




AI工作流Xinference后台大模型平台搭建教程

探索国内自研的高性能大模型平台,发现AI推理的新天地。 之前我们聊过Ollama大模型后台,今天来介绍另一个重量级选手——Xinference。很多人可能觉得Xinference是个新面孔,其实它在圈子里已经存在很久了,只是最近随着国产大模型的升温才被更多人关注。简单来说,Xinference是一个
探索国内自研的高性能大模型平台,发现AI推理的新天地。
之前我们聊过Ollama大模型后台,今天来介绍另一个重量级选手——Xinference。很多人可能觉得Xinference是个新面孔,其实它在圈子里已经存在很久了,只是最近随着国产大模型的升温才被更多人关注。简单来说,Xinference是一个基于Xorbits Inference的分布式推理框架,由国内团队开发,支持大语言模型、语音识别、多模态模型等各类模型的推理部署。无论是研究者、开发者还是数据科学家,都能通过它一键调用前沿模型,快速验证想法。下面就直接进入正题,先看一组横向对比,感受一下它在江湖中的地位。
| 功能特点 | Xinference | FastChat | OpenLLM | RayLLM |
|---|---|---|---|---|
| 兼容 OpenAI 的 RESTful API | ✅ | ✅ | ✅ | ✅ |
| vLLM 集成 | ✅ | ✅ | ✅ | ✅ |
| 更多推理引擎(GGML、TensorRT) | ✅ | ❌ | ✅ | ✅ |
| 更多平台支持(CPU、Metal) | ✅ | ✅ | ❌ | ❌ |
| 分布式集群部署 | ✅ | ❌ | ❌ | ✅ |
| 图像模型(文生图) | ✅ | ✅ | ❌ | ❌ |
| 文本嵌入模型 | ✅ | ❌ | ❌ | ❌ |
| 多模态模型 | ✅ | ❌ | ❌ | ❌ |
| 语音识别模型 | ✅ | ❌ | ❌ | ❌ |
| 更多 OpenAI 功能 (函数调用) | ✅ | ❌ | ❌ | ❌ |
具体项目细节可以参考官方仓库:https://github.com/xorbitsai/inference。
既然Ollama已经很好用了,为什么还要折腾Xinference?两者到底有什么区别?下面分几个方面来讨论。
为什么
先说为什么要上Xinference平台,主要有三个原因。
原因一:模型种类更丰富。 Ollama虽然模型不少,但主要局限于文字生成(对话、补充)和视觉模型,文字处理方面也只包含生成类和Embedding模型。而Xinference除了覆盖这些,还额外支持Rerank模型(如Jina、BGE)、图像模型(如Stable Diffusion)、音频模型(如CosyVoice、ChatTTS)、视频模型(如混元大模型),以及自定义模型。而且内置的优质模型更多,比如ChatGLM-4V这类国产大模型也直接可用。
原因二:对RAG知识库更友好。 Dify对Ollama的定位是文字输出和Embedding,但文字处理中缺少Rerank这一环。在构建RAG知识库时,Embedding处理后的Rerank是提升检索质量的关键步骤,而Ollama本身不支持这个环节。除非自己手搓Dify的代码,否则很难绕开。而Xinference天生就支持Rerank模型,省了不少事。
原因三:多条路总没错。 毕竟Ollama是海外项目,万一哪天出现什么变故,手头有个国产备选方案会从容得多。
当然,任何工具都有两面。Xinference相对于Ollama,优势明显,但劣势也值得注意。
优点: 支持的模型种类多,可用性好;下载有国内源,速度很快;自带独立UI,基本操作无需命令行;能力范围比Ollama更广;国内公司开发,对国内用户更友好。
缺点: 上手难度较大,模型体量较大,模型优化不如Ollama;下载没有进度条,只能通过后台流量间接观察;开发门槛较高,对代码能力有要求;模型运行在后台时资源占用较大;必须依赖Docker,不像Ollama那样有独立后台;Docker本身占用资源较多;模型使用时需要手动选择框架,不清楚原理的话很容易卡住;部分技术框架(如Pytorch)需要手动安装。
怎么做
Xinference的安装
第一步:安装Docker。Docker的安装过程这里不再展开,可以参考官方文档或相关教程。
第二步:在空间较大的磁盘(如D盘)上创建一个文件夹,名称用英文且不含空格,例如 D:\Xinference。然后在该目录下再建一个 model 文件夹作为模型存储路径。
第三步:打开命令提示符或PowerShell,执行以下Docker命令拉取镜像并启动容器:
docker run -d --name xinference --gpus all -v D:/Xinference/model:/root/models -v D:/Xinference/.xinference:/root/xinference -v D:/Xinference/.cache/huggingface:/root/.cache/huggingface -e XINFERENCE_HOME=/root/models -p 9997:9997 registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:latest xinference-local -H 0.0.0.0
这条命令将从阿里云镜像仓库拉取最新版的Xinference,并将本地目录挂载到容器内对应的路径,最后指定端口为9997。执行后Docker会自动下载镜像并启动。
Xinference运行
镜像启动后,打开浏览器,访问 http://localhost:9997 或 http://127.0.0.1:9997 即可进入Xinference的UI界面。
如果打不开,请检查两点:是否有其他应用占用了9997端口;Docker中Xinference容器是否正常运行。
模型下载
进入界面后,建议先切换语言:在左下角找到切换按钮,点击选择“中文”,界面会更友好。
点击“启动模型”,选择需要的模型类型,然后搜索具体模型。以音频模型CosyVoice-300M-SFT为例:
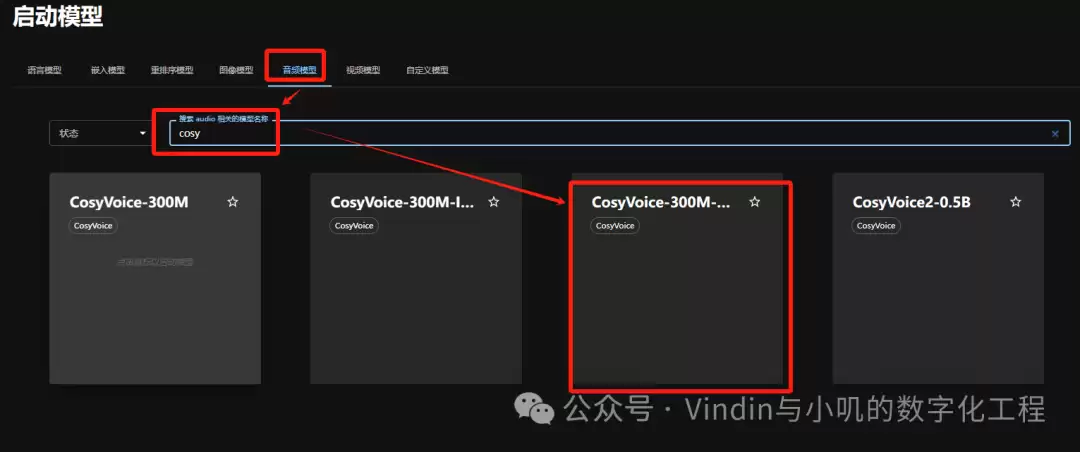
点击CosyVoice-300M-SFT的卡片,弹出模型配置窗口。重点是下载中心:国内用户建议选择“modelscope”,下载速度很快。设置好后点击小火箭按钮开始下载:
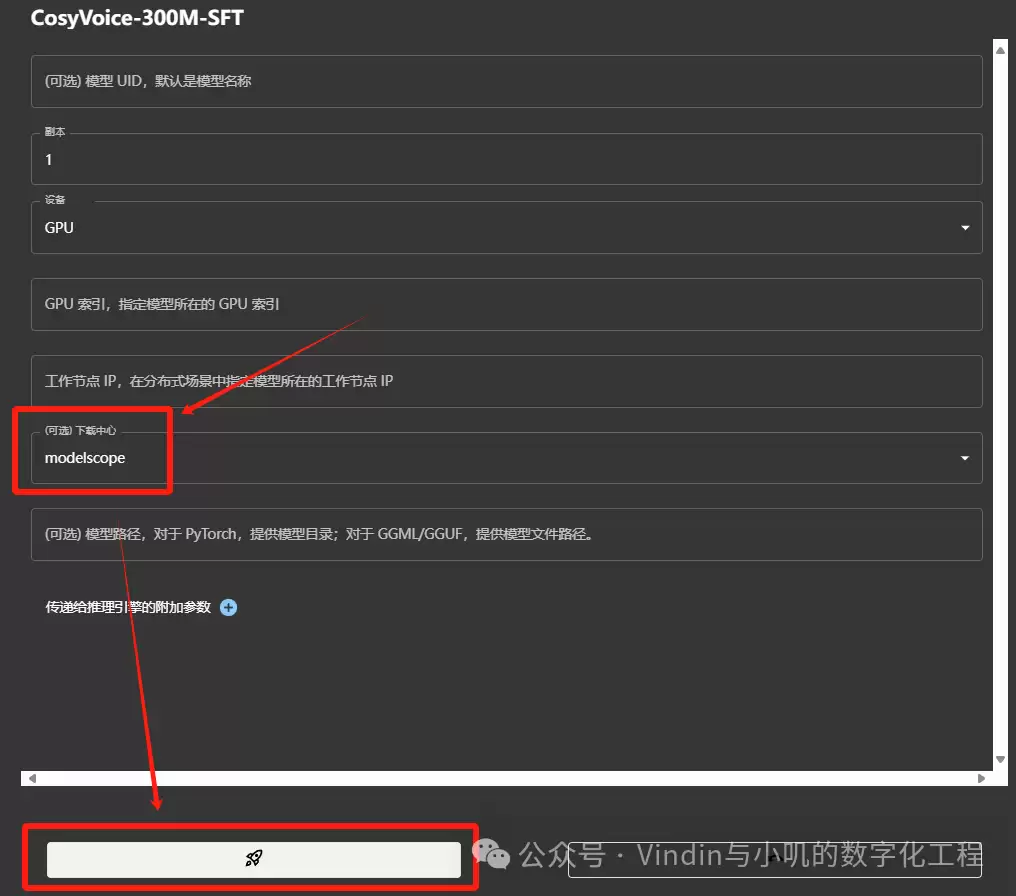
下载速度一般在5~15MB/s左右,如果带宽足够还能更高:
对于消费级显卡和个人电脑,模型大小通常在4~15GB之间,比如CosyVoice-300M-SFT大小是5.35GB:

下载完成后,在“运行模型”页面即可看到已启动的模型:
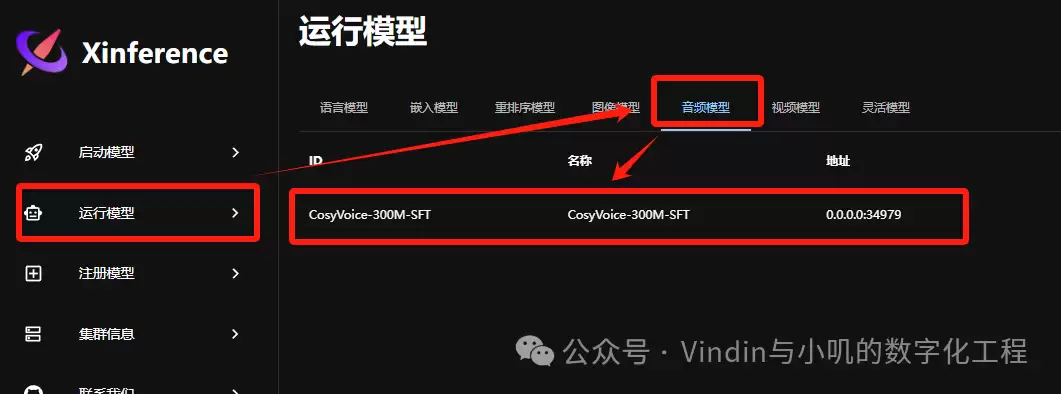
其他平台调用Xinference端口时,通常使用9997端口即可。
结论
Xinference是一个非常强大且全面的模型后台平台。虽然在性能优化上略逊于Ollama(比如自动释放硬件资源等方面),但它的模型支持范围更广,能力更全面,与FastGPT、Dify等平台的对接也非常流畅。更重要的是,它完全适配国内用户:模型下载不局限于HuggingFace,同时支持ModelScope等国内源,下载的是原始全量模型,而非Ollama那种加密打包。这样做的好处是方便开发者直接操作和调试;坏处是对硬件资源的要求更高,模型文件也更大。
总结来看:如果你不想做深度开发,只是需要用平台化的方式运行一些模型,那么Ollama和Xinference都是非常好的选择。对于一般开发者,它们能显著加速开发流程,当然也有一定限制。而对于高度定制化的开发场景,平台本身并非必需品,但在端口配置和接口统一方面仍能节省不少时间。
无论你最终选择哪个,多一个备选项总归不是坏事。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:AI工作流Xinference后台大模型平台搭建教程要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点基于人工智能的室内设计与虚拟布置平台,通过上传房间照片、手绘草图或SketchUp文件,自动识别空间结构并更换风格。核心功能包括草图转逼真渲染、3D漫游视频及虚拟布置,支持多种设计风格,提升可视化沟通效率。
OctoparseCEM是AI驱动的客户体验管理平台,聚合电商、社交媒体、客服工单等多渠道反馈,通过情感分析、客户旅程映射等功能,将非结构化数据转化为可操作洞察,助力产品优化、服务提升与业务增长。
在客户关系管理领域,如何让工具更智能地辅助市场决策?Odoo CRM 近期推出的一款扩展程序,或许给出了一个令人关注的答案——它直接将 OpenAI GPT-3 5 Turbo 与情感分析能力嵌入 CRM 工作流,使营销不再仅凭经验盲目判断。 什么是 Odoo CRM OpenAI GPT-3 5
联想与Meta合作,基于Llama大模型推出面向PC的个人AI智能体AINow。该产品由杨元庆和扎克伯格共同宣布,旨在将AI与混合现实技术普及。扎克伯格强调开源Llama可让联想微调模型以优化特定场景,并称开源是最高效、可定制且值得信赖的选择。
- 日榜
- 周榜
- 月榜
热点快看