




DeepSeek-R1训练过程深度拆解解析

昨晚DeepSeek开源了R1模型,直接引爆了中美互联网圈。这事儿不小,来仔细拆解一下。 核心要点:R1遵循MIT License,允许蒸馏;上线API并开放思维链输出;在数学、代码、推理等任务上比肩OpenAI o1正式版,小模型甚至超越o1-mini;价格嘛,只有OpenAI的几十分之一。 下面
昨晚DeepSeek开源了R1模型,直接引爆了中美互联网圈。这事儿不小,来仔细拆解一下。
核心要点:R1遵循MIT License,允许蒸馏;上线API并开放思维链输出;在数学、代码、推理等任务上比肩OpenAI o1正式版,小模型甚至超越o1-mini;价格嘛,只有OpenAI的几十分之一。
下面从性能、方法、蒸馏、展望几个维度做系统拆解,所有数据和图表均源自论文《R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》。
结论前置
先划重点:除了R1,DeepSeek还发布了R1-Zero。R1-Zero基于DeepSeek-V3-Base,纯强化学习训练,没有监督微调;R1则在R1-Zero基础上,先用少量人工标注的高质量数据做冷启动微调,再进行强化学习。
几个关键发现:
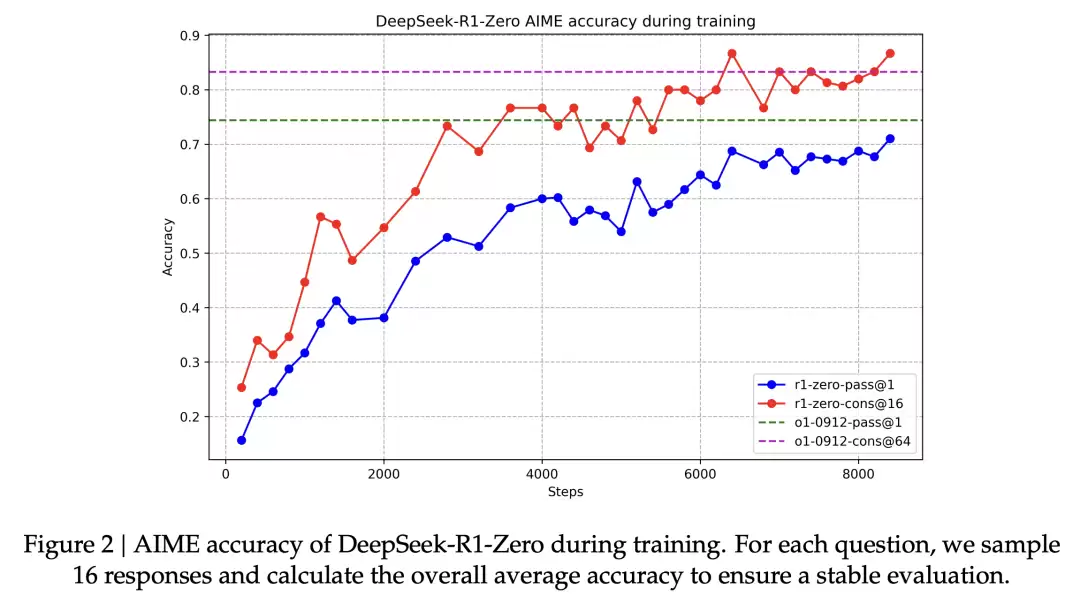
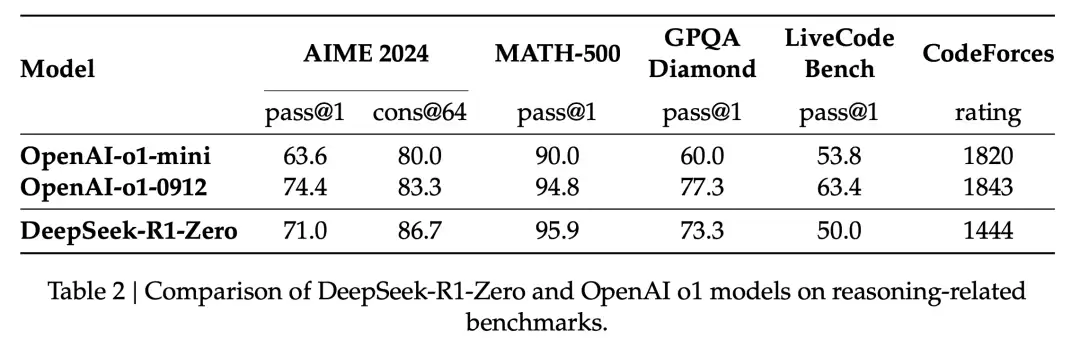
纯强化学习确实能打。R1-Zero证明了仅靠强化学习、不需要监督微调,大模型也能有强大的推理能力。在AIME 2024上,R1-Zero的pass@1从15.6%飙到71.0%,用投票策略后更是达到86.7%,跟OpenAI-o1-0912打平(表2,第7页)。
训练过程中间出现了“顿悟”现象。模型能自发学会新的、更有效的推理策略——这事本身就值得重视。
蒸馏比小型模型直接做强化学习更有效。用R1的推理能力去蒸馏Qwen和Llama系列的小模型,效果远好过直接在这些小模型上跑强化学习(表5,第14页)。比如R1-Distill-Qwen-7B在AIME 2024上得分55.5%,远超QwQ-32B-Preview;R1-Distill-Qwen-32B更是干到72.6%。这说明大模型在强化学习中学到的推理模式是可以迁移的。
冷启动数据确实有价值。R1相比R1-Zero,只加了少量高质量冷启动数据,就大幅提升了强化学习的效率和最终性能。
性能评估
论文在多个维度做了评估,覆盖知识密集型、推理密集型、长文本理解和开放式问答任务。对比基线包括DeepSeek-V3、Claude-3.5-Sonnet-1022、GPT-4o-0513、OpenAI-o1-mini和OpenAI-o1-1217。
结合表格4来看,结论很清晰:
R1在推理任务上表现突出,AIME 2024、MATH-500、Codeforces等任务上跟OpenAI-o1-1217打得有来有回,部分还超越。
知识密集型任务中,MMLU(90.8%)、MMLU-Pro(84.0%)、GPQA Diamond(71.5%)都显著超过DeepSeek-V3。
长上下文理解上,FRAMES数据集准确率82.5%,优于DeepSeek-V3。
开放式问答方面,AlpacaEval 2.0上LC-winrate 87.6%,Arena-Hard上GPT-4-1106评分92.3%。
训练流程
R1-Zero
纯粹的强化学习路线,没有监督微调数据,直接在DeepSeek-V3-Base上应用GRPO算法。奖励机制用了基于规则的方式,包括准确性奖励和格式奖励。训练模板很简洁:要求模型先输出推理过程(放在特定标签内),再给最终答案。
训练过程中间出现了“顿悟”现象。表3(第9页)展示了一个经典案例:模型在解数学题时突然意识到可以“重新评估”之前的步骤,换新思路解题。

性能上,R1-Zero在AIME 2024上的pass@1从最初的15.6%稳步提升到71.0%,跟OpenAI-o1-0912持平(图2,第7页)。在AIME 2024、MATH-500、GPQA Diamond等任务上也都能跟OpenAI-o1-0912掰手腕,部分任务还有明显领先(表2,第7页)。
R1
在DeepSeek-V3-Base上先做冷启动微调,再跑强化学习。这套思路结合了监督学习和强化学习的优势。
冷启动阶段用了数千个高质量人工标注样本。为了构建这批数据,团队尝试了几种方法:用带长思维链的few-shot提示、直接提示模型生成带反思和验证的详细解答、收集R1-Zero的输出做人工标注和格式化。
冷启动之后,R1进入面向推理的强化学习阶段,流程跟R1-Zero类似但做了优化。训练中引入了语言一致性奖励,根据思维链中目标语言单词的比例来计算,解决语言混杂问题。
当推理强化学习收敛后,R1用训练好的RL模型做拒绝采样,生成新的监督微调数据。这一阶段的数据不光有推理任务,还覆盖写作、角色扮演、问答等,目的是提升通用能力。
最后进入面向全场景的强化学习阶段,训练目标覆盖所有类型任务,针对不同任务用不同的奖励信号和提示分布。数学、代码、逻辑推理用基于规则的奖励,开放式问答、创意写作用基于模型的奖励。
核心方法
GRPO
R1采用的核心算法是Group Relative Policy Optimization,配合精心设计的奖励机制。跟传统需要构建Critic模型来估计状态值函数的算法不同,GRPO通过比较一组样本的奖励来估计优势函数,降低训练复杂度和计算资源。算法细节看论文2.2.1章节(第5页)。

奖励系统
R1-Zero的奖励系统分两类:准确性奖励,用于评估响应是否正确——确定性答案的任务(如数学题)自动验证,代码任务(如LeetCode)用编译器测试;格式奖励,强制模型把推理过程放在特定标签里。
训练模板
R1-Zero的模板很简洁(表1,第6页):要求模型先输出推理过程,再给最终答案。训练时把具体的推理问题替换到模板里。
模型蒸馏
DeepSeek团队进一步探索了蒸馏路线。他们用R1生成的800K数据,微调了Qwen和Llama系列多个小模型。结果(表5,第14页)很能说明问题:
经过R1蒸馏的小模型,推理能力提升显著,甚至超过直接在小模型上做强化学习。R1-Distill-Qwen-7B在AIME 2024上得分55.5%,远超QwQ-32B-Preview。
R1-Distill-Qwen-32B在AIME 2024上得分72.6%,MATH-500上94.3%,LiveCodeBench上57.2%,显著优于之前的开源模型,跟o1-mini相当。
表6(第14页)直接对比了R1-Distill-Qwen-32B和R1-Zero-Qwen-32B。直接在Qwen-32B-Base上做强化学习只能跟QwQ-32B-Preview打平,但经R1蒸馏的版本远超两者。这说明R1学到的推理模式通用性和可迁移性都很强。
还有更多
论文最后讨论了R1的局限性和未来方向。
局限性方面:通用能力(函数调用、多轮对话、复杂角色扮演、JSON输出)仍落后于DeepSeek-V3;处理非中英文问题时可能出现语言混杂;对提示词敏感,few-shot提示可能降低性能;软件工程任务上提升有限,因为强化学习的评估周期较长。
未来工作包括:探索用长思维链提升通用能力、解决语言混杂问题、优化提示词策略、把强化学习应用到软件工程任务、继续探索更有效的强化学习算法和奖励机制、研究如何把推理能力更好地落地到科学研究、代码生成、药物研发等实际场景。
额外的
团队也尝试了其他方法但效果不理想:Process Reward Model的构建和训练挑战大,容易导致奖励“hack”;Monte Carlo Tree Search在token生成任务中面临搜索空间过大的问题,value model训练也比较困难。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:DeepSeek-R1训练过程深度拆解解析要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点日常工作中,你是不是也经常需要快速查询资料、验证想法?一个小工具就能搞定——基于ChatGPT API的Chrome扩展,装好之后随问随答,连注册都不用折腾。 什么是 ChatGPT Chrome Extension ai chrome 扩展程序 插件? 这个Chrome扩展的本质,就是把ChatG
你是否厌倦了在搜索结果中翻页寻找答案?Candle AI 这款基于 GPT-3 的浏览器工具,能够直接为你呈现精准的文本答案——只需输入查询,它便快速生成基于网页内容的搜索结果摘要。简单来说,就是借助 AI 自动摘要与回答,省去手动筛选信息的繁琐过程。 什么是 Candle AI Chrome 扩展
在内容创作与社交媒体运营日益复杂的当下,各类工具层出不穷,但真正能将AI写作、图形设计、视频剪辑与多账号管理无缝整合的一站式平台并不多见。今天介绍的这款工具,恰好把这一点做到了极致——它是一个集成了AI能力的全流程营销解决方案,专为企业和内容创作者打通内容生产与社交发布的全链路。 什么是 Simpl
Shift-Ctrl-F 是一款集成 MobileBERT 模型的 Chrome 扩展,专注于网页内容的语义搜索与关键信息高亮,让用户在浏览时快速定位所需答案。 Shift-Ctrl-F AI Chrome 扩展程序 插件究竟是何物? 简单来说,Shift-Ctrl-F 作为一个 Chrome 扩展
- 日榜
- 周榜
- 月榜
热点快看