




金融NER大模型性能与视觉文档理解技术总结

一、视觉文档理解技术总结 近期阅读到一篇极具参考价值的综述文章,系统化地梳理了文档视觉问答模型在架构上的演进脉络,值得向各位推荐分享。 视觉丰富文档(VRDs)之所以特殊,在于其并非单纯的文字堆砌——文本与图形、图表、表格等视觉元素相互交织,共同完成信息的传递。相较于传统文本文档,VRDs具备两大核
一、视觉文档理解技术总结
近期阅读到一篇极具参考价值的综述文章,系统化地梳理了文档视觉问答模型在架构上的演进脉络,值得向各位推荐分享。
视觉丰富文档(VRDs)之所以特殊,在于其并非单纯的文字堆砌——文本与图形、图表、表格等视觉元素相互交织,共同完成信息的传递。相较于传统文本文档,VRDs具备两大核心特征:其一,文字本身绑定了丰富的排版细节(如字体、字号、样式、颜色);其二,布局信息在空间上对内容进行了有机组织,更不用说那些提升理解效能的视觉要素——图表与图形,皆是关键信息载体。

视觉丰富文档理解(VrDU)这一研究方向,本质上属于计算机视觉与自然语言处理的交叉领域,其目标十分明确:既要能够感知(解析文档,识别并提取其中的对象),也要能够解释(基于文档特征执行问答、分析等任务)。下表汇总了当前相关工作的统计信息,一目了然。
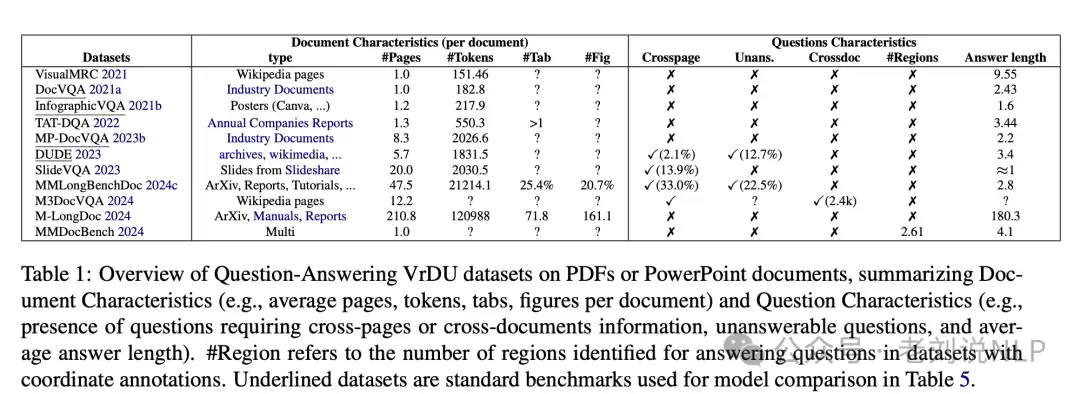
由此可见,当前针对PDF或PowerPoint文档的问答VrDU数据集,已全面覆盖文档特征(如平均每篇文档的页数、标记数量、标签页数、图表数量)及问题特征(如需要跨页面或跨文档信息的问题、无法回答的问题、答案平均长度),覆盖相当完整。
该综述题为《Survey on Question Answering over Visually Rich Documents: Methods, Challenges, and Trends》(https://arxiv.org/pdf/2501.02235),核心思路在于:如何将视觉特征有效整合进大语言模型(LLM),从而增强视觉丰富文档理解(VrDU)能力。文章拆解了三个关键环节:文档表示(探索融合文本、布局、视觉的编码方法,或纯视觉方法,重点关注多页表示);嵌入与大模型的整合(文档嵌入应该置于何处、以何种方式接入);高效训练这些VrDU模型(模态对齐的预训练方法)。接下来逐一深入剖析。
1. 整合三种模态的模型如何构建?
通常涉及三种模态:文本、布局、视觉。处理这三种模态的VrDU模型有多种实现方案,例如以下所示:
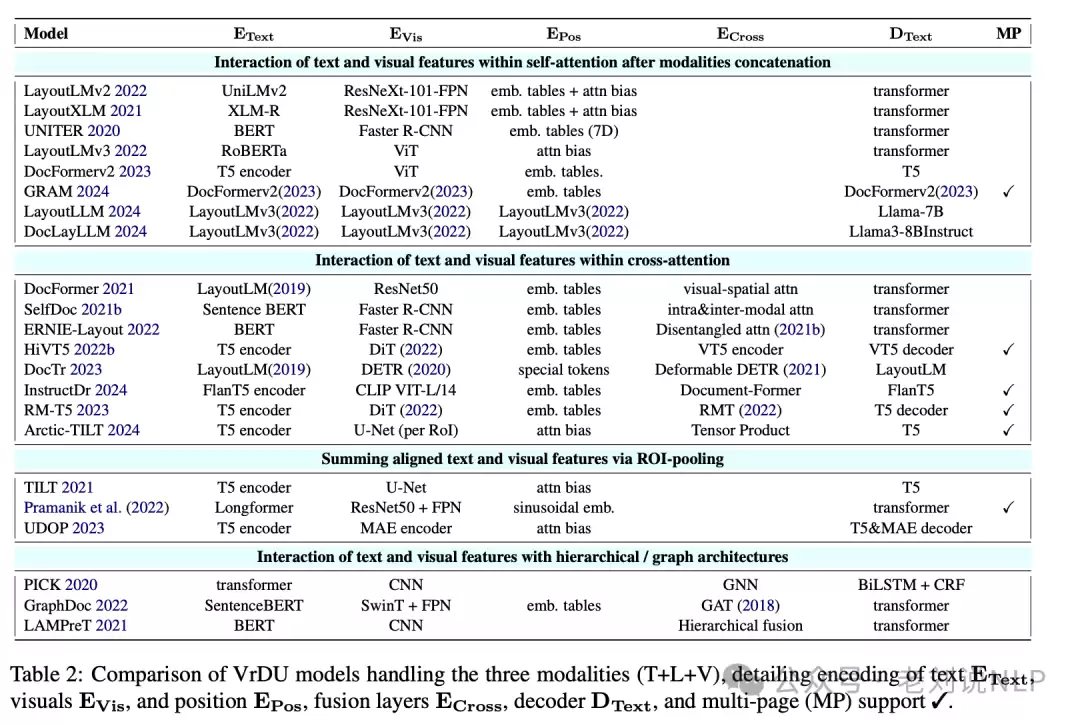
其中,布局特征指的是围绕文本及结构元素(如表格)的边界框,以及文档内各元素的位置与大小——精细到单个标记,粗粒度到单元格、表格、图像或段落。布局信息在模型中可通过三种方式表示:位置嵌入、注意力偏差,或者直接在文本中嵌入特殊标记。例如,Lyrics和ViTLP模型在文本标记中加入了
在视觉层面,主要捕捉文档页面的外观特征,包括整体结构以及整个文档的视觉上下文。视觉信息通过视觉编码器生成一组视觉“标记”(向量)。早期采用CNN,如今基本已过渡到视觉变换器(ViT)。
局部模态对齐是指在文档特定区域内将文本与视觉特征进行对齐;全局模态对齐则是通过连接文本与视觉特征来实现。
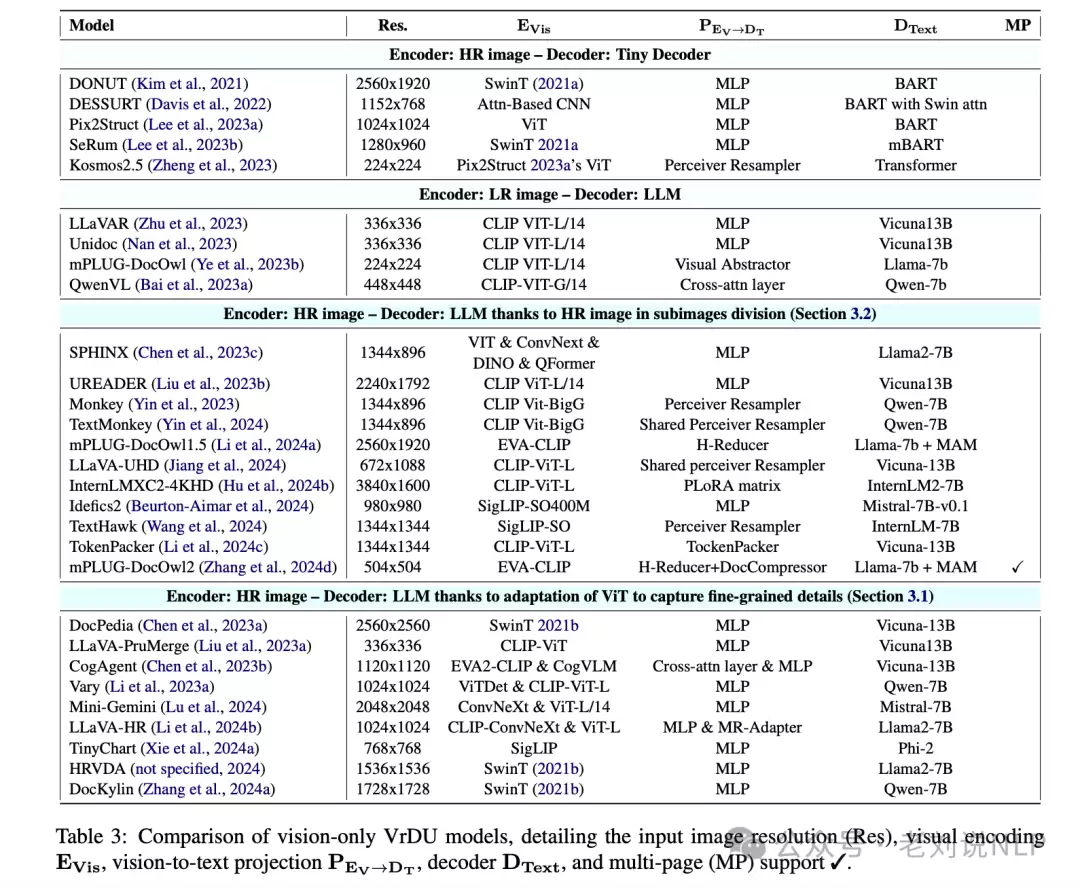
2. 视觉单一模态编码VrDs如何实现?
架构方面,最初是将CNN与ViT结合,或利用Swin Transformers等局部窗口机制处理高分辨率图像。近来的趋势是去除冗余信息,或直接采用未经修改的ViT架构处理分割后的图像。
随后又出现了使用多个ViTs处理分割图像的做法:将高分辨率图像切分为子图像,每个子图像交由独立的ViT处理,再通过变换器层或低分辨率表示来维持子图像之间的连续性。
3. 如何编码多页文档
多页文档的编码需要应对长序列与高信息密度的挑战,目前存在几种主流方案。
- 检索增强生成(RAG):利用检索技术,仅将包含相关信息的页面表示送入VrDU解码器,代表模型包括HiVT5和InstructDr。
- 逐页表示:每页使用独立的视觉编码器处理,随后将表示压缩后注入LLM,代表模型如mPLUG-DocOwl2。
- 长序列处理:采用递归记忆变换器(RMT)或稀疏注意力技术(如全局-局部、块状注意力)来处理多页文档,代表模型有RM-T5和Arctic-TILT。
4. 如何将VRD特征注入LLMs?
注入方式上,自注意力和交叉注意力各有优劣。自注意力方法计算效率较高——将VRD表示前置到提示中,让模型在自注意力层同时处理VRD特征与提示,只需线性投影或卷积调整特征空间,无需引入过多新参数。但问题在于对所有文本提示的原始标记一视同仁,未区分角色或重要性,可能导致性能次优。
交叉注意力方法则利用VrDU编码器的隐藏状态来条件化冻结的LLM,通过插入交叉注意力层实现。该方法能处理更长的序列,让查询/提示标记与VRD特征进行显式交互,更充分地发挥LLM的能力,适合长序列及高分辨率表示。但代价是引入了大量新参数,模型整体规模显著增大,计算效率与训练成本均会受到影响。
5. 不同方案效果如何?
这部分颇具趣味性。评测使用了多个VRDU数据集,包括VisualMRC 2021、DocVQA 2021a、InfographicVQA 2021b、TAT-DQA 2022、MP-DocVQA 2023b、DUDE 2023、SlideVQA 2023、MMLongBenchDoc 2024c、M3DocVQA 2024、M-LongDoc 2024和MMDocBench 2024,评估指标为平均归一化Levenshtein相似度(ANLS)。
几个关键发现:
- 多模态表示:最大化利用位置信息的模型表现最佳,说明文本与布局信息本身已足够回答问题,即使是复杂的图表和图形,只要布局被充分考虑,效果便十分理想。
- 纯视觉方法:使用预训练ViT处理高分辨率图像切片展现出一定潜力,能够在保留必要布局与语义细节的同时,实现紧凑且高效的表示。
- 多页文档处理:基于稀疏注意力机制的方法(如全局-局部或块状注意力)在跨页推理任务中表现出色,代表了多页文档理解的未来发展方向。
二、金融领域实体识别任务的大模型性能
前沿大语言模型在金融领域命名实体识别(NER)任务上实际表现如何?不同提示类型的效果存在哪些差异?此外,传统监督小模型与之相比又处于什么水平?这些问题值得仔细探究。
参考研究工作《Financial Named Entity Recognition: How Far Can LLM Go?》(https://arxiv.org/pdf/2501.02237),核心数据采用FiNER-ORD数据集作为基准,该数据集包含201篇金融新闻文章,人工标注了ORG、LOC、PER三种实体类型。
评估对象为三种前沿LLM及其轻量级版本:GPT-4o、LLaMA-3.1和Gemini-1.5,以及两个基于Transformer的模型(BERT和RoBERTa)。
提示方法设计了三种类型:直接提示(先给出NER任务指令,再提供文本与答案格式);上下文学习(在直接提示后附加示例);链式推理(CoT,使用“让我们一步一步来”引导中间推理步骤)。
结论方面,常见的错误类型包括:上下文误解、代词和通用术语误分类、公民身份术语误分类、隐含实体误分类,以及实体遗漏和边界错误。
值得注意的性能对比:Gemini系列在少样本学习后表现优于GPT-4o和LLaMA 3.1系列。而BERT类的监督方案,在零样本场景下全面优于通用LLM。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:金融NER大模型性能与视觉文档理解技术总结要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看