




DeepSeek模型家族全解析:从LLM到R1

DeepSeek系列模型从LLM到R1持续创新,涵盖密集与MoE架构、MLA注意力、GRPO算法、无辅助损失负载均衡及FP8训练等技术。各版本在数学推理、性能与经济性上超越多个开源及闭源模型,推动全球AI竞争格局变革。
DeepSeek系列模型的技术创新,正在悄然重塑全球人工智能竞争版图。这些模型究竟强在何处?它们为何能在全球科技界引发如此巨大的反响?从DeepSeek LLM到R1,每一次迭代背后都暗藏着怎样的技术突破?今天,我们就来系统梳理这份技术家族的进化历程。

引言
DeepSeek的横空出世,在全球科技领域掀起的波澜远超预期。最直接的冲击体现在资本市场:NVIDIA股价单日暴跌18%,全球科技股市值蒸发近1万亿美元。就连特朗普也公开称赞DeepSeek的崛起具有“积极意义”,甚至直言这为美国敲响了“警钟”。而Anthropic的反应则更具策略性:一方面肯定DeepSeek的技术成就,另一方面呼吁美国政府强化对华芯片管制。
种种信号都指向一个事实:中国AI的技术实力已经不容小觑,正在深刻改写全球AI的发展方向。
深入研读DeepSeek系列模型的前沿文献和解读资料后,我梳理出了这篇文章。今天,就让我们一起看看DeepSeek模型家族的技术全貌。
各版本简介
DeepSeek系列在技术创新的道路上走得相当稳健,每次新版本的发布都代表着一次实质性的跃升。从最初的DeepSeek LLM、DeepSeekMoE、DeepSeekMath,到后来的DeepSeek V2、V3,以及最新的R1,每一款模型都在架构、训练方法、数据集开发等多个维度上带来了独特的创新。
- DeepSeek LLM:2024年1月发布,优化了模型层数配置,并利用分组查询注意力机制有效降低了推理成本;改进了超参数设置,用多步学习率调度器替代余弦调度器;运用HAI-LLM训练框架优化基础设施,提出了新的缩放分配策略。使用2万亿字符的双语数据集进行预训练,67B模型性能全面超越LLaMA-2 70B,对话版本表现优于GPT-3.5。
- DeepSeekMoE:2024年1月同步发布,核心创新在于细粒度专家分割和共享专家隔离。性能上优于传统MoE架构和部分密集模型,16B版本可在单张40GB显存的GPU上部署,并构建了对应的聊天模型。
- DeepSeekMath:2024年2月发布,通过数学预训练、监督微调、强化学习三阶段训练,构建了120B数学语料库,提出了GRPO算法。其数学推理能力直逼GPT-4,超越众多30B-70B参数规模的开源模型。
- DeepSeek V2:2024年5月发布,创新性地改造了注意力模块(MLA),改进了MoE架构,基于YaRN扩展长上下文,并发布了Lite版本。引入了三种辅助损失和Token-Dropping策略,通过多阶段训练流程提升模型性能。
- DeepSeek V3:2024年12月发布,采用了无辅助损失的负载均衡策略和多Token预测,配合FP8混合精度训练框架和高效通信框架,通过知识蒸馏提升推理性能。训练成本极低,但性能强劲——基础模型超越其他开源模型,聊天版本与领先闭源模型性能相当。
- DeepSeek R1:2025年1月发布,Zero版本无需监督微调就具备卓越推理能力,与OpenAI o1-0912在AIME上性能相当;R1版本采用多阶段训练和冷启动数据,推理性能与OpenAI o1-1217相当。此外,还提炼了六个蒸馏模型,显著提升了小模型的推理能力。
DeepSeek LLM
发布时间:2024年1月
论文:https://arxiv.org/pdf/2401.02954
DeepSeek LLM属于密集型的语言模型。在微观设计上,它沿用了LLaMA的部分设计,例如Pre-Norm结构、RMSNorm函数、SwiGLU激活函数和Rotary Embedding位置编码。
核心创新点
模型架构与训练的优化:
- 调整模型架构:除了沿用LLaMA的设计,宏观上调整了层数配置——7B模型30层,67B模型95层,且67B模型使用分组查询注意力机制来优化推理成本。
- 改进训练超参数:使用标准差0.006进行初始化,采用AdamW优化器,设置β1=0.9、β2=0.95和权重衰减0.1。用多步学习率调度器替代余弦调度器,便于持续训练,且最终性能相当。
- 在预训练和对齐(监督微调与DPO)方面进行了创新。
- 优化训练基础设施:运用HAI-LLM训练框架,整合了数据并行、张量并行、序列并行和1F1B流水线并行,利用Flash Attention提升硬件利用率,使用ZeRO-1分区优化器状态,融合部分层和操作以加速训练,采用bf16精度训练并在fp32精度下累积梯度。
缩放定律研究:提出了新的最优模型/数据扩展-缩放分配策略,指导了开源配置(7B和67B),并指导了最佳超参数的使用。
数据集规模:使用2万亿字符的双语数据集进行预训练,数据集规模比LLaMA更大。
模型性能:67B版本在各项基准测试中全面超越LLaMA-2 70B,尤其在代码、数学和推理方面表现突出。开放评估显示,对话版本表现优于GPT-3.5。
模型规模:包括7B和67B两个版本。
DeepSeek Chat:在基础模型上进行了监督微调和直接偏好优化(DPO),从而创建了对话模型。
局限性:预训练后知识更新较为困难,容易生成不实信息;中文数据初始版本不够详尽,且主要覆盖中文和英文,对其他语言的处理能力有限。
DeepSeek MoE
发布时间:2024年1月
论文:https://arxiv.org/pdf/2401.06066
在大模型时代,混合专家(MoE)架构被寄予厚望。但传统MoE架构面临专家专业化不足的问题。DeepSeekMoE的出现,正是为了解决这一痛点。其架构包含两个关键创新:
- 细粒度专家分割:将专家进一步细分,实现更高的专家专业化和更精准的知识获取。
- 共享专家隔离:隔离部分共享专家,以减轻路由专家之间的知识冗余。
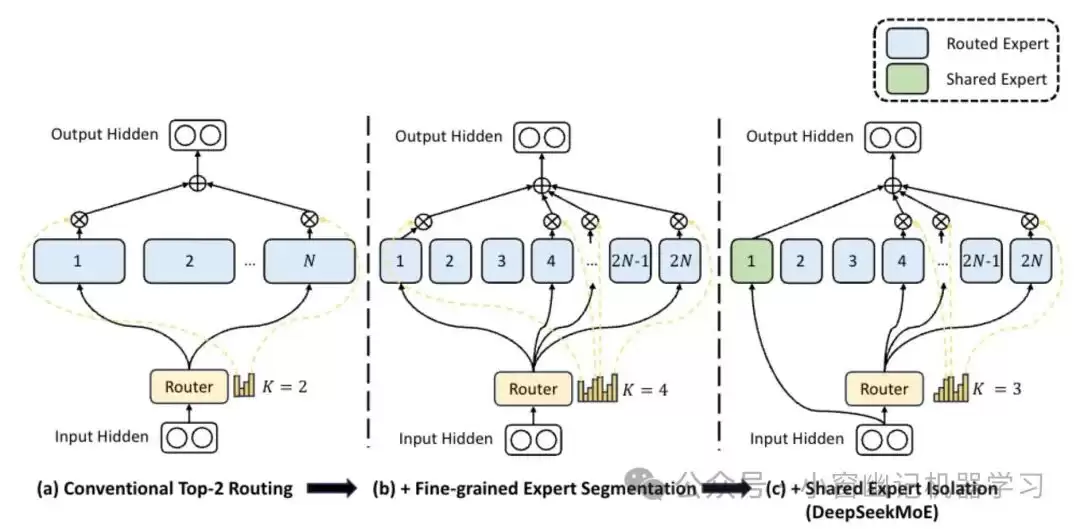
通过更灵活的专家组合,模型性能得以提升,同时计算成本保持不变。
数据集规模:16B。
性能优势:
- 优于传统MoE:DeepSeekMoE 2B性能优于GShard 2B,与GShard 2.9B相当,接近相同参数总量的密集模型性能。
- 优于密集模型:扩展到160亿参数后,仅使用约40%的计算量,性能与DeepSeek 7B和LLaMA2 7B相当。
- 参数量增大后优势更明显:1450亿参数版本,仅用28.5%的计算量就达到了DeepSeek 67B的性能。
对话模型:基于DeepSeekMoE 16B进行了有监督微调,构建了对应的聊天模型。
开源:DeepSeekMoE 16B的模型检查点已公开发布,可在单张40GB显存的GPU上部署。
负载均衡的辅助损失:采用了专家级平衡损失和设备级平衡损失,以缓解路由策略可能带来的负载不均衡问题,防止路由崩溃和计算瓶颈。
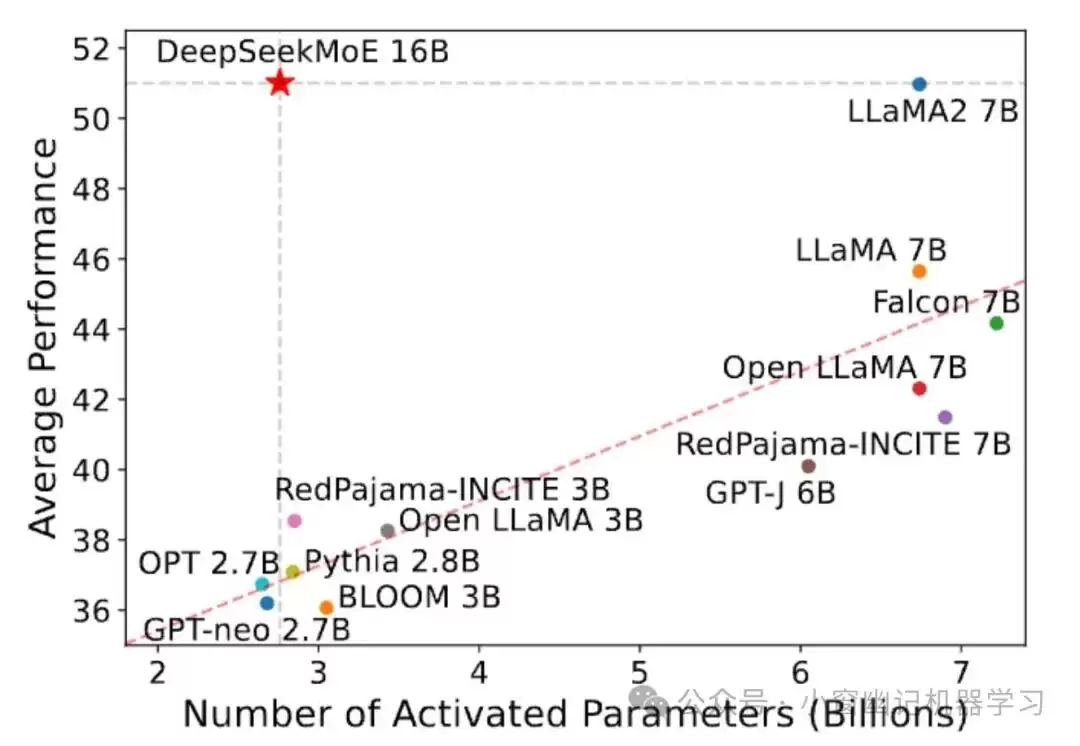 DeepSeekMoE 16B与开源模型在Open LLM Leaderboard上的对比。红色虚线是从除DeepSeekMoE 16B之外的所有模型的数据点线性拟合得到。可以看到,DeepSeekMoE 16B始终以明显优势胜过同类激活参数数量的模型,性能与LLaMA2 7B相当,而后者的激活参数量大约是它的2.5倍。
DeepSeekMoE 16B与开源模型在Open LLM Leaderboard上的对比。红色虚线是从除DeepSeekMoE 16B之外的所有模型的数据点线性拟合得到。可以看到,DeepSeekMoE 16B始终以明显优势胜过同类激活参数数量的模型,性能与LLaMA2 7B相当,而后者的激活参数量大约是它的2.5倍。
DeepSeek Math
发布时间:2024年2月5日
论文:https://arxiv.org/abs/2402.03300
DeepSeekMath仅有7B参数,但数学推理能力直逼GPT-4。在权威的MATH基准测试中,它力压群雄,超越了一众30B-70B参数的开源模型。两大亮点值得关注:
- 三阶段训练方式:
- 数学预训练:从Common Crawl构建了120B数学语料库,经过反复迭代筛选后进行训练。实验证实,代码训练能够有效提升数学推理能力。
- 监督微调:构建了多格式数学指令微调数据集,训练得到的DeepSeekMath-Instruct 7B,在MATH数据集上表现优于多数开源和部分闭源模型。
- 强化学习:提出了GRPO算法,通过组分数来估计基线,从而减少训练资源消耗。利用该算法训练得到的DeepSeekMath-RL 7B,在多个基准测试中超越多数开源和部分闭源模型。
- 群体相对策略优化GRPO:相比于PPO,GRPO通过从组分数估计基线,避免了使用价值函数,因此训练资源消耗显著降低。
DeepSeek V2
发布时间:2024年5月7日
论文:https://arxiv.org/pdf/2405.04434
DeepSeek V2是一款强大的MoE语言模型,参数量高达236B,但由于MoE结构,每个token仅激活21B的参数,同时支持128K上下文。其创新主要集中在四个维度:
两大核心创新
- 改造注意力模块:提出了多头潜在注意力(MLA),用以替代传统多头注意力。MLA利用低秩键值联合压缩,降低了推理时的KV Cache开销,且性能不输于MHA。更重要的是,它缓解了MQA和MGA对性能的影响。
- 改进MoE:将FFN结构改为DeepSeekMoE,这是对传统MoE架构的一次实质性升级。
基于YaRN的长上下文扩展:初始预训练后,采用YaRN将默认上下文窗口从4K扩展到128K。
DeepSeek-V2-Lite:同时发布了Lite版本,配备了MLA和DeepSeekMoE,总参数为15.7B,每个token仅激活2.4B参数。
负载均衡的辅助损失:训练过程中设计了三种辅助损失:专家级均衡损失、设备级平衡损失以及通信平衡损失。同时引入了设备级Token-Dropping策略。
训练流程:
- 先在完整预训练语料库上进行预训练
- 收集150万个对话会话(涵盖数学、代码、写作、推理、安全等领域)进行监督微调
- 采用GRPO进一步与人类偏好对齐,生成DeepSeek-V2 Chat(RL)。
DeepSeek V3
发布时间:2024年12月26日
论文:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
V3能够在海内外风靡,关键因素只有两个:训练成本极低、引领前沿创新。参数量高达671B,但所用GPU训练资源仅为Llama 3.1 405B的约1/14。
整体思路上,它基于DeepSeek-V2,采用了MLA和DeepSeekMoE架构。通过引入新的架构和训练策略,进一步提升了性能,同时降低了成本。创新主要集中在以下几个方向:
核心创新点:
- 无辅助损失的负载均衡策略:通过引入偏置项来动态调整专家负载,从而避免了传统辅助损失带来的性能损失。
- 多Token预测:在每个位置预测多个未来token,增加了训练信号,提高了数据效率。
高效的训练框架:
- FP8混合精度训练框架:首次验证了FP8训练在超大规模模型上的可行性。
- 通过DualPipe算法和优化的通信内核,实现了近乎零开销的跨节点通信。
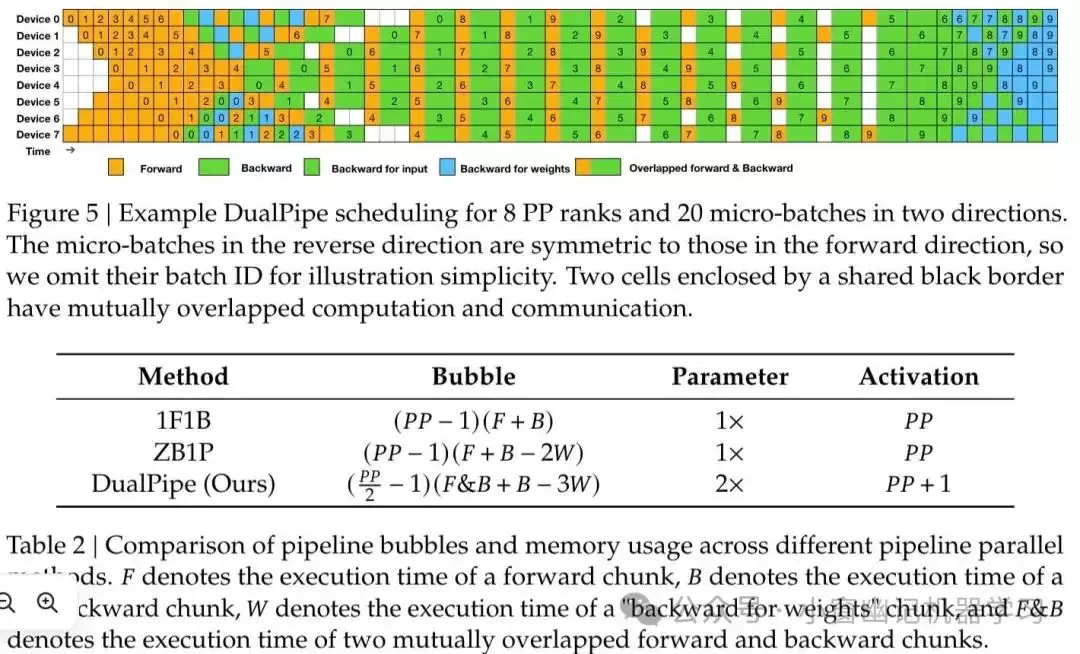
知识蒸馏与能力提升:在训练阶段,从DeepSeek R1系列模型中将推理能力进行蒸馏并融入V3,有效提升了模型的推理性能。在保持准确性的同时,合理控制了输出风格和长度,使模型在复杂推理任务中表现更加出色。
卓越性能与低成本:实现了经济效益与性能的双重兼顾。基础模型在知识、代码、数学和推理等领域的基准测试中全面超越其他开源模型,聊天版本在标准和开放式基准测试中与领先的闭源模型性能相当,成为当前最强的开源基础模型之一。
DeepSeek R1
发布时间:2025年1月
论文:https://arxiv.org/pdf/2501.12948v1
关键贡献
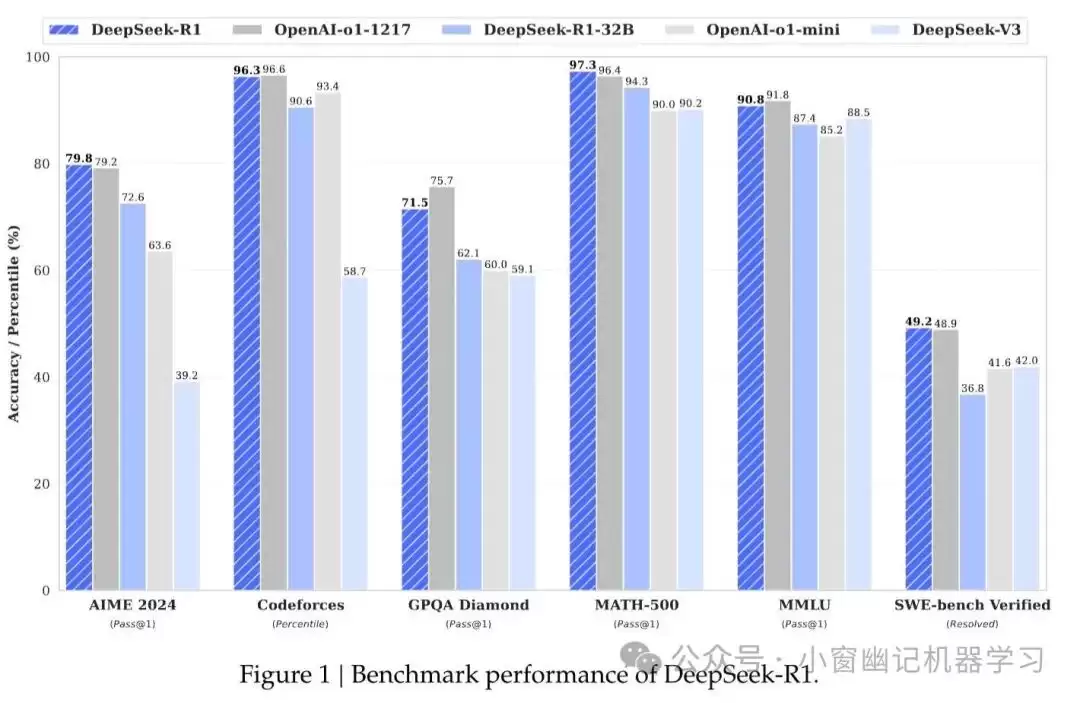
- 开源DeepSeek-R1-Zero:通过大规模强化学习训练,无需监督微调(SFT)作为初始步骤,在AIME上与OpenAI o1-0912性能相当。
- 开源DeepSeek-R1:采用多阶段训练,并在强化学习前加入冷启动数据,在推理任务上与OpenAI o1-1217性能相当。
- DeepSeek-R1蒸馏模型:基于Qwen和Llama提炼出六款密集模型(15亿、70亿、80亿、140亿、320亿、700亿参数),显著提升了小模型的推理能力。
总结
DeepSeek系列模型在人工智能领域的进展,依靠的不是偶然的运气,而是一系列扎实的技术创新。
- 技术创新成果显著:从DeepSeek LLM到R1,每一个版本都在架构、训练方法、数据集等关键维度上实现了实质性突破。例如DeepSeek LLM的缩放分配策略,DeepSeekMoE的细粒度专家分割,DeepSeekMath的GRPO算法,DeepSeek V2的MLA注意力机制,DeepSeek V3的无辅助损失负载均衡和FP8训练验证,以及DeepSeek R1的大规模强化学习和多阶段训练。这些创新持续推高了模型性能,部分版本甚至超越了同类型的其他知名模型。
- 推动行业发展与变革:DeepSeek系列模型的出现,对全球AI行业产生了深刻影响。强大的性能引起了广泛关注,促使其他研究机构和企业加大相关领域的投入,推动了AI技术的整体发展。同时,模型的开源为研究人员提供了宝贵资源,促进了学术交流和技术共享,加速了AI技术的创新与落地。训练成本和推理效率等方面的优化,也为AI技术的大规模应用提供了更具经济优势的方案。
- 面临挑战与未来展望:尽管取得了令人瞩目的成绩,DeepSeek系列模型仍面临一些挑战。例如部分模型存在预训练后知识更新困难、易生成不实信息、多语言处理能力不足等问题。未来,需要在模型架构和训练方法上继续优化,提高泛化能力和稳定性,并加强对多语言的支持。随着技术发展,DeepSeek很有可能在推理能力、多模态融合等方面取得新的突破,为人工智能的更广泛应用提供更强有力的支撑。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:DeepSeek模型家族全解析:从LLM到R1要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看