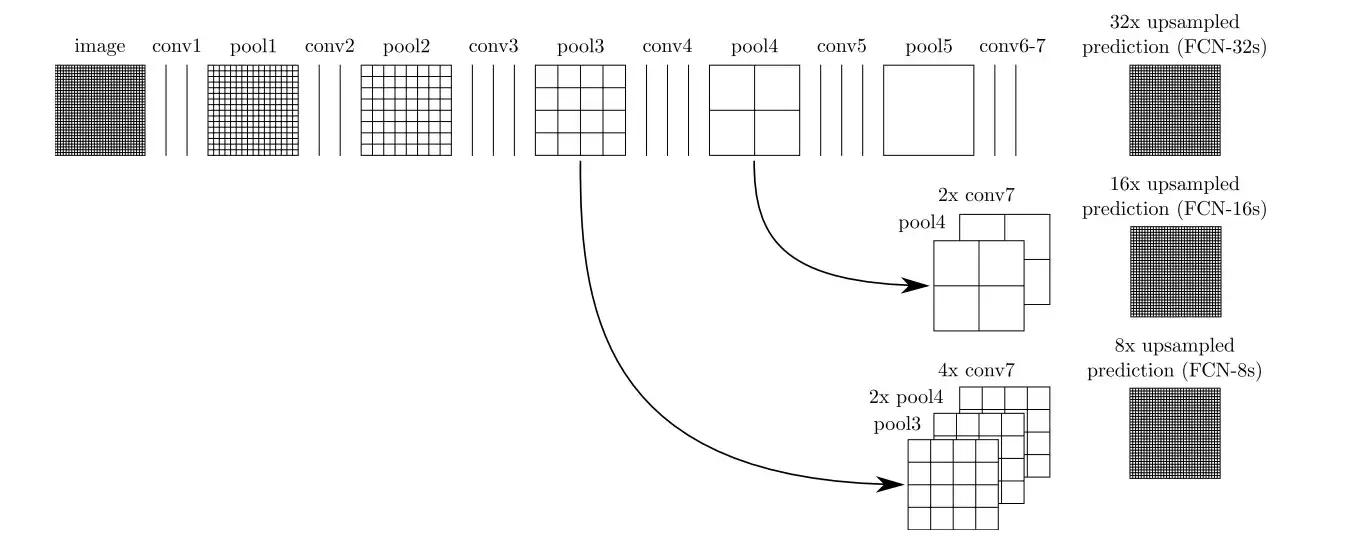
具体怎么操作?以 FCN-8s 为例,在执行逐点相加之前,必须满足两个硬性条件:尺寸相同且通道数相同。尺寸控制靠反卷积上采样,通道控制靠 1x1 卷积。
流程拆解如下:
- 顶层降维: Conv7(4096维)先通过一个1x1卷积,变成 (7, 7, 3)。
- 第一次融合(FCN-16s 路径): 把 Conv7 的结果2倍上采样,变成 (14, 14, 3)。同时把 Pool4(14, 14, 512)也用一个1x1卷积变成 (14, 14, 3)。两者逐点相加,得到融合特征 A (14, 14, 3)。
- 第二次融合(FCN-8s 路径): 把特征 A 再2倍上采样,变成 (28, 28, 3)。同时把 Pool3(28, 28, 256)用1x1卷积变成 (28, 28, 3)。两者再逐点相加,得到融合特征 B (28, 28, 3)。
- 最终输出: 把特征 B 进行8倍上采样,直接跳回 (224, 224, 3)。最后通过 Softmax 得到每个类别在每个像素上的概率。


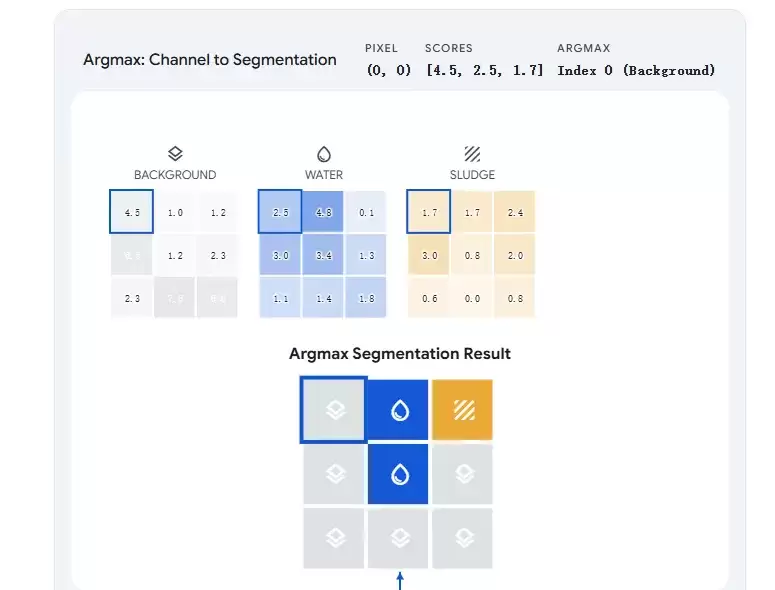
最终得到的 (224, 224, 3) 特征图,可以理解为3层重叠的概率图。对于坐标 (x, y) 处的像素,如果 Channel_0 分数是 0.1,Channel_1 分数是 0.8,Channel_2 分数是 0.1,那么该像素就被判定为类别 1(水体)。
```python # 预测输出: [Batch, 3, 224, 224] # 真实标签: [Batch, 224, 224] (这里的每个像素是类别的索引,如0,1,2) loss = criterion(output, target) ```

损失函数怎么算?
语义分割的损失计算,其实就是把图像分类的逻辑,在每一个像素点上反复执行几万次。因为是对每个像素做独立分类,最常用的损失函数就是交叉熵损失。
假设图片分为三类:0-背景,1-水体,2-污泥。对于原图中某个像素点,真实标签告诉我们“这是水体(标签为1)”。模型在经过一系列计算后,在 (100, 100) 这个位置输出了三个通道的得分,比如:通道0(背景)得分为1.5,通道1(水体)得分为2.8,通道2(污泥)得分为-0.5。
手算交叉熵
模型输出的得分没有上下限,需要先用 Softmax 公式把它变成总和为1的概率分布。


计算之后,三个通道上的值就被转换成了三个概率。此时我们只盯着真实标签对应的那个概率看。真实标签是水体,所以只看那 76.4% 的概率。交叉熵 Loss 的公式非常简洁:


拿这个例子套进去,Loss 值大约是 0.269。
全图的 Loss 怎么算?
刚才只算了一个像素点的 Loss。在 224x224 的图片里,一共有 50176 个像素点。全图的最终 Loss,就是把所有这 50176 个像素点的 Loss 全部加起来,再求一个平均值。这个平均值,就是最终反向传播用来更新网络参数的数值。
网络结构代码
理论讲完,来看看核心代码,这样理解会更上一层楼。
_make_bilinear_weights
这个函数的任务是生成双线性插值的权重,用来初始化上采样层。
假设我们要生成一个大小为 3 的双线性卷积核。首先计算 factor=(3+1)//2=2,center=2-1=1。在一个长度为3的线段上(坐标0,1,2),中心点正好落在坐标1上。
然后使用 og = np.ogrid[:size, :size] 生成两个一维向量。


核心公式是:filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)





代码实现如下:
```python # ========================================== # 拼图1:定义双线性插值的权重初始化函数 # (呼应博客理论:让反卷积层初始状态就具有双线性插值的能力) # ========================================== def _make_bilinear_weights(size, num_channels): """ 创建双线性插值的卷积核权重 """ factor = (size + 1) // 2 if size % 2 == 1: center = factor - 1 else: center = factor - 0.5 # 构造一个网格,根据距离中心的距离计算权重 og = np.ogrid[:size, :size] filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor) filt = torch.from_numpy(filt).float() # 生成权重矩阵 [out_channels, in_channels/groups, H, W] w = torch.zeros(num_channels, 1, size, size) w[:, 0, :, :] = filt return w ```
VGG16 Backbone
这个函数用于加载预训练的 VGG16模型作为骨干网络,它是 FCN 的“眼睛”。
```python def get_backbone(backbone='vgg16', pretrained=True): if backbone == 'vgg16': # 使用 torchvision 自带的 VGG16 model = models.vgg16(pretrained=pretrained) return model else: raise NotImplementedError("目前只支持 vgg16") ```
完整代码
下面就是 FCN-8s 的完整实现,把前面讲的所有概念都串了起来。
```python import torch import torch.nn as nn import torchvision.models as models import numpy as np # ========================================== # 拼图1:定义双线性插值的权重初始化函数 # ========================================== def _make_bilinear_weights(size, num_channels): factor = (size + 1) // 2 if size % 2 == 1: center = factor - 1 else: center = factor - 0.5 og = np.ogrid[:size, :size] filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor) filt = torch.from_numpy(filt).float() w = torch.zeros(num_channels, 1, size, size) w[:, 0, :, :] = filt return w # ========================================== # 拼图2:获取预训练的 VGG16 Backbone # ========================================== def get_backbone(backbone='vgg16', pretrained=True): if backbone == 'vgg16': model = models.vgg16(pretrained=pretrained) return model else: raise NotImplementedError("目前只支持 vgg16") # ========================================== # 核心网络:FCN-8s 完整架构 # ========================================== class FCN8s(nn.Module): def __init__(self, num_classes=21, backbone='vgg16'): super(FCN8s, self).__init__() self.num_classes = num_classes # 加载特征提取网络 vgg_model = get_backbone(backbone=backbone, pretrained=True) features = list(vgg_model.features.children()) # 找到所有 MaxPool2d 层的位置 pool_indices = [i + 1 for i, layer in enumerate(features) if isinstance(layer, nn.MaxPool2d)] pool_indices = [0] + pool_indices + [len(features)] # 划分 5 个下采样阶段 self.stage1 = nn.Sequential(*features[pool_indices[0]:pool_indices[1]]) self.stage2 = nn.Sequential(*features[pool_indices[1]:pool_indices[2]]) self.stage3 = nn.Sequential(*features[pool_indices[2]:pool_indices[3]]) self.stage4 = nn.Sequential(*features[pool_indices[3]:pool_indices[4]]) self.stage5 = nn.Sequential(*features[pool_indices[4]:pool_indices[5]]) # 全卷积头 (替换原有的全连接层) self.fcn_head = nn.Sequential( nn.Conv2d(512, 4096, kernel_size=7, padding=3), nn.ReLU(inplace=True), nn.Dropout2d(), nn.Conv2d(4096, 4096, kernel_size=1), nn.ReLU(inplace=True), nn.Dropout2d(), nn.Conv2d(4096, self.num_classes, kernel_size=1), ) # 1x1 卷积,用于控制池化层的通道数 self.pool3_score = nn.Conv2d(256, self.num_classes, kernel_size=1) self.pool4_score = nn.Conv2d(512, self.num_classes, kernel_size=1) # 反卷积上采样层 self.upsample2_1 = nn.ConvTranspose2d(self.num_classes, self.num_classes, kernel_size=4, stride=2, padding=1, bias=False) self.upsample2_2 = nn.ConvTranspose2d(self.num_classes, self.num_classes, kernel_size=4, stride=2, padding=1, bias=False) self.upsample8 = nn.ConvTranspose2d(self.num_classes, self.num_classes, kernel_size=16, stride=8, padding=4, bias=False) # 初始化反卷积层的权重为双线性插值 for m in self.modules(): if isinstance(m, nn.ConvTranspose2d): m.weight.data.zero_() m.weight.data = _make_bilinear_weights(m.kernel_size[0], m.out_channels) def forward(self, x): input_size = x.size()[2:] # 记录原始输入尺寸 # 前向传播:提取特征 x = self.stage1(x) x = self.stage2(x) pool3 = self.stage3(x) pool4 = self.stage4(pool3) x = self.stage5(pool4) # 全卷积化 x = self.fcn_head(x) # ==================== 跳跃连接与融合 ==================== # 第一次融合:2倍上采样的深层特征 + 降维后的 pool4 x = self.upsample2_1(x) pool4_score = self.pool4_score(pool4) pool4_score = pool4_score[:, :, :x.size()[2], :x.size()[3]] x = x + pool4_score # 第二次融合:再进行2倍上采样 + 降维后的 pool3 x = self.upsample2_2(x) pool3_score = self.pool3_score(pool3) pool3_score = pool3_score[:, :, :x.size()[2], :x.size()[3]] x = x + pool3_score # ==================== 最终上采样 ==================== # 第三次:直接 8倍 上采样 x = self.upsample8(x) x = x[:, :, :input_size[0], :input_size[1]] # 确保输出尺寸与原图一致 return x # ========================================== # 简单的测试脚本 # ========================================== if __name__ == '__main__': dummy_input = torch.randn(1, 3, 224, 224) model = FCN8s(num_classes=3) output = model(dummy_input) print(f"输入图像尺寸: {dummy_input.shape}") print(f"预测输出尺寸: {output.shape}") ```运行测试,可以看到输出是符合预期的:
输入图像尺寸: torch.Size([1, 3, 224, 224])
预测输出尺寸: torch.Size([1, 3, 224, 224])
至此,从 FCN 的核心思想、网络结构、上采样策略、跳跃连接原理,到损失函数计算和最终的代码实现,整个闭环就打通了。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:PyTorch深度学习实战 手算FCN全卷积神经网络要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点AI生成甘特图时间线混乱源于提示词缺乏结构化约束。解决方法:强制指定起止日作为时序锚点;用箭头或括号显式声明任务依赖;以自然周为单位,禁用相对时间表述,仅使用绝对日期格式。
在Windows或macOS本地运行Sunov4需自行搭建环境。Windows必须使用WSL2子系统,macOS需启用Metal后端。关键步骤包括安装Python3 11+、正确配置CUDA驱动(≥536 67)及建立符号链接,否则无法调用v4模型。首次运行会自动下载约4 2GB权重文件,建议磁盘空间超10GB。
Manusv1 8在Mac上因沙盒机制无法同步iCloud。需授予完全磁盘访问权限,将项目路径设为~ Library MobileDocuments com~apple~CloudDocs ,并删除cloud_state json文件重置状态。前提:已登录iCloud并开启云盘。
用AI工具撰写季度目标拆解表时,许多初次使用者常在提示词环节出错。尝试几次便会发现:要么AI输出的内容缺少责任人和时间节点,要么直接生成一段密密麻麻的长篇大论。问题究竟出在哪里?核心在于提示词未能匹配妙鸭文档AI的解析逻辑,也没有兼顾实际使用中的理解盲区。 先明确一个关键判断:妙鸭文档AI无法识别诸
- 日榜
- 周榜
- 月榜
热点快看