




大模型开发工作手册从入门到精通指南

大模型基础能力快速迭代,但应用落地困难,主要因开发成本高、效果不稳定。需降低技术门槛,让领域专家参与研发。通过构建模型研发框架与MultiAgent系统,实现用户只需明确需求、提供数据即可完成应用开发,推动能力领域化。
先说几个核心判断。大模型爆发两年了,基础能力的迭代速度大家有目共睹。从去年9月OpenAI的“O1”模型到多模态领域的持续突破,技术红利确实够猛。但一个很尴尬的现实是:我们眼看着模型的“智商”越来越高,能用好它的应用却寥寥无几。无论是“领域模型”、“AI原生应用”还是“AI-Agent”,概念热度轮番上阵,但真正让人眼前一亮、人人可用的产品,似乎还在路上。问题到底出在哪?
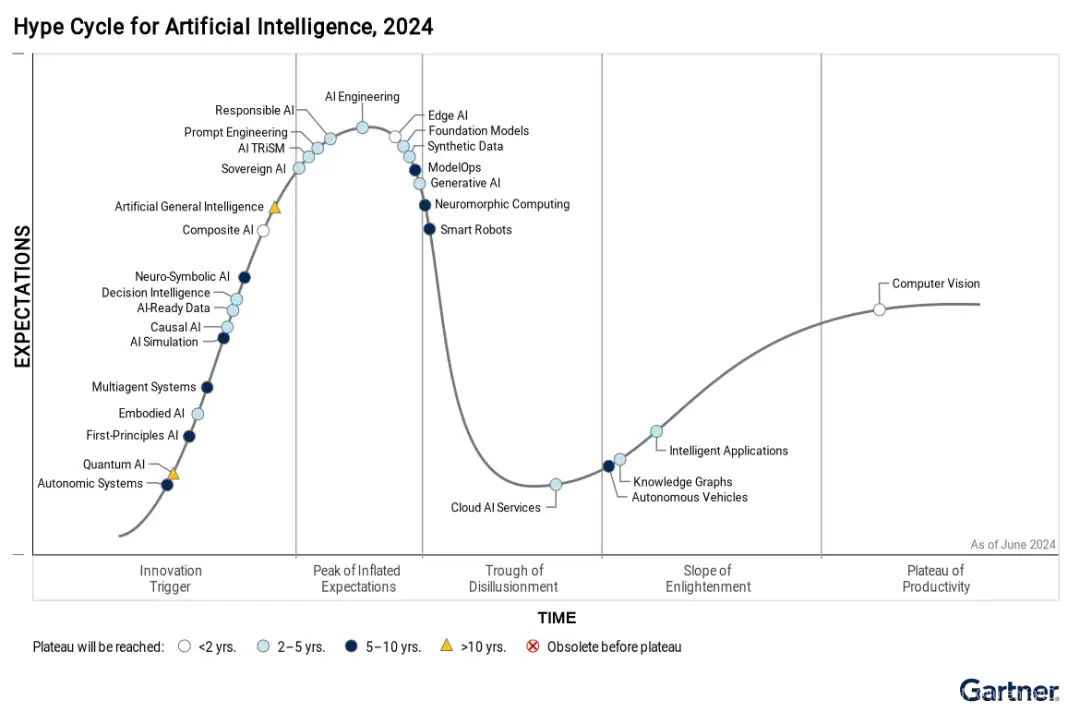
我们不妨看看“2024 Gartner AI 技术成熟度曲线”。一个值得注意的信号是:“Generative AI”(也就是今天我们讨论的大模型底层技术)已经走到了“期望膨胀期”和“泡沫破裂期”的交界点。这个位置很敏感,它意味着前期的野蛮生长积累了不少水分,接下来相当一部分“伪创新”会被清洗掉,只有真正有根基的东西才能存活下来。从这个角度看,“AI应用”的爆发可能还没到火候——在曲线里,应用层的大规模落地通常出现在“稳步爬升”阶段,这在PC互联网和移动互联网的发展史上都有迹可循。
但问题在于,我们明明已经感受到了大模型的强大,有时候甚至觉得它无所不能,为什么到了具体落地的时候就变得“水土不服”?同样在那张趋势图里,我们能看到一些与“应用”直接相关的技术节点:“AI Engineering”、“Model Ops”、“Prompt Engineering”处于发展期;“Multiagent Systems”、“Decision Intelligence”这些还在萌芽期。这些技术恰恰是决定模型能否被“用好”的关键。最典型的例子是“Prompt Engineering”,几乎和大模型同时诞生的概念,到今天依然处于早期探索阶段。而最近大火的“Multiagent System”,在2023年就被认为是未来技术,可直到现在也没真正成熟起来。
把这些碎片拼在一起,结论就很清晰了:应用侧的技术短板,直接捆住了大模型的手脚。业内有这样一种声音一直在流传:“模型的效果底层取决于基础能力,在模型还在高速进化的时候,别急着在应用层下太多功夫,说不定一次模型升级,你之前做的全白费了。”这个观点有其逻辑,但站在今天的视角看,模型基础能力的迭代速度已经在放慢了,而市场对应用的渴望却在升温。所以,想做出真正落地的模型应用,必须把重心从“等模型变强”转向“主动建设应用技术”。
那么,回到具体问题:应用侧的技术不成熟,到底怎么阻碍了我们?我们要做些什么来破解这个僵局?
1.2. 什么阻碍了模型应用?
我们可以把前文提到的应用层能力画成两张图:一类是帮开发者“做好”模型能力,另一类是帮模型“用好”它的能力。
研发与部署:AI Engineering、Model Ops、Prompt Engineering
效果提升:Agent、MultiAgent Systems(综合行为能力)、Decision Intelligence(推理能力)、AI-Ready Data(数据能力)
这其实就是模型在落地时面对的两大核心痛点:开发成本高,应用效果差。
1.2.1. 模型研发成本高昂
首先得说清楚,我们讨论的“模型应用”不是那种随便聊两句天的场景。如果只是用来写个文案、答个疑,今天的大模型确实够用。但一旦你要把它嵌入到实际工作流里,稳定性、准确性、可控性这些“对齐”问题就会像潮水一样涌过来。
为了搞定这些,市面上已经有了不少技术手段:
- Prompt工程:通过优化输入,影响输出质量。
- 模型训练:通过喂数据,调整模型参数。
- RAG & 知识库:给模型装上“外设”,弥补知识短板。
- Agent系统:扩展模型的能力边界,让它能调用工具、调度多模型。
每一种技术都用门槛。哪怕是最“平易近人”的Prompt工程,如今也积累了大量技巧,还分不同模型之间的差异——单是弄清楚这些,对非技术背景的人来说就够呛了。
更麻烦的是,即便你是个初级开发者,掌握了一两种技术(比如能写好Prompt),也很难独立构建一个完整的模型应用。因为整个流程不是单一模块的事,它涉及数据、算法、工程三大领域,从“数据准备”、“标注”、“问题建模”,到“能力研发”、“效果评测”、“模型调试”、“上线部署”、“迭代优化”,这是一个系统工程。说句不好听的,人人都能和大模型聊得火热,但并不是人人都能真正驱动它干活。
1.2.2. 模型效果优化困难
抛开开发成本,模型本身的效果也是个大难题。即便基础能力一季一更新,大模型依然有几个根深蒂固的“死xue”:
- 知识不足:模型不等于知识库。面对高时效性、专业领域或业务相关的知识,它很容易“露怯”。
- 推理能力不足:绝大多数模型在数理逻辑上表现不佳。即便是O1发布之后,推理能力依然是大模型最需要补的课之一。
- 稳定性不足:“幻觉”虽然少了很多,但“不稳定性”依然是影响模型可控性的头号难题。
针对这些痛点,行业里也有了一些应对策略:RAG已经成了解决“知识不足”的共识。Hidden COT(也就是O1采用的技术)通过逐步拆解问题、自检修正,显著提升了推理能力。Agent & MultiAgent则是对模型的“能力边界”进行拓展,让它能做规划、会执行、懂协作。但这些技术本身也还在萌芽期,没有完全固化。换句话说,即便你的模型再强,如果不用好这些中间技术,落地效果也很难让人满意。
1.3. 模型应用研发的痛点
把上面的问题总结一下:成本高、效果差、技术挑战大。这让大模型的能力从“通用”倒逼成了“定制”,开发模式也变成了集中化的闭源模式。这不是一两个模块能解决的,而是需要从整个研发流程去做优化。
市场上现有的工具,比如Prompt工具、模型训练工具、调度工具,确实降低了单个环节的成本。但光靠这些还不够——因为它们面向的还是开发者,专业壁垒依然存在。想让更多人用起来,首先要降低的是整个研发流程的成本,而不是只盯着某一个环节。
尤其是对于大模型的领域化应用来说,依赖算法工程师集中构建能力,既和通用化的大趋势相悖,也满足不了行业需求。只有让真正懂业务的人——那些领域的专家——自己也能上手开发,搭建一个类似开源的能力生态,才能实现真正的“能力领域化”。
二、让人人都能开发大模型应用
我们想要解决的问题,总结起来一句话:让人人都能低门槛、高效率地把大模型用起来。
过去一年多,我一直在探索大模型与“质效”领域的结合。我们在“测试用例”、“缺陷”、“需求”、“代码”等多个场景里做了不少尝试,有些已经在业务中落地,也取得了成效。但撞上的墙也很真实:
- 研发效率跟不上领域需求:质效领域贯穿产品研发全周期,光“测试用例”相关的能力点就能拆出上百个。而且业务定制化严重,复用率低。当时一个模型能力从研发到落地,需要1个人月,和业务诉求差距太大。
- 研发人员掌握不了领域专业:质效的每个模块都积攒了大量专业知识和专家经验,模型研发人员很难完全吃透。而且大多数领域缺乏现成标注数据,研发极度依赖开发者的专业能力,非领域人员很难搞定。
- 协作模式低效:领域专家有知识,但算法研发有壁垒,两套话语体系隔着一道墙。
这些问题不是“质效”领域的专利,很多模型应用的场景都存在类似的困境。因此,我们的目标很明确:降低模型应用的研发成本,打破专业壁垒,让领域内的人也能自主完成模型能力的建设。
目标:让人人都能完成大模型应用
“人人”:指的是对大模型(AI)不了解的领域专家
“完成”:低成本满足自己的诉求,获得稳定的效果
“大模型应用”:能在实际场景中真正落地,产生价值
三、大模型研发框架
为了达到这个目标,我们打算打造一个模型应用的研发工具。和市面上那些面向技术人员的框架不同,我们希望这个工具能通过大模型能力本身,对整体研发流程进行重构。用户不需要懂底层技术,只需要处理“任务”维度的信息,就能完成研发。
这个方向有点像2024百度世界大会上发布的“秒哒”——一个不用写代码,输入自然语言或PRD就能生成应用的平台。我们想做的,是对模型能力本身做一套“MultiAgent”系统,用户只需简单输入,就能自动生成一个可靠的模型应用。
与现有工具的差异:
- 面向所有人:不要求你有技术背景。
- 本身就是一个多智能体系统:系统内部有多个Agent,分别负责研发各个环节。
- 作用于全流程:不是单一模块的增效工具,而是从目标出发,贯穿整个研发链条。
3.1. 从 “Prompt工程” 到 “模型研发框架”
坦率讲,最初我们也和很多人一样,只想做一个Prompt优化工具。毕竟Prompt是影响模型效果最直接、最立竿见影的变量。在早期探索里,我花了大量时间研究Prompt框架,想着怎么把它结构化、工程化、甚至自动生成。
事实上,这个赛道已经非常拥挤:
算法层面:APE、APO、OPRO
技术框架:DSPy(斯坦福的自动Prompt优化框架)
产品层面:阿里百炼的Prompt优化、PromptPerfect、百度ModelBuilder
这些工具确实能帮上大忙——它们懂不同模型的特点,善于运用各种技巧,还能结合数据做自动优化。对于非专家来说,这已经很贴心了。
但再往下想一步,Prompt工程再强,它也只是“技巧”,不是模型研发的“第一性”。在很多场景下,人们甚至会纠结“到底该优化Prompt,还是该训练模型”。我们认为,基于当前大模型的能力,模型研发的“第一性”应该是“提升应用效果”。用户不需要知道背后有多少技巧,他需要的是一个能帮他把效果提起来、把问题查清楚、把模型用起来的完整工具。所以,与其做一个“Prompt编辑器”,不如去做一个“模型研发流程平台”。
围绕这个目标,我们关注的几个关键问题变成了:
- 如何评估效果?
- 如何排查问题(debug)?
- 如何优化模型(能力不够怎么办)?
- 如何把模型真正用到工作中?
这些问题没有一个指向单一模块,而是指向了全流程。所以,我们最终把赌注押在了研发流程的工具化上。
3.2. 模型研发流程
简单来说,我们想用AI帮用户完成研发过程中那些费力的事。要讲清楚这件事,得先拆解一下现在一个模型应用是怎么“造”出来的:
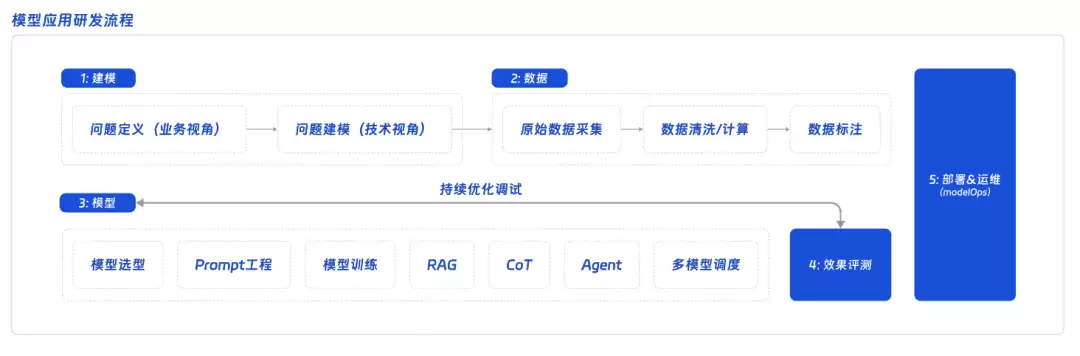
- 建模:定义清楚“模型要帮我做什么”。这一步很像写需求文档,要先把问题翻译成技术语言,明确输入和输出的形式。这一步常常被忽视,但它对后续研发至关重要。
- 数据:数据是模型的“燃料”。准备数据最难的一环是标注——很多时候只有输入,没有输出。现在已经很流行用AI来做粗标,再人工确认。
- 模型:这是研发工作的核心,包括:
- 模型选型(根据任务选合适的模型)
- Prompt工程(写并调试提示词)
- 其他优化(RAG、训练、CoT等)
- Agent & MultiAgent(复杂任务需要多个智能体协作)
- 效果评测:准备数据,让模型跑一遍,对比结果。量化指标(准确率、召回率等)很重要,但badcase的分析才是优化的关键。
- 持续优化调试:模型上线不是终点,根据badcase迭代才是常态。
- 部署 & 运维:让模型能力融入已有业务系统(API、定时任务、工程化开发)。
为了更直观地解释这个过程,可以举一个我们做过的实际例子:“用例检查”。我们希望用大模型检查“测试用例”中是否存在“二义性”问题——这是导致漏测的典型原因之一。
- 建模:确定“二义性”的定义,并将问题建模为一个“分类任务”(判断用例是否有二义性)。
- 数据:业务有20万+用例,但没有标注。于是我们用GPT-4做了粗标,再人工确认,最终拿到500条标注数据。
- 模型:选择了公司内部私有部署的模型。我们做了多轮Prompt优化,引入了RAG(补充业务专用词解释)、CoT(拆分思维链)、格式限制、反思机制,还把各种限制条件抽象成独立模块,结合模型调度能力,看上去像一套Agent系统。
- 效果评测:多次评测准确率、精确率、召回率,持续分析badcase。
- 部署 & 运维:提供了API接口、定时检查任务,还做了智能用例平台,把检查结果与Tapd(项目管理工具)打通,配合看板推送,推动问题闭环。
3.3. 我们要做什么
通过前面的例子,可以更清楚地看到,我们希望工具在这个流程中扮演什么角色。我们把流程中的环节分为三类:用户全权负责、系统全权负责、两者协同。具体划分如下:
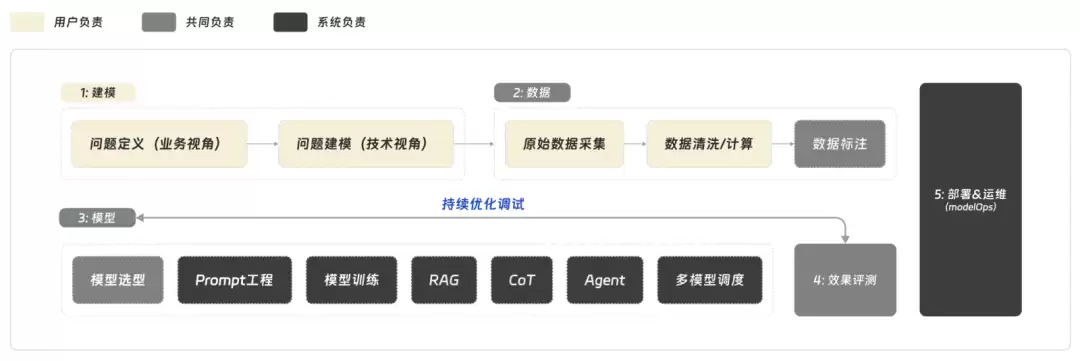
- 建模:
- 问题定义:用户独立负责。你需要想清楚“让模型做什么”。
- 问题建模:用户主导,工具辅助。用户需要把问题翻译成技术语言,工具会通过模板来帮用户规范输出。
- 数据:
- 原始数据采集:用户负责。工具会提供插件(如从Tapd、腾讯文档读数据)降低采集难度。
- 数据清洗/计算:用户为主,工具提供格式解析等辅助。
- 数据标注:用户与工具协同。工具先调用GPT-4或混元等进行“AI粗标”,用户再人工确认,大幅降低成本。
- 模型:
- 这一阶段的所有工作(模型选型、Prompt工程、其他优化)由系统自动处理。用户可以根据需要手动选择模型或进行一定程度的干预。
- 效果评测:系统自动输出评测指标。
- 持续优化调试:半自动化。系统分析badcase并驱动自动优化,同时用户也可以自行提炼规则,用自然语言描述优化目标,系统负责执行。
- 部署 & 运维:系统提供多种方式——API接口、定时任务、智能用例平台一键上线、聊天机器人、Tapd连通看板等。
3.4. 总结
总的来说,我们想做的这个工具本身就是一个MultiAgent系统。用户只需要“明确需求”和“提供数据”,剩下的全交给系统。我们希望借此持续积累领域能力,最终建立起类似开源的研发生态,把模型能力的构建“放权”给领域内的每一个人。
四、构建模型能力的Agent系统
目标清楚了,具体怎么实现?这里挑几个关键模块,从技术角度聊聊。
4.1. 建模
建模是模型调试阶段最核心的信息输入,就像一份需求的蓝图。和前面说的一样,它分两步:问题定义和问题建模。问题定义可以由用户任意发挥,但建模就需要一定的规范——得把任务映射到常见的AI任务类型上。
基础类型:分类、聚类、生成、回归
综合类型:信息抽取、文本总结、问答、关键词抽取
前文提到的“用例检查”,本质就是一个“分类”任务。每种任务类型都有共性,工具就是利用这种共性来封装研发流程的。比如所有分类任务的Prompt结构、评测指标都有相似之处。
为了保证建模质量,工具为每种任务类型都提供了标准模板。以分类任务为例:
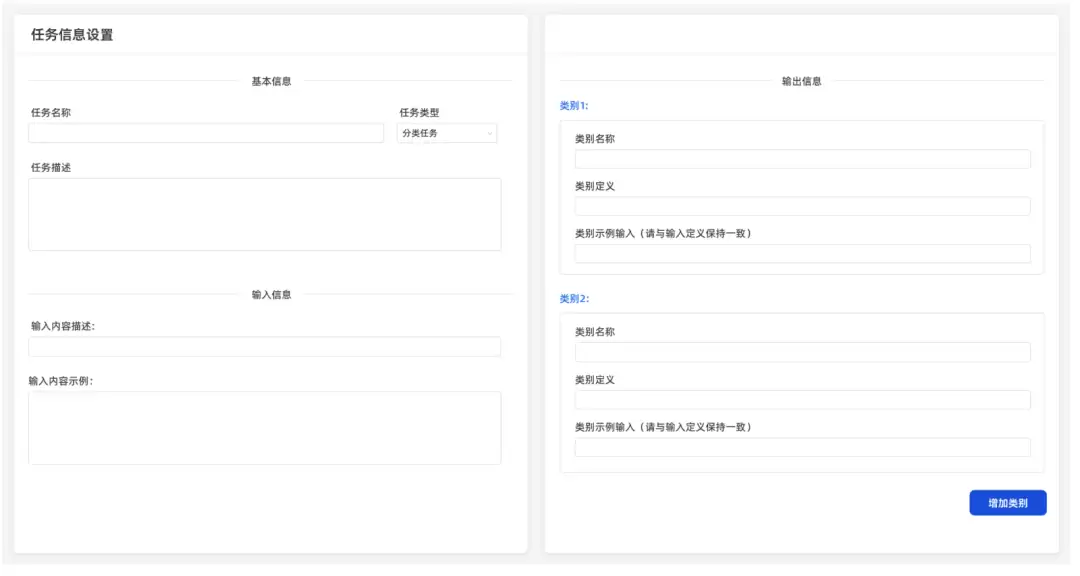
用户需要确认任务类型,填写模板,完成建模。目前这块没有引入智能填写,所以模板填写本身就是一种学习和打磨的过程。不过别担心,用户完全可以先简单填,后期再根据评测结果逐步优化。
4.2. 数据
数据是模型的“粮食”,后续所有调试、训练、评测都离不开它。工具中的所有对象都按任务维度管理,用户在上手调试前,得先上传对应的数据集。
工具对数据格式没有太严格的要求,每种任务类型会有相应的格式规范。但大原则很简单:只需包含模型的“输入-输出”对就好。当然,尽可能覆盖任务的多样性,是保证效果的基石。
前面提到,数据标注常常是个费时费钱的活儿。工具已经集成了“AI标注”能力,先让大型模型(混元、GPT-4)做粗标,再由人工确认。这个做法在业界已经有充分验证:
- S3框架:用大模型缩小小模型在合成数据和真实数据之间的差距,性能提升显著。
- FreeAL框架:大模型与下游小模型协同,实现零人工投入的数据标注。
4.3. 模型
模型效果调试是整个研发流程里成本最高、技术壁垒最厚的部分,也是工具最有价值的部分。理论上,用户只要完成建模和数据准备,工具就能自主完成后续所有工作。
4.3.1. MultiAgent系统
大模型本身是一个语言模型,它能做决策,但不能自主“执行”任务。而Agent是一个更广泛的概念——它是一个能独立做出决策并实际执行的实体。显然,我们需要的不是一个语言模型,而是一群Agent。
我们的工具本身就构建了一个MultiAgent系统,包含6个核心Agent模块:
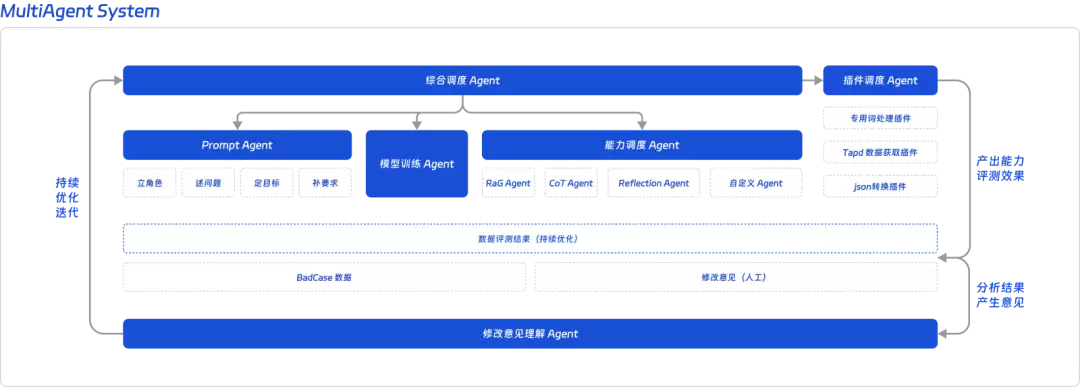
- 综合调度Agent:系统的大脑,负责理解输入、拆解任务、制定计划和调度资源。
- Prompt Agent:负责Prompt的编写、管理和持续优化。
- 模型训练Agent:负责模型训练脚本的调度和流程串联。
- 能力调度Agent:根据实际情况调用各种能力模块,如RAG、CoT、反思等。
- 插件调度Agent:在各个环节调用外部工具(数据获取、格式转换等)。
- 意见理解Agent:解析评测结果和用户反馈,驱动持续优化。
- Decision(决策):分析任务,决定要调用的能力和方式。
- Plan(规划):设计具体实施方案,指导执行。
- Action(执行):完成每个原子任务。
- Result(结果):汇集结果反馈给Decision层。
- 前处理阶段:
- 数据解析(复杂数据预处理)
- 数据格式化
- 异常数据检查
- 模型推理阶段:
- Prompt修改(如RAG插入额外上下文)
- 要求限制(白/黑名单、字数限制等)
- 后处理阶段:
- 结果格式转换(如转为JSON)
- 结果内容转换(如分类标签映射)
- 结果校验(如反思机制)
- BadCase数据:实验和应用中的失败案例是最宝贵的优化资料。
- 规则要求:用户根据经验总结出的具体要求。
- 基础能力升级:底层模型或技术的迭代。
- Agent驱动的半自动方式:用户输入BadCase数据或自然语言规则,Agent会自动分析并形成修改意见,传递给“综合调度Agent”,由它去修改Prompt、调度能力模块。整个过程用户只需要“说一句话”。
- 修改输入的人工方式:用户可以直接修改建模定义、补充数据或扩充知识库(如RAG的知识库),以此来直接影响模型效果。
- 建模框架化:模板式输入,从2天降到1天。
- 辅助数据标注:借助闭源模型粗标+人工确认,从2天降到0.5天。
- Prompt编写:Agent自动完成,从3天降到0.5天。
- 能力调用:RAG、CoT、反思等能力开箱即用,从1周降到1天。
- 插件调用:数据读写、格式转换等插件直接调用,从1天降到1小时。
- 上线部署:一键配置,从3天降到1天。
- 流程串联:规范化流程,从3天降到1天。
- 效果调试&优化:半自动Agent辅助,从1周降到2天。
为了让这些Agent高效协作,我们设计了统一的4层职责框架:
这个四层结构是Agent的最小工作单元,无论是单一模块还是多Agent协作,都依此展开。
4.3.2. Prompt Agent
Prompt Agent负责Prompt的编写,是模型调试中最重要的模块之一。基于我们的应用经验,我们把一个Prompt拆解为“立角色 + 述问题 + 定目标 + 补要求”四个部分,并在此基础上引入统一的研发流程,实现了Prompt的框架化编写。
需要强调的是,一个“任务”可能不止包含一次模型推理,而是由多次推理组成(例如CoT)。每次推理对应自己的Prompt。Prompt Agent不仅会编写单个Prompt,还会对整个任务进行“思维链”拆分,为每个环节生成专有的Prompt。
任务拆分同样由Agent完成,不需要用户介入。Agent会先拆分成多个推理阶段,再逐一编写Prompt,最终生成完整的调度流程。
4.3.3. 能力调度Agent
除了Prompt,额外能力的引入对模型效果影响更大。最具代表性的就是RAG。像这样的技术还在不断发展,且用户可能有定制化的需求。因此,我们将每个能力封装成独立的“子Agent”,通过调度Agent统一管理。
目前,能力调度主要作用于模型推理的三个阶段:
每个能力都是一个Agent,底层结构统一(决策-规划-执行-结果),保障了可扩展性。用户也可以自主定义新的能力模块,将其注入到系统中。
值得一提的是,每一个可复用的“模型应用”本身,也可以成为一个通用外部能力,被用在其他能力上。能力的“自我增长”是工具持续进化的核心动力。
4.4. 调试 & 优化
模型效果的提升不是一蹴而就的。我们有三个主要的优化来源:
在工具中,我们提供了两种调试途径:
即便有这些自动化手段,模型的调试优化依然依赖开发者的经验。如何把这个过程变得更“傻瓜化”,是我们还在持续探索的方向。
五、最佳实践
目前,这套工具的初版已经研发完成,并在实际业务中跑起来了。结合我们在质效领域过去一年多的积累,我们已经用它完成了多项模型能力的落地。结果是:在效果有保障的前提下,效率和成本都有了质的飞跃。
5.1. 研发效率提升最佳实践
5.1.1. 效率低带来的痛点
在过去一年多里,我们完成了8项模型能力的研发落地,覆盖用例、缺陷、代码等场景。但离业务的需求还差得远。仅“用例域”一个领域,检查点就能拆出上百个。而一个模型能力从研发到落地要花1人月,产能和需求的落差太大了。
5.1.2. 实践成效
在一次“用户反馈检查”的任务中,业务方希望模型能识别出反馈内容中的严重问题(如隐私泄露、白屏、消息导入失败等),以便进行特殊监控。这类判断高度依赖人为经验,容易遗漏。
通过工具的引入,我们在2周内完成了2项模型能力的研发(“隐私相关问题”和“白屏相关问题”),并成功部署上线。单项能力的研发成本从“1人月”降到了“1人周”,准确率均保持在80%以上,效率提升了数倍。
5.1.3. 效率提升详情
具体到每个环节,效率提升的“账”是这么算的:
5.2. 研发成本下降最佳实践
5.2.1. 成本高带来的痛点
在探索大模型与质效的结合中,大量工作由算法开发人员承担。但质效领域专业壁垒深、业务耦合度高,开发者和领域专家之间总存在错位。这不仅增加了成本,也拖累了效果。
我们始终认为,大模型的“领域化”不是让算法人员去学领域知识,而是**要让领域人员学会用模型工具**。这才是“授人以渔”。
5.2.2. 实践成效
以“用例域”的“用例检查”为例。我们之前已经完成了6个检查点的建设,但业务积累了200+个检查点。如果靠算法团队持续推进,根本做不过来。
通过工具的引入,我们与业务质量同学合作,没有一名算法开发人员介入,仅由质量同学完成输入,在2周内完成了2项新检查点的研发(“杀进程用例缺失检查”、“写操作用例缺失检查”),准确率均达80%以上。在调试过程中,质量同学只需修改定义或补充数据,就能低成本迭代效果。
5.2.3. 成本降低详情
正如上图所示,工具承担了大量研发工作,用户只需负责:定义检查点、填写建模模板、收集数据。至于标注,系统用混元粗标后再人工确认;模型调试、评测、部署全由工具处理。最终,用户一键就能将能力上线到“智能用例平台”或定时任务中。
通过这种方式,我们真正实现了“让质量人员也能做模型开发”的闭环。
六、写在最后
6.1. 从 “Prompt框架” 到 “模型研发工具”
回看这一年多的探索,我们其实走过一段弯路。很长一段时间里,我们都坚信Prompt是模型应用的万能钥匙——只要把Prompt写好,一切问题都解决了。但随着对Agent、MultiAgent等技术的深入体验,我们越来越意识到,Prompt只是众多应用技术中的一环。
把目光从“一个环节”扩大到“整个流程”,我们看到了模型研发的“第一性”——就是“提升应用效果”。不管用什么手段,只要能把这个效果提起来,就是好方法。所以,我们不再执着于做最完美的Prompt编辑器,而是选择了做最完整的研发流程工具。
6.2. 总结 & 后续规划
目前,工具已经初步就位,也跑通了几个案例。但这才只是开始。大模型被视为通向AGI的阶梯,但现有的开发模式却在不断削弱模型的“通用性”以换取领域内的稳定性。这种偏闭源的开发方式不符合趋势。
我们希望,通过这个工具,能让更多人参与到模型能力的构建中来。只有让懂业务的人拥有模型能力,才是真正的“领域化”。技术上,本文开头提到的那些趋势曲线不一定全对,但有一点是确定的:应用层技术的发展,会在模型落地中占据越来越高的权重。
前面说的每一段观点,都只是个人经验的阶段性总结。大模型技术还在飞速前进,非常期待和大家持续交流。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:大模型开发工作手册从入门到精通指南要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点LucidaAI是一款面向企业的AI英语口语教练,通过实时对话提供发音、语法、词汇和流利度的个性化反馈。采用端到端加密并支持合规定制,定价策略注重普及化,旨在以低成本提升团队英语沟通能力。
Screenshot2Code工具能够从截图中自动识别代码,并将其转换为可直接运行的代码。支持Python、HTML及API接口信息提取,帮助开发者快速复用他人分享的代码片段,从而显著提升工作效率。这个工具极大简化了代码复用过程。
SpeakStruct通过可自定义模板将语音转换为结构化数据,适用于会议记录、客户通话等场景。核心功能包括自定义模板、准确转录和随处捕捉,使口语信息直接转化为可用的数据资产。
IzzyAI是一款AI驱动的语音治疗应用,提供全天候服务。通过智能治疗师头像互动,系统评估并治疗五种常见语音语言障碍,融合语音与面部识别技术给予实时反馈。内置综合评估、个性化练习、进展报告及支持性社区,提升治疗效果。
- 日榜
- 周榜
- 月榜
热点快看