




机器学习5种采样方法解析与实战应用指南

数据科学本质上离不开算法。在日常的算法实践中,有些采样技术是必须掌握的基础。本文系统梳理数据预处理中最常用的几种采样方法——虽然看似基础,但正确选择能大幅提升效率,选错则可能导致结果完全偏离预期。 简单随机抽样 当你需要从一个总体中随机选取一个子集,且每个个体被选中的概率完全相同,这就是简单随机抽样
数据科学本质上离不开算法。在日常的算法实践中,有些采样技术是必须掌握的基础。本文系统梳理数据预处理中最常用的几种采样方法——虽然看似基础,但正确选择能大幅提升效率,选错则可能导致结果完全偏离预期。
简单随机抽样
当你需要从一个总体中随机选取一个子集,且每个个体被选中的概率完全相同,这就是简单随机抽样。下面用一行代码演示如何从数据集中抽样100个样本:
sample_df = df.sample(100)
分层抽样
下面考虑一个更加贴近实际的场景。假设要估算一场选举中各个候选人的平均得票数,国家有三个镇:A镇100万工人,B镇200万工人,C镇300万退休人员。如果直接从全体人口中随机抽60个人,样本很可能在不同镇之间失衡——退休人员偏多或工人偏多,导致估计偏差很大。
采用分层抽样则能有效解决:从A镇抽10人、B镇抽20人、C镇抽30人,总样本量不变,但估计误差会小很多。在Python中实现起来也非常直接:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.25)
水塘采样
这个问题非常有趣:假设有一个长度未知且规模庞大的项目流,只能迭代一次,需要从中随机选出一个项目,让每个项目被选中的概率相等。这该如何实现?
来看一个具体例子——从无限流中抽取5个对象,每个元素被选中的概率必须相等。下面这段代码就是经典的水塘采样实现:
import random
def generator(max):
number = 1
while number < max:
number += 1
yield number
stream = generator(10000)
k = 5
reservoir = []
for i, element in enumerate(stream):
if i+1 <= k:
reservoir.append(element)
else:
probability = k/(i+1)
if random.random() < probability:
reservoir[random.choice(range(0, k))] = element
print(reservoir)
# 输出示例:[1369, 4108, 9986, 828, 5589]
从数学上可以证明,流中每个元素被选中的概率确实相同。想知道为什么?不妨从一个小问题入手来理解。
考虑一个只有3个项目的流,需要保留其中2个。看到第一个项目时,水塘还有空间,直接放进去;看到第二个项目,同样放进去;看到第三个项目时,有趣的地方来了:有2/3的概率把这个新项目放进水塘,但此时水塘已满,需要随机替换掉一个已有的项目。
计算一下第一个项目最终被选中的概率:它被移除的概率等于第三个项目被选中(概率2/3)乘以第一个项目被随机选为替换对象(概率1/2),即2/3 × 1/2 = 1/3。因此第一个项目被保留的概率就是 1 − 1/3 = 2/3。同样的分析对第二个项目也成立,推广到任意数量项目——每个项目被选中的概率都是 K/N。简洁又漂亮。
随机欠采样和过采样
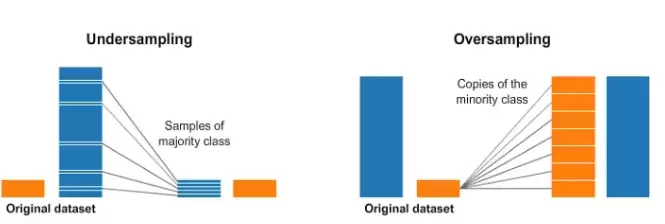
在实际项目中,我们经常遇到不平衡数据集,例如欺诈检测、罕见病诊断等场景,正类样本数量极少。针对这类问题,重采样是一种常用策略:一是对多数类进行欠采样(删除部分样本),二是对少数类进行过采样(增加样本数量)。
先用代码造一点不平衡数据来演示:
from sklearn.datasets import make_classification
X, y = make_classification(
n_classes=2, class_sep=1.5, weights=[0.9, 0.1],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10
)
X = pd.DataFrame(X)
X['target'] = y
然后看看简单的过采样和欠采样怎么做:
num_0 = len(X[X['target'] == 0])
num_1 = len(X[X['target'] == 1])
print(num_0, num_1)
# 随机欠采样
undersampled_data = pd.concat([
X[X['target'] == 0].sample(num_1),
X[X['target'] == 1]
])
print(len(undersampled_data))
# 随机过采样
oversampled_data = pd.concat([
X[X['target'] == 0],
X[X['target'] == 1].sample(num_0, replace=True)
])
print(len(oversampled_data))
# 输出:90 10 → 20 → 180
使用 imbalanced-learn 进行欠采样和过采样
imbalanced-learn(简称imblearn)是专为解决不平衡数据集问题而设计的Python库,提供了多种成熟的重采样方法。
a. 使用 Tomek Links 进行欠采样
Tomek Links 指的是那些在特征空间里靠得很近但属于不同类别的样本对。算法会把这些多数类的“邻居”删掉,让分类器得到更清晰的决策边界:
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(return_indices=True, ratio='majority')
X_tl, y_tl, id_tl = tl.fit_sample(X, y)
b. 使用 SMOTE 进行过采样
SMOTE(Synthetic Minority Oversampling Technique)的思路是在已有少数类样本附近合成新的少数类样本,而不是简单地复制:
from imblearn.over_sampling import SMOTE
smote = SMOTE(ratio='minority')
X_sm, y_sm = smote.fit_sample(X, y)
当然,imblearn包还提供了许多其他方法,比如欠采样的Cluster Centroids、NearMiss,过采样的ADASYN和bSMOTE,可以根据具体场景灵活选用。
结论
算法是数据科学的核心驱动力,然而采样这一基础环节却常常被忽视。一个恰当的采样策略往往能显著推动项目进展,而错误的选择则可能使整个分析偏离方向。下次处理数据时,建议多关注采样方法的选择,它带来的收益往往超出预期。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:机器学习5种采样方法解析与实战应用指南要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点基于人工智能的室内设计与虚拟布置平台,通过上传房间照片、手绘草图或SketchUp文件,自动识别空间结构并更换风格。核心功能包括草图转逼真渲染、3D漫游视频及虚拟布置,支持多种设计风格,提升可视化沟通效率。
OctoparseCEM是AI驱动的客户体验管理平台,聚合电商、社交媒体、客服工单等多渠道反馈,通过情感分析、客户旅程映射等功能,将非结构化数据转化为可操作洞察,助力产品优化、服务提升与业务增长。
在客户关系管理领域,如何让工具更智能地辅助市场决策?Odoo CRM 近期推出的一款扩展程序,或许给出了一个令人关注的答案——它直接将 OpenAI GPT-3 5 Turbo 与情感分析能力嵌入 CRM 工作流,使营销不再仅凭经验盲目判断。 什么是 Odoo CRM OpenAI GPT-3 5
联想与Meta合作,基于Llama大模型推出面向PC的个人AI智能体AINow。该产品由杨元庆和扎克伯格共同宣布,旨在将AI与混合现实技术普及。扎克伯格强调开源Llama可让联想微调模型以优化特定场景,并称开源是最高效、可定制且值得信赖的选择。
- 日榜
- 周榜
- 月榜
热点快看