




翁荔最新万字长文:大模型Scaling Laws需谨慎理解

最近,翁荔(Lilian Weng)时隔一年更新了一篇长文,系统梳理了 Scaling Laws 这条线。从早期机器学习里的学习曲线,到 Kaplan、Chinchilla,再到数据受限场景和现实拟合中的各种坑,一次性说清楚了。这篇文章很值得完整读一遍。它讨论的核心问题,是训练算力、模型规模、数据
最近,翁荔(Lilian Weng)时隔一年更新了一篇长文,系统梳理了 Scaling Laws 这条线。从早期机器学习里的学习曲线,到 Kaplan、Chinchilla,再到数据受限场景和现实拟合中的各种坑,一次性说清楚了。
这篇文章很值得完整读一遍。它讨论的核心问题,是训练算力、模型规模、数据 token、重复数据、拟合外推之间到底如何相互影响,而不是简单停在“模型越大越好”。
正文
缩放定律是深度学习里被讨论得最频繁的经验发现之一。形式上看,它很简单:当我们扩大模型规模、数据集规模和计算量时,训练损失会以可预测的方式下降,沿着一条幂律曲线走——在 log-log 图上,就是一条直线。我们可以把缩放定律视作一个描述计算、损失、模型规模和数据的框架;它的核心问题在于,如何在模型规模和数据之间最优地分配宝贵的计算资源。
这种可预测性让缩放定律在实践中非常有价值。常见的工作流是:先用少量小规模训练运行拟合出缩放定律,然后外推,估计更大模型所需的 token 和计算量。
| 符号 | 说明 |
|---|---|
| N | 模型规模,用参数量衡量。 |
| D | 训练数据集规模,通常用 token 数衡量。 |
| C | 训练计算量,单位为 FLOPs。一个常用的近似是 C ≈ 6ND(Kaplan et al. 2020),其中前向传播约占 2ND,反向传播约占 4ND。 |
| L0 | 不可约损失。 |
| L(N, D) | 测试损失 / 测试损失预测函数;也可以指训练损失,因为二者高度相关。 |
| E | 泛化误差。 |
早期:机器学习损失的可预测性
在缩放定律成为主流之前,关于泛化误差随规模变化的可预测性就已经有人研究过了。
Amari et al. (1992) 使用贝叶斯方法和 annealed approximation,推导出四类学习曲线:
-
确定性学习算法、无噪声数据、唯一解:学习曲线呈幂律衰减,指数由某个常数决定。
-
确定性学习算法、无噪声数据、多个等价解:每加入一个新数据点,学习会更快,因为模型只需要学习最优参数流形,而不是寻找单一解点。
-
确定性学习算法、有噪声数据:数据噪声让学习更困难,衰减变慢。
-
随机学习算法、有噪声数据:存在一个不可约损失,这是随机学习器无法继续降低的残余误差,比如模型在大数据上容量耗尽时。
所有四类学习曲线都遵循幂律形式,其中 L0 可以为 0。虽然它们的理论设定基于简化的二分类任务,但为后续构建经验性的学习曲线预测模型指明了方向。
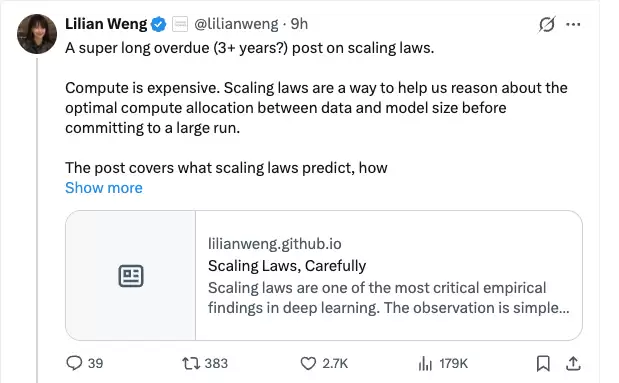
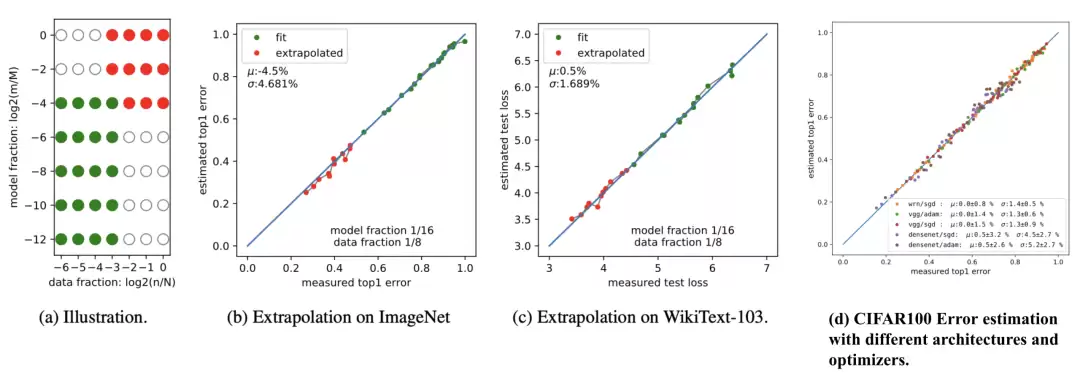
Hestness et al. (2017) 是早期经验研究中的标杆。他们在四个不同领域(神经机器翻译、图像分类、语言建模和语音识别)都观察到一个重复出现的模式:泛化误差会在一组因素上按幂律缩放,比如数据规模;模型改进会平移误差曲线,但不会影响幂律指数;有意思的是,架构会改变幂律拟合的偏移项,但不会改变指数——幂律斜率看起来更像是问题领域的性质,而不是模型架构的性质;拟合给定数据集规模所需的模型参数量也按幂律缩放。
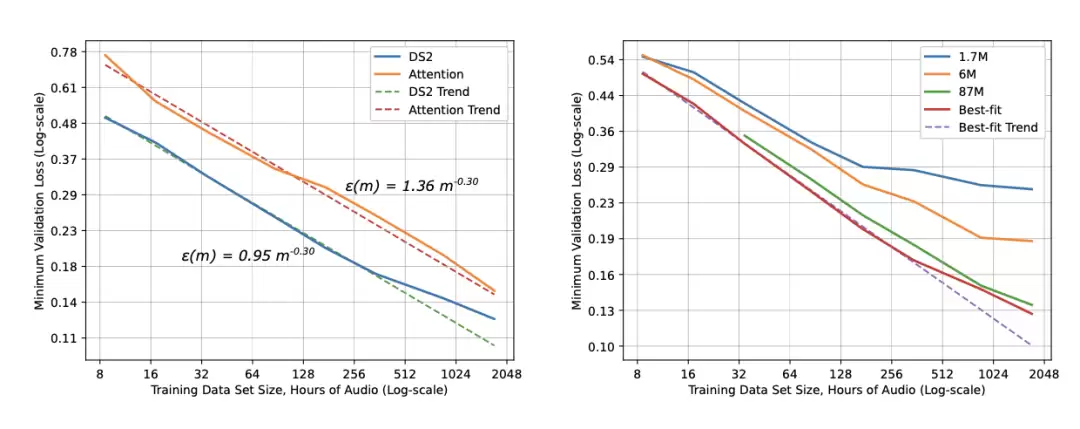
一张概念图把学习曲线拆成了三个阶段。在小数据区域,学习信号不足,模型表现只比随机猜测略好。中间是“幂律区域”,可以观察到损失、数据和模型规模之间的幂律关系。最后是不可约误差区域,这可以归因于数据噪声等因素。
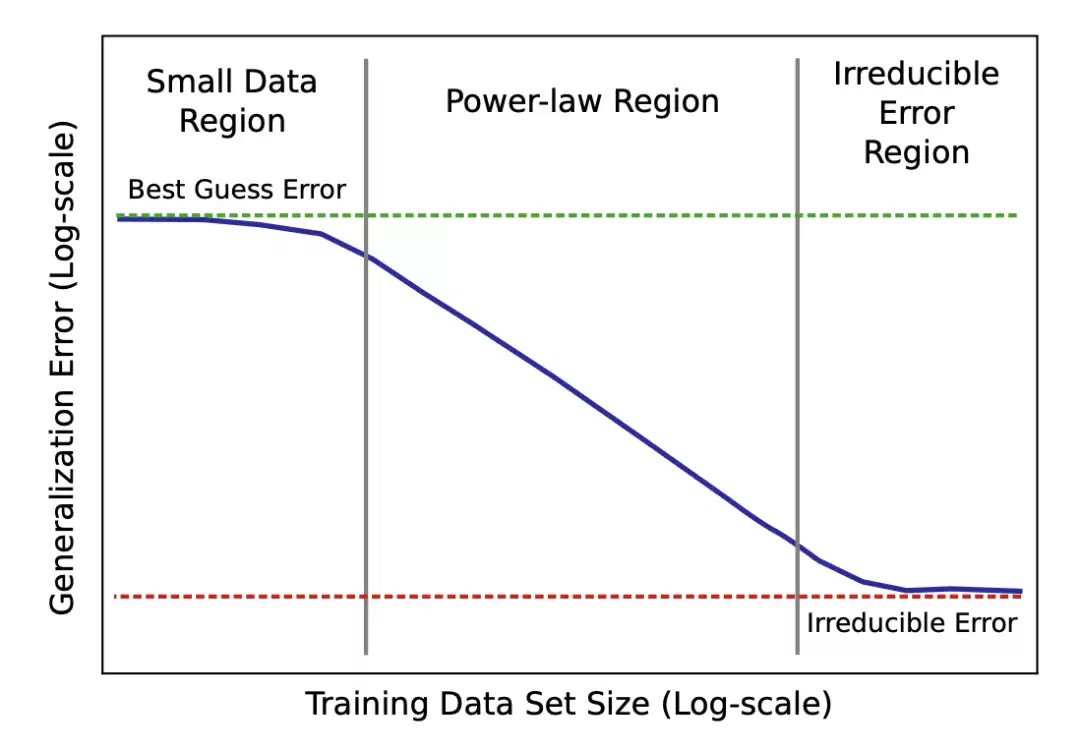
Rosenfeld et al. (2020) 又往前推了一步,尝试把误差建模为模型规模 N 和数据规模 D 的联合函数,覆盖了多种架构和优化器。他们在经验上观察到,固定其中一个轴时,误差会沿另一个轴按幂律衰减。这表明存在一个简单参数函数形式的预测模型,只需要在一组较小训练配置上训练,便能预测超过某些阈值后的预期损失。
旁注:这些早期工作依赖经典学习理论直觉,比如 VC 维。但在现代深度学习工作中,VC 维往往过于粗糙,经验幂律比理论提供的最坏情况边界更清晰,也更实用。
数据无限区域中的缩放定律
Kaplan et al. 的缩放定律
Kaplan et al. (2020) 在语言建模社区中真正普及了缩放定律。他们发现,交叉熵测试损失会分别随着模型规模、数据集规模和训练计算量按幂律缩放,跨度达到多个数量级。这个发现和早期工作一致,但 Kaplan 等人把概念形式化,并聚焦于 Transformer 语言模型和更大规模的经验实验:模型规模从 768M 到 1.5B 非 embedding 参数,数据集规模从 22M 到 23B token。
关键发现包括:损失会随着 N、D 和 C 分别按幂律缩放,为了获得最优性能,三者必须一起缩放;训练曲线遵循可预测的幂律,其参数大致独立于模型规模;更大的模型样本效率更高;架构细节没有纯粹规模那么重要;训练损失和测试损失正相关——听起来很显然,但这正是预训练工作的基础;在固定计算预算时,训练一个非常大的模型并在收敛前停止,比把一个较小模型训练到完全收敛更高效——这个结论后来被 Chinchilla 推翻了。
他们用一个方程总结了 N 和 D 的联合依赖关系。这个形式的好处是,过拟合程度主要取决于 N 和 D 的比值。它表明,为了避免训练受数据限制,数据需要按模型规模增长的某个特定比例一起增长。
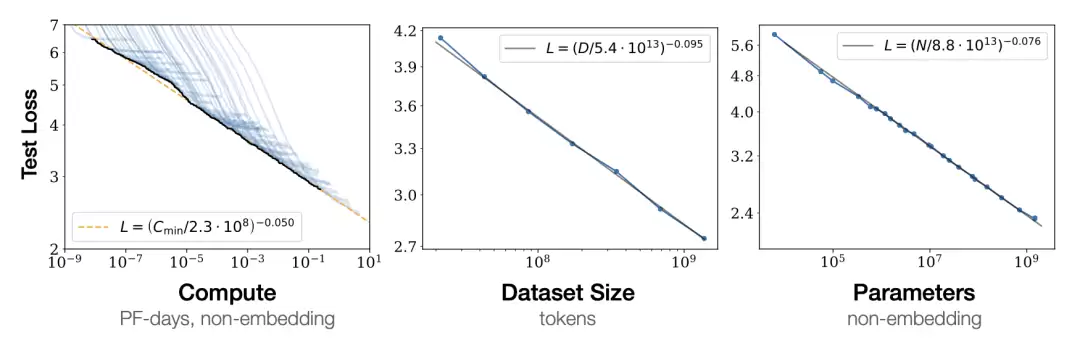
最有影响、事后看来也最有争议的结论,是 compute-optimal allocation。Kaplan 等人发现,当计算量增加 10 倍时,他们建议模型规模扩大约 5.5 倍,而训练 token 只增加约 1.8 倍。后来的 Chinchilla 论文推翻了这一建议,认为这会让大模型严重训练不足。
Kaplan 等人的另一个有用分析,是根据 N 和 D 近似计算所需训练 FLOPs。
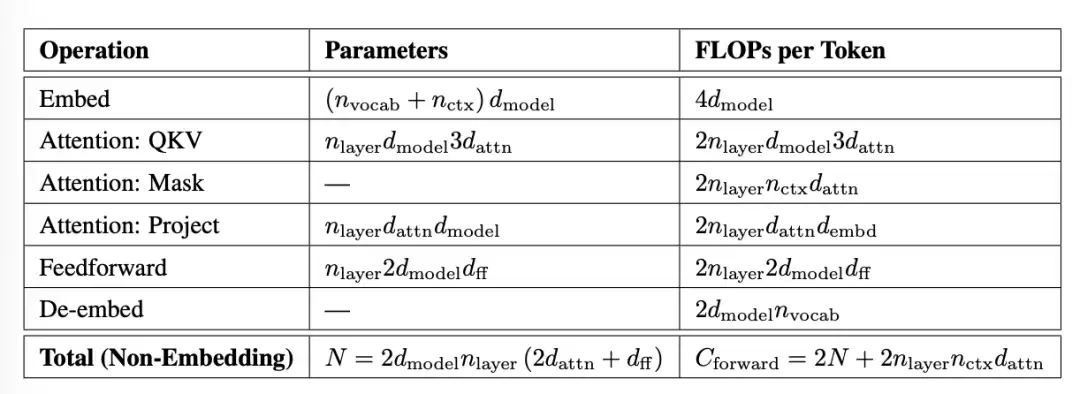
给定一个标准配置,从 N 和每 token 前向计算中排除 embedding 层,反向传播 FLOPs 约是前向传播的两倍,因此总体上每 token 训练 FLOPs 约为 6N,在 D 个 token 上训练的总 FLOPs 约为 6ND。
Chinchilla 缩放定律
Chinchilla 论文(Hoffmann et al. 2022)研究了固定计算预算 C 下,最优模型规模 N 和 token 数 D 之间的关系。它使用了更谨慎的实验设计,得出了一个与 Kaplan 等人不同的答案。

核心问题是:给定 FLOPs 有限,我们应该如何在更多数据 token 和更多模型参数之间做选择?Chinchilla 论文给出了三种设计得很整齐的缩放定律拟合方法。经验实验扫描了 400 多个模型,规模从 70M 到超过 16B 参数,训练 token 从 5B 到 500B。实验假设每个训练 token 都是唯一的,即数据无限区域。
方法 1:固定模型规模,改变 token 预算
对每个参数量 N,用不同 token 预算训练多次,记录每个 FLOP 预算下达到的最小损失。
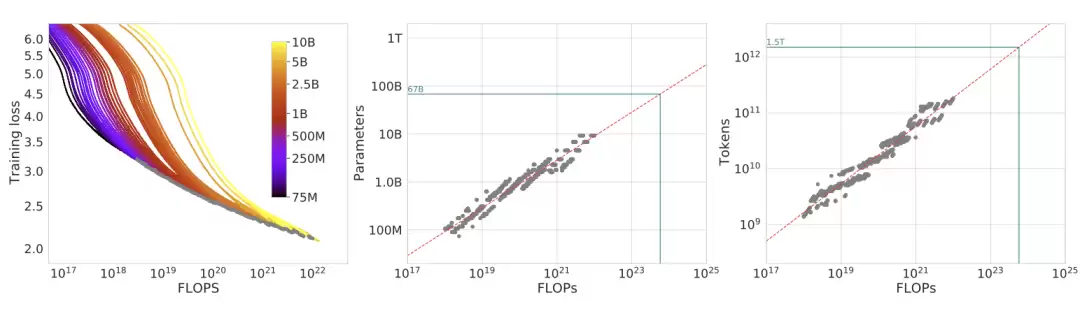
方法 2:IsoFLOP profiles
固定一个计算预算 C,绘制最终损失相对于参数量 N 的曲线。每条 iso-FLOP 曲线在 log 空间里大致是一条抛物线,其最低点标记了该计算预算下的最优模型规模。重复这一过程,就能在图中描出一条幂律线。
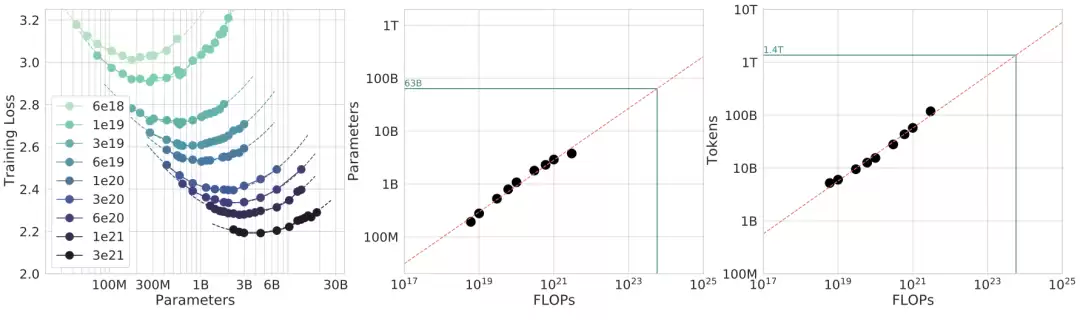
方法 3:参数化拟合
直接拟合 Rosenfeld et al. (2020) 中的同一个参数函数,在约束 C ≈ 6ND 下最小化 L(N, D),可以得到最优 Nopt(C) 的闭式近似。Chinchilla 通过三种互补方法得到答案,最终结果彼此一致——这也是它的结论相当有说服力的一部分原因。
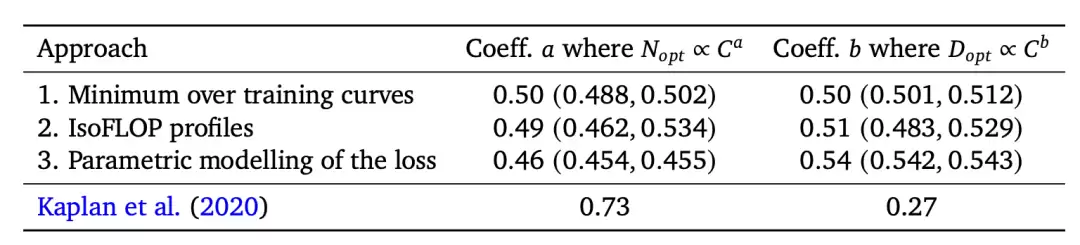
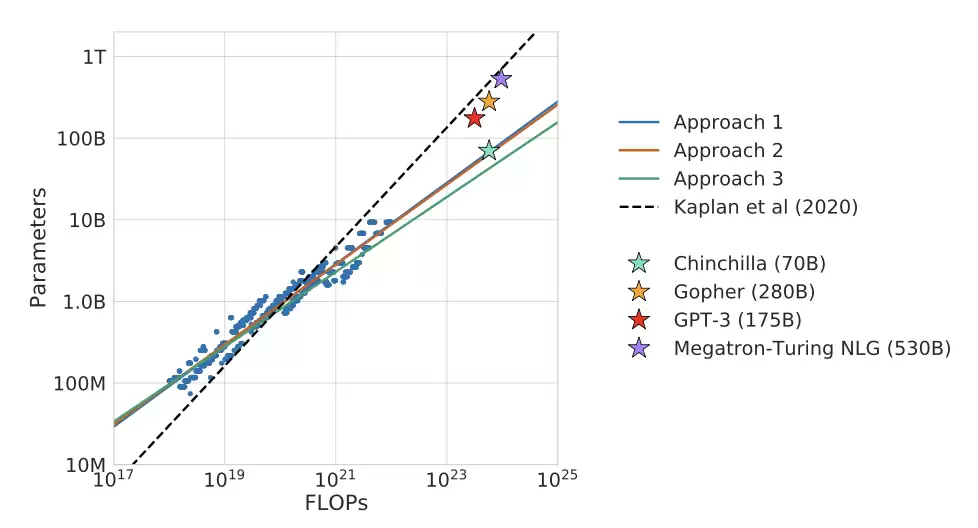
Chinchilla 论文中“当时多数大模型训练不足”的主张,由一个著名演示支持:在与 Gopher 相同的计算预算下,他们训练了 Chinchilla(70B 参数、1.4T token 预算)。这个模型比 Gopher 小 4 倍左右,但训练 token 大约多 4 倍,并且在各项评估中全面超过 Gopher。
调和 Kaplan 与 Chinchilla
两篇论文的分歧很明确:Kaplan 等人认为“模型增长快于数据”;Chinchilla 认为,每当模型规模翻倍,训练 token 数也应该翻倍。为什么分歧这么大?
差异 1:Kaplan et al. 主要在小模型上实验。他们在 log-log 空间中外推时,拟合中的一个小差异可能导致预测上的巨大差异。
差异 2:embedding 参数量对小模型很重要。在小参数区域,是否计入 embedding 很重要。Kaplan 等人排除了 embedding,而 Chinchilla 包含了 total embedding。为了连接二者,Pearce & Song (2024) 拟合了总参数和非 embedding 参数之间的关系,结果表明局部幂律指数会随模型规模变化,并收敛到 Chinchilla 的估计。
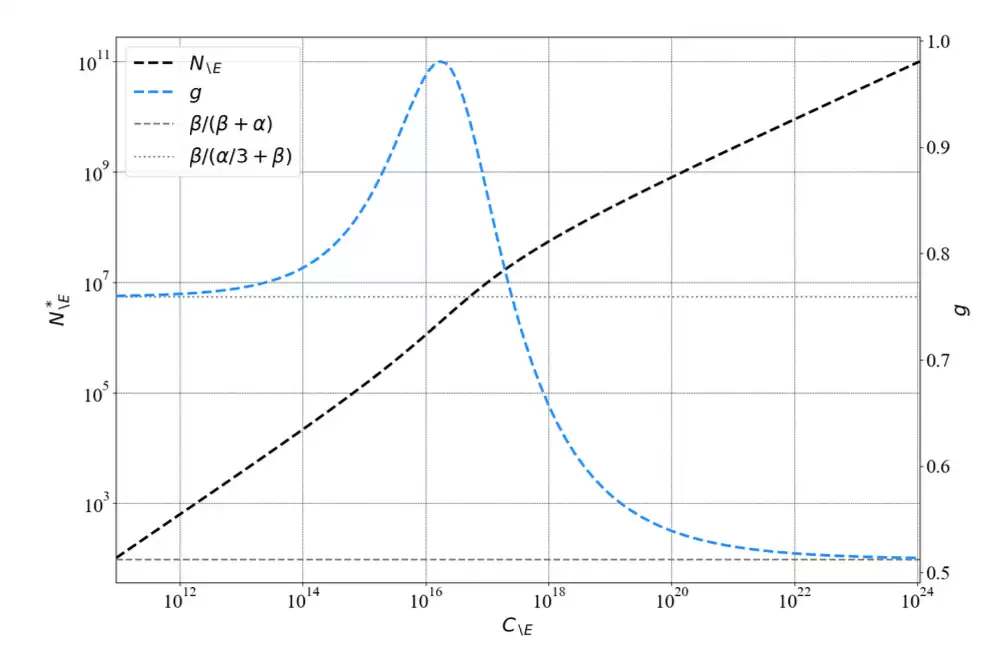
为什么是幂律?
幂律在 AI 之外很多领域都被广泛观察到,比如 Zipf 定律、无标度网络、城市缩放定律。规模和频率之间的关系在 log-log 尺度上通常接近一条直线。为什么 LLM 缩放定律也呈现幂律形状?
一个早期解释假设,语言建模可以被看作是在数据低维流形上做回归。更多模型参数可以诱导出对数据流形更细的划分,从而获得更小泛化误差。后来的假设认为,知识或技能是以离散块的方式被学习的,并且这些技能的频率分布遵循幂律。模型先学习常见技能,再学习稀有技能,从而使损失平滑地按幂律下降。
数据受限区域中的缩放定律
经典缩放定律假设无限的唯一数据。随着模型规模增长,我们正在耗尽高质量唯一 token。一些关于 AI 缩放还能持续多久的争论,核心就是是否正在撞上“数据墙”。
Hernandez et al. (2022) 的研究聚焦于一个受控版本:一个大部分唯一、但含少量重复数据的数据集。他们观察到双下降现象:随着重复数据被强调得越来越多,测试损失可能先变差,然后又变好。
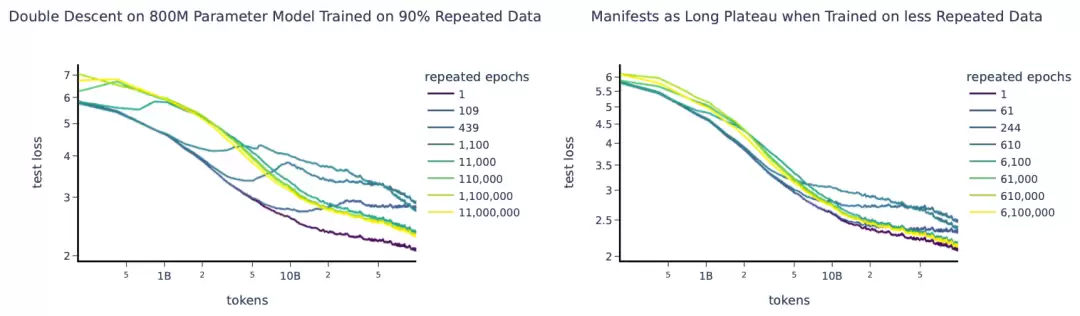
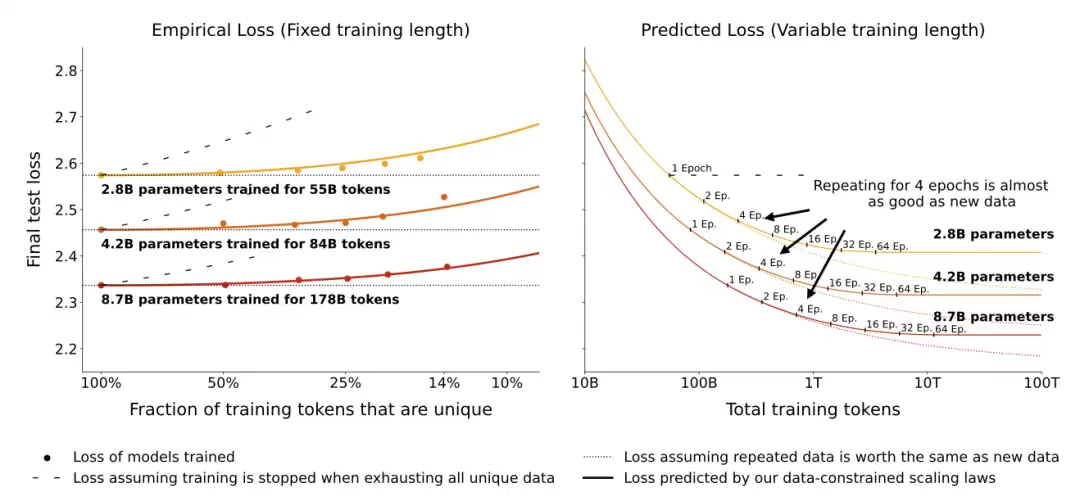
Muennighoff et al. (2023) 研究的是,当模型训练受到数据约束时,计算应该如何最优分配。关键建模调整,是把总 token 数拆成两部分:唯一 token 数和重复次数。他们发现,超额参数的价值衰减速度快于重复数据,因此应该把更多资源分配到更多 epoch,而不是更多模型参数。
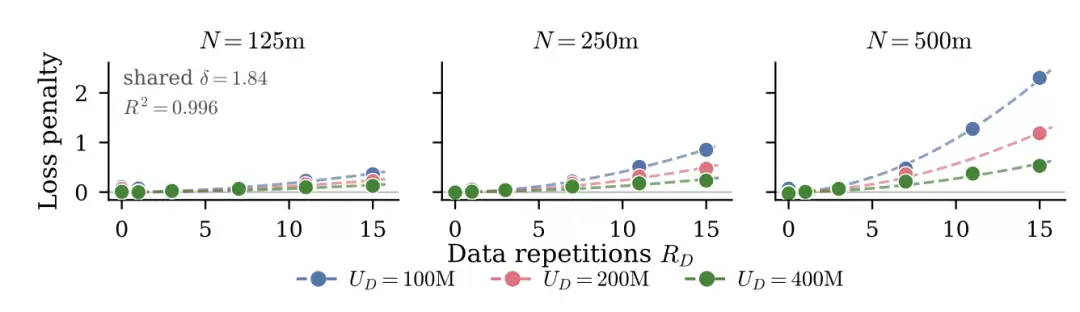
最近,Lovelace et al. (2026) 用不同方法重新审视了这个问题。他们不再把过参数化建模为有效模型规模的收益递减,而是显式建模模型规模和数据重复之间的相互作用。在固定模型规模下,更多 epoch 会造成更多伤害,而且更大的模型对重复更敏感。
现实中拟合缩放定律的棘手之处
尽管缩放定律形式干净,但在实践中,拟合缩放定律可能会对看似琐碎的流程选择出乎意料地敏感。原因在于,我们只能在小模型上拟合,然后外推到大几个数量级的模型上。看起来像舍入误差的选择,可能导致预测中的巨大差异。
Kaplan 和 Chinchilla 之间的分歧,就是展示缩放定律拟合棘手之处的一个绝佳例子。另一个例子来自 Besiroglu et al. (2024),他们发现 Chinchilla 方法 3 的拟合存在几个具体问题:L-BFGS-B 优化器中的损失尺度过高,导致过早终止;以及参数四舍五入到 2 位精度,让推导出的指数看起来偏差更大。
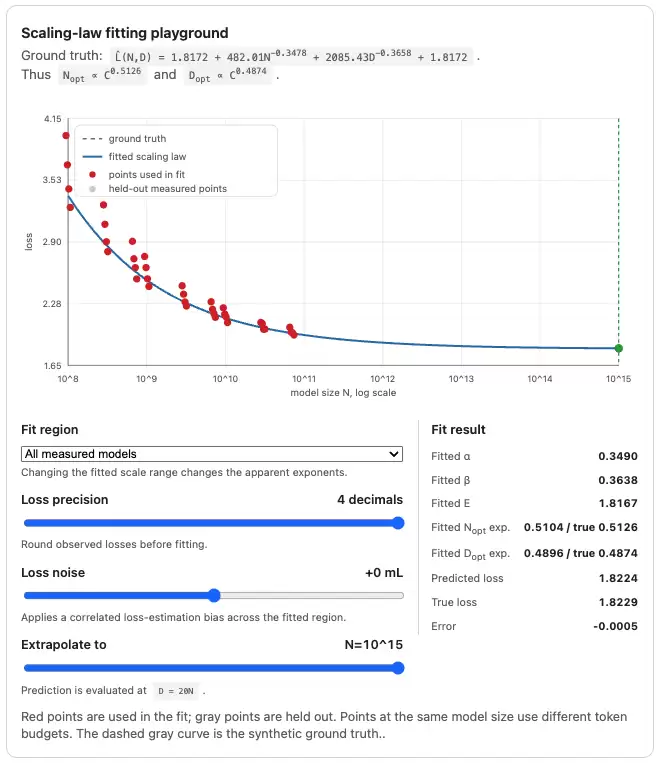
Toy simulation
下面是一个 toy simulation,用来展示三种具体失败模式:损失精度、损失噪声和拟合区域敏感性。通过交互式图,可以直观感受这些因素如何影响最终拟合结果。
引用
请这样引用本文:
Weng, Lilian. "Scaling Laws, Carefully". Lil'Log (Jun 2026). https://lilianweng.github.io/posts/2026-06-24-scaling-laws/
或者使用 BibTex 引用:
@article{weng2026scaling,
title = {Scaling Laws, Carefully},
author = {Weng, Lilian},
journal = {lilianweng.github.io},
year = {2026},
month = {June},
url = "https://lilianweng.github.io/posts/2026-06-24-scaling-laws/"
}
参考文献
[1] S. Amari, N. Fujita, and S. Shinomoto. “Four Types of Learning Curves. Neural Computation.” 4(4):605-618, 1992.
[2] Hestness et al. “Deep Learning Scaling is Predictable, Empirically.” arXiv preprint arXiv:1712.00409, 2017.
[3] Rosenfeld et al. “A Constructive Prediction of the Generalization Error Across Scales.” ICLR 2020.
[4] Kaplan et al. “Scaling Laws for Neural Language Models.” arXiv preprint arXiv:2001.08361, 2020.
[5] Hoffmann et al. “Training Compute-Optimal Large Language Models.” NeurIPS 2022.
[6] Pearce and Song. “Reconciling Kaplan and Chinchilla Scaling Laws.” TMLR 2024.
[7] Bahri et al. “Explaining Neural Scaling Laws.” arXiv preprint arXiv:2102.06701, 2021.
[8] Sharma and Kaplan. “A Neural Scaling Law from the Dimension of the Data Manifold.” arXiv preprint arXiv:2004.10802, 2020.
[9] Hernandez et al. “Scaling Laws and Interpretability of Learning from Repeated Data.” arXiv preprint arXiv:2205.10487, 2022.
[10] Muennighoff et al. “Scaling Data-Constrained Language Models.” NeurIPS 2023.
[11] Lovelace et al. “Prescriptive Scaling Laws for Data Constrained Training.” arXiv preprint arXiv:2605.01640, 2026.
[12] Besiroglu et al. “Chinchilla Scaling: A Replication Attempt.” arXiv preprint arXiv:2404.10102, 2024.
[13] Michaud et al. “The Quantization Model of Neural Scaling” NeurIPS 2023.
[14] Brill. “Neural Scaling Laws Rooted in the Data Distribution.” arXiv preprint arXiv:2412.07942, 2024.
[15] Rae et al. “Scaling Language Models: Methods, Analysis & Insights from Training Gopher.” arXiv preprint arXiv:2112.11446, 2021.
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:翁荔最新万字长文:大模型Scaling Laws需谨慎理解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点美国、欧盟和英国将于9月5日签署全球首部具有法律约束力的人工智能国际条约。公约要求签署国对AI造成的任何有害和歧视性后果负责,确保产出尊重平等权与隐私权,并赋予受害者法律追索权。但条约缺乏罚款等实质性制裁,执行效果依赖各国国内法律配合。
将YouTube视频语音转化为文字稿,并集成ChatGPT或Claude进行AI分析,支持自定义提问以总结核心观点、提取术语或复述复杂段落。该浏览器插件使视频学习从被动接收变为主动交互,大幅提升信息提取效率。
OpenAI计划推出“草莓”和“猎户座”大模型,月费高达2000美元。高昂定价源于公司累计投入超100亿美元,同时新产品推理能力大幅升级,具备AIAgent功能。现有企业用户超100万,月活达2亿,用户基础为高价提供了支撑。
基于AI的音频转录与洞察平台,自动将录音转为文字并提取结构化见解,可用于会议、采访等场景。核心功能包括准确转录和关键信息挖掘,帮助用户从对话中提炼实用知识,节省回听和整理时间。
- 日榜
- 周榜
- 月榜
热点快看