




PyTorch深度学习实战 手动计算Transformer与完整代码实现

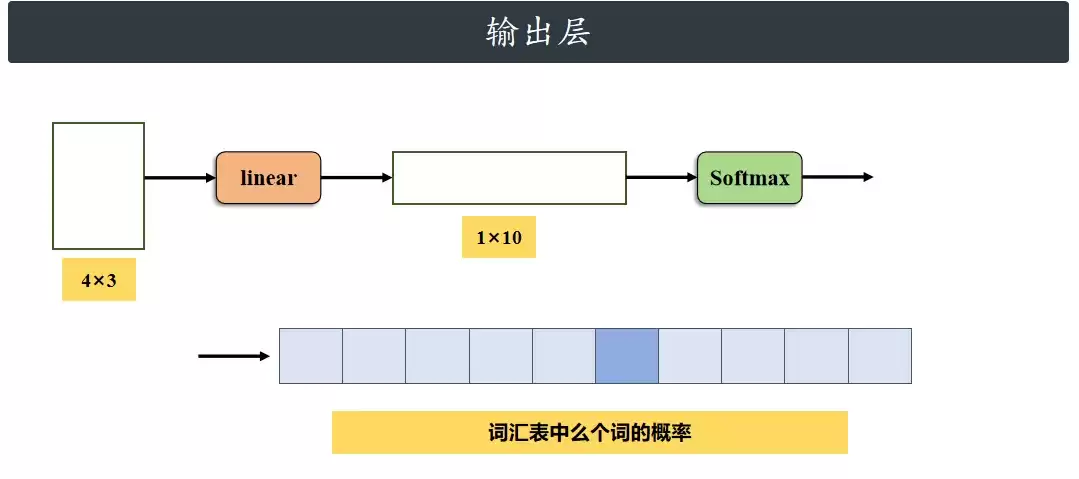
Transformer输出层由线性层和Softmax组成,将解码器输出的512维特征映射为词汇表上的分数,经Softmax转换为概率分布,选取概率最大的索引对应的汉字作为当前预测结果。模型自回归地逐步生成输出序列,直至结束符。
假设你现在要开发一个英译汉的翻译系统,输入一句英文“Are you OK?”,期待模型输出对应的中文“你 好 吗 ?”。那模型到底是怎么把英文一步步变成中文的呢?我们先看输出层——它是整个Transformer的最后一公里,负责把解码器算出的抽象特征,最终映射成我们能看懂的文字。
现在我们把Transformer当作一个整体来看。假设输入的英文“Are you OK?”在词嵌入和位置编码后,变成了一个形状为 4 * 512 的张量。参考之前博客的讲解,经过复杂的编码-解码流程之后,解码器输出的依然是一个 4 * 512 的张量。你可能会问:这个抽象的512维特征,是怎么变成具体汉字的?答案就在线性层和Softmax层。
基于此前已生成的结果,模型会持续推理后续的输出内容。在这个过程中,模型是自回归地、一步步生成输出序列的,推理流程如下图所示。
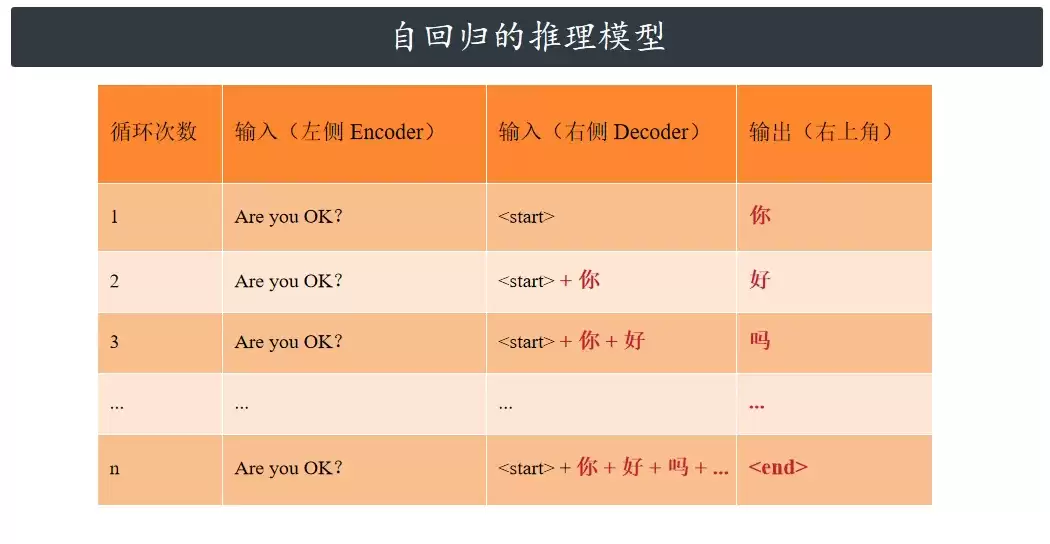
假设我们的中文词汇表非常小,只有 10 个词(对应 10 个索引),那么整个预测流程就像下面这样,分五步走:
(1) 解码器在当前循环输出一个512维的特征向量,这个向量代表了“下一个要预测的词”的抽象特征;
(2) 这个512维特征传入线性层,被映射成一个 1×10 的张量 —— 这个张量里的10个数值,分别代表当前这个位置与词汇表里10个词的“匹配分数”(也叫 logits);
(3) 接着,把这个 1×10 的分数张量喂给 Softmax 函数,将分数转换成概率分布(10个概率值的总和为1),哪个词的概率最高,就说明模型认为哪个词最可能是正确答案;
(4) 然后,从这 10 个概率值中挑出数值最大的那个,它的索引就是当前循环的预测结果;
(5) 最后,根据这个索引去中文词汇表里查表,找到对应的汉字,这就是当前循环的最终输出。
之后,会把这个刚生成的汉字拼接到解码器的输入中,进入下一次循环,预测下一个词,直到模型生成结束符(
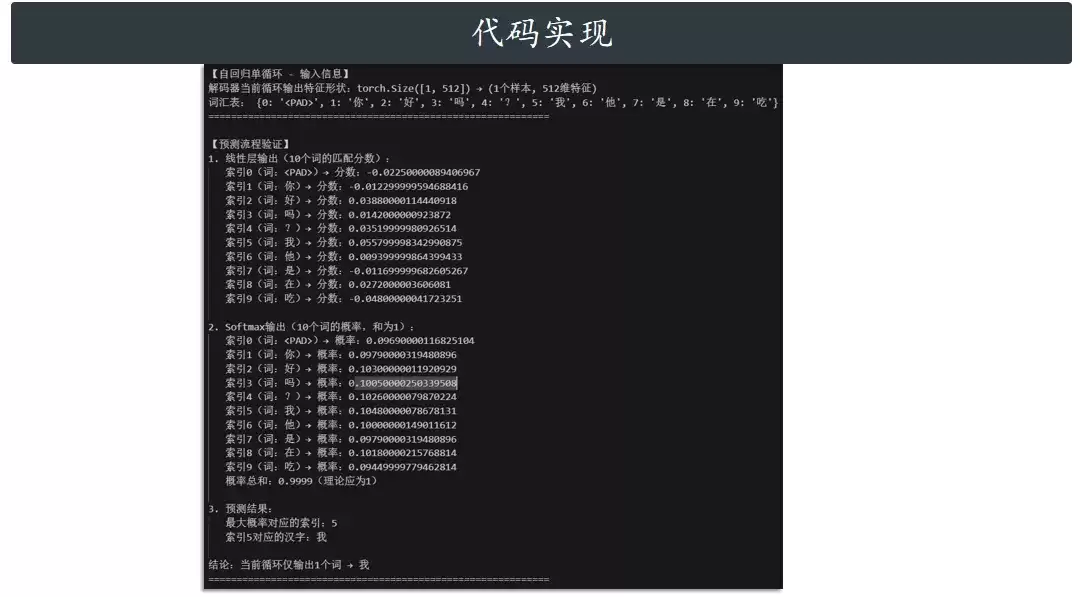
光说不练假把式,咱们上代码。用PyTorch来实现Transformer的最后两层(线性层 + Softmax)看看:
import torch
import torch.nn as nn
import torch.nn.functional as F
# -------------------------- 1. 实现 Transformer 最后两层(线性层 + Softmax)--------------------------
class TransformerFinalLayers(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
"""
Args:
d_model: 解码器输出的特征维度(固定512)
vocab_size: 中文词汇表大小(这里设为10)
"""
super().__init__()
# 线性层:512维特征 → 10维词汇表分数
self.linear = nn.Linear(d_model, vocab_size)
# 参数初始化(保证预测稳定)
nn.init.xa vier_normal_(self.linear.weight, gain=0.02)
nn.init.zeros_(self.linear.bias)
def forward(self, decoder_feature: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor, int, str]:
"""
前向传播(单个循环,仅输出1个词)
Args:
decoder_feature: 解码器当前循环的特征 (1, 512) → 1个样本,512维特征
Returns:
scores: 线性层输出的分数 (1, 10)
probs: Softmax后的概率 (1, 10)
pred_idx: 最大概率对应的词索引(整数)
pred_word: 最终预测的汉字(字符串)
"""
# 1. 线性层:高维特征 → 词汇表分数
scores = self.linear(decoder_feature) # (1, 10)
# 2. Softmax:分数 → 概率(按最后一维归一化,和为1)
probs = F.softmax(scores, dim=-1) # (1, 10)
# 3. 取最大概率的索引
pred_idx = torch.argmax(probs, dim=-1).item() # 从张量转成整数索引
return scores, probs, pred_idx
# -------------------------- 2. 具体例子验证(自回归单循环)--------------------------
if __name__ == "__main__":
# -------------- 步骤1:设置关键参数和词汇表 --------------
d_model = 512 # 解码器特征维度
vocab_size = 10 # 中文词汇表大小
# 中文词汇表:索引→汉字映射(简化版)
chinese_vocab = {
0: "", # 填充词
1: "你", # 目标预测词(对应英文Are)
2: "好", # 后续循环预测词
3: "吗", # 后续循环预测词
4: "?", # 后续循环预测词
5: "我", # 干扰项
6: "他", # 干扰项
7: "是", # 干扰项
8: "在", # 干扰项
9: "吃" # 干扰项
}
# -------------- 步骤2:模拟解码器输入特征(单个循环)--------------
# 自回归某一次循环:解码器输出 (1, 512) 特征(融合了历史生成词+原文信息)
torch.manual_seed(42) # 固定种子,结果可复现
decoder_feature = torch.randn(1, d_model) # (1, 512) → 1个样本,512维特征
print("="*60)
print("【自回归单循环 - 输入信息】")
print(f"解码器当前循环输出特征形状:{decoder_feature.shape} → (1个样本, 512维特征)")
print("词汇表:", chinese_vocab)
print("="*60)
# -------------- 步骤3:初始化最后两层并执行预测 --------------
final_layers = TransformerFinalLayers(d_model=d_model, vocab_size=vocab_size)
scores, probs, pred_idx = final_layers(decoder_feature)
pred_word = chinese_vocab[pred_idx] # 索引→汉字
# -------------- 步骤4:打印结果(验证流程)--------------
print("\n【预测流程验证】")
# 1. 线性层输出(分数)
print(f"1. 线性层输出(10个词的匹配分数):")
scores_rounded = (torch.round(scores * 10000) / 10000).squeeze().tolist() # 保留4位小数
for idx, score in enumerate(scores_rounded):
print(f" 索引{idx}(词:{chinese_vocab[idx]})→ 分数:{score}")
# 2. Softmax输出(概率)
print(f"\n2. Softmax输出(10个词的概率,和为1):")
probs_rounded = (torch.round(probs * 10000) / 10000).squeeze().tolist() # 保留4位小数
total_prob = sum(probs_rounded) # 验证概率和为1
for idx, prob in enumerate(probs_rounded):
print(f" 索引{idx}(词:{chinese_vocab[idx]})→ 概率:{prob}")
print(f" 概率总和:{round(total_prob, 4)}(理论应为1)")
# 3. 最终预测结果
print(f"\n3. 预测结果:")
print(f" 最大概率对应的索引:{pred_idx}")
print(f" 索引{pred_idx}对应的汉字:{pred_word}")
print(f"\n结论:当前循环仅输出1个词 → {pred_word}")
print("="*60)
集成化的实现
下面这张图是Transformer的整体结构,看着确实挺复杂,对吧?
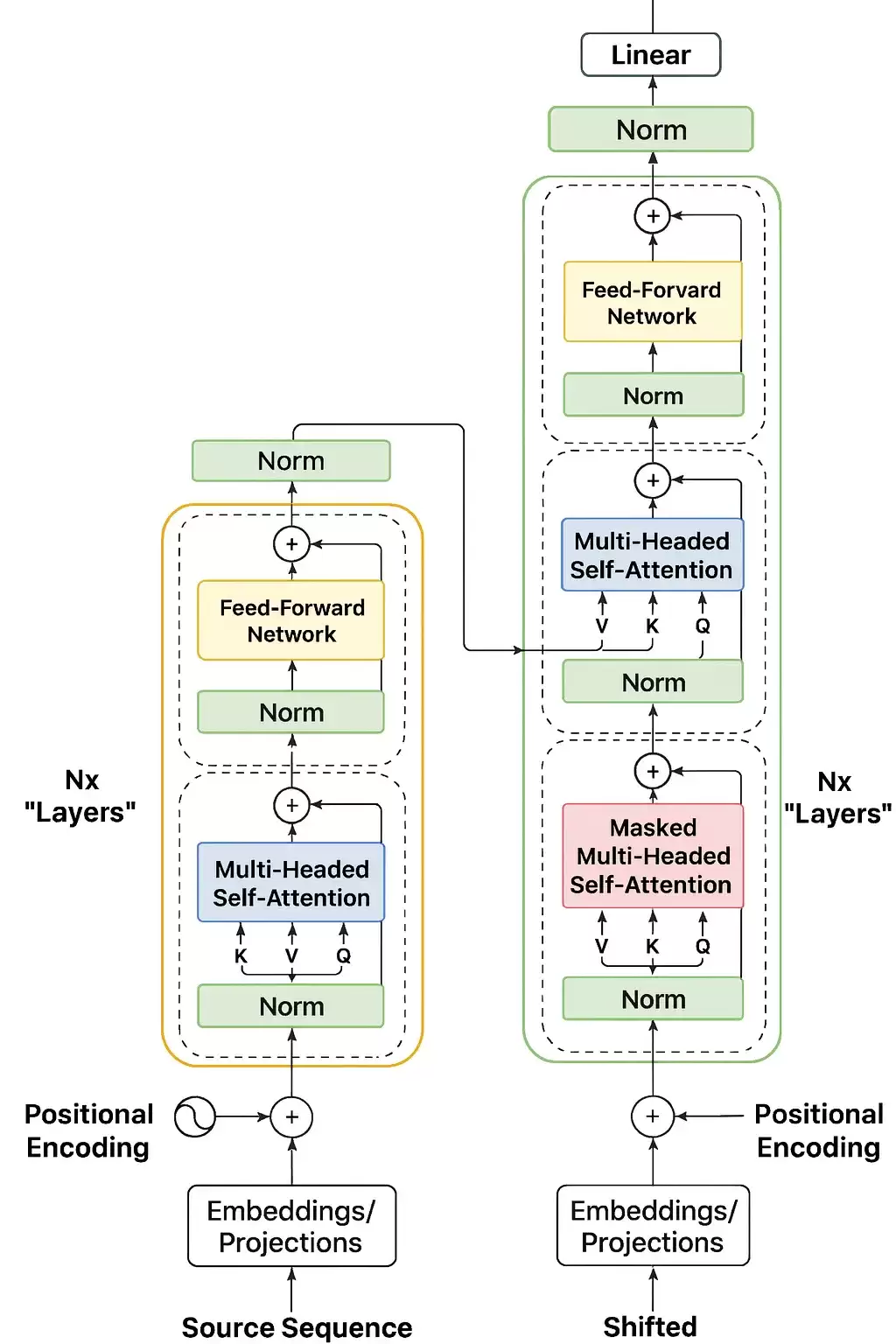
但是,如果咱们把编码器和解码器分别封装成一个个模块,整体结构是不是就显得清爽多了?我们把封装起来的模块统称为Transformer 模块。
这样一来,整个Transformer模型就可以被简化成以下几个核心模块:
(1)词嵌入层
(2)位置编码
(3)Transformer 模块
(4)全连接层
下面我们来详细看看每一层的作用。
词嵌入层
首先,词嵌入层要解决一个根本问题:模型是“数字计算器”,只认识数字,不认识汉字或英文单词。词嵌入层的作用,就是把这些离散的词索引(整数),映射成包含语义信息的高维向量(连续数值)。这就好比给每个词都安排了一个独特的“身份证号码”,但这个号码里还藏了词的“性格”和“关系”。
import torch
import torch.nn as nn
# 1. 定义词嵌入层:词汇表大小=3(3个词),每个词转成2维向量(极简维度)
embedding = nn.Embedding(num_embeddings=3, embedding_dim=2)
# 输入3个词的索引(0、1、2)
word_indices = torch.tensor([0, 1, 2], dtype=torch.long)
vecs = embedding(word_indices)
print(vecs)
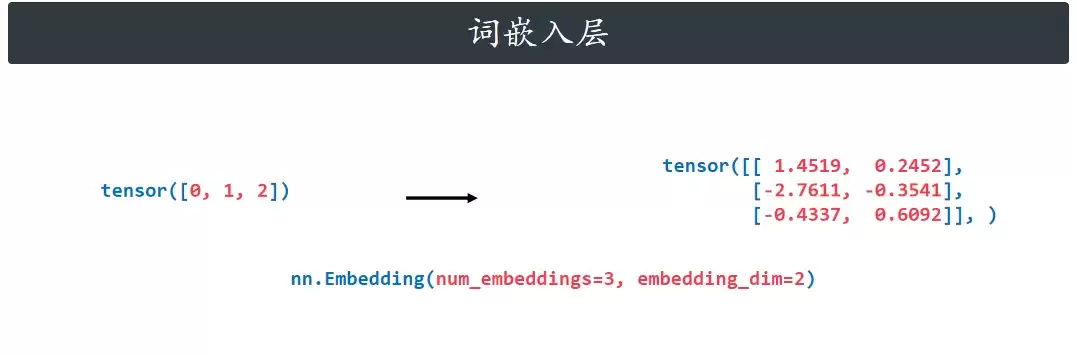

一个简单的例子
接下来,我们写一个非常简单的例子,模拟数据在各层之间的流转过程。假设我们只有一个样本,这句话包含3个词,所以输入大小应该是 (1*3) 的。
- 经过词嵌入层,输出(1*3*2) 的张量
- 加上位置编码,输出(1*3*2) 的张量
- 经过Transformer层,输出(1*3*2) 的张量
- 经过全连接层,输出(1*3*3) 的张量
import torch
import torch.nn as nn
# 定义完整的简化版 Transformer(含指定结构)
class SimpleTransformer(nn.Module):
def __init__(self, vocab_size=3, model_dim=2, max_seq_len=1000):
super().__init__()
# 1. 词嵌入层
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=model_dim)
# 2. 位置编码(指定参数化方式)
self.positional_encoding = nn.Parameter(torch.zeros(1, max_seq_len, model_dim))
# 3. Transformer 模块(batch_first=True)
self.transformer = nn.Transformer(
d_model=model_dim,
nhead=1, # model_dim=2 仅支持1个注意力头(2÷1=2,整除)
num_encoder_layers=1,
num_decoder_layers=1, # 显式指定解码器层数(默认和编码器一致)
batch_first=True
)
# 4. 全连接层
self.fc = nn.Linear(model_dim, vocab_size)
def forward(self, x):
# 输入 x: (batch_size, seq_len) = (1, 3)
batch_size, seq_len = x.shape
# -------------------------- 层1:词嵌入层 --------------------------
embed_out = self.embedding(x) # (1, 3, 2)
# -------------------------- 层2:位置编码层(叠加) --------------------------
# 只取前 seq_len 个位置的编码(避免超出序列长度)
pos_enc = self.positional_encoding[:, :seq_len, :] # (1, 3, 2)
pos_embed_out = embed_out + pos_enc # (1, 3, 2)
# -------------------------- 层3:Transformer 模块 --------------------------
# 生成解码器掩码(屏蔽未来词)
tgt_mask = self.transformer.generate_square_subsequent_mask(seq_len).to(x.device)
# Transformer 前向传播(编码器+解码器)
transformer_out = self.transformer(
src=pos_embed_out, # 编码器输入:带位置的嵌入向量
tgt=pos_embed_out, # 解码器输入:带位置的嵌入向量(自回归场景)
tgt_mask=tgt_mask # 解码器掩码
) # (1, 3, 2)
# -------------------------- 层4:全连接层 --------------------------
fc_out = self.fc(transformer_out) # (1, 3, 3)
# 返回每一层的输出(用于打印)
return {
"输入": x,
"词嵌入层输出": embed_out,
"位置编码叠加后输出": pos_embed_out,
"Transformer模块输出": transformer_out,
"全连接层输出": fc_out
}
# -------------------------- 运行示例:打印每一层完整输出 --------------------------
if __name__ == "__main__":
# 输入:1个样本,3个词的索引(shape: (1, 3))
input_tensor = torch.tensor([[0, 1, 2]], dtype=torch.long)
# 初始化模型
model = SimpleTransformer(vocab_size=3, model_dim=2, max_seq_len=1000)
# 前向传播,获取所有层输出
all_outputs = model(input_tensor)
# 打印每一层的输出(保留4位小数,修复round报错)
print("="*80)
for layer_name, output in all_outputs.items():
print(f"\n【{layer_name}】")
print(f"形状:{output.shape}")
print("具体数值:")
# 保留4位小数(兼容所有PyTorch版本)
output_rounded = (torch.round(output * 10000) / 10000)
print(output_rounded)
print("\n" + "="*80)

运行结果:
================================================================================
【输入】
形状:torch.Size([1, 3])
具体数值:
tensor([[0., 1., 2.]])
【词嵌入层输出】
形状:torch.Size([1, 3, 2])
具体数值:
tensor([[[-0.9721, -1.0100],
[ 1.6261, -1.0117],
[-0.3243, 1.1878]]], grad_fn=)
【位置编码叠加后输出】
形状:torch.Size([1, 3, 2])
具体数值:
tensor([[[-0.9721, -1.0100],
[ 1.6261, -1.0117],
[-0.3243, 1.1878]]], grad_fn=)
【Transformer模块输出】
形状:torch.Size([1, 3, 2])
具体数值:
tensor([[[ 1., -1.],
[ 1., -1.],
[-1., 1.]]], grad_fn=)
【全连接层输出】
形状:torch.Size([1, 3, 3])
具体数值:
tensor([[[ 0.9120, 0.3824, -0.5490],
[ 0.9120, 0.3824, -0.5490],
[ 0.0754, 0.6252, -0.2340]]], grad_fn=)
================================================================================
从0开始手搓Transformer
多头注意力机制
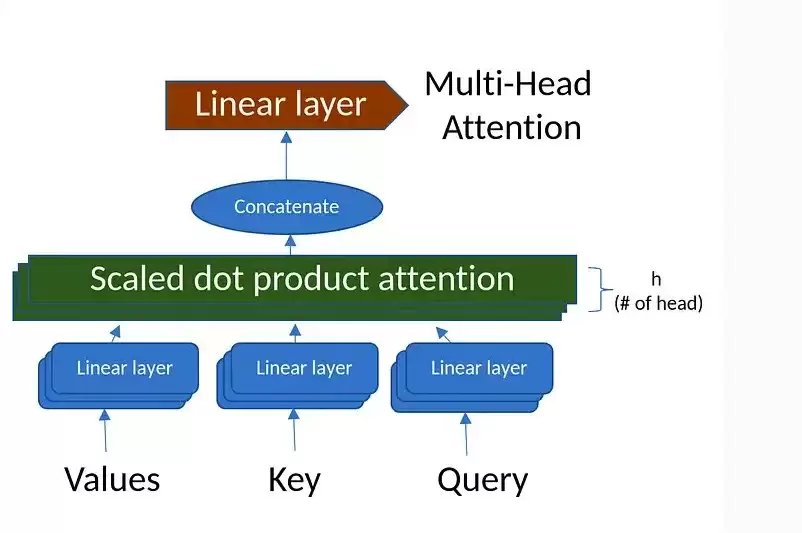

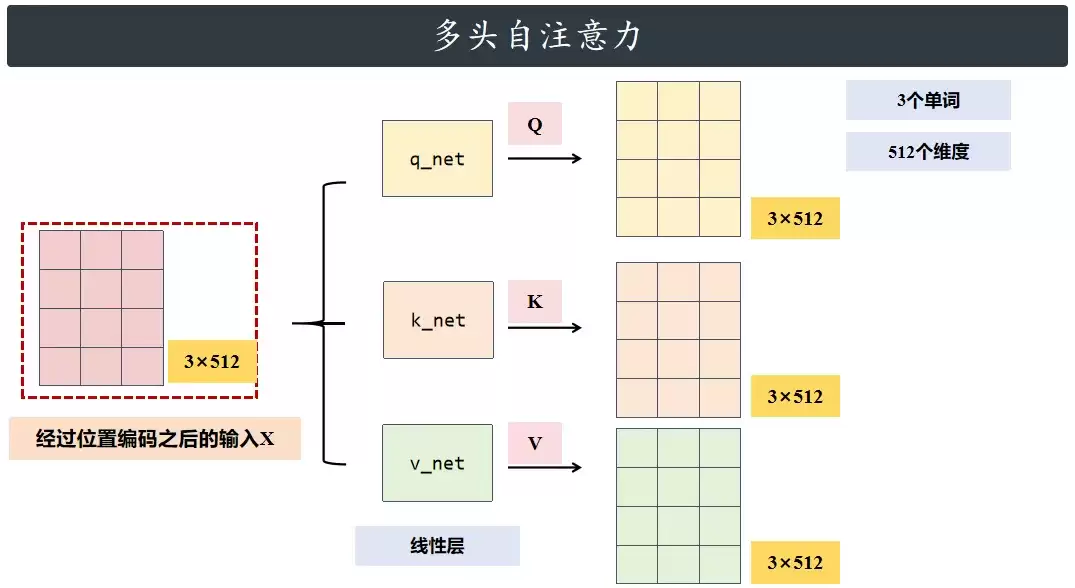
假设我们输入的数据大小为 32 * 512,32代表样本(batch),512是词向量的维度(d_model)。这里我们使用8个注意力头 (n_head)。那么,每个注意力头的维度就是 512 ÷ 8 = 64 (n_d)。接下来就是计算每个头的Q,K,V。

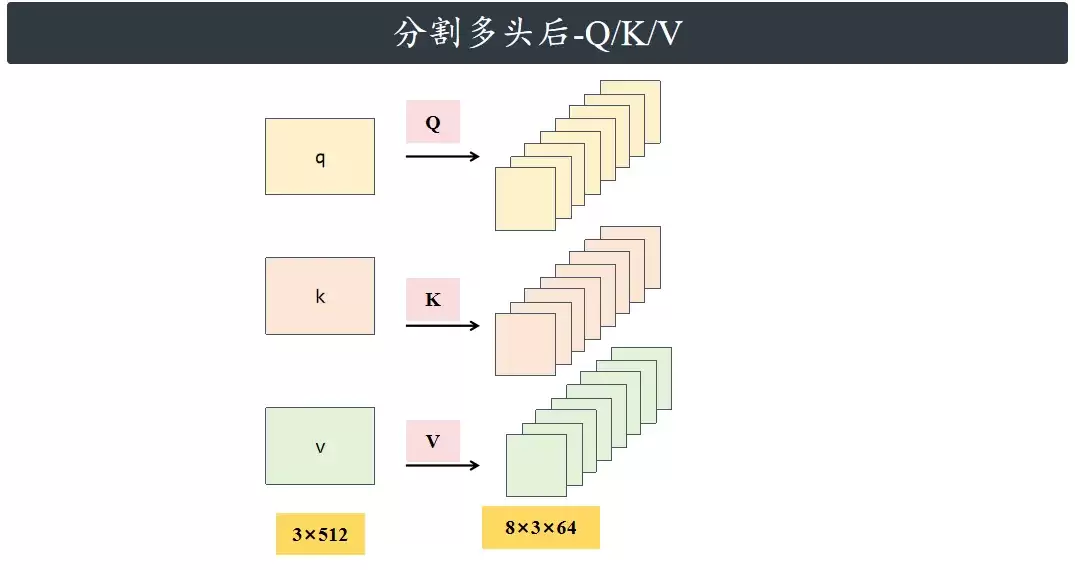
分割多头后-Q/K/V

接着,计算Q与K的点积,再除以√n_d(这是缩放操作,可以避免分数过大,让梯度更稳定)。
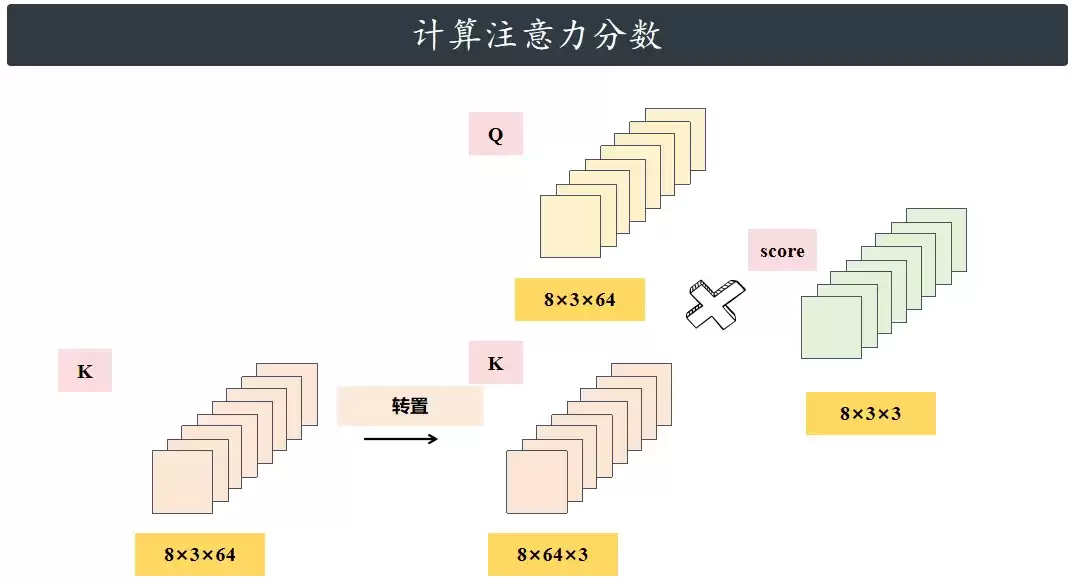
应用掩码后-注意力分数
在解码器的自注意力机制中,需要屏蔽未来的词或填充的
计算注意力权重
接着,用Softmax对分数进行归一化,让每一行的和都为1,表示当前词对序列中其他词的关注程度。输出的概率分布大小是(8*3*3)。
加权求和
最后,用注意力权重去加权V向量,得到融合了上下文信息后的特征。
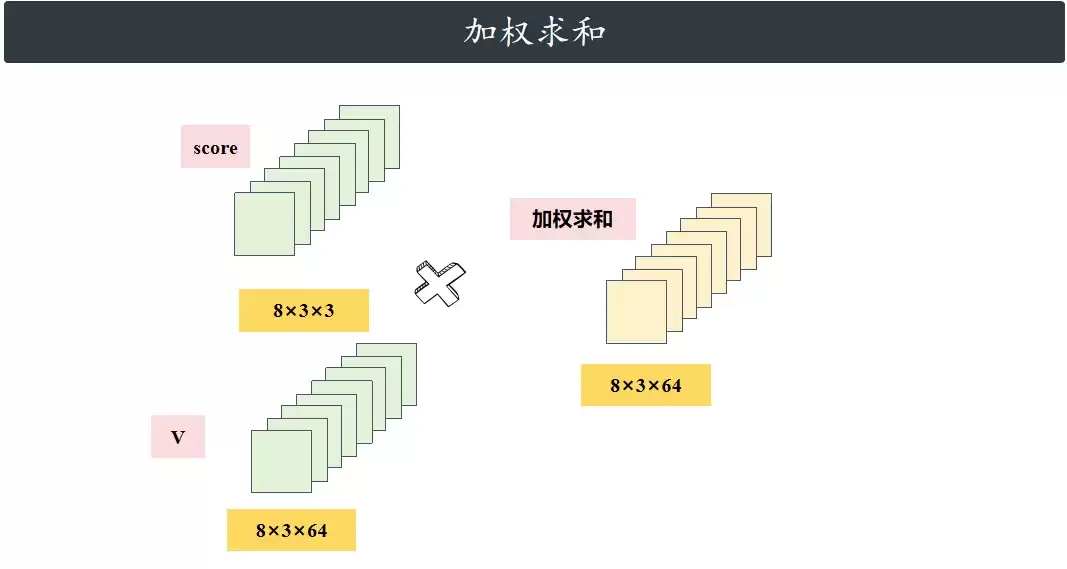
合并多头
每个头的计算结果拼接到一起,恢复到原始维度。
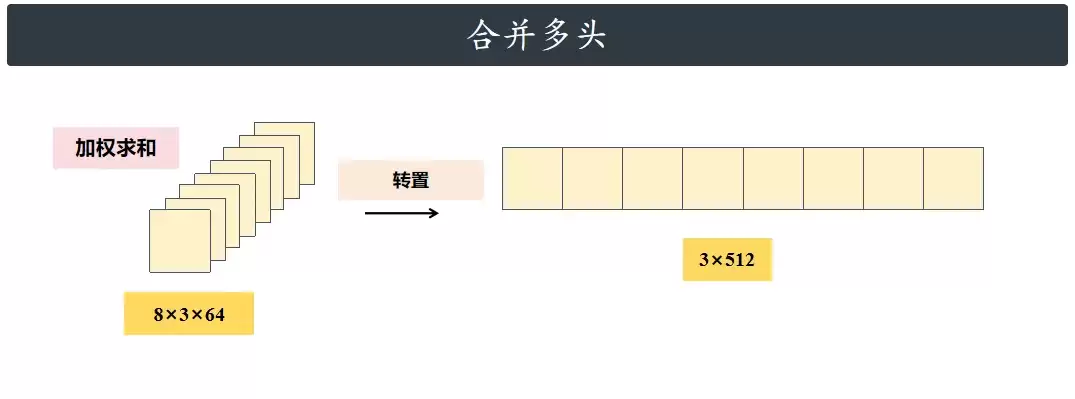
线性层
合并后的数据最后再通过一个线性层进行整合和变换,作为多头注意力的最终输出。最终输出的大小仍然是 3 * 512(假设序列长度为3)。
完整代码
import torch
from torch import nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.d_model = d_model
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_combine = nn.Linear(d_model, d_model)
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None):
batch, time, dimension = q.shape
n_d = self.d_model // self.n_head
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
q = q.view(batch, time, self.n_head, n_d).permute(0, 2, 1, 3)
k = k.view(batch, time, self.n_head, n_d).permute(0, 2, 1, 3)
v = v.view(batch, time, self.n_head, n_d).permute(0, 2, 1, 3)
score = q @ k.transpose(2, 3) / math.sqrt(n_d)
if mask is not None:
score = score.masked_fill(mask == 0, -10000)
score = self.softmax(score) @ v
score = score.permute(0, 2, 1, 3).contiguous().view(batch, time, dimension)
out = self.w_combine(score)
return out
# 定义模型的维度和头数
d_model = 512
n_head = 8
# 创建多头注意力实例
x = torch.rand(128, 32, 512)
attention = MultiHeadAttention(d_model, n_head)
out = attention(x, x, x)
print(out.shape)

位置前馈网络(Position-wise Feed-Forward Network)
前馈网络由两个全连接层和一个 ReLU 激活函数组成,主要职责是对注意力机制输出的特征做进一步的“精加工”。你可以把它想象成一个带有瓶颈结构(先升维再降维)的信息强化层。
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff) # 第一层全连接
self.fc2 = nn.Linear(d_ff, d_model) # 第二层全连接
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 前馈网络的计算
return self.fc2(self.relu(self.fc1(x)))

输入形状:torch.Size([3, 512]),输出形状:torch.Size([3, 512])。这个网络的特点是不改变输入输出的形状。
位置编码
位置编码是Transformer理解“词序”的关键。它使用不同频率的正弦和余弦函数来生成一个位置信号,就像是给序列中的每个词都贴上一个独一无二的“位置标签”,告诉模型“我是第几个词”。当然,它同样不改变输入的形状。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model) # 初始化位置编码矩阵
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置使用正弦函数
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置使用余弦函数
self.register_buffer('pe', pe.unsqueeze(0)) # 注册为缓冲区
def forward(self, x):
# 将位置编码添加到输入中
return x + self.pe[:, :x.size(1)]

构建编码器层(Encoder Layer)
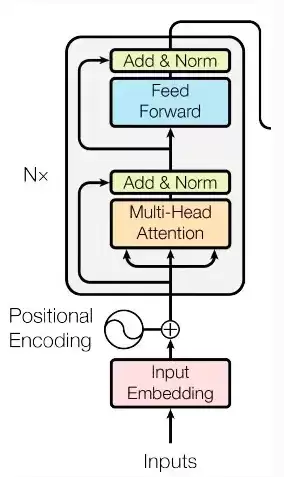
编码器层是Transformer的核心部件之一,它内部包含一个自注意力机制和一个前馈网络。每个子层的输出都会经过一个残差连接和层归一化处理,这是防止梯度消失或爆炸、加速模型训练的关键设计。
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads) # 自注意力机制
self.feed_forward = PositionWiseFeedForward(d_model, d_ff) # 前馈网络
self.norm1 = nn.LayerNorm(d_model) # 层归一化
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout) # Dropout
def forward(self, x, mask):
# 自注意力机制
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output)) # 残差连接和层归一化
# 前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output)) # 残差连接和层归一化
return x

构建解码器模块
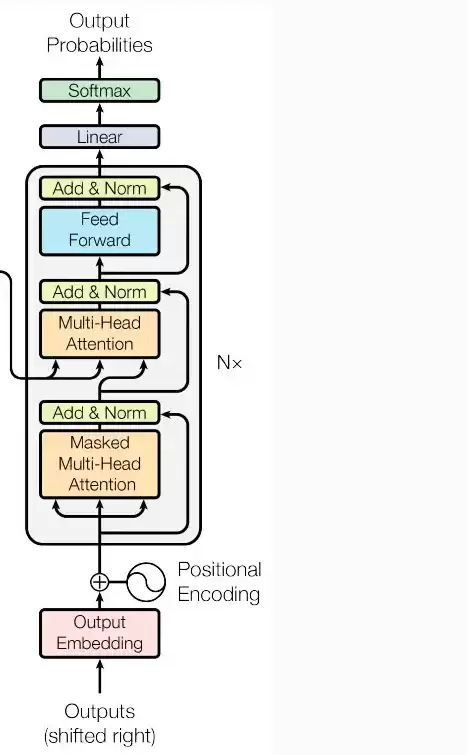

解码器层比编码器层稍微复杂一点点,它包含三个核心模块:一个屏蔽的自注意力机制(防止看到未来信息)、一个交叉注意力机制(用于关注编码器的输出)和一个前馈网络。同样,每个子层后都跟着残差连接和层归一化。
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads) # 自注意力机制
self.cross_attn = MultiHeadAttention(d_model, num_heads) # 交叉注意力机制
self.feed_forward = PositionWiseFeedForward(d_model, d_ff) # 前馈网络
self.norm1 = nn.LayerNorm(d_model) # 层归一化
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout) # Dropout
def forward(self, x, enc_output, src_mask, tgt_mask):
# 自注意力机制
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output)) # 残差连接和层归一化
# 交叉注意力机制
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output)) # 残差连接和层归一化
# 前馈网络
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output)) # 残差连接和层归一化
return x

构建完整的 Transformer 模型
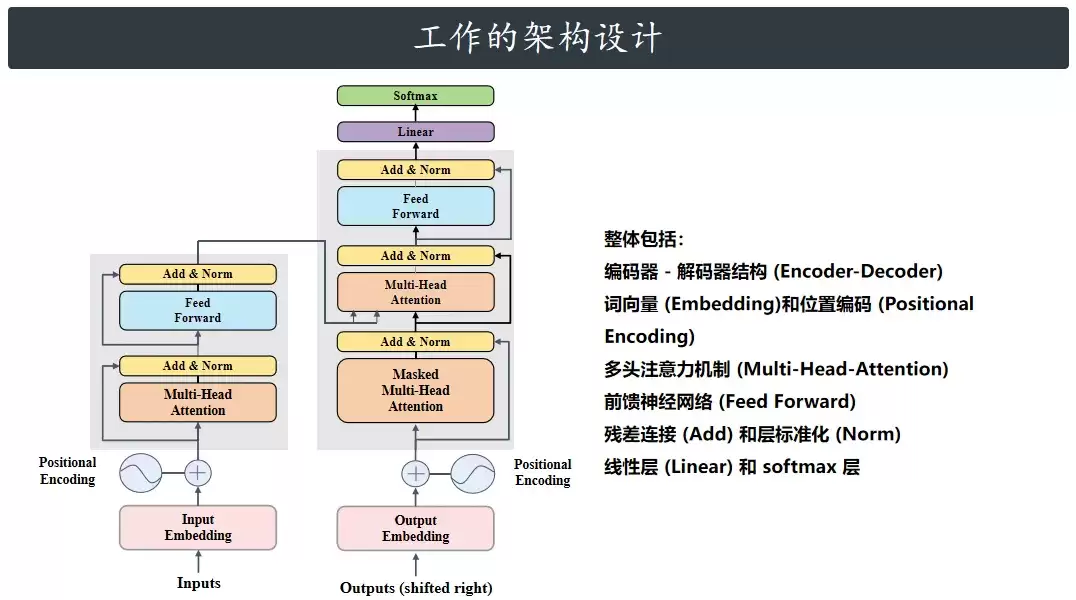

把所有组件拼装起来,就得到了一个完整的Transformer模型。下面的代码演示了如何用随机数据训练这个模型,计算损失并更新参数。
# 超参数
src_vocab_size = 5000 # 源词汇表大小
tgt_vocab_size = 5000 # 目标词汇表大小
d_model = 512 # 模型维度
num_heads = 8 # 注意力头数量
num_layers = 6 # 编码器和解码器层数
d_ff = 2048 # 前馈网络内层维度
max_seq_length = 100 # 最大序列长度
dropout = 0.1 # Dropout 概率
# 初始化模型
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# 生成随机数据
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # 源序列
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # 目标序列
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略填充部分的损失
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
# 训练循环
transformer.train()
for epoch in range(100):
optimizer.zero_grad() # 清空梯度,防止累积
# 输入目标序列时去掉最后一个词(用于预测下一个词)
output = transformer(src_data, tgt_data[:, :-1])
# 计算损失时,目标序列从第二个词开始(即预测下一个词)
# output形状: (batch_size, seq_length-1, tgt_vocab_size)
# 目标形状: (batch_size, seq_length-1)
loss = criterion(
output.contiguous().view(-1, tgt_vocab_size),
tgt_data[:, 1:].contiguous().view(-1)
)
loss.backward() # 反向传播
optimizer.step() # 更新参数
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")

模型评估
评估过程:与训练流程类似,我们在验证数据上计算损失,评估模型性能。关键区别在于,评估模式下需要关闭梯度计算,以提高速度并防止意外更新模型参数。
transformer.eval()
# 生成验证数据
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length))
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length))
# 假设输入为一批英文和对应的中文翻译(已转换为索引)
# 示例数据:
# src_data: [[3, 14, 25, ..., 0, 0], ...] # 英文句子(0为填充符)
# tgt_data: [[5, 20, 36, ..., 0, 0], ...] # 中文翻译(0为填充符)
# 注意:实际应用中需对文本进行分词、编码、填充等预处理
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")

参考文献
[1] PyTorch 构建 Transformer 模型 | 菜鸟教程
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:PyTorch深度学习实战 手动计算Transformer与完整代码实现要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点多平台发布这件事,终于可以一键搞定了。14个平台,10分钟搞定,听起来有点夸张,但确实是字流2 0现在能做到的事。 今天想聊聊这个产品背后的故事。其实没什么高大上的商业计划,纯粹是在做个人IP的路上,被各种重复劳动逼出来的产物。 先说几个核心判断:如果你同时在运营公众号、知乎、掘金、知识星球,还兼顾
一个面向知识工作者的Skills聚合站,专注将重复工作一键自动化。覆盖阅读、写作、学习、创作等场景,采用免费加付费模式,付费服务399元,支持7日内无理由退款。目标是春节前技能数量达100个以上。
腾讯会议的AI面试助手与学霸笔记功能,让高压面试和知识吸收变得轻松高效,成为职场人士的智能助理。 核心内容: 1 AI面试助手如何帮助面试官和求职者提升面试效率 2 学霸笔记功能在知识传递型会议中的实际应用场景 3 通用会议场景下AI助手的待办事项自动生成能力 三个月前, 腾讯会议AI托管功能
刚看到 NotebookLM 这个年终更新弹窗时,想必不少人第一反应是:就这? "Data Tables(数据表格) "?这都 2025 年底了,市面上哪个 AI 工具不敢吹自己能生成表格?问题从来不在于生成表格本身,而在于生成的表格能不能用、敢不敢信。谷歌那帮工程师,有时候真挺让人捉摸不透的——他们把
- 日榜
- 周榜
- 月榜
热点快看